Die Volltextsuche ist eine optionale Komponente des SQL Server-Datenbankmoduls und hilft bei der Volltextabfrage für zeichenbasierte Daten in SQL Server-Tabellen.
Sie dient daher dem Auffinden und Extrahieren wichtiger Informationen aus großen Mengen von unstrukturierten Texten oder Dateien und ist somit auch ein wichtiger Teilbereich des Text Mining.
Bevor wir aber Volltextabfragen für eine bestimmte Tabelle ausführen können, müssen noch einige Vorbereitungen getroffen werden.
“FILESTREAM” einrichten
FILESTREAM ermöglicht in SQL Server-basierten Anwendungen, nicht-strukturierte Daten wie Dokumente und Bilder im Dateisystem zu speichern, abzufragen, zu aktualisieren und zu durchsuchen. Somit integriert FILESTREAM das Datenbankmodul in ein NTFS-Dateisystem, indem BLOB-Daten (Binary Large Object) vom Typ “varbinary(max)” im Dateisystem gespeichert werden.
Zuerst müssen wir jedoch FILESTREAM mit dem “SQL Server Configuration Manager” aktivieren, weil SQL Server dies bei der Installation nicht automatisch macht.
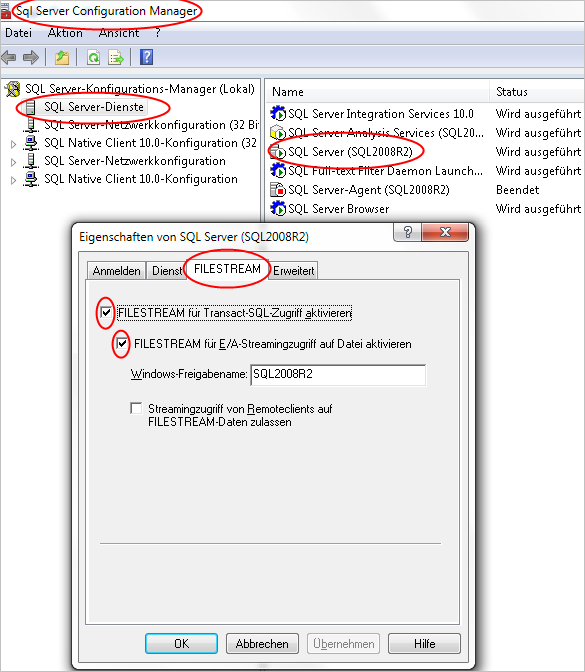
Abb. 1: Enable Streaming
Dateigruppe für FILESTREAM in der Datenbank definieren
Um FILESTREAM verwenden zu können, müssen wir für die Datenbank eine besondere Art von Dateigruppe anlegen bzw. gleich eine neue Datenbank mit dieser Dateigruppe erstellen.
Das geschieht über folgenden Code für die Datenbank “Volltextsuche”, die wir zuvor angelegt haben:
Alter Database Volltextsuche Add Filegroup FileStreamPDF_FG CONTAINS Filestream
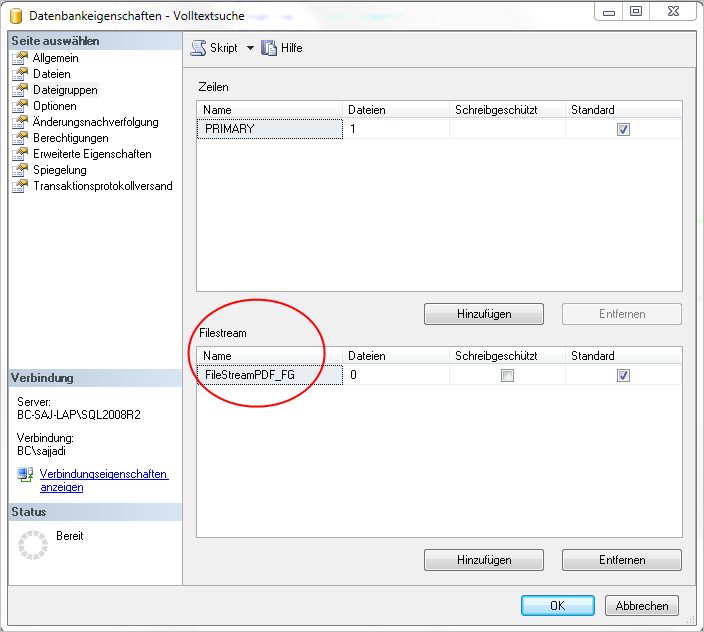
Abb. 2: Dateigruppe definieren
Datenbankordner für FILESTREAM-Dateigruppe erstellen
Im Gegensatz zu einer normalen Dateigruppe benötigt eine FILESTREAM-Dateigruppe keine neue Datenbankdatei, sondern einen neuen Ordner. Dabei muss der Pfad bis zum letzten Ordner vorhanden sein. Der Unterordner “FS_Volltextsuche_Documents” wird jedoch automatisch erstellt. Mit Hilfe des folgenden Codes legen wir den Ordner an:
Alter Database Volltextsuche ADD File ( Name = 'FileStreamPDF_FG' ,FILENAME = 'C:\Data\FS_Volltextsuche_Documents' ) To FILEGROUP FileStreamPDF_FG
Nach der Ausführung des obigen Codes werfen wir einen Blick auf das Dateisystem:
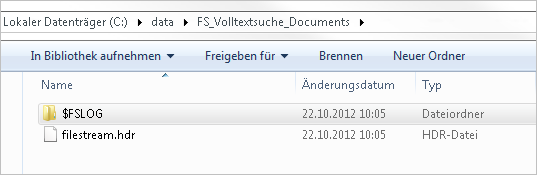
Abb. 3: Dateigruppe Ordnerstruktur
Die Datei “filestream.hdr” ist eine Systemdatei, die FILESTREAM-Headerinformationen enthält. Sie darf nicht entfernt oder geändert werden.
Nun sind datenbankseitig alle Vorbereitungen abgeschlossen, so dass wir uns den Tabellen und ihrer Struktur zuwenden können.
Tabelle mit Filestream-Spalte anlegen
Es wird eine Tabelle zum Speichern von FILESTREAM-Daten erstellt. Diese enthält eine Spalte vom Typ “varbinary(max)”. Hier werden z. B. PDF-Dokumente im FILESTREAM-Ordner abgelegt. Außerdem muss die ID-Spalte “DocumentID” als ROWGUIDCOL-Spalte definiert werden, die zur Verwendung von FILESTREAM-Daten erforderlich ist. Die Spalte “Document_Type” ist genauso wichtig, damit bei der Volltextsuche der richtige Filter verwendet wird, in unserem Beispiel also “.pdf”.
Create Table T_Documents ( DocumentID uniqueidentifier NOT NULL ROWGUIDCOL CONSTRAINT DF_T_Documents_ID DEFAULT NEWSEQUENTIALID() CONSTRAINT UQ_T_Documents_ID UNIQUE , Document varbinary(max) FILESTREAM DEFAULT (0x) , Document_No int Not NULL Identity(1,1) --Primary Key CONSTRAINT PK_T_Documents Primary KEY , Document_Type nvarchar(100) , Document_Name nvarchar(200) , Document_Page int )
Volltextkatalog anlegen
Zum Erstellen von Volltextindizes in Tabellen einer Datenbank benötigen wir den sogenannten Volltextkatalog, den wir wie folgt anlegen:
CREATE FULLTEXT CATALOG ft_Catalog_pdf as DEFAULT
Der Volltextindex umfasst eine oder mehrere zeichenbasierte Spalten der Tabelle. Diese Spalten können jeden der folgenden Datentypen aufweisen: char, varchar, nchar, nvarchar, text, ntext, image, xml oder varbinary(max) und FILESTREAM. Jeder Volltextindex indiziert mindestens eine Spalte aus der Basistabelle. Und man kann sogar für jede Spalte eine eigene Sprache verwenden.
Datenbank für Volltext einrichten
In SQL Server 2008 und höheren Versionen sind standardmäßig alle von Benutzern erstellten Datenbanken immer volltextfähig. Der folgende SQL-Befehl wird nur aus Gründen der Abwärtskompatibilität unterstützt:
exec sp_fulltext_database 'enable'
Zusätzliche Komponente für PDF-Dateien installieren
Standardmäßig werden PDF-Dateien in SQL Server nicht unterstützt. Um zu prüfen ob die Komponente bereits installiert ist, führen wir folgenden Code im Abfragefenster des SQL Server Management Studios einfach aus:
exec sp_help_fulltext_system_components 'filter' go SELECT document_type, path FROM sys.fulltext_document_types WHERE document_type = '.pdf'
Die erste Zeile liefert uns alle registrierten Komponenten vom Typ “filter”.
Wird nach der Ausführung vom “SELECT-Statement” kein Datensatz geliefert, muss der sogenannte “PDF iFilter” installiert werden. Die Installationsdatei kann von hier heruntergeladen werden. Die Dokumentation für die Konfiguration des “iFilter” befindet sich hier. “iFilter” funktioniert auch mit SQL Server 2012.
Der “iFilter” dient dazu, große Mengen von PDF-Dokumenten zu indizieren, so dass bestimmte Inhalte schnell gefunden werden können.
Neuladen von Volltext-Filter nach der Installation des “iFilter”
Nach der Installation des “iFilter” müssen wir die Änderungen der Serverinstanz mitteilen, weil diese nicht automatisch wirksam werden.
Zum Laden neu installierter Filter in die Serverinstanz benutzen wir folgenden Code:
exec sp_fulltext_service 'load_os_resources', 1
Standardmäßig werden nur vertrauenswürdige signierte Binärdateien geladen. Um dieses Verhalten zu deaktivieren, verwenden wir folgenden Befehl:
exec sp_fulltext_service 'verify_signature', 0
Volltext-Index anlegen, mit Dokumententyp verbinden, aktivieren und Index starten
Jetzt ist es an der Zeit den Volltext-Index zu erstellen:
DECLARE @indexName nvarchar(255) = (SELECT Top 1 i.Name from sys.indexes i Join sys.tables t on i.object_id = t.object_id WHERE t.Name = 'T_Documents' AND i.type_desc = 'CLUSTERED') PRINT @indexName --Primary Key!
Mit dem Dokumententyp zu verbinden:
EXEC sp_fulltext_table 'T_Documents', 'create', 'ft_Catalog_pdf', @indexName EXEC sp_fulltext_column 'T_Documents', 'Document', 'add', 0, 'Document_Type'
Den Index zu aktivieren:
EXEC sp_fulltext_table 'T_Documents', 'activate'
Und den Index zu starten:
EXEC sp_fulltext_catalog 'ft_Catalog_pdf', 'start_full' ALTER FULLTEXT INDEX ON [dbo].[T_Documents] ENABLE ALTER FULLTEXT INDEX ON [dbo].[T_Documents] SET CHANGE_TRACKING = AUTO
Füllen der Tabelle mit PDF-Dokumenten
In einem Test haben wir sieben Dokumente aus unseren DeltaMaster clicks! in einem Ordner gespeichert und mit Hilfe von folgendem Code in die Tabelle “T_Documents” importiert:
Declare @i int Declare @sql varchar(max) Set @i = 1 While @i < 8 begin Set @sql = 'INSERT INTO T_Documents(Document_Name, Document_Type, Document) SELECT ''DeltaMaster_clicks!_2010-0' + Cast(@i as varchar(1)) + ''' AS DocumentName ,''.pdf'' AS DocumentExtension , * FROM OPENROWSET(BULK ''C:\_Ablage\DeltaMaster_Clicks\DeltaMaster_clicks!_2010-0' + Cast(@i as varchar(1)) + '.pdf'', SINGLE_BLOB) AS Document;' exec (@sql) Set @i = @i + 1 end
Erklärungsbedürftig ist der Befehl OPENROWSET, der BULK-Rowsetanbieter verwendet, um Daten aus einer Datei zu lesen und mit dem Parameter “SINGLE_BLOB” den Inhalt der Datei als einzeiliges, einspaltiges “Rowset” vom Typ “varbinary(max)” zurückgibt.
Zur Kontrolle führen wir folgende Select-Anweisung aus:
SELECT * FROM dbo.T_Documents
Das Ergebnis:

Abb. 4: T_Documents
In diesem ersten Teil der Volltextsuche schauen wir uns einen einfachen Suchvorgang an:
SELECT d.* FROM dbo.T_Documents d WHERE Contains(d.Document, '%spannweiten%')
Bei Spalten mit zeichenbasierten Datentypen wird ein sogenanntes “Prädikat”, hier “CONTAINS”, in der WHERE-Klausel verwendet. “CONTAINS” durchsucht solchen Spalten nach genauen oder ungefähren Treffern. In unserem Fall suchen wir in den sieben PDF-Dateien nach dem Begriff “Spannweiten”. Als Resultat liefert uns die Datenbank:
![]()
Abb. 5: T_Documents
Im nächsten Blogbeitrag schauen wir uns weitere Volltextprädikate und Suchoptionen an. Lassen Sie sich überraschen.
