Wie bereits im Blogbeitrag „Konvertierung von Excel-Kreuztabellen“ erwähnt, kommt es in BI-Projekten immer wieder vor, dass Quelldaten in einem Format zur Verfügung gestellt werden, welches das sofortige Weiterverarbeiten erschwert bzw. unmöglich macht. So trifft man häufig auf Tabellenstrukturen, in denen die Werte, die später als Kennzahlen analysiert werden sollen, nicht spaltenweise sondern zeilenweise abgelegt sind, d. h. die eigentlichen Werte sind in nur einer Spalte gespeichert und die restlichen Spalten beschreiben diese Werte. Folgende Abbildung zeigt eine solche Tabelle mit dem Namen „T_Import_Umsatz_Liste“.
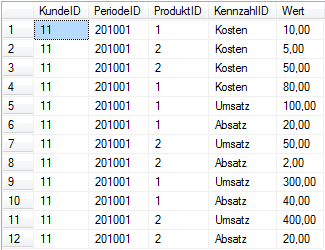
Hier werden verschieden Kennzahlen zeilenweise aufgeschlüsselt nach Kunden, Periode und Produkten dargestellt. Um was für eine Kennzahl es sich jeweils handelt, ist aus der Spalte „KennzahlID“ ersichtlich. Für eine Weiterverarbeitung der Daten im ImportWizard wäre dieses Format ausreichend, die Kennzahlen im Modell werden dann als eigene Dimension abgebildet. Dies ist vor allem bei gleichartigen Daten sinnvoll, wie zum Beispiel bei Bilanz- oder GuV-Daten.
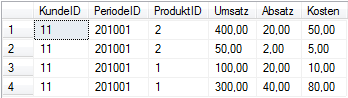
Möchte man die Kennzahlen jedoch explizit als Measures abbilden, müssen die Werte spaltenweise abgelegt sein. Auch für die Speicherung der Daten in den SQL Server Analysis Services (SSAS) wird dieses Format benötigt. Die folgende Abbildung zeigt die Daten der obigen Tabelle im gewünschten Format.
Der PIVOT-Operator
Bis zur Version 2005 des SQL Servers war bei der Nutzung des T-SQL Sprachschatzes das Umwandeln einer Tabelle mit einer flachen Ergebnismenge (Abbildung 1) in eine Kreuztabelle (Abbildung 2) eine echte Herausforderung. Hierfür nutze man oft verschachtelte Unterabfragen oder behalf sich mit temporären Tabellen. Seit der Version 2005 des SQL Servers steht nun der PIVOT-Operator zum Erstellen von Kreuztabellen zur Verfügung. Die Syntax lautet:
select
<Spalte1>,
<Spalte2>,
<Spalte3>,
...
from
<Quelltabelle>
PIVOT
(
<Aggregatfunktion>(<Wertspalte>)
FOR <Kennzahlenspalte>
IN (<Spaltenliste>)
) <Alias>
Umgesetzt auf unser obiges Beispiel würde das SQL-Statement folgendermaßen aussehen:
select
KundeID,
PeriodeID,
ProduktID,
Umsatz,
Absatz,
Kosten
from
dbo.T_Import_Umsatz_Liste p
PIVOT
(
sum(Wert)
FOR KennzahlID
IN (Umsatz,Absatz,Kosten)
) as pvt
Das Ergebnis der Abfrage wird in nachstehender Abbildung gezeigt:

Der PIVOT-Operator setzt den Inhalt der angegebene Spalte „KennzahlID“ um, indem er die eindeutigen Werte dieser Spalte (Umsatz, Absatz, Kosten) in Spalten der Ausgabe umwandelt und dabei, entsprechend des angegebenen Operators, die Werte aus der Spalte „Wert“ aggregiert. Die Aggregation der Daten hat den positiven Nebeneffekt, dass die Anzahl der Datensätze enorm reduziert werden kann.
Der UNPIVOT-Operator
Für den Fall, dass man eine Kreuztabelle in eine Tabelle mit einer flachen Ergebnismenge (zurück) verwandeln möchte, existiert ebenfalls seit der Version 2005 des SQL Servers der UNPIVOT-Operator. Seine Syntax lautet:
select
<Spalte1>,
<Spalte2>,
<Spalte3>,
...
from
<Quelltabelle>
UNPIVOT
(
<Wertspalte>
FOR <Kennzahlenspalte>
IN (<Spaltenliste>)
) <Alias>
Bezogen auf unser Beispiel lautet das SQL-Statement:
select
KundeID,
PeriodeID,
ProduktID,
KennzahlID,
Wert
from
dbo.T_Import_Umsatz_Kreuztabelle p
UNPIVOT
(Wert FOR KennzahlID IN (Umsatz,Absatz,Kosten)) as pvt
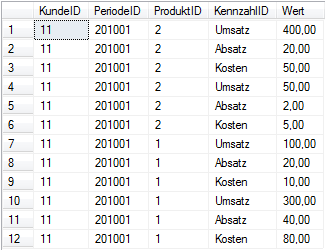
Das Ergebnis der Abfrage wird in der folgenden Abbildung gezeigt, es entspricht der obigen Quelltabelle aus Abbildung 1:
Einschränkungen
Bei der Aggregation der Daten mit dem PIVOT-Operator werden Daten, welche den Wert NULL enthalten, bei der Berechnung der Aggregate nicht berücksichtigt. Das würde im obigen Beispiel kein Problem darstellen, da ein NULL-Wert zum Beispiel im Umsatz nicht zu Erhöhung des selbigen führen würde. Möchte man aber statt der Summe die Anzahl der Datensätze über die Funktion „Count“ ermitteln, hat das möglicherweise einen Einfluss auf das Ergebnis.
Eine weitere Einschränkung besteht hinsichtlich der Dynamik der Inhalte der Quelltabellen. Gemeint ist damit nicht eine Änderung der Datensatzanzahl, sondern das Hinzukommen weiterer Kennzahlen in der Spalte „KennzahlID“. Das hätte zur Folge, dass das SQL-Statement in der Spaltenliste entsprechend erweitert werden müsste, um eine zusätzliche Spalte mit dem Inhalt der neuen Kennzahl an die resultierende Kreuztabelle anzufügen.
Um das händische Anpassen des SQL-Statements zu vermeiden, könnte man eine Prozedur erstellen, welche den Inhalt der Kennzahlenspalte der Quelltabelle abfragt und anschließend dynamisch ein SQL-Statement erzeugt und in einer Sicht abspeichert.
Eine solche Prozedur könnte den folgenden Inhalt haben und wird hier unter dem Namen „P_BC_Create_Pivot_View“ gespeichert:
create proc [dbo].[P_BC_Create_Pivot_View]( @SourceTable varchar(100),-- Tabelle, welche umgewandelt werden soll @DestinationView varchar(100),-- Name der zu erstellenden View @MeasureColumnName varchar(50),-- Spalte der Kennzahlen @ValueColumnName varchar(50) -- Spalte der Beträge (Werte) )as Declare @Column varchar(100), @Measure varchar(100), @sql_str_Column varchar(max), @sql_str_Measure varchar(max), @sql_str_exec varchar(max) -- Spaltencursor DECLARE Column_cursor CURSOR FOR SELECT col.Name from dbo.syscolumns col, dbo.sysobjects obj WHERE col.ID = obj.ID AND obj.Name = @SourceTable AND col.Name <> @MeasureColumnName AND col.Name <> @ValueColumnName OPEN Column_cursor FETCH NEXT FROM Column_cursor INTO @Column SET @sql_str_Column = '' WHILE @@FETCH_STATUS = 0 BEGIN set @sql_str_Column = @sql_str_Column + ' ' + @Column + ',' FETCH NEXT FROM Column_cursor INTO @Column END CLOSE Column_cursor DEALLOCATE Column_cursor
— temporäre Tabelle löschen
if exists (select * from dbo.sysobjects where name='_T_Temp_Measure') drop table _T_Temp_Measure
— temporäre Tabelle anlegen
create table _T_Temp_Measure([Measure] [varchar] (100)) Declare @sql_str_temp varchar(4000) set @sql_str_temp = 'Select distinct '+ @MeasureColumnName + ' from ' + @SourceTable+' where ' + @MeasureColumnName + ' is not null'
— temporäre Tabelle füllen
insert into _T_Temp_Measure(Measure) exec(@sql_str_temp) -- Measurecursor DECLARE Measure_cursor CURSOR FOR SELECT Measure FROM _T_Temp_Measure OPEN Measure_cursor FETCH NEXT FROM Measure_cursor INTO @Measure set @sql_str_Measure = '' WHILE @@FETCH_STATUS = 0 BEGIN set @sql_str_Measure = @sql_str_Measure + ' ' + @Measure + ',' FETCH NEXT FROM Measure_cursor INTO @Measure END CLOSE Measure_cursor DEALLOCATE Measure_cursor
— letztes Komma entfernen
set @sql_str_Measure = left(@sql_str_Measure, len(@sql_str_Measure)-1)
— Löschen der View, falls vorhanden
Declare @sql_str_drop varchar(100) if exists (select * from dbo.sysobjects where name = @DestinationView) Begin set @sql_str_drop = 'drop view ' + @DestinationView exec (@sql_str_drop) End
— SQL zusammensetzen
SET @sql_str_exec =
'create view ' + @DestinationView + ' as
select' +
@sql_str_Column +
@sql_str_Measure + '
from
' + @SourceTable + '
PIVOT
(sum(' + @ValueColumnName + ') FOR ' + @MeasureColumnName + '
IN (' + @sql_str_Measure + ')) as pvt'
exec (@sql_str_exec)
Der Aufruf der Prozedur bezogen auf unser obiges Beispiel lautet:
[code lang="sql"]
exec P_BC_Create_Pivot_View
@SourceTable = 'T_Import_Umsatz_Liste',
@DestinationView = 'V_Import_Umsatz_Liste',
@MeasureColumnName = 'KennzahlID',
@ValueColumnName = 'Wert'
Als Ergebnis erhält man eine Sicht, welche das dynamisch erzeugte SQL-Statement enthält.
ALTER view [dbo].[V_Import_Umsatz_Liste] as
select
KundeID,
PeriodeID,
ProduktID,
Absatz,
Kosten,
Umsatz
from
T_Import_Umsatz_Liste
PIVOT
(sum(Wert) FOR KennzahlID
IN (
Absatz,
Kosten,
Umsatz)) as pvt
Die vorgestellten Scripte, inklusive der Beispieldatenbank, befinden sich auf der Blog-Seite.
