In der Datenbankprogrammierung muss gelegentlich eine Tabelle mit sich selbst verbunden werden. Beispielsweise müssen Vorgänger- oder Nachfolger gefunden werden, um anschließend Berechnungen auf Grundlage dieser Informationen durchzuführen. Mit Hilfe eines so genannten Self Joins, der eine Datenbanktabelle mit sich selbst verbindet, kann eine Nachfolgersuche durchgeführt werden.
Dieser Blogbeitrag zeigt am Beispiel der Nachfolgersuche wie ein Self Join grundsätzlich erstellt wird, anschließend wird eine leistungsfähige Variante mit Hilfe von Tabellenausdrücken (Common Table Expres-sions (CTE)), Partitionen und Rangfolgefunktionen gezeigt. Die Beispiele beziehen sich auf die Tabelle „promotion“ aus der Microsoft Beispiel Datenbank „Foodmart“. Die Tabelle enthält 1.864 Datensätze.
Entwicklung eines Self Joins zur Nachfolgersuche
Für die Nachfolgersuche wird in diesem Beispiel aus Gründen der Veranschaulichung angenommen, dass je Gebiet immer nur eine Werbeaktion zur gleichen Zeit stattfindet. Daraus ergibt sich, dass das Startdatum einer nachfolgenden Aktion immer nach einem Enddatum einer vorhergehenden liegt.
Alle Nachfolger
Sollen der erste und der letzte Datensatz bei der Nachfolgersuche ebenfalls dargestellt werden, so ist beim Self Join ein Left Join zu verwenden, da es keinen Vorgänger bzw. Nachfolger gibt; ein Join würde somit keinen Treffer zurückgeben.
Das folgende SQL-Statement liefert zu einer Werbeaktion alle nachfolgenden Aktionen innerhalb eines Gebiets, also noch nicht das gewünschte Ergebnis.
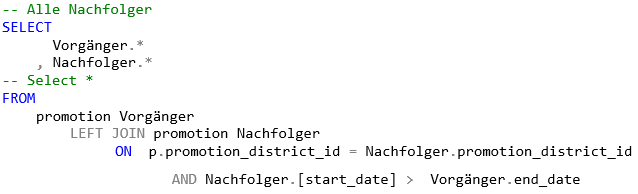
-- Alle Nachfolger
SELECT
Vorgänger.*
, Nachfolger.*
-- Select *
FROM
promotion Vorgänger
LEFT JOIN promotion Nachfolger
ON p.promotion_district_id = Nachfolger.promotion_district_id
AND Nachfolger.[start_date] > Vorgänger.end_dateDirekter Nachfolger
Damit ausschließlich die nachfolgenden Werbeaktionen geholt werden, muss der Left Join um eine Bedingung erweitert werden. Dazu wird innerhalb eines Subselects das erste Startdatum einer Aktion ermittelt, dass nach dem Enddatum der vorhergehenden Aktion liegt.

-- Direkter Nachfolger
SELECT
p.promotion_district_id
,p.promotion_id
,p.promotion_name
,p.[start_date]
,p.end_date
,DATEDIFF("DAY", p.end_date, Nachfolger.[start_date]) AS DaysToNextPromotion
,Nachfolger.promotion_id
,Nachfolger.promotion_name
,Nachfolger.[start_date]
,Nachfolger.end_date
-- Select *
FROM
promotion p
LEFT JOIN promotion Nachfolger
ON Nachfolger.promotion_district_id = p.promotion_district_id
AND Nachfolger.[start_date] = ( -- get min start date
SELECT MIN(p2.[start_date])
FROM promotion p2
WHERE p2.[start_date] > p.end_date
AND p2.promotion_district_id = p.promotion_district_id
)
ORDER BY
p.promotion_district_id
,p.[start_date]
,Nachfolger.[start_date]Performance
Der aufmerksame Leser des oberhalb aufgeführten Statements wird bemerkt haben, dass die Tabelle „promotion“ drei Mal verwendet wird. Der folgende Ausführungsplan wird bei der Ausführung erstellt:
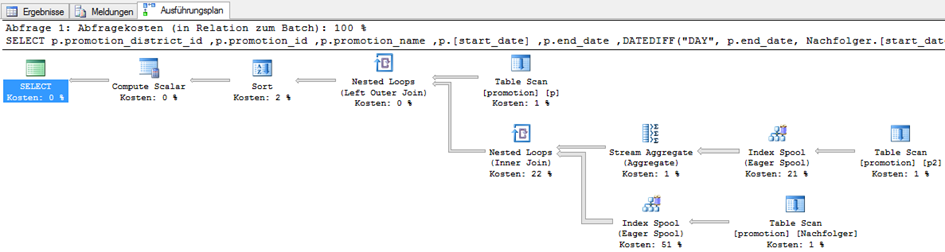
Abbildung 1: Ausführungsplan der Nachfolgersuche
Es ist deutlich zu erkennen, dass 51 % der Ausführungszeit für einen „Index Spool (Eager Spool)“ ver-wendet werden, 21 % für einem weiteren „Index Spool“ und 22 % für einen „Nested Loop“, zusammen also 94 % der Ausführungszeit.
Ein Index Spool legt einen temporären Index an, damit anschließende Operationen, in diesem Fall der Inner Join, schneller ausgeführt werden können. Aber wieso überhaupt ein Inner Join? Es wurde doch explizit ein Left Join verwendet.
Betrachtet man den Index Spool genauer, dann fallen zwei Punkte auf:
- Tatsächliche Anzahl von Zeilen: 144.622
- Anzahl von Ausführungen: 1.864

Abbildung 2: Erläuterung Index Spool aus dem Ausführungsplan der Nachfolgersuche
Woher kommt der Inner Join und warum wird für 144.622 Zeilen ein temporärer Index angelegt, wobei die Tabelle doch nur 1.864 Datensätze hat?
Das Subselect ist dafür verantwortlich, denn dort wird die Tabelle „promotion“ mit sich selbst über das Feld promotion_district_id verbunden. Das folgende Statement liefert genau die 144.622 Datensätze zurück:

SELECT COUNT(1)
FROM
promotion p
LEFT JOIN promotion Nachfolger
ON Nachfolger.promotion_district_id = p.promotion_district_idIn dem gesamten Subselect wird ein so genannter Triangular Join durchgeführt, welcher für Ausführungszeiten katastrophal ist. Weitere Informationen dazu hier:
http://www.sqlservercentral.com/articles/T-SQL/61539/
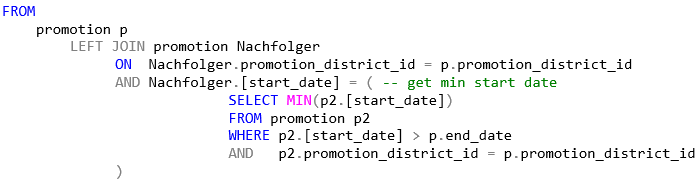
FROM
promotion p
LEFT JOIN promotion Nachfolger
ON Nachfolger.promotion_district_id = p.promotion_district_id
AND Nachfolger.[start_date] = ( -- get min start date
SELECT MIN(p2.[start_date])
FROM promotion p2
WHERE p2.[start_date] > p.end_date
AND p2.promotion_district_id = p.promotion_district_id
)Entwicklung einer leistungsfähigen Nachfolgersuche
Unter Verwendung aktueller Möglichkeiten von Transact SQL kann eine sehr elegante und schnelle Datenbankabfrage für eine Nachfolgersuche erstellt werden. Betrachten wir das Ergebnis in zwei Schritten.
Partitionen und Tabellenausdrücke
Zunächst werden über eine Over-Klausel Partitionen über die promotion_district_id gebildet, die Spalte über die der Self Join hergestellt wurde; Partitionen können wie Self Joins auch über mehrere Felder gebildet werden. Innerhalb einer Partition wird nach aufsteigendem Startdatum sortiert, damit später der direkte Nachfolger ermittelt werden kann. Schließlich wird jedem Datensatz auf Basis der genannten Kriterien über die Funktion ROW_NUMBER() eine fortlaufende Nummer zugewiesen (im Folgenden RowNum genannt). Diese Abfrage wiederum wird in einem Tabellenausdruck WITH gekapselt. Tabellenausdrücke haben den Vorteil, dass diese in aufbauenden Abfragen mehrfach verwendet werden können. Statt eines Tabellenausdrucks könnte auch eine View erstellt und im nächsten Statement verwendet werden, das Ergebnis wäre identisch.

-- 1) Partitionen mittels Partitionen für Nachfolgersuche erstellen
WITH wPromotion (PromotionDistrictID, PromotionID, PromotionName, StartDate, EndDate, RowNum) AS (
SELECT
p.promotion_district_id
,p.promotion_id
,p.promotion_name
,p.[start_date]
,p.end_date
,ROW_NUMBER() over (
partition by p.promotion_district_id
order by p.[start_date], p.end_date ASC
) AS RowNum
-- Select *
FROM
dbo.promotion p
)Verwendung des Tabellenausdrucks zur Nachfolgersuche
Der oben erstellte Tabellenausdruck kann nun in einer aufbauenden Abfrage in der gleichen View verwendet werden. Der Self Join wird weiterhin über die promotion_distirct_id hergestellt, aber zusätzlich noch über die RowNum. Der Nachfolger eines Datensatzes ist die folgende RowNum. Und schon ist eine sehr schnelle und einfache Nachfolgersuche erstellt.

-- 2) Datenaufbereitung und Kennzahlenberechnung
SELECT
p.PromotionDistrictID
,p.PromotionID
,p.PromotionName
,p.StartDate
,p.EndDate
,DATEDIFF("DAY", p.EndDate, Nachfolger.StartDate) AS DaysToNextPromotion
,Nachfolger.PromotionID
,Nachfolger.PromotionName
,Nachfolger.StartDate
,Nachfolger.EndDate
-- Select *
FROM
wPromotion p
LEFT JOIN wPromotion Nachfolger
ON Nachfolger.PromotionDistrictID = p.PromotionDistrictID
AND Nachfolger.RowNum - 1 = p.RowNumBetrachtung des Ausführungsplans
Der Ausführungsplan aus dieser Nachfolgersuche zeigt, dass kein Index Spool mehr notwendig ist. Die höchsten Kosten hat nun ein Merge Join mit 60 %, der die Zeilen aus zwei sortierten Eingabetabellen verbindet und gemäß der Sortierreihenfolge abgleicht. Besonders auffällig sind die beiden bereits bekannten Punkte:
- Tatsächliche Anzahl der Zeilen: 1.864
- Anzahl der Ausführungen: 1
Was bedeutet das nun? Bereits nach einer Ausführung steht das Ergebnis und es sind exakt so viele Zeilen betroffen, wie die Ausgangstabelle beinhaltet. Dadurch wird gerade bei Tabellen mit vielen Datensätzen sehr schnell ein Ergebnis zurückgeliefert.

Abbildung 3: Ausführungsplan der leistungsfähigen Nachfolgersuche
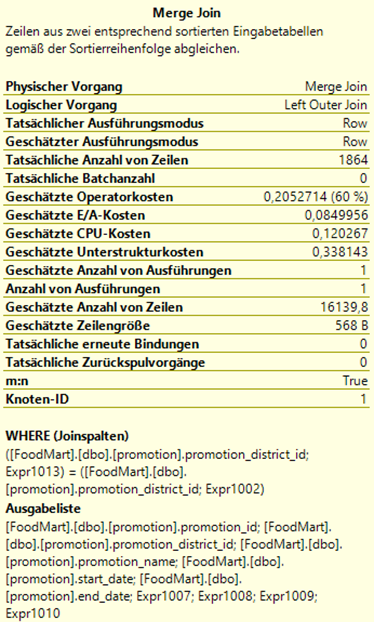
Abbildung 4: Erläuterung Merge Join aus der performanten Nachfolgersuche
