Bereits 2007 haben wir uns in einem Blogbeitrag Gedanken gemacht, wie lange OLAP-Datenbanken wohl noch überleben werden. Im Zeitalter des DeltaMaster ImportWizzard kommt man auch tatsächlich ab und an ins Grübeln, wozu man diese Form der Datenbanken überhaupt noch benötigt. Bei genauer Betrachtung findet man aber schnell zahlreiche Gründe, warum wir immer noch lieber Würfel als Tabellen bauen. Neben dem deutlich schnelleren Aggregationsverhalten einer multidimensionalen Datenbank zählt auch die MDX-Zeitintelligenz nach wie vor zu den Pluspunkten. Relational Kumulieren beispielsweise erzeugt bei einem T-SQL-Programmierer nach wie vor ein flaues Gefühl in der Magengegend.
2012 ist jetzt auch Microsoft auf die Idee gekommen und sagt ihrer eigenen OLAP-Datenbank den Kampf an. Mit dem neuen „Tabular Mode“ und der Abfragesprache DAX des SQL Servers 2012 gibt Microsoft ein deutliches Statement für relationale Datenbanken ab. Im Zuge dessen wurden auch Implementierungslücken bereits existierender T-SQL-Befehle behoben, so dass künftig eine relationale Kumulation einem Programmierer nur noch ein müdes Lächeln ins Gesicht zaubern wird.
Wenn Sie wissen wollen wie, dann folgen Sie mir einfach auf dem Weg zum Ende des Regenbogens…
Eigentlich ein alter Hut
Mit der SQL-Server-Version 2005 hat Microsoft einen Befehl eingeführt, der zu dem Zeitpunkt aber meiner Meinung nach noch nicht komplett fertig programmiert war. Die Rede ist hier von der OVER-Klausel. Ein Blick in das Microsoft Developer Network der zugehörigen Version erklärt auch klar den Zweck der Funktion. Dort heißt es:
„Bestimmt die Partitionierung und Reihenfolge des Rowsets vor der Anwendung der zugehörigen Fensterfunktion.“
Klar, oder…
Tatsächlich werden die in Zusammenhang mit OVER angewendeten Funktionen im Englischen „Window functions“ genannt. Allerdings hilft auch dies nicht sonderlich zum Verständnis des Befehls.
In der Sprachreferenz des SQL Servers 2012 hat man ein paar Zeilen mehr spendiert, die schon ein wenig mehr erahnen lassen:
„Bestimmt die Partitionierung und Reihenfolge eines Rowsets vor der Anwendung der zugehörigen Fensterfunktion. Demnach definiert die OVER-Klausel ein Fenster oder eine benutzerdefinierte Reihe von Zeilen innerhalb eines Abfrageresultsets. Eine Fensterfunktion berechnet dann einen Wert für jede Zeile im Fenster. Sie können die OVER-Klausel mit Funktionen verwenden, um aggregierte Werte wie gleitende Durchschnitte, kumulierte Aggregate, laufende Gesamtbeträge oder Ergebnisse vom Typ “Erste n pro Gruppe” berechnen.“
Der entscheidende Teil ist „…ein Fenster… von Zeilen innerhalb des Abfrageresultsets…“. Es geht also tatsächlich um Fenster im wortwörtlichen Sinne. Man kann mit der Funktion Fenster in seinem Abfrageergebnis definieren und auf diese Fenster wiederum Aggregatfunktionen anwenden. Klingt immer noch abstrakt, wir haben da mal etwas vorbereitet.
Regenbogenstreifen Nummer 1 – x
Zunächst legen wir uns in einer neuen Datenbank mal eine Tabelle an und füllen diese mit Umsatzdaten. Folgendes Skript sollte Ihnen die Arbeit etwas erleichtern:
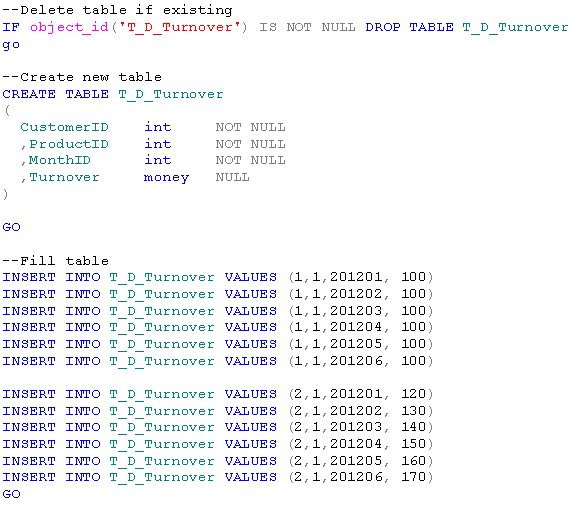
Die erste Anwendung, die mir beim SQL Server 2005 damals im Zusammenhang mit OVER untergekommen ist, war die Möglichkeit jetzt endlich auch im SQL Server Zeilennummern in einer Abfrage generieren zu können. Eine kleine Sensation – die Oracle-Fangemeinde war schockiert…
Um alle Zeilen in unserer Tabelle durchzunummerieren, benötigt man folgende Abfrage:

Das großartige Ergebnis sieht folgendermaßen aus:
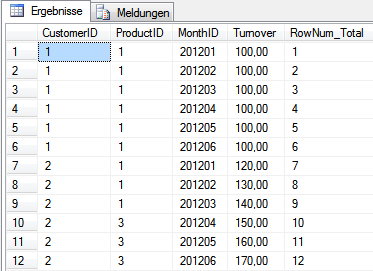
Die Zeilen werden also komplett durchnummeriert und nach dem Kriterium, welches hinter der OVER-Klausel in den Klammern mit ORDER BY definiert wurde, sortiert. ORDER BY kann dabei wie gewohnt angewendet werden und ein oder mehrere Spalten, sowie eine Sortierrichtung (ASC oder DESC) enthalten.
Wo ist jetzt aber das Fenster, werden Sie vermutlich einwenden?
Stimmt, noch gibt es keines.
Für die Definition der Fenster muss man den Befehl in den Klammern erweitern. Die Arbeit erledigt hier PARTITION BY. Damit kann man quasi die Fenster angeben, nach denen die Funktion neu rechnen soll. Ich teile also meine Abfrage in verschiedene Unterfenster. Im obigen Beispiel lassen wir uns jetzt mal zusätzlich die Zeilennummern innerhalb der jeweiligen Kundennummer ausgeben:

Ergebnis:
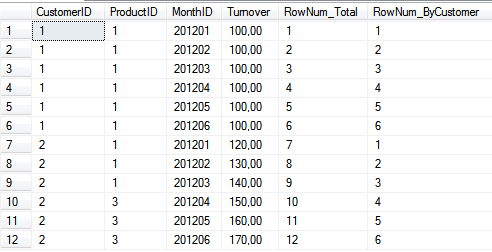

Das ist doch schon mal ziemlich hilfreich, wenn es um segmentspezifische Auswertungen geht und bildet auch tatsächlich die Grundlage für eine spätere Kumulation. Wir können irgendwie die Zähler zurückstellen (zum Beispiel an der Jahresgrenze) und können zeilenweise etwas zählen.
Soweit so gut.
Alle Streifen zusammen
Der fehlende Baustein ist jetzt das Summieren von gewissen Kennzahlen und tatsächlich ist in der Dokumentation im Zusammenhang mit der OVER-Klausel von Aggregatfunktionen die Rede.
Und tatsächlich – prüft man die Hilfe der Aggregatfunktionen wird dies bestätigt:
„Die OVER-Klausel kann auf alle Aggregatfunktionen außer CHECKSUM folgen.“
Das hieße für unser Beispiel, dass wir ROW_NUMBER() durch SUM() ersetzen können und hier selbstverständlich eine andere Spalte zum Summieren angeben können. Wir würden in unserem Beispiel den Umsatz verwenden.
Tja, doch leider weit gefehlt, führt man genau diese Ersetzung durch, behaupten alle SQL Server Versionen bis 2008R2, wir hätten einen Syntax-Fehler in unserer Abfrage.
Die einzige Variante, die bis zu diesen Versionen unterstützt wird, ist das Errechnen von Teilaggregaten, hier also Teilsummen. Dies kann man erzielen, indem man einfach den ORDER BY Teil der Abfrage weglässt und nur den PARTITION BY Teil anwendet. Das hilft auch schon weiter, um relationale Monatsanteile zu errechnen, beispielsweise für Verteilungsrechnungen. Hier spart man sich umfangreiche Unterabfragen. Im Folgenden ein paar Beispiele, um Zwischensummen zu errechnen:

Ergebnis:
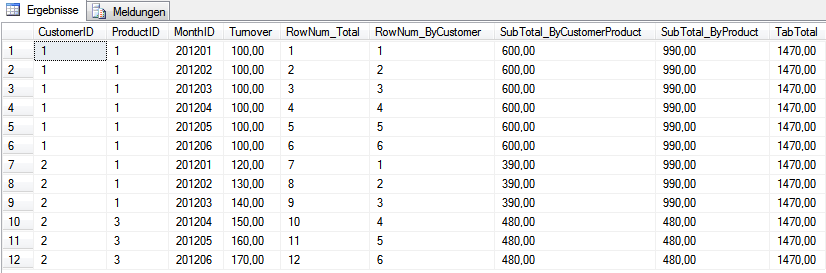
Die erste Zwischensumme zeigt dabei die Summe pro Kunde und Produkt und gibt damit für jede Kunde-Produkt-Kombination eine andere Summe aus. Die zweite Summe zeigt die Summe pro Produkt und gibt damit nur zwei unterschiedliche Summen aus. Die letzte Variante ganz ohne PARTITION BY zeigt die komplette Tabellensumme.
Das Ende des Regenbogens
Der Trick, um eine echte, zeilenweise Kumulation zu erreichen, ist tatsächlich nur der Wechsel auf die SQL-Server-Version 2012. Kopiert man dort unsere ROW_NUMBER-Befehle und ersetzt diese durch SUM(Turnover) funktionieren diese einwandfrei und liefern das gewünschte Ergebnis. Hier die komplette Wegbeschreibung zum Ende des Regenbogens:

Das Ergebnis sieht märchenhaft aus:
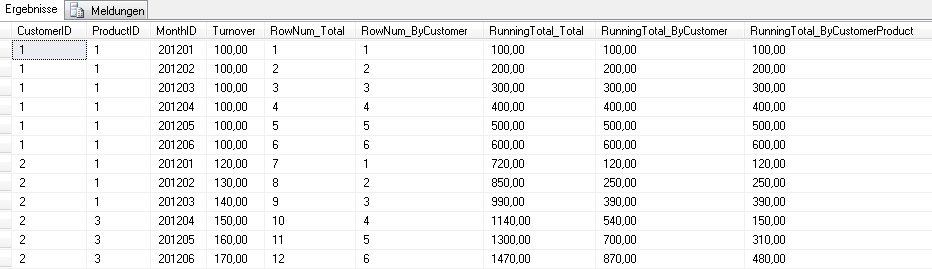
Über die Optionen können wir also frei steuern, wie und in welcher Reihenfolge wir kumulieren wollen. Damit haben wir alles was wir brauchen. Und das Beste dran – die Berechnung ist sogar sehr schnell.
Damit haben wir tatsächlich unser sagenumwobenes Ziel erreicht. Und wenn man genau hinsieht, findet man am Ende des Regenbogens sogar noch einen echten Schatz. Microsoft hat nämlich noch einen draufgesetzt und mit der Version dieses Jahres sogar noch den Funktionsumfang der „Fensterfunktionen“ erweitert. In dem MSDN liest man von LEAD und LAG! Das kennen wir doch auch irgendwo her – wenn da nicht mal das Dekumulieren vereinfacht wurde…
