Dieser Beitrag zeigt eine Möglichkeit, ein integriertes Stammdaten-Reporting aufzubauen. Dabei geht es darum, sich verändernde Eigenschaften von Dimensionselementen darzustellen. Wir betrachten die relationale Speicherung und Modellierungstricks bis hin zum DeltaMaster-Bericht (in Form einer Pivottabelle)
Im Verlauf vieler BI-Projekte mit langlebigen Anwendungen stellt man fest, dass sich Eigenschaften von Dimensionselementen mit der Zeit verändern. Zum Beispiel ändert sich die Zuordnung eines Produkts zu der übergeordneten Produktgruppe, Kostenstellen werden einem anderen Bereich zugeordnet oder der Status von Beleginformationen wechselt. Bei derartigen Fällen verwenden wir bisher den letzten bekannten Stand der Eigenschaft für den Aufbau der betroffenen Dimension.
Durch die attributbasierte Modellierung in Microsofts Analysis-Services-Datenbanken (kurz: SSAS) können wir Eigenschaften in DeltaMaster wie separate Merkmale darstellen und für den Anwender filterbar machen. Allerdings bedeutet das auch, dass auf den aggregierten Ebenen eigentlich falsche Sachverhalte dargestellt werden, wenn wir unsere Berichte mit Vorjahres- oder Vorperiodenabweichungen aufbauen – zum Beispiel bei Produktgruppen: Der Wert einer Produktgruppe A im Vorjahr wird eigentlich für eine andere Menge von Produkten berechnet, wenn sich deren Zuordnung geändert hat. Tatsächlich verhält sich der Filter so, als ob sich die Produktgruppe im Vorjahr aus allen Produkten des heutigen Stands zusammensetzt.
Ein Lösungsansatz ist, das gewünschte Merkmal zu duplizieren, die Bewegungsdaten zu verbreitern und eine separate Dimension zu modellieren, die oft den Zusatz „historisch“ in der Bezeichnung erhält. Ein alternativer Ansatz ist die Verwendung einer Schalterdimension mit Ausprägungen wie „historisch“ und „aktuell“. Anschaulich beschrieben haben wir diese Variante in einem früheren Beitrag zu zeitabhängigen Merkmalen (Historisierung).
Im vorliegenden Beitrag möchten wir eine weitere Alternative vorstellen: ein separates Berichtswesen über die Änderung der Stammdaten, integriert in einer OLAP-Anwendung nur mit Hilfe einer Pivottabelle und ohne neue Kennzahlen, verdoppelte oder verbreiterte Daten im Backend.
Ziel
Die zentrale Fragestellung lautet: Welche Eigenschaft hat sich wann und von welchem zu welchem Wert verändert? Die Lösung soll für den Anwender möglichst einfach zu bedienen und in eine bereits vorhandene zentrale DeltaMaster-Anwendung integrierbar sein. Dabei sollen die Stammdaten separat gefiltert und bei Bedarf nur die Änderungen von Eigenschaften komfortabel in Pivottabellen analysiert werden können.
Voraussetzung
Die Stammdaten werden historisiert im Data Warehouse (DWH) gespeichert. Die Änderungen werden nach dem Konzept von Slowly Changing Dimensions (SCD) Typ 1 oder 2 beibehalten. Den Prozess zu Import und Speicherung der Veränderungen klammern wir in diesem Beitrag aus, stellen ihn aber auf Nachfrage gern bereit.
Lösung
Die Lösung besteht im Grundsatz aus drei Komponenten:
- Für die gewünschte Stammdaten-Dimension muss eine separate Dimension erstellt werden.
- Für jede gewünschte Filterung müssen separate Attributhierarchien erstellt werden.
- Für die komfortable Darstellung der Veränderungen als Pivotbericht muss das Stammdatenmerkmal als Parent-Child-Dimension definiert sein.
Speicherung im Datawarehouse
Werfen wir zunächst einen Blick auf die Datenlage, wie in der Voraussetzung beschrieben: Wir betrachten also die gespeicherten Stammdateninformationen am Beispiel einer zweistufigen Kundendimension im Datenbanksystem.
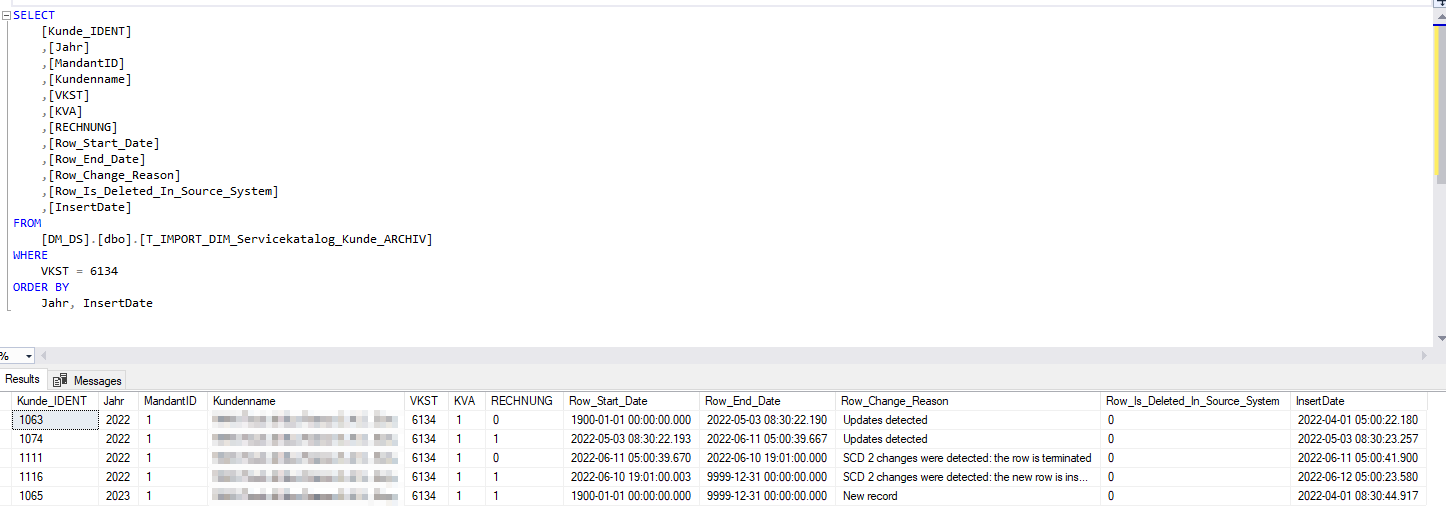
Abbildung 1: Auszug aus Archivtabelle im DWH
In der Abbildung 1 sehen wir ein Beispiel von Kundenstammdaten und deren historisierte Ablage im DWH. Sobald neue Daten geliefert werden (Spalte InsertDate) wird eine Zeile für den betroffenen Kunden eingefügt. Dabei werden die Spalten Row_Start_Date und Row_End_Date aktualisiert. Bei einer Änderung vom SCD-Typ 2 wird die existierende Zeile mit dem InsertDate des neuen Datensatzes in der Spalte Row_End_Date beendet. Zu Informationszwecken wird zusätzlich der Row_Change_Reason in der Datenbank gespeichert.
Hinweis: Die Spalte Kunde_Ident ist nicht der Kundenschlüssel, sondern lediglich eine fortlaufende Nummerierung der Datensätze, notwendig für die Funktionalität der Archivierungsprozedur.
Das Beispiel oben zeigt, dass im Jahr 2022 vier Änderungen für den Kunden „6134“ (VKST) stattgefunden haben:
- Am 01.04.2022 wurde der Kunde in das System eingespielt.
- Am 03.05.2022 wurde der Kunde zur Rechnungsstellung markiert (Spalte „Rechnung“).
- Am 11.06.2022 wurde die Markierung wieder zurückgenommen.
- Am 12.06.2022 wurde die vorherige Änderung erneut zurückgenommen.
Die Zeile 5 ist für den Sachverhalt nicht relevant, da wir nur die Änderungen innerhalb eines Jahres berücksichtigen. Erst mit Beginn der Planungsphase werden Änderungen an Stammdaten auch für Folgejahre (hier: 2023) relevant.
Genau diese Änderungen sollen für den Anwender in DeltaMaster korrekt abgebildet werden.
Aufbereitung (Logik)
Basierend auf der Tabelle in Abbildung 1 erzeugen wir eine Sicht, die die notwendige Parent-Child-Struktur, die Änderungen, spätere Filterkriterien und Zuordnungen erzeugt. Der grundlegende Aufbau besteht aus einer CTE, die zunächst über Kunde und Jahr partitioniert und über das Row_Start_Date absteigend sortiert wird. Zusätzlich werden Vorgänger und Nachfolger mithilfe der LEAD- und LAG-Funktion für die gewünschten Spalten jeweils als separate Spalte ausgegeben . Genaueres dazu beschreibt unser Beitrag „LEAD und LAG mit T-SQL“.
Die beiden folgenden Abschnitte der Sicht erzeugen die Parent- und Child-Elemente. Dabei werden diejenigen Spalten vervielfältigt, über die später in DeltaMaster separat gefiltert werden soll – hier also zum Beispiel die Spalte „Rechnung“ mit den Ausprägungen „ja“ und „nein“.
Da ein Anwender den Bericht nur nach Änderungen filtern können soll, erzeugt man mit Hilfe der IIF-Funktion und Vergleich mit den zuvor erstellten Vorgängern und Nachfolgern zusätzlich eine neue Spalte mit den Ausprägungen „Veränderung“ und „keine Veränderung“.
Änderungen vom Typ SCD können dadurch im Bericht inklusive der alten und neuen Information dargestellt werden. Bei SCD-Typ-1-Änderungen kann nur der aktuelle Wert berichtet werden, da es sich um eine Aktualisierung der gültigen Zeile handelt.
Das kann für beliebig viele Eigenschaften wiederholt werden.
Notwendige Modellbestandteile
Werfen wir jetzt einen Blick in die Modelldefinition: Wir definieren wie angekündigt zunächst eine neue Parent-Child-Dimension.
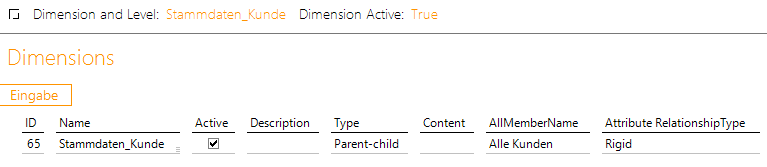
Abbildung 2: DM-ETL Definition Stammdatendimension
Warum Parent-Child? Im Ergebnis soll der Anwender später in DeltaMaster immer den aktuellen Stand (Parent) der Stammdaten sehen und bei Bedarf über beim Aufklappen eines Kunden die historischen Einträge (Child) dargestellt bekommen.
Die eigentliche Musik spielt in dem Bericht „Attributes“.
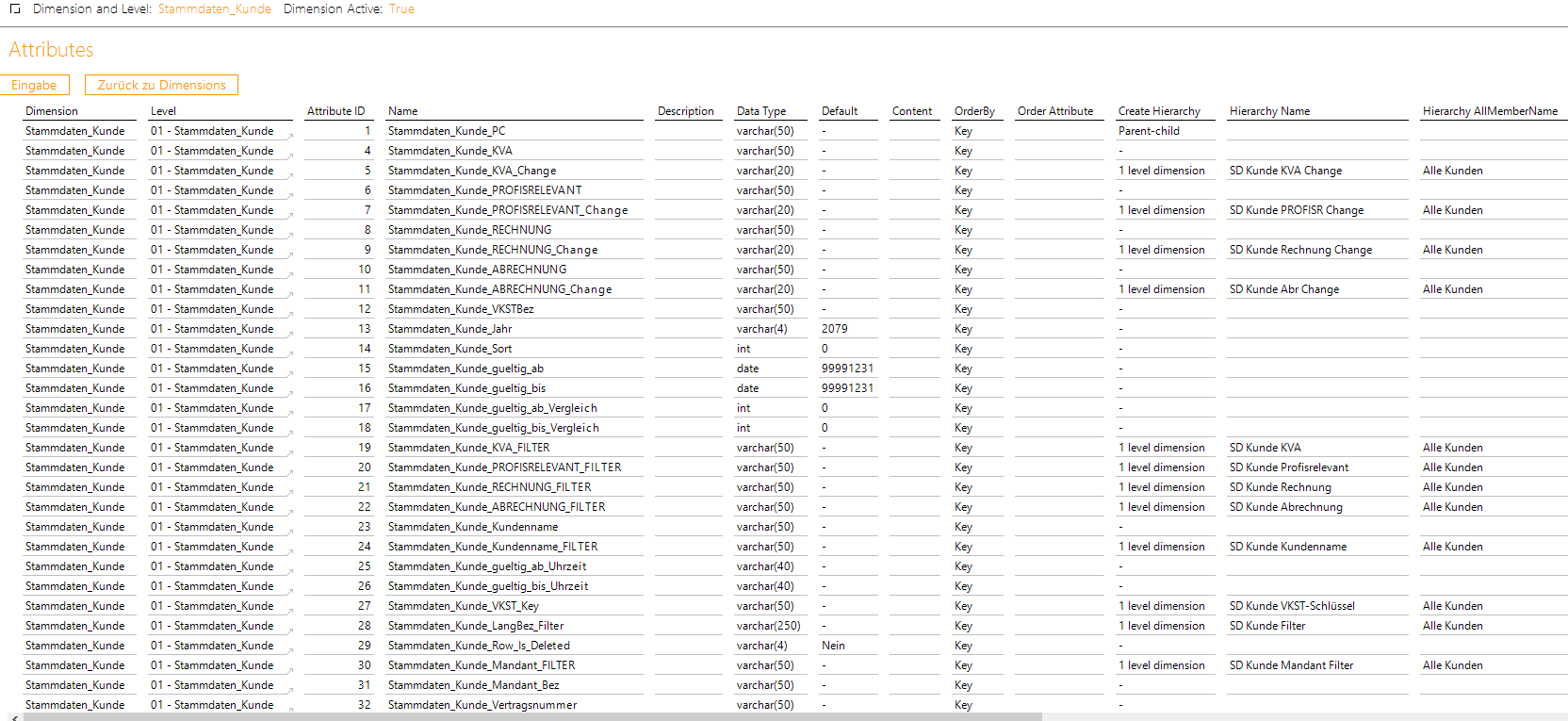
Abbildung 3: Notwendige Attributdefinitionen in DeltaMaster ETL
Die Abbildung 3 verdeutlicht, warum aus einer Quellinformation in der Logikschicht drei Spalten erzeugt werden: die erste als reine Eigenschaft für die Berichtsdarstellung, die zweite zur Filterung, ob es eine Veränderung gab, und die dritte als weitere Attributhierarchie, um die Ausprägung selbst filtern zu können.
Da es sich um ein separates Berichtswesen handelt, benötigen wir keine Zuweisung zu einer Measure Group, die Definition in DeltaMaster ETL bleibt also leer (vgl. Abbildung 4).
Abbildung 4: keine Dimensionszuordnung zu Measure Groups in DeltaMaster ETL
Da die Berichte Bestandteil der zentralen Anwendung sein sollen, müssen wir noch dafür sorgen, dass die Dimension in das OLAP-Modell eingefügt wird.

Abbildung 5: Einstellung zur Aktivierung der Stammdatendimension in der OLAP-Datenbank in DeltaMaster ETL
Eine separate Measure Group für die Stammdaten ist nicht erforderlich: Eine neue Kennzahl hätte zum einen keine Aussagekraft und wird im Bericht auch nicht benötigt.
Berichtswesen in DeltaMaster
In DeltaMaster sieht man im Ergebnis eine Pivottabelle, die über das +/-Symbol aufgeklappt werden kann und separat filterbar ist, mit einem definierten Absprung und ohne überflüssige Kennzahlen.

Abbildung 6: DeltaMaster-Bericht mit Übersicht der Kundeninformationen
Diesen Bericht können wir auf unseren Beispielkunden 6134 filtern, um uns die Veränderungen darstellen zu lassen.

Abbildung 7: Anzeige der Änderungen bei Kunde 6134 (SCD Typ 2)
Die Darstellung zeigt die reale Datenlage inklusive Gültigkeiten und tatsächlichen Werten zu dem jeweiligen Datenimport. Die Filterleiste zeigt bereits, dass der Anwender über verschiedene Möglichkeiten zur Eingrenzung verfügt:
- Filter über die Ausprägung (vgl. Abbildung 8)
- Filter über Veränderung einer Eigenschaft (vgl. Abbildung 9)

Abbildung 8: Filterdimension für Ausprägungen

Abbildung 9: Filterdimension für Veränderungen
Um weitere Eigenschaften anzuzeigen, genügt ein Klick auf die Verknüpfung des aktuellen Datensatzes. Wichtig zu wissen ist dabei, dass nicht alle Attribute und deren Änderungen auf die zuvor dargestellte Art modelliert wurden. Es gibt auch Eigenschaften, bei denen einzig der aktuelle Zustand relevant ist.

Abbildung 10: Darstellung zusätzlicher Eigenschaften des aktuellen Stammdatensatzes
Fazit
Wenn man eine Datenlage vorfindet, bei der man mit Fragen zu den Veränderungen von Eigenschaften konfrontiert ist, kann das beschriebene Vorgehen eine sinnvolle Alternative zu bisherigen Ansätzen sein. Allerdings ist anzumerken, dass durchaus zusätzliche Logik und Aufwand im Importprozess stecken, mit denen die Lösung nicht für jeden sinnvoll umsetzbar ist. Gerne klären wir Fragen dazu über unser Nachrichtenformular.
