In unserer schnelllebigen Welt ändern sich die Daten (Werte) so schnell, dass die große Herausforderung in der Aktualität dieser Daten liegt. Nun kennen wir dieses Thema praktisch in jedem Projekt und wie so oft gibt es diverse Lösungswege, die mehr oder weniger aufwendig und komplex zu implementieren sind. Eine Möglichkeit sich dem Problem zu nähern, ist der Einsatz einer Transformation im BI Development Studio (kurz: BIDS), dem Lookup-Task (Achtung: erst ab SQL-Server 2008 einsetzbar). Vereinfacht dargestellt bietet der Lookup-Task eine Art Veränderungslogik, sprich: was ändert sich wann, wie und wo. Da dieser Schritt, je nach Konfiguration, unterschiedlichste Komplexitäten annehmen kann, beginnen wir zunächst mit der einfachsten, trotzdem schon sehr nützlichen Variante. In einem zweiten Blogbeitrag werden wir dann dieses Projekt um weitere Funktionalitäten erweitern.
Als Szenario haben wir den Profisport mal näher betrachtet, hier sind Spielertransfers, Aufstellungen je Spieltag und Kontrolle des Trainingszustands sehr gut nachvollziehbare Beispiele für sich ändernde Daten. Der letztjährige Kader eines relativ erfolgreichen Handballclubs, der THW Kiel, dient hier als Quelle, Weihnachten und der Jahreswechsel als typischer Grund verschiedenster Veränderungen. Schauen wir uns mal unsere Ausgangsdaten an:

Nachdem die csv-Datei in die Tabelle T_Import_THW importiert wurde, kann der Lookup-Tasks (in der deutschen Toolbox zu finden als „Suche“) konfiguriert werden.
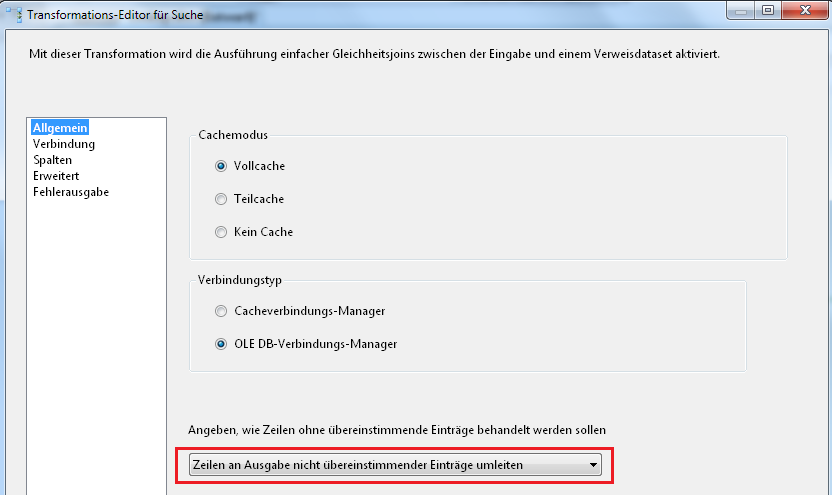
Zunächst ist die Einstellung von Cache-Modus und Vergleichsverhalten festzulegen.
Der Cache-Modus steuert, wann der Lookup ausgeführt wird:
Vollcache: Zu Beginn der Paketausführung übergibt der Lookup seine komplette Ergebnisliste (Kombinationen aus den Vergleichsspalten in der Verweistabelle) an den Cache (RAM). Kommen jetzt Datensätze aus dem Fileimport, werden diese nur noch gegen die Liste aus dem Cache verglichen. Es wird also nur ein Datenbankaufruf ausgeführt. Vorsicht jedoch bei wenig RAM-Speicher, dann schlägt der Lookup fehl.
Teilcache: Es wird jeder ankommende Datensatz zunächst gegen den Cache geprüft und bei Erfolg von hier geladen. Ist im Cache kein Eintrag zu dem Lookup-Key vorhanden, wird dieser Key mit in den Cache aufgenommen. Für eindeutige Tabellen also Unsinn.
Kein Cache: Jede Zeile einzeln löst das Lookup-Statement aus. Schnell bei kleinen Datenmengen, natürlich viele Abfragen gegen die Datenbank.
Bei der Festlegung des Vergleichsverhaltens wird eingestellt, wohin die Datensätze ohne Übereinstimmung umgeleitet werden. In unserem Fall leiten wir diese Daten in die Ausgabe für „nicht übereinstimmende Einträge“.
Unter Verbindung gibt man den entsprechenden ConnectionManager und die Zieltabelle an:
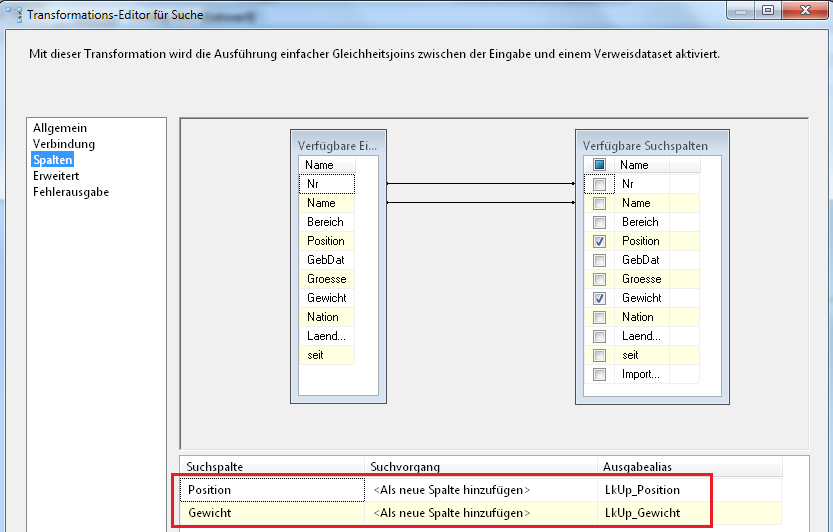
Jetzt kommt der spannende Teil dieser Transformation. Unter dem Punkt Spalten wird nun eingestellt, welche Spalten für den Join zwischen Quell- und Verweistabelle benutzt werden. Die Haken vor den verfügbaren Suchspalten bedeuten, dass diese Felder in die Trefferausgabe für Übereinstimmungen aufgenommen werden. In diesem Beispiel soll über die Nummer und den Namen das Feld Position und Gewicht hinsichtlich Änderungen überwacht werden, die Konfiguration sieht dann also wie folgt aus:
Findet der Lookup nun übereinstimmende Datensätze, werden diese in die Ausgabe „übereinstimmende Einträge“ umgeleitet. Im Klartext bedeutet das, es werden zwei neue Spalten (Tipp: manuell um ein Präfix zur besseren Unterscheidung erweitern, hier: LkUp_) in die Metadaten der Ausgabe mit aufgenommen. Diese beinhalten also neben allen Spalten aus der Quelle auch unsere beiden zusätzlichen Spalten, in denen die geänderten Feldinhalte stehen. Ein Blick in die Metadaten gibt Aufschluss:
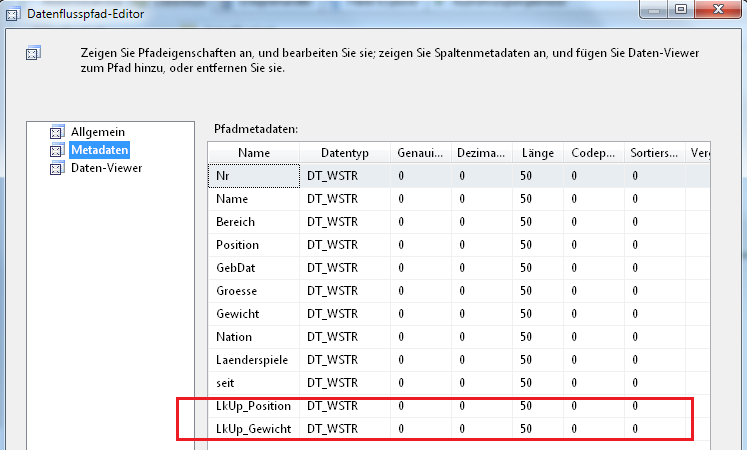
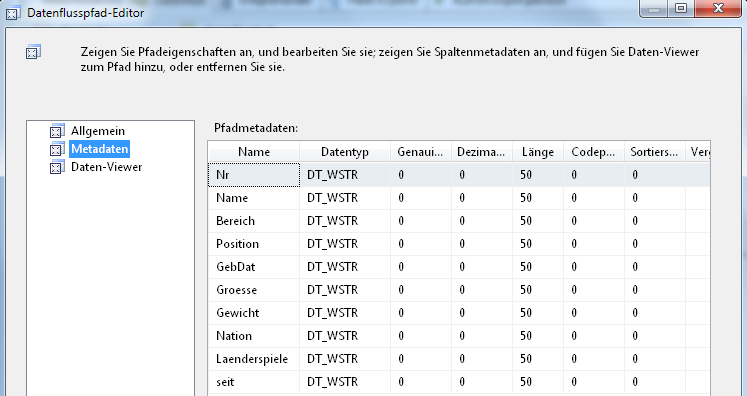
Hier zum Vergleich die Metadaten der Ausgabe für keine Übereinstimmungen, es fehlen genau diese beiden im Lookup definierten Spalten:
Zu unserem gewünschten Gesamtergebnis müssen wir dem Prozess nun noch mitteilen, wohin die Daten, die schon in der Zieltabelle vorhanden sind, fließen sollen. Dafür binden wir ein neues OLE-DB Ziel an diesen Ausgabestrang an, unser Datenfluss sieht nun mittlerweile schon ein wenig umfangreicher aus.

Es existieren jetzt also zwei Tabellen, eine mit den Quelldaten, für die keine Übereinstimmung gefunden wurde (T_Import_THW), und eine mit den Quelldatensätzen, die im Lookup eine Übereinstimmung hatten (T_Import_THW_updates). Mit einem einfachen SQL-Task sorgen wir nun noch für die Zusammenführung in der Zieltabelle und das Leeren der Änderungstabelle. Hier das SQL-Statement:
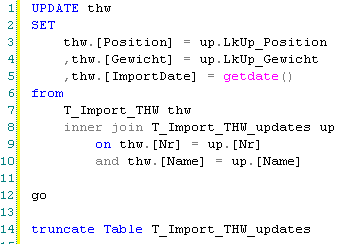
In unserem Beispiel hier haben wir den SQL-Task einfach an den Datenfluss hinten angefügt. Durch diesen Ablauf ist immer gewährleistet, dass die Tabelle mit den Änderungen auch tatsächlich leer ist.
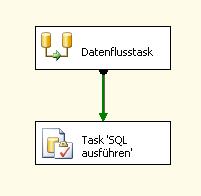
Damit haben wir unseren ersten kleinen inkrementellen Ladeprozess erstellt.
In einem nächsten Blogbeitrag werden wir diesen Prozess erweitern und zeigen, was man mit dem Lookup-Task noch alles realisieren kann.
