In diesem Blogbeitrag möchten wir gerne ein Thema beleuchten, das uns nicht unbedingt täglich in unserem Projektgeschäft begegnet – das aber trotz allem nicht minder interessant ist. Beim SSIS-Import von Flatfiles in eine Tabelle muss immer peinlichst genau darauf geachtet werden, dass die Anzahl der Spalten aus den Flatfiles exakt die gleiche ist. Aber in der Praxis ist das manchmal gar nicht so einfach – zum Beispiel bei folgendem Szenario:
- Umstellung der Flatfile-Definition: Durch ein neues Attribut, das im Flatfile geliefert werden soll, kommt eine weitere Spalte im Flatfile hinzu
- Die Änderung soll zuerst nur in der Entwicklungsumgebung berücksichtigt werden, aber es sollen keine separaten Flatfiles für die Entwicklungsumgebung eingesammelt werden
- Unterschiedlich schnelle Umsetzung der neuen Flatfile-Definition bei den Datenlieferanten (z.B. Tochterunternehmen). Es ist sehr schwierig, alle Beteiligten auf einen Stichtag für die Datenlieferung im neuen Format fest zu legen. Dadurch hat man für eine Übergangszeit ein gewisses “Durcheinander”
Der hier gezeigte Lösungsansatz geht davon aus, dass zu einer bestimmten Anzahl und Reihenfolge von Spalten in einem Flatfile weitere Spalten angehängt werden. Bei überzähligen Spalten werden diese entsprechend aus dem Flatfile gelöscht.
Kleines Script mit großer Wirkung
Das hier verwendete Script wird einfach als Script-Task in einen “ForEach in Folder”-Container mit eingebaut. Nach ein paar Anpassungen ist das Script in der Lage, jedes beliebige Flatfile Zeile für Zeile zu durchlaufen und zu prüfen, ob die Anzahl der Spalten korrigiert werden muss oder nicht.
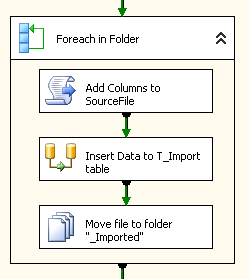
Voraussetzungen
Steuer- und Log-Tabellen
Um das Script richtig einsetzen zu können, werden zwei Tabellen (T_S_ImportFlatfileInfo und T_S_LOG_ImportFlatfile) benötigt, die über dieses SQL-Script erzeugt werden können.
CREATE TABLE [dbo].[T_S_FileImportInfo](
[ImportType] [varchar](50) NOT NULL,
[ColumnsExpected] [int] NOT NULL,
[Delimiter] [varchar](50) NOT NULL
) ON [PRIMARY]
GO
-------------------------------------------------
CREATE TABLE [dbo].[T_S_LOG_FileImport](
[ID] [bigint] IDENTITY(1,1) NOT NULL,
[ImportStart] [datetime] NOT NULL,
[ImportEnd] [datetime] NULL,
[ImportType] [varchar](50) NULL,
[FilePath] [varchar](500) NULL,
[AdditionalColumnsCreated] [bit] NULL,
[NeedlessColumnsDeleted] [bit] NULL,
[ErrorText] [varchar](500) NULL,
CONSTRAINT [PK_T_S_LOG_FileImport] PRIMARY KEY CLUSTERED ([ID] ASC)
WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY =
OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY])
ON [PRIMARY]
GO
Die Tabelle T_S_FileImportInfo enthält die Steuer-Informationen für das Script:
- ImportType: Ein eindeutiger Name
- ColumnsExpected: Anzahl der Spalten, die erwartet werden (Sonderfall: bei “0” bleiben die Spalten im Flatfile unverändert)
- Delimiter: Das zu verwendende Trennzeichen (Sonderfall: bei Tabulator als Trennzeichen muss hier “tab” eingegeben werden – diese Zeichenfolge wird dann später in CHAR(9) umgesetzt)
Die Tabelle T_S_LOG_FileImport dient als LOG-Tabelle ausschließlich zu Informationszwecken und wird direkt aus dem Script heraus gefüllt.
SSIS Paket-Variable varFileName
Innerhalb des “ForEach in Folder”-Containers muss eine Variable mit dem vollständigen Pfad zum jeweiligen Flatfile befüllt werden. Die Variable muss “varFileName” heißen und als ReadOnlyVariable in den Eigenschaften des Script-Tasks angegeben werden. Hat diese Variable einen anderen Namen, so ist dieser Name bei den “ReadOnlyVariables” anzugeben und auch im Script entsprechend zu ändern.
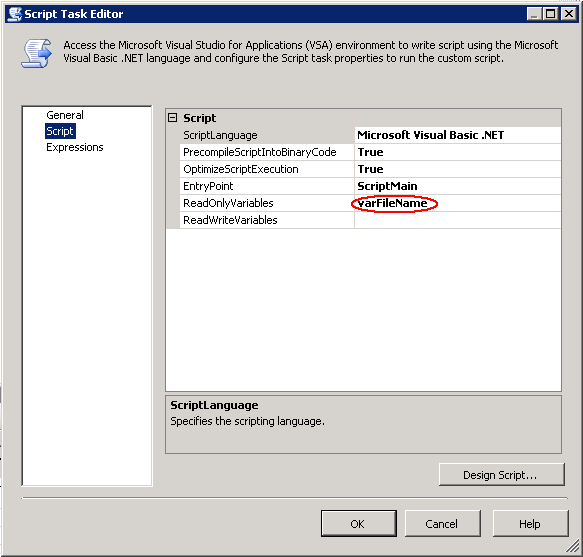
Angaben im Kopfbereich des Scripts
Im Kopfbereich des Scripts (Zeile 54 bis 92) ist anzugeben
- wie die im SSIS-Paket verwendete SQL-Server Datenverbindung heißt. Diese Verbindung wird benutzt um die Verbindungsparameter zu ermitteln, damit später die Inhalte der Tabelle T_S_FileImportInfo ausgelesen werden können. Dies setzt voraus, dass die Daten aus dem Flatfile in eine Tabelle innerhalb der gleichen Datenbank geschrieben werden, die auch die Steuer- und Log-Tabelle enthält. Alternativ kann auch ein fester Connectstring angegeben werden – damit gibt es dann aber eine zusätzliche Stelle im Script (also ziemlich versteckt), die im Falle eines Datenbank-Umzugs angepasst werden muss und nicht vergessen werden darf!
- welche Codepage beim Öffnen des Flatfiles angewendet werden soll. Diese Angabe ist wichtig, damit bei der Verarbeitung nicht aus Sonderzeichen irgendein Murks gemacht wird. Die Codepage kann z.B. aus der Flatfile-Quelle im DataFlow ermittelt werden.
- wie der Import-Typ heißt. Der hier angegebene Name muss mit dem Eintrag in der ImportType-Spalte der Tabelle T_S_FileImportInfo übereinstimmen – hierüber werden später die Spaltenanzahl und das Trennzeichen ermittelt.
Wenn das Script läuft
Initial erzeugt das Script in jedem Ordner zwei Unterordner “_Delivered” und “_Imported”. In den Ordner “_Delivered” wird das Original-Flatfile 1:1 hineinkopiert, damit für den Fall der Fälle ein Backup der ursprünglichen Datenlieferung vorhanden ist. Der Ordner “_Imported” wird vom Script nur angelegt, aber nicht befüllt. Im Anschluss an den Datenimport können die verarbeiteten Flatfiles z.B. mit einer FileSystem-Task hier hinein verschoben werden.
Nachdem die beiden Unterordner angelegt wurden, durchläuft das Script die Quell-Datei Zeile für Zeile. Pro Zeile wird die Anzahl der Trennzeichen ermittelt und geprüft, ob die erwartete Anzahl an Spalten (T_S_FlatFileInfo.ColumnsExpected) mit der tatsächlichen übereinstimmt (Achtung: Es werden immer nur n-1 Trennzeichen in einer Zeile stehen, da die letzte Spalte ja mit einem Zeilenumbruch abgeschlossen ist und nicht mit einem Spaltentrennzeichen). Nun werden drei Fälle unterschieden:
- Anzahl der Trennzeichen (+1) stimmt mit der Anzahl der erwarteten Spalten überein oder Anzahl der erwarteten Spalten = “0”: Die Zeile wird ohne Änderung in eine temporäre Datei übertragen
- Anzahl der Trennzeichen (+1) ist kleiner als die Anzahl der erwarteten Spalten: Die fehlende Anzahl Trennzeichen wird ans Zeilenende angehängt und die Zeile dann in eine temporäre Datei geschrieben
- Anzahl der Trennzeichen (+1) ist größer als die Anzahl der erwarteten Spalten: Die überzähligen Spalten werden am Ende der Zeile abgeschnitten und die bearbeitete Zeile dann in eine temporäre Datei übertragen
Sind alle Zeilen durchlaufen, wird die ursprüngliche Datei in das “_Delivered”-Verzeichnis verschoben und die temporäre Datei wird unter dem Namen der ursprünglichen Datei abgespeichert. Alle weiteren Operationen greifen dann auf die Datei mit den angepassten Spalten zu und es kann beim Import nichts mehr schief gehen, weil jetzt die richtige Anzahl von Spalten in der Datei enthalten ist.
