Es kommt mitunter vor, dass strukturgleiche Daten im Ladeprozess aus verschiedenen Datenquellen in das System überführt werden müssen.
Um hier nicht für jede Datenquelle einen eigenen Prozessschritt anlegen zu müssen, bietet sich die Möglichkeit an, in der Organisation der Dateneinspeisung einen Container zu verwenden, der einen Loop über die verschiedenen Quellen durchführt. Dabei werden die Connection Strings zunächst in eine Variable gespeichert und dann zur Laufzeit abgearbeitet. Die technische Umsetzung dieser Arbeitsersparnis wird im Folgenden dargestellt.
Zunächst benötigen wir eine kleine Tabelle in einer relationalen Datenbank, in welcher die beliebig vielen, verschiedenen Datenquellen hinterlegt werden können. Diese könnte in etwa folgendermaßen aussehen:
CREATE TABLE T_S_Verbindung ( VerbindungsID [smallint], VerbindungBEZ [varchar](255) ) GO

Zur Befüllung der Steuertabelle mit Werten eignet sich folgende Syntax:
INSERT INTO T_S_Verbindung SELECT 1 VerbindungsID, 'Data Source=Server1;Initial Catalog=Datenbank1;Provider=SQLNCLI10.1;Integrated Security=SSPI;Auto Translate=False;' VerbindungBEZ GO
Sind die gewünschten Verbindungszeichenfolgen hinterlegt, so kann ein SSIS Task angelegt werden, um diese anzusteuern und letztendlich mittels einer Schleife auf die unterschiedlichen Datenquellen zuzugreifen.
Hierfür werden zunächst zwei Variablen benötigt. Eine vom Typ „Object“ für die Speicherung unseres Abfrageergebnisses und die zweite vom gewöhnlichen Typ „String“. In Letztere kann initial der erste Eintrag der zuvor angelegten Tabelle geschrieben werden, um eine Warnmeldung zu umgehen. Zur Laufzeit wird der Wert neu befüllt.
![]()
Als nächstes sind für unser Vorhaben dann zwei Verbindungsmanager notwendig.
Hier steht der Verbindungsmanager „Parameter und Ziel“ für eine gebräuchliche OLE-DB Verbindung zu jener Datenbank, in welcher wir unsere Steuertabelle T_S_Verbindung angelegt haben und in welcher idealerweise auch unsere später geladenen Zieldaten Verwendung finden.
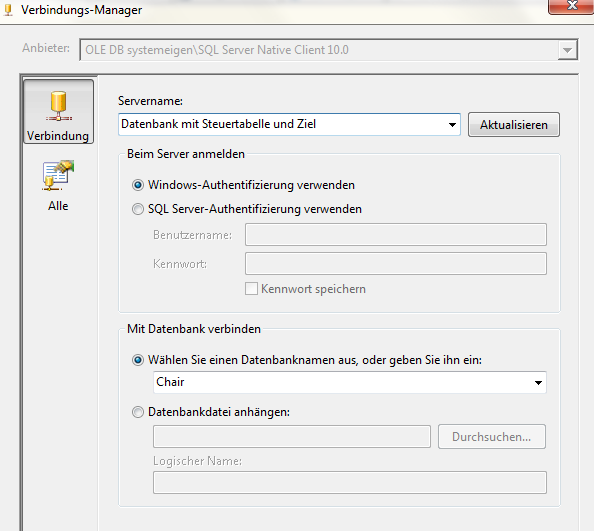
Interessanter ist da schon der zweite Verbindungsmanager „Dynamische Verbindung“. Hier wird neben dem gewünschten Server und der Datenbank auch mittels Eigenschaftendialog eine Expression hinzugefügt, und zwar unsere zuvor angelegte Variable „User::Verbindungszeichenfolge“.
![]()
Nachdem diese Vorbereitungen getroffen sind, gelangen wir an den eigentlichen Aufbau der SSIS Ablaufsteuerung und erstellen zunächst einen „SQL ausführen“ Task, hier namentlich mit „Verbindungszeichenfolgen lesen“ tituliert.


Und die Zuordnung der Objektvariable an das erhaltene Resultset:

Da die Verbindungszeichenfolgen im Folgenden aus der Variable „Quelle“ ausgelesen werden können, bedarf es nun eines neuen Prozessschrittes „ForEachSchleifencontainer“, um in einer Schleife die verschiedenen Verbindungen anzusprechen.
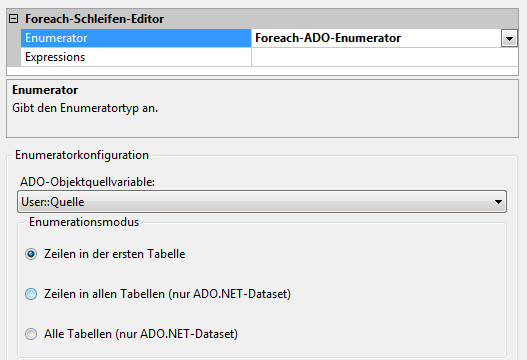
Bei den Einstellungen des Schleifencontainers ist nun vor allem darauf zu achten, die Variablen richtig zu setzen. Als Enumerator ist hier der „Foreach-ADO-Enumerator“ auszuwählen und die zugehörige ADO-Objektquellvariable wird unsere Objektvariable „Quelle“.
Bei den Variablenzuordnungen ist dann der jeweilige String aus der Verbindungszeichenfolge auszulesen.

Sind diese Einstellungen vorgenommen, kann in den zentralen Bauch des Schleifenablaufs ein herkömmlicher Datenfluss mit Quell- und Zielobjekten eingestellt werden.
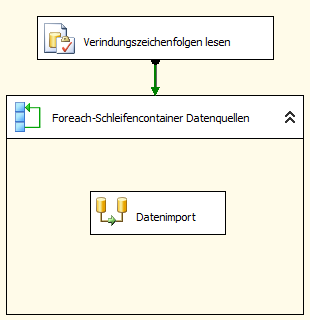
Hier ist jedoch darauf zu achten, dass Quelle und Ziel in allen Verbindungsmanagern gleiche Struktur aufweisen. Ist dies nicht der Fall, so kann in unsere Steuertabelle ebenfalls auch noch das SQL einer Abfrage eingebaut werden, welche aus unterschiedlichen Tabellen die Inhalte in gleicher Form selektiert und an eine allgemeingültige Zieltabelle weitergibt. Dieses SQL wird dann zur Laufzeit ebenfalls über eine Variable in die zur jeweiligen Verbindungszeichenfolge gehörige Quelle geschrieben und gewährleistet somit weitere Flexibilität.
