Seit dem SQL-Server 2005 gibt es für die AnalysisServices eine großartige Möglichkeit, um die internen Abläufe und Prozesse während des laufenden Betriebs aufzuzeichnen und später (z.B. nach einem Serverabsturz) zu analysieren. Vor kurzem hatten wir einen solchen Fall bei einem Kunden: Der Server hat im laufenden Betrieb plötzlich nicht mehr reagiert. Natürlich zu einer absolut unpassenden Zeit. Bei dem Kunden wurden weltweit Zahlen für die Produktionsplanung eingesammelt und den Anwendern standen insgesamt nur 48 Stunden für die Dateneingabe zur Verfügung. Der Serverstillstand ereignete sich nachts um kurz nach 1:00 Uhr MEZ – Dateneingabe-Zeit in Asien. Natürlich haben die Kollegen aus Asien sofort eine Mail an den Administrator in Deutschland geschickt. Die entsprechenden Gegenmaßnahmen wurden aber erst eingeleitet, als der Administrator gegen 7:30 Uhr sein Büro betreten und seine Mails gecheckt hatte. Der SSAS-Dienst wurde durchgestartet und alles lief wieder einwandfrei.
Sechs geschlagene Stunden Systemstillstand bei einem Zeitfenster von nur 48 Stunden. Natürlich kam die Frage auf, wie es dazu kommen konnte und was in Zukunft getan werden kann, dass ein solches Problem nicht wieder auftritt.
Zur Beantwortung dieser Fragen konnte das mit dem SSAS-FlightRecorder aufgezeichnete Trace-File einen entscheidenden Beitrag leisten! Aber zuerst ein paar Informationen zur Konfiguration des FlightRecorder:
SSAS FlightRecorder aktivieren
Der SSAS FlightRecorder kann über eine Boolesche Variable in den Server-Eigenschaften des SSAS aktiviert bzw. deaktiviert werden. Ähnlich wie ein Flugschreiber in einem Flugzeug, zeichnet der SSAS FlightRecorder in regelmäßigen Abständen die Vorgänge und Zustände des Analysis Servers in einem “Kurzzeit”-Protokoll auf. Das auf diesem Wege erzeugte Trace-File enthält also nur einen bestimmten Zeitraum. Der Zeitraum, der im FlightRecorder festgehalten wird, kann über einen Parameter in den SSAS-Server-Eigenschaften gesetzt werden. Die Einträge werden immer in die Datei FlightRecCurrent.trc eingetragen. Diese befindet sich in dem Verzeichnis, das in der Eigenschaft LogDir eingetragen ist. Immer wenn das eingestellte Zeitlimit oder die maximale Dateigröße überschritten sind, wird die aktuelle FlightRecCurrent.trc umbenannt in FlightRecBack.trc und eine neue FlightRecCurrent.trc wird erstellt. Die alte FlightRecBack.trc wird gelöscht.
Die Aufzeichnung des Server-Zustands erfolgt – wie bereits erwähnt – nicht kontinuierlich, sondern in einem vorgegebenen Zeitintervall. Dabei werden die Serverzustände mit sogenannten DISCOVER-Requests abgefragt. Welche Server-Zustände abgefragt werden, kann über eine XML-Datei gesteuert werden (siehe Log\FlightRecorder\SnapshotDefinitionFile).
Um an die Server-Eigenschaften des SSAS zu gelangen öffnet man eine SSAS-Serververbindung im SQL Server Management Studio. Nach einem Rechtsklick auf die Serververbindung im Objekt-Explorer des Management Studio und einem Klick auf “Eigenschaften” öffnet sich der Dialog mit den SSAS-Servereigenschaften. Anschließend muss noch die Auswahlbox “Erweiterte (alle) Eigenschaften anzeigen” gesetzt werden, damit alle für den FlightRecorder relevanten Eigenschaften auch angezeigt werden.
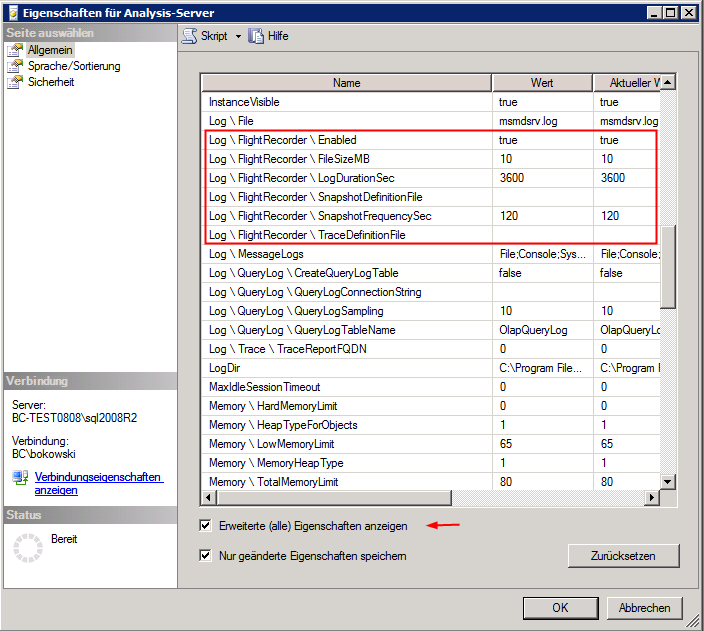
Log \ FlightRecorder \ Enabled
Genereller Schalter für die Verwendung des FlightRecorder. Standardmäßig ist diese Eigenschaft auf TRUE gesetzt.
Log \ FlightRecorder \ FileSizeMB
Die maximale Dateigröße in MB. Erreicht die Datei FlightRecCurrent.trc diese Größe, wird ein Backup erstellt und eine neue Version erstellt.
Der Wert darf nur halb so groß wie der zur Verfügung stehende Speicherplatz auf der Platte sein, da ja auch immer noch die FlightRecBackup.trc angelegt wird!
Log \ FlightRecorder \ LogDurationSec
Das maximale Zeitintervall für die Aufzeichnung. Erreicht die Aufzeichnung dieses Zeitlimit, wird ein Backup erstellt und eine neue FlightRecCurrent.trc erstellt. Standardmäßig sind hier 3600 sec. eingestellt – dies kann aber möglicherweise zu wenig sein, wenn z.B. ein Problem nachts aufgetreten ist und erst am nächsten Morgen bemerkt wird. Mit der Standard-Einstellung wäre dann das Trace schon längst wieder überschrieben… Wir haben uns für ein 12 Stunden-Intervall entschieden – auch auf die Gefahr hin, dass sich dies evtl. auf die Performance auswirken kann.
Log \ FlightRecorder \ SnapshotDefinitionFile
Hier kann der Name einer Datei angegeben werden, die eine Definition der Servereigenschaften enthält, die während eines DISCOVER-Requests abgefragt werden sollen. Standardmäßig ist dieses Feld leer. In diesem Fall wird die Datei flightrecordersnapshotdef.xml im Verzeichnis \OLAP\bin\ verwendet.
Log \ FlightRecorder \ SnapshotFrequencySec
Vorgabe des Zeitintervalls, in dem die DISCOVER-Requests an den Server geschickt werden.
Log \ FlightRecorder \ TraceDefinitionFile
Definition der vom FlightRecorder aufzuzeichnenden TRACE-Events (Verbindungsauf- und –abbau, MDX-Abfragen, etc.). Standardmäßig ist dieses Feld leer – dann wird die Datei flightrecordertracedef.xml im Verzeichnis \OLAP\bin\ verwendet.
Fehlersuche im FlightRecorder
Nachdem das System wieder stabil lief, haben wir uns die Datei FlightRecBack.trc vorgenommen, um zu sehen, warum der Server plötzlich nicht mehr auf Anfragen von außen reagiert hat. Dabei habe ich mir zuerst das Ende des Trace-Files angeschaut – ab dem Zeitpunkt, zu dem der SSAS-Dienst durchgestartet wurde. Einfach zu finden durch den Eintrag “Audit Server Starts And Stops” in der Spalte EventClass. Es ist sofort aufgefallen, dass in den folgenden Zeilen Abfragen beendet wurden, die in der Nacht um 1:06 gestartet wurde (Spalte StartTime)! Damit war klar, dass zu dieser Zeit oder kurz danach etwas vorgefallen ist, das den Server komplett “aus dem Tritt” gebracht hat.
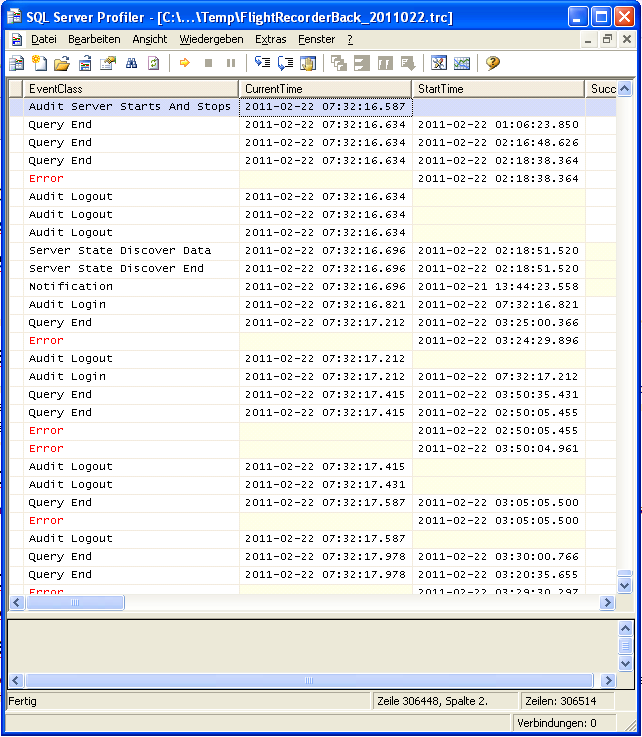
Nachdem der zeitliche Horizont eingegrenzt war, habe ich alle FlightRecorder-Snapshots gesucht, die in diesem Zeitraum aufgezeichnet wurden. Eigentlich hätte ich damit gerechnet, dass alle zwei Minuten ein Snapshot aufgezeichnet wurde. Aber dem war nicht so. Nur in der ersten Stunde nach der Abfrage gab es diese Einträge mit der EventClass “Server State Dicover …”. Dann kam eine weitere Benutzerabfrage und danach war es aus mit den State-Discovers. Nur noch Logins und Logouts…
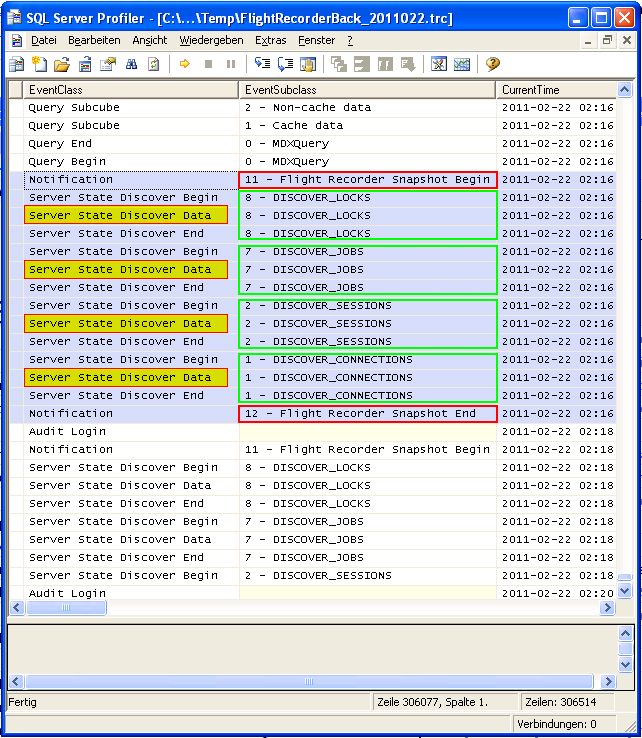
Jetzt galt es, den letzten FlightRecorder Snapshot zu untersuchen. Ein einzelner FlightRecorder Snapshot ist im Trace-File eingebettet in zwei Notification-Meldungen “Flight Recorder Snapshot Begin” und “Flight Recorder Snapshot End” (“Notification” steht in Spalte EventClass, die anderen beiden Einträge finden sich in der Spalte EventSubclass).
Ein solcher FlightRecorder Snapshot Block kann mehrere Server State Discoveries enthalten. Per Default werden die folgenden Discoveries ausgeführt – zu finden in der Spalte EventSubclass:
- DISCOVER_LOCKS
- DISCOVER_JOBS
- DISCOVER_SESSIONS
- DISCOVER_CONNECTIONS
Während jedes einzelne Server-State Discover wiederum drei Zeilen im Trace einnimmt. In der Spalte EventClass findet man dazu die Einträge:
- Server State Discover Begin
- Server State Discover Data
- Server State Discover End
Interessant sind jedoch nur die Zeilen der EventClass Server State Dicover Data – in diesen Zeilen findet sich in der Spalte TextData das Ergebnis des jeweiligen DISCOVER-Requests im XML-Format. Wenn man diese Zeile selektiert, kann man den Text im unteren, grauen Fensterbereich markieren und kopieren.
Um das Ergebnis-XML in eine lesbare Form zu bringen, kann man einen XML-Editor oder aber auch das BI-Studio verwenden. Im BI-Studio einfach eine neue XML-Datei öffnen, das Ergebnis-XML hineinkopieren und dann noch ein wenig “in Form” bringen. Dafür die beiden Zeilen mit den Tags <DiscoverResponse…> und entfernen und am Ende der Datei einen abschließenden Tag einfügen. Anschließend noch den Bereich von <xsd:schema…> bis einschließlich entfernen. Danach kann über einen Rechtsklick im Kontextmenü des Editors der Eintrag “Datenraster anzeigen” ausgewählt werden und das Ergebnis-XML wird in Tabellenform dargestellt.
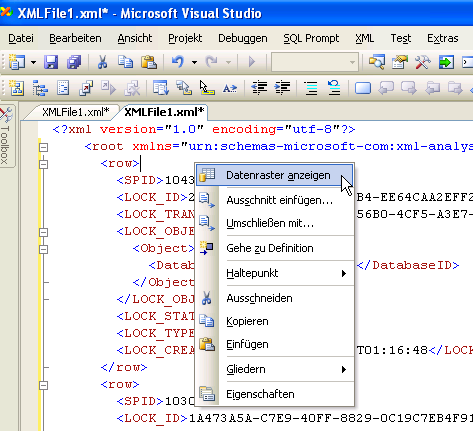
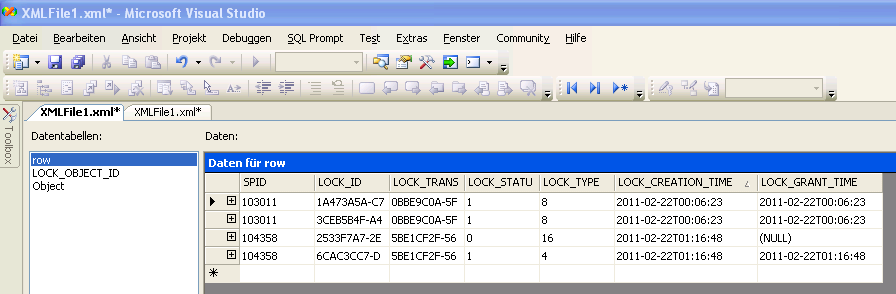
Über diese Einträge kann man nachvollziehen, dass die erste nicht abgeschlossene Abfrage von 1:06 Uhr (Achtung bei den Zeiten hier im Trace muss eine Stunde hinzugerechnet werden) zwei Read-Locks auf dem AnalysisServer ausgelöst hat. Das ist zu erkennen an dem Eintrag in der Spalte LOCK_TYPE. Etwas mehr als eine Stunde später kamen dann zu den zwei Read-Locks noch zwei Write-Locks. Einer mit der LOCK_TYPE-ID 4 (0×0004) = “Wirte lock during processing” und einer mit der LOCK_TYPE-ID 16 (0×0010) = “Commit lock, exclusive”. An der Spalte LOCK_GRANT_TIME kann man erkennen, dass beim Versuch diesen LOCK anzunehmen etwas schief gegangen ist. Und tatsächlich hat der SSAS eine Schwachstelle genau dort. Wenn eine aufwändige Datenabfrage mit einem Schreibversuch zusammenkommt, kann der SSAS nicht damit umgehen und es kommt zu einem sogenannten Dead-Lock. Zwei Prozesse blockieren sich gegenseitig und das wiederum hat zur Folge, dass auf dem SSAS gar nichts mehr geht.
Damit wäre das “WARUM” geklärt – aber viel wichtiger ist jetzt noch zu klären: “WAS KANN MAN DAGEGEN TUN”?
Klar ist, dass eine Abfrage, die länger als eine Stunde dauert, nicht in Ordnung ist. Zumal die Abfrage von einem Standard-Bericht ausgeht, denn die Standard-Anwender sind nur über die DeltaMaster Web-Option mit dem SSAS verbunden. Eine solche Antwortzeit ist nicht akzeptabel! Aber – was wurde eigentlich abgefragt? Welcher Bericht steht dahinter? Welche Sicht-Einstellungen hat der Anwender vorgenommen? Diese Antwort-Zeiten kamen bei keinem der im Web veröffentlichten Berichte zustande. Die Berichte stehen schon seit mehreren Monaten über die Web-Option bereit und wurden auch ausgiebig getestet. Eine hohe Serverauslastung ist auch nicht schuld. Über das Trace-File kann nachvollzogen werden, dass nur wenige Anwender auf dem System angemeldet waren.
Die Analyse der Queries bringt hier die Erleuchtung. Um die Queries zu finden, können die SPIDs aus dem Ergebnis-XML verwendet werden. Über die Suchfunktion im SQL Server Profiler kann die Spalte SPID nach diesen Einträgen durchsucht werden und man kann genau sehen, welche MDX-Statements an den Server übermittelt wurden. Die Analyse der Queries mit der SPID 104358 hat ergeben, dass es sich um eine ganz normale Dateneingabe handelt. Aber die Query mit der SPID 103011 hatte es in sich. Ein an und für sich schon sehr komplexer Bericht wurde vom Benutzer mit einer Mehrfachselektion in der Zeitdimension aufgerufen. Normalerweise sollte in diesem Bericht nur eine einzelne Periode (z.B. ein Jahr oder ein Quartal) aufgerufen werden, aber dieser Anwender hat um 1:06 Uhr fünf Quartale ausgewählt und damit die Misere ausgelöst. Es war auch sofort klar, welcher Bericht hinter (oder besser gesagt vor) diesem MDX-Statement steht. Die erste Gegenmaßnahme war, die Multiselektion für diesen Bericht auszuschalten – ein einfacher Handgriff im DeltaMaster.
Weitere Maßnahmen, die zu prüfen sind, wären:
- Spiegelung des SSAS-Datenmodells, rein für die Datenerfassung. Damit wurden bereits bei anderen Kunden gute Erfahrungen gemacht.
- In den SSAS Servereigenschaften einen “CommitTimeout” vorgeben. Dieser ist standardmässig ausgeschaltet.
- In den SSAS Servereigenschaften einen “IdleConnectionTimeout” vorgeben. Dieser ist standardmässig ausgeschaltet.
- In den SSAS Servereigenschaften einen “MaxIdleSessionTimeout” vorgeben. Dieser ist standardmässig ausgeschaltet.
