Das SQLCMD-Dienstprogramm ist ein kleines Hilfsprogramm mit zum Teil großer Wirkung. Denn durch dieses Hilfsprogramm ist es möglich, über die Kommandozeile SQL-Befehle an einen lokalen oder entfernten SQL-Server abzusetzen. Das Programm selbst ist Bestandteil jeder SQL-Server Installation (Pfad auf Anfrage erhältlich). Das Hilfsprogramm kann auch einzeln im Downloadcenter von Microsoft heruntergeladen werden. Es ist sogar für das Linux- und Mac-Betriebssystem verfügbar, wodurch sich weitere Einsatzmöglichkeiten ergeben. SQLCMD nutzt selbst den OLEDB Provider, um eine Verbindung zum SQL Server aufzubauen. Einsatzgebiete von SQLCMD sind vor allem das Absetzen von standardisierten SQL-Kommandos und -Skripten, ohne dabei das Management Studio zu benötigen oder auch öffnen zu müssen. In eine Batch-Datei gekleidet, kann die Routine dann auch einfach von jedem Anwender oder Scheduler gestartet werden. Dies kann gerade bei einigen Anwendungsszenarien sehr hilfreich sein, auf die im Folgenden eingegangen wird.
Grundlagen
Die Syntax von SQLCMD ist relativ simpel und verständlich aufgebaut. Um diese einzusehen, bedarf es nicht mehr als folgenden Befehl in der Kommandozeile auszuführen: SQLCMD -?. Als Ergebnis erhält man folgende Auflistung der Syntax, die recht übersichtlich daherkommt.
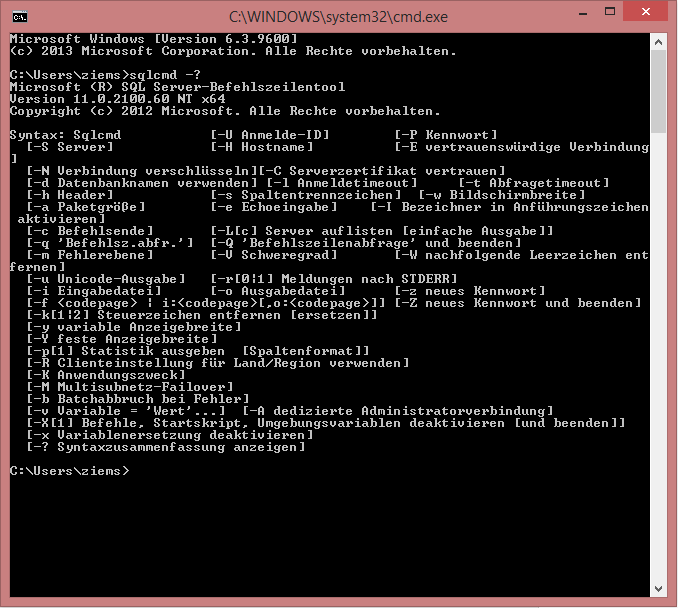
Nun wollen wir, nachdem wir den Syntaxumfang gesichtet haben, einen ersten Befehl ausführen. Als erstes verbinden wir uns mit dem SQL-Server. Der SQL-Servername (und die Instanz) ist über die Syntax -S anzugeben. Um einen SQLCMD-Befehl abzusetzen ist es eine Grundvoraussetzung, den Befehl mit eben dieser Syntax auch zu beginnen – „SQLCMD“. In diesem Fall wird SQLCMD -S LOCALHOST\SQL2012 angegeben.
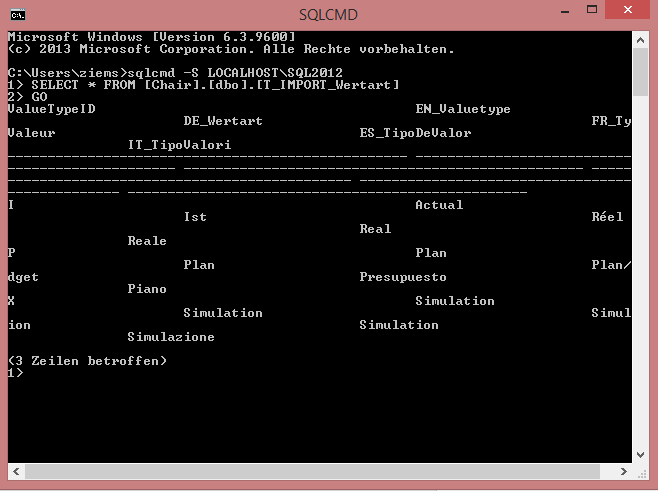
Nach Bestätigung der Eingabe mit der ENTER-Taste wird mit dem SQL-Server verbunden. Dies ging auch deswegen so einfach, weil per default die Windows-Authentifizierung genutzt wird. Sollte man diese nicht nutzen, kann man über die weiteren Parameter -U und -P sein (U)ser und sein (P)asswort mitgeben. Richtig viel sehen wir jedoch auch noch nicht. Nur, dass wir nun in eine neue Zeile gesprungen sind die nun mit „1>“ beginnt. Dies steht für die erste Abfragezeile, in die wir nun ganz normal unser SQL-Statement eingeben können. Als Test fragen wir hier folgendes Statement ab: SELECT * FROM [Chair].[dbo].[T_IMPORT_Wertart]. Beim Bestätigen mit ENTER wechselt der Cursor jedoch nur in die nächste Zeile, aber zeigt noch kein Ergebnis an. Hierfür muss mit dem bekannten Befehl GO der SQL-Befehl erst tatsächlich abgesetzt werden. Als Ergebnis erhalten wir dann die Tabelle in der Kommandozeile angezeigt. Es gibt definitiv schönere und übersichtlichere Formen eine Tabelle anzuzeigen, aber darum geht es in diesem Fall erstmal nicht.
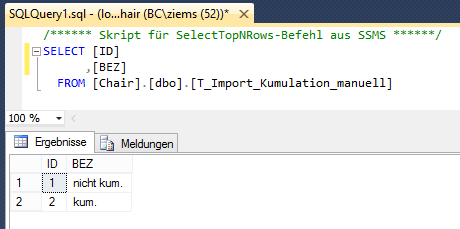
Mit dieser Form der Syntax nutzen wir die Kommandozeile auch gleichzeitig als Anzeigefenster für das Ergebnis. Dies wird jedoch in sehr wenigen Fällen das Anwendungsszenario sein. Viel mehr wird das Anstoßen von Prozessen oder das Ausführen von Skripten zu den normalen Anwendungsfällen von SQLCMD zählen. Die SQLCMD-Syntax erlaubt es auch, die Verbindung mit dem SQL-Server und die Abfrage eines SQL-Statements zu kombinieren und in ein Statement zusammenzufassen. Im Folgenden wird die Syntax anhand eines Insert-Befehls auf eine Beispieltabelle gezeigt. Dabei sieht das Statement folgendermaßen aus: SQLCMD -S localhost\SQL2012 -d Chair -Q “INSERT INTO T_Import_Kumulation_manuell (ID, BEZ) VALUES (2, ‘kum.’)”. Zu dem Parameter -S ist nun noch der Parameter „-d“ für die Datenbankangabe gekommen, sowie „-Q“ für die Query, die dann in diesem Kontext ausgeführt werden soll. Führen wir die Syntax in der Kommandozeile aus und betrachten die Tabelle anschließend im Management Studio, so sehen wir, dass der neue Eintrag auch tatsächlich in der Tabelle steht.
Neben der bereits beschriebenen Syntax gibt es zwei Parameter, die in der Praxis ebenso relevant sind. Hierbei handelt es sich um die Parameter -i und -o. Der Parameter -i steht dabei für Input und o für Output. Dabei wird relativ schnell klar, wofür diese beiden Parameter genutzt werden können. Mit dem Input-Parameter ist es möglich im Dateisystem abliegende SQL-Skripte auszuführen. Wohingegen man sich mit dem Output-Parameter das Ergebnis einer Abfrage, sowie Fehlernachrichten und Leistungsstatistiken in eine Flatfile-Datei ausgeben lassen kann. Zur Veranschaulichung kombinieren wir diese beiden Parameter in einem Beispiel. Hierzu bauen wir folgendes SQL-Skript auf, welches wir anschließend im Dateisystem ablegen.
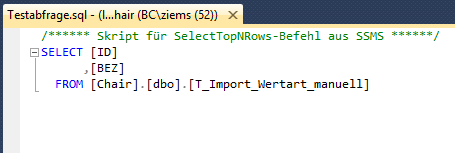
Nun soll das Ergebnis dieses SQL-Skripts in einem Flatfile ausgeben werden. Hierzu verwenden wir die Syntax SQLCMD -S localhost\SQL2012 -d Chair -i c:\temp\SQLCMD\Testabfrage.sql -o c:\temp\SQLCMD\Testabfrage_Ergebnis.txt . Nun erhalten wir in dem angegebenen Ordner im Dateisystem eine neue Datei (diese wird automatisch generiert und muss nicht zuvor schon angelegt sein), die das Ergebnis des SQL Abfrage aus dem Skript enthält.
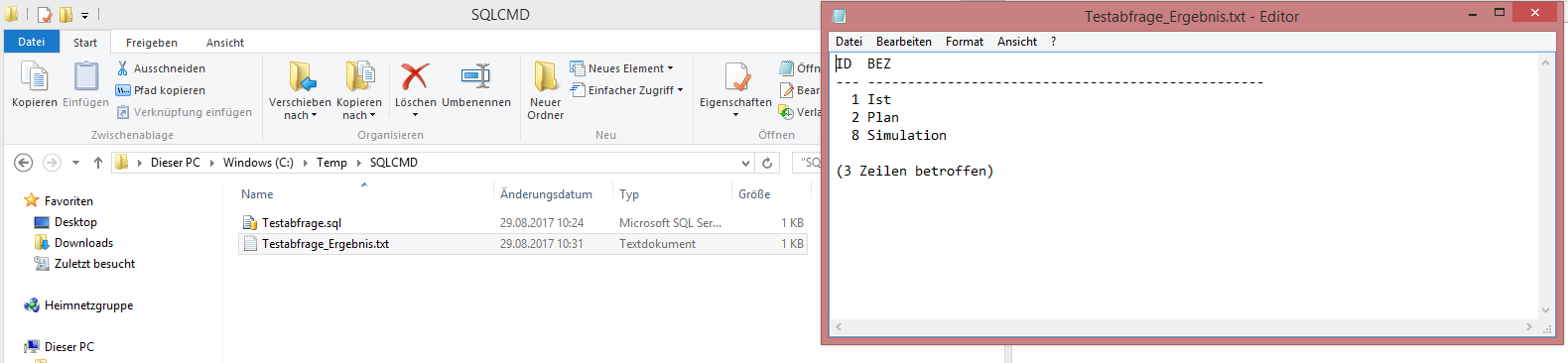
Beispiele mit Praxisbezug
Nachdem wir im vorherigen Teil die Grundlagen für SQLCMD geschaffen haben, ist es sicherlich interessant zu sehen, in welchen Anwendungsszenarien in unserer täglichen Praxis das SQLCMD dann schlussendlich auch sinnvoll einsetzbar ist. Die aufgeführten Beispiele sind zum einen Teil aus wirklichen Anforderungen und zum anderen Teil aus möglichen bzw. überlegten Anforderungen entstanden. Da es sicherlich mannigfaltige Einsatzzwecke gibt, erhebt die Sammlung an Beispielen keinen Anspruch auf Vollständigkeit.
Clientseitige Ausführung von SQL-Server Agent Jobs
Um Anwendern die Freiheit zu bieten gewisse Prozess von ihrem Client aus anzustoßen und die Person gleichzeitig nicht mit der Benutzeroberfläche vom SQL Server Management Studio zu überfordern, kann es sinnvoll sein hierzu SQLCMD zu nutzen. Der SQLCMD kann dann in eine Batch-Datei gekapselt und vom Anwender per Doppelklick gestartet werden. Um einen beliebigen SQL Server Agent Job auszuführen, nutzen wir die SQL-Standardprozedur msdb.dbo.sp_start_job ‘Jobname‘. Damit schaut unser SQLCMD-Statement dann folgendermaßen aus: SQLCMD -S localhost\sql2012 -d msdb -Q “EXEC dbo.sp_start_job ‘SQLCMD_Test'” -o C:\Temp\SQLCMD\SQLCMD_Test_Job.txt.
Zusätzlich zur Ausführung lassen wir uns mit dem Output-Parameter das Ergebnis in eine Textdatei ausgeben. Um eine Batch-Datei zu erstellen geben wir das SQLCMD-Statement in eine Textdatei ein und speichern diese dann mit der Dateiendung .bat ab. Anschließend können wir den Job über einen Doppelklick auf die Batch-Datei ausführen. Als Ergebnis bekommen wir dann in der Output-Textdatei gemeldet, dass der Job erfolgreich gestartet worden ist.

Da die einfache Prozedur sp_start_job lediglich den erfolgreichen Start des Jobs angibt, nicht aber die möglicherweise auftretenden Fehler oder die erfolgreiche Beendigung des Jobs, müsste das SQL-Statement um diese Funktionalitäten ergänzt werden (was wiederum nicht Teil dieses Beitrags sein soll). Hierzu gibt es jedoch einige Ansätze, die in den einschlägigen Foren zu finden sind.
SQL-Statements mit dem Windows Scheduler ausführen
In der Praxis kommt es immer mal wieder vor, dass der favorisierte SQL Server Agent uns als Scheduler aus unterschiedlichen Gründen nicht zur Verfügung steht. Dann wird meist auf die im Windows-Betriebssystem integrierte Aufgabenplanung (Windows Task Scheduler) zurückgegriffen. Was für die Ausführung von Publisherjobs an Funktionalität völlig ausreicht, stößt an seine Grenzen, wenn es um die Ausführung von SQL-Statements geht. Denn der Task Scheduler kann nur Programme starten und kein T-SQL ausführen.
Jedoch können wir diesen Makel mit der SQLCMD-Funktionalität einfach umgehen. Als Praxisbeispiel kann auch diesmal eine tatsächliche Kundenanforderung dienen. In dem Fall wollte der Kunde nämlich wöchentlich einen Bericht über den Publisher versenden, der jedoch nicht über die normale, hinterlegte Emailadresse verschickt werden sollte. Der Bericht musste über eine spezielle Emailadresse versendet werden, die den Inhalt der Email verschlüsselt. Da jedoch nicht mehrere Emailadressen hinterlegt werden können, über die der Bericht versendet und die je Job definiert werden kann, musste ein Workaround gefunden werden. Da auch die Einstellungsinformationen des Publishers in der dazugehörigen Datenbank gespeichert werden, war ein Workaround schnell gefunden. Vor der Ausführung des Publisher-Jobs zum Versand des Berichtes, musste der Eintrag für die Versenderemailadresse in der Publisher-Datenbank angepasst und danach wieder auf den alten Stand zurückgesetzten werden. Die anzupassende Tabelle in der Publisher-Datenbank war schnell mit dem passenden Namen „Mail“ gefunden. Nun mussten nur noch die SQL-Skripte für das Updatestatement vor und nach der Publisher-Job Ausführung erstellt werden. (Siehe Screenshot).

Die dazugehörigen Batch-Dateien erhielten dann lediglich die folgende SQLCMD-Syntax:
SQLCMD -S localhost\SQL2012 -d Chair -i C:\Temp\SQLCMD\NeueEmailadresse_Publisher.sql &
SQLCMD -S localhost\SQL2012 -d Chair -i C:\Temp\SQLCMD\AlteEmailadresse_Publisher.sql
Schlussendlich musste dann nur noch der Aufgabenplanungs-Job erstellt werden, der von der Aktionsreihenfolge folgendermaßen aufgebaut sein musste.
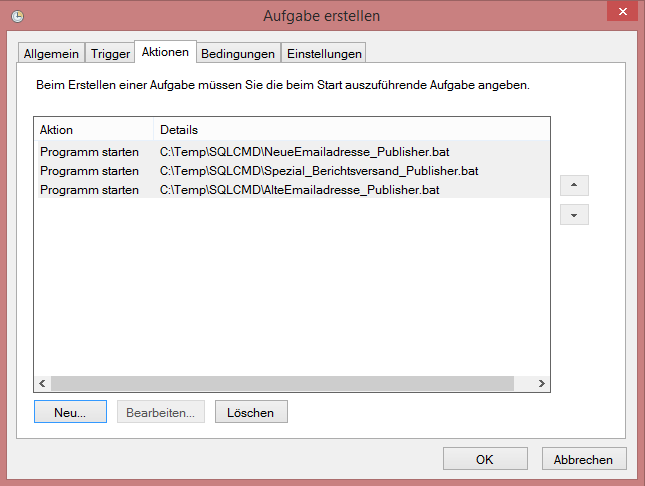
Daten als CSV-Dateien exportieren
Stellen wir uns vor, wir müssen Daten aus dem SQL-Server für den Import in ein anderes System vorbereiten. Die Daten sollen an einem bestimmten Ort im Dateisystem abgelegt werden, sodass Sie von hieraus in das andere System importiert werden können. Normalerweise würden wir hierzu ein SSIS-Paket erstellen, welches diesen Job für uns erledigt. Eine andere und schnellere Möglichkeit wäre es hier, die Funktionalität von SQLCMD zu nutzen.
Als Beispieldaten sollen uns hier die Daten aus der Deckungsbeitragsrechnung der Chair-Datenbank dienen. Diese wollen wir nun in einem Importfähigen Format im Dateisystem ablegen. Hierzu erstellen wir erst einmal die SQL-Abfrage der Daten und speichern die Abfrage als SQL-Skript ab.
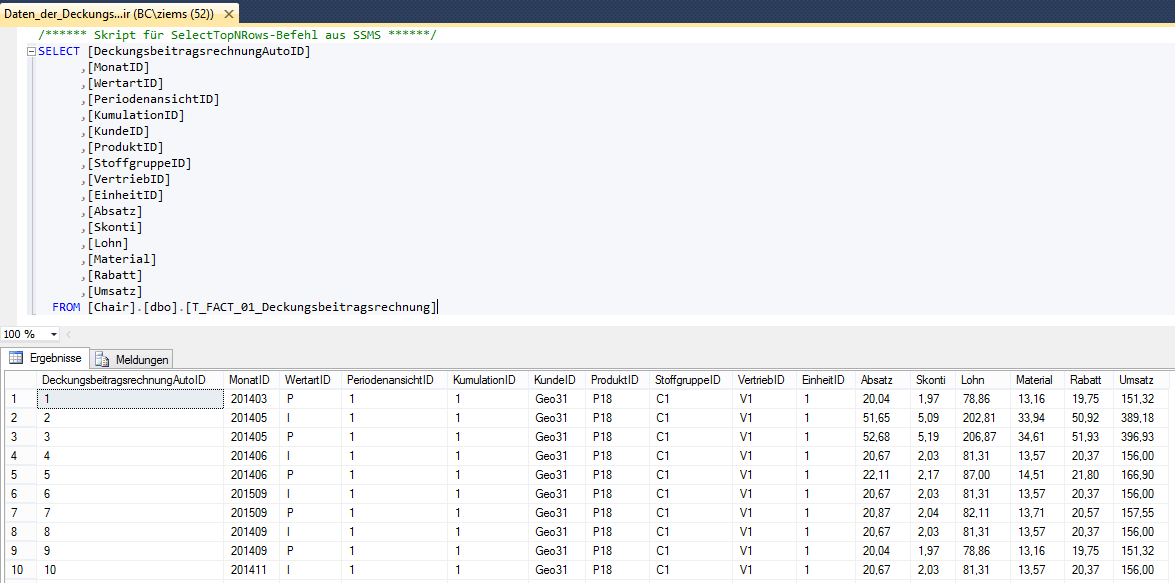
Anschließend erstellen wir wieder ein SQLCMD-Statement, welches wie folgt aussehen soll:
SQLCMD -S localhost\SQL2012 -d Chair -i
c:\temp\SQLCMD\Daten_der_Deckungsbeitragsrechnung.sql -o
c:\temp\SQLCMD\Import\Importdaten_Deckungsbeitragsrechnung.csv
Führen wir dieses Statement über die Kommandozeile aus, so erhalten wir, wie gewünscht, ein Flatfile (in unserem Fall eine csv-Datei) im angegebenen Ordner abgelegt. Wenn wir dieses öffnen, erhalten wir genau die Daten, die wir abgefragt haben.
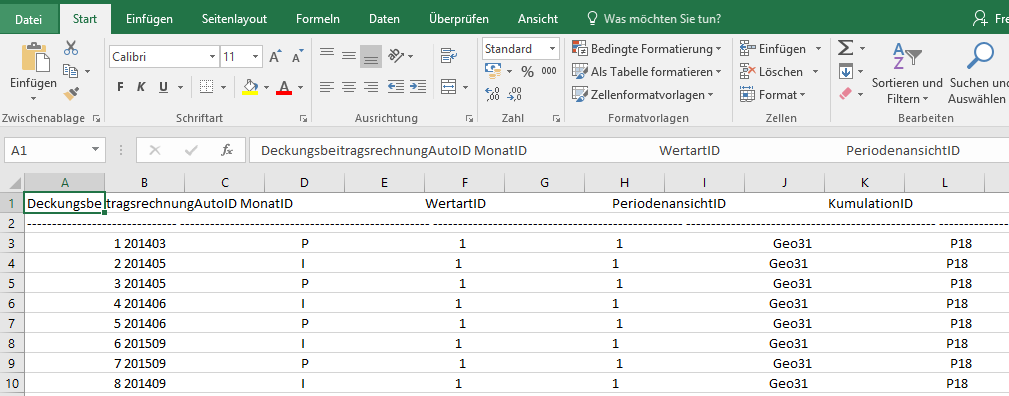
Jedoch werden die Daten alle in eine Spalte geschrieben, da kein Spaltentrenner mitgegeben wird. Zudem haben wir zwischen den Datensätzen Leerzeichen. Für den Import wollen wir in unserem Fall auch keinen Header mitführen. Um diese Änderungswünsche umzusetzen, reicht es, unser SQLCMD-Statement um ein paar Output-spezifische Parameter zu erweitern:
SQLCMD -S localhost\SQL2012 -d Chair -i
c:\temp\SQLCMD\Daten_der_Deckungsbeitragsrechnung.sql -o
c:\temp\SQLCMD\Import\Importdaten_Deckungsbeitragsrechnung.csv -W -s”;” -h-1
In diesem Fall führt der Parameter -W dazu, dass alle Leerzeichen eliminiert werden. -s gibt den Spaltentrenner vor und der Parameter -h ist für den Header zuständig, wobei -1 bewirkt, dass gar kein Header mitgegeben wird.
Wenn wir in der Flatfile-Datei nun noch bis ans Ende scrollen, fällt uns noch eine störende Tatsache auf. Dem Output wird immer ein Count über die betroffenen Datensätze mitgegeben, welcher beim Import in das andere System stören würde.

Deshalb müssen wir noch eine kleine Anpassung an unserem SQL-Skript vornehmen. Setzen wir nämlich „SET NoCount ON” noch vor unser SELECT-Statement, wird die Information über die betroffenen Datensätze nicht mehr mitgegeben und unser endgültiges Resultat sieht dann folgendermaßen aus.
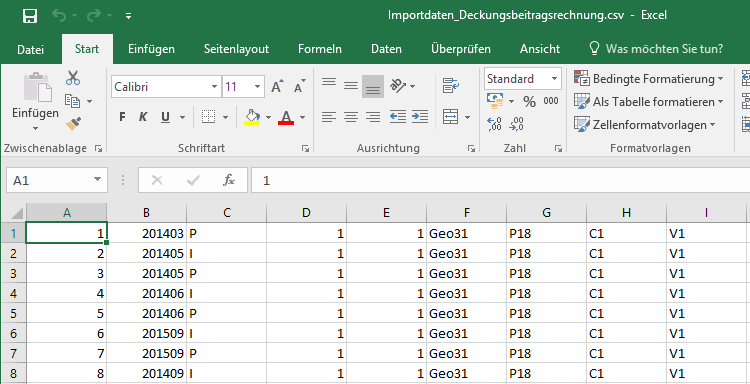
Repository-Datenbankskript per Batch-Datei ausführen lassen
Ein Praxisbeispiel, das zugegebenermaßen so wahrscheinlich nicht oft per SQLCMD gelöst werden wird, stellt die folgende Lösung dar. Mit Hilfe von SQLCMD werden wir uns eine Repository-Datenbank mit allen Objekten erstellen lassen und das mit nur einem Doppelklick. Hierfür brauchen wir auf jeden Fall das mit dem DeltaMaster Service ausgelieferte Repository-SQL-Skript. Jedoch fehlt uns für die vollautomatische Erstellung in diesem Skript ein entscheidender Schritt. Die Erstellung der Datenbank an sich, falls diese noch nicht existiert, wie in meinem Beispiel. Deshalb erstellen wir uns erstmal ein SQL-Skript, welches die Erstellung der Datenbank vornimmt. Dieses würde folgendermaßen aussehen:

Mit diesem Skript würde uns nun zwar eine Datenbank mit dem Namen „DeltamasterRepository“ erstellt werden, aber es wäre auf Ihr noch nicht das Repository-SQL-Skript ausgeführt worden. Dementsprechend müssten wir aus dem neu erstellten Skript heraus, das Repository-SQL-Skript ausführen können. Dies funktioniert auch mit Hilfe von SQLCMD. Hierfür gibt es den Parameter :r, welcher genutzt werden kann um aus einem Skript weitere Skripte auszuführen. Mit dieser Erweiterung, würde unser neues Skript dann folgendermaßen aussehen:
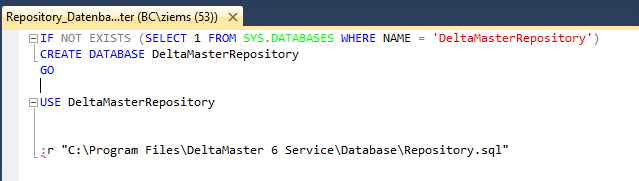
Wichtig in diesem Fall ist auch das vorgelagerte USE-Statement, um uns auf die richtige Datenbank zu beziehen, bevor das Repository-SQL-Skript ausgeführt wird. Anschließend können wir nun das SQLCMD-Statement schreiben, welches dementsprechend wie folgt aussehen würde:
SQLCMD -S localhost\SQL2016 -d master -i C:\Temp\SQLCMD\Repository_Datenbank_erstellen.sql
Dieses können wir dann in eine Batch-Datei schreiben, um es per Doppelklick ausführbar zu machen. Da zurzeit auf der Instanz SQL2016 keine Repository-Datenbank existiert, sollte er nun diese anlegen und anschließend das Repository-SQL-Skript ausführen. Nach Ausführung der Batch-Datei reicht ein Blick ins Management Studio aus, um zu sehen, dass alles wie gewünscht funktioniert hat.
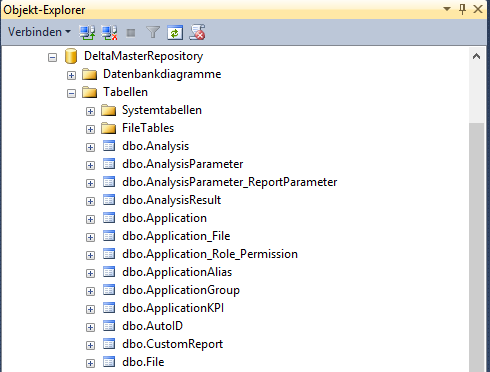
Fazit
Mit SQLCMD lassen sich viele Prozesse und Einsatzszenarien abbilden. Dabei bietet es nicht nur Administratoren bei Ihrer täglichen Arbeit eine gute Unterstützung im automatisierten Ausführen von mehreren aneinander folgenden Skripten. Auch für unsere Tätigkeiten fernab von Performancetests und Portierungen, kann SQLCMD ein probates Mittel sein, wie die Praxisbeispiele zeigen.
