In diesem Blogbeitrag wird zunächst das Dateiformat JSON vorgestellt und gezeigt, wie derartige Dateien komfortabel gelesen werden können. Es wird erläutert, wie die Dateien im JSON-Format zur weiteren Verwendung in den SQL Server importiert werden können. Dabei wird auf die verschiedenen Voraussetzungen und benötigten Berechtigungen Rücksicht genommen. Auf gegebenenfalls auftretende Probleme und Lösungsansätze wird genauer eingegangen.
Einführung in JSON
JSON steht für JavaScript Object Notation. Das Dateiformat wurde hauptsächlich für das Speichern und Übertragen von strukturierten Daten entwickelt. Es handelt sich dabei um eine normierte Textdatei mit der Endung .json, die aus Objekten und Arrays besteht. Die Syntax ist dabei denkbar übersichtlich:
- Anfang/Ende eines Objektes: { }
- Anfang/Ende eines Arrays: [ ]
- Name-Wert-Trenner: :
- Objekt-Trenner: ,
- String-Kennzeichner: “ “
Diese fünf Zeichen reichen aus, um so gut wie jedes JSON-File interpretieren zu können.
Arbeiten mit JSON
Als Beispiel wird die Datei customers.json herangezogen, die Informationen zu zwei Kunden enthält:

In diesem Beispiel gibt es ein Objekt, das aus einem Array namens „customers“ mit zwei Einträgen besteht. Innerhalb dieser Einträge können weitere Objekte und Arrays verschachtelt werden. Hier ist das Objekt „address“ und das Array „phoneNumbers“ unter dem Arrayeintrag verschachtelt.
Das Beispiel ist so formatiert, dass es für das menschliche Auge angenehm zu lesen ist. Das ist in der Praxis meist nicht der Fall. Da Leerzeichen und Zeilenumbrüche beliebig eingefügt werden können, ist eine Datei ohne Zeilenumbrüche syntaktisch korrekt. Um sich einen Überblick über solche Strukturen zu verschaffen, gibt es das Notepad++ Plugin „JSON Viewer“, welches hier kostenfrei heruntergeladen werden kann. Zur Installation muss lediglich unter Berücksichtigung der Befehlssatzarchitektur (x86 bzw. x64) die NPPJSONViewer.dll in den „plugins“ Ordner des Note-pad++Installationsordners eingefügt werden.
Enthält das geöffnete Dokument einen syntaktisch korrekten JSON-String, kann die Struktur bequem über die Tastenkombination Strg + Shift + ALT + J in einer Baumstruktur mit ein-/ausklappbaren Knoten angesehen werden:
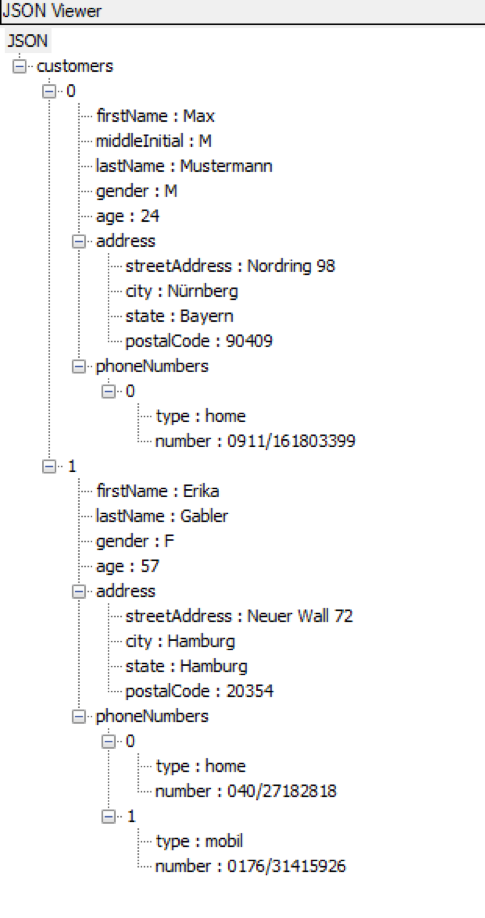
Abbildung 1: JSON Viewer
Import in den SQL Server
Bevor die Struktur in Tabellen eingefügt werden kann, muss der JSON String dem SQL Server zugänglich gemacht werden. Für einmalige Importe ist es ausreichend, den String in das SQL-Skript zu kopieren. Soll allerdings ein automatisierter und wiederholt ausführbarer Prozess implementiert werden, ist diese Vorgehen unzureichend. In diesen Fällen stellt der SQL Server die Funktion OPENROWSET zur Verfügung. Mit der Formatierungseinstellung „SINGLE_CLOB“ kann der komplette Inhalt der Textdatei in eine einzelne Zelle geschrieben werden. Dieser Wert lässt sich wie folgt in einer Variablen speichern:
DECLARE @json varchar(max); SELECT @json = BulkColumn FROM OPENROWSET (BULK 'C:\Users\schwegler\customers.json', SINGLE_CLOB) AS j
Zum Parsen der Struktur wird im Anschluss die Funktion OPENJSON verwendet:
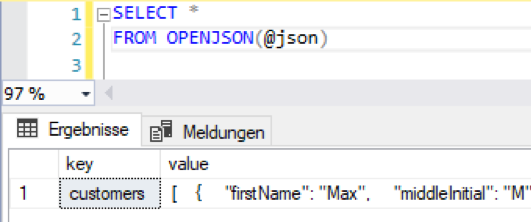 Abbildung 2: OPENJSON
Abbildung 2: OPENJSON
Diese Funktion weist ohne weitere Parameter auf oberster Ebene den Schlüsseln ihre Werte zu. Sind diese Werte geschachtelte Objekte, werden diese im JSON-Format ausgegeben. Explizit können die zu extrahierenden Schlüssel mit Hilfe einer WITH-Klausel angegeben werden:
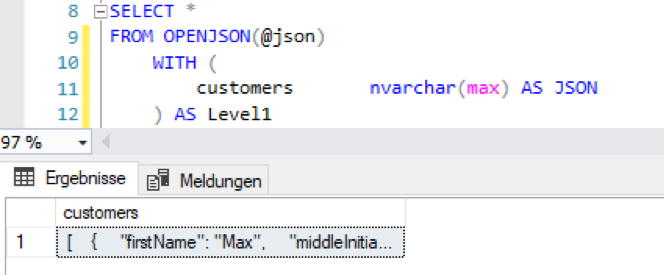 Abbildung 3: OPENJSON mit WITH-Klausel
Abbildung 3: OPENJSON mit WITH-Klausel
Der Zusatz AS JSON nach der Datentypdeklaration ermöglicht es, die nächste Ebene zu parsen:
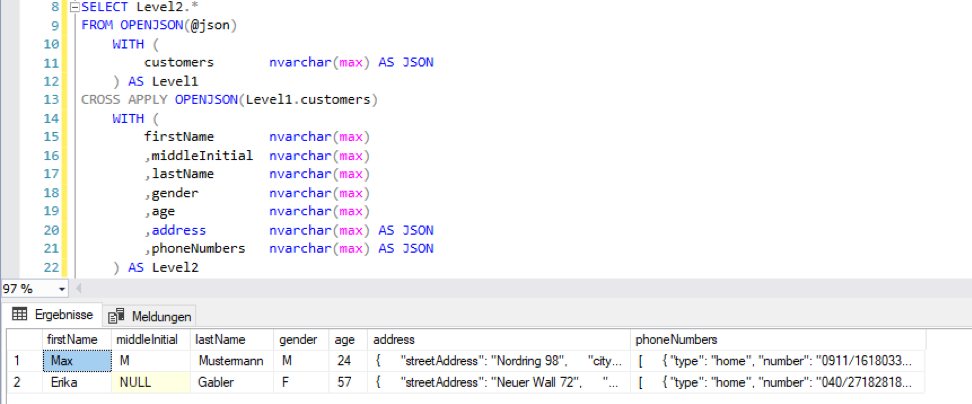 Abbildung 4: OPENJSON mit Cross Apply
Abbildung 4: OPENJSON mit Cross Apply
Es ist möglich Datentypen anzugeben, die von nvarchar(max) abweichen, allerdings ist der Import mit Zeichenkettendatentypen äußerst stabil. Die Einstellung des korrekten Datentyps kann inklusive Fehlerbehandlung im weiteren Verlauf des ETL-Prozesses durchgeführt werden.
Dies kann nun beliebig oft wiederholt werden:
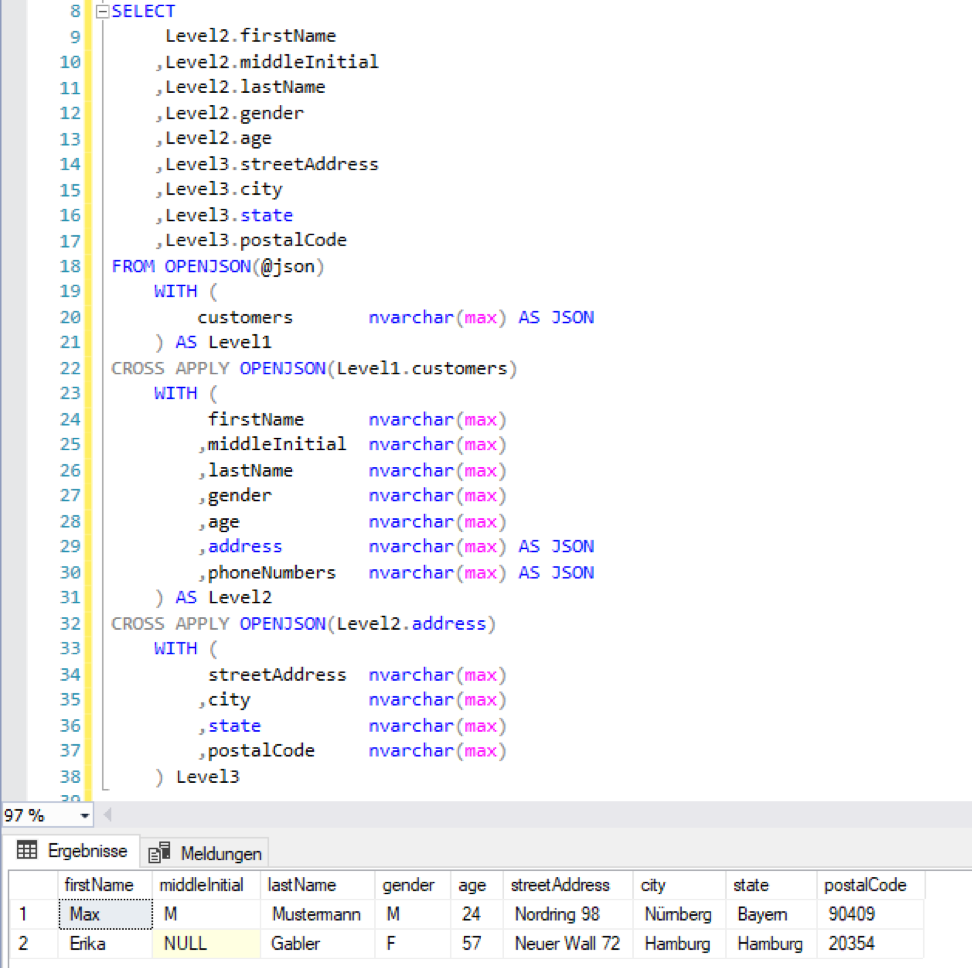 Abbildung 5: OPENJSON mit zwei CrossApplies
Abbildung 5: OPENJSON mit zwei CrossApplies
Die Inhalte von verschachtelten Arrays können abhängig von der Anforderung unterschiedlich behandelt werden. Vor dem Hintergrund des Normalisierungsgedankens von relationalen Datenbankmodellen, ist es allerdings sinnvoll diese Daten in eine gesonderte Tabelle zu schreiben. Dies ist durch eine zweite Abfrage auf dieselbe Variable problemlos möglich. Hierbei müssen nur die Schlüsselattribute in der zusätzlichen Tabelle aufgenommen werden. Hier wird beispielhaft angenommen, dass Vor- und Nachname den Schlüssel beschreiben:

Abbildung 6: OPENJSON für geschachtelte Ebene
Voraussetzungen und mögliche Probleme
Auf dem eigenen System mit Zugehörigkeit zur Serverrolle „sysadmin“ funktioniert das meist ohne großen Aufwand. Bevor man versucht, eine solche Lösung auf einem unbekannten System zu implementieren, muss allerdings geklärt werden, ob alle technischen Voraussetzungen gegeben sind.
Zunächst können Probleme auftreten beim Importieren des Strings mit der Funktion OPENROWSET. Um diese mit der BULK Option durchführen zu können, muss der ausführende User der Serverrolle „bulkadmin“ zugehörig sein.
Des Weiteren muss das Verzeichnis, aus dem die JSON-Datei gelesen wird, für den ausführenden User zugänglich sein. Dies führt allerdings zu Problemen, wenn der SQL Server und der File Server zwei unterschiedliche Server sind. Bei einer Windows-Authentifizierung kann ein Identitätswechsel notwendig werden. Bei einer SQL-Server-Authentifizierung ist es notwendig, dem SQL-Server-Prozesskonto entsprechende Leserechte zu vergeben.
Eine weitere Einschränkung ist die OPENJSON-Funktion. Diese Funktion kann nur auf Datenbanken mit Kompatibilitätsgrad 130 oder höher ausgeführt werden. Das entspricht SQL Servern der Version 2016 oder höher. Um den Kompatibilitätsgrad zu erhöhen muss folgender Befehl ausgeführt werden:
ALTER DATABASE databasename SET COMPATIBILITY_LEVEL = 130
Ein kleineres – eher kosmetisches – Problem entsteht durch die Verwendung von Sonderzeichen in der JSON-Datei. Es kann vorkommen, dass z.B. Umlaute im SQL Server nach dem Import falsch angezeigt werden. Dieses Problem entsteht durch unterschiedliche Encodings der JSON-Datei. Wir haben bisher beim Import gute Erfahrungen mit dem ANSI Encoding gemacht, während der JSON Viewer am stabilsten mit UTF-8 funktioniert. Am besten ist es, direkt beim Export der JSON-Datei aus dem Vorsystem, darauf zu achten, dass die Kodierung mit dem SQL Server kompatibel ist.
Workaround für die OPENROWSET-Problematik
Das Berechtigungsproblem der OPENROWSET-Funktion ist das kritischste, da hier in den meisten Fällen ein Systemadministrator konsultiert werden muss. Die offensichtliche Lösung ist, die Quelldatei auf dem Server abzufragen, auf dem der SQL Server läuft. Dazu muss die Datei nicht unbedingt zusätzlich auf dem Server abgelegt werden. Es ist ausreichend, wenn der Import-Prozess die Datei auf den Server legt, ausliest und im Anschluss wieder vom Datenbankserver entfernt. Dies ist allerdings in den meisten Fällen nicht möglich bzw. nicht erwünscht.
Eine andere Möglichkeit ist, mit Hilfe von SSIS die OPENROWSET-Funktion zu umgehen. Die Idee ist, den String komplett in den SQL Server zu importieren und im Anschluss die OPENJSON-Funktion zu benutzen. Hierfür wird eine Import-Tabelle mit einer Spalte des Typen (n)varchar(max) benötigt. SSIS lässt keine längeren Zeichenketten als 8000 (für varchar) bzw. 4000 (für nvarchar) zu. Daher muss unabhängig von der Formatierung der JSON-Datei, der Inhalt in mehrere Zeilen geschrieben werden. Dies gelingt im SSIS-Verbindungsmanager für Flatfiles, indem kein Spaltentrennzeichen, aber ein Zeilentrennzeichen, welches mindestens alle 8000 bzw. 4000 Zeichen vorkommt (z.B. Komma), angegeben wird:
 Abbildung 7: Verbindungs-Manager für JSON Import
Abbildung 7: Verbindungs-Manager für JSON Import
Diese abgeschnittenen Zeilen werden in die vorbereite Importtabelle eingefügt.
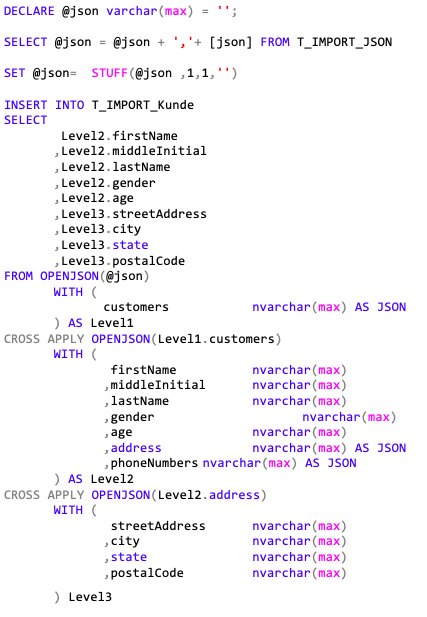
Im Anschluss wird in einem SSIS-Skripttask folgendes SQL-Skript ausgeführt:
DECLARE @json varchar(max) = '';
SELECT @json = @json + ','+ [json] FROM T_IMPORT_JSON
SET @json= STUFF(@json ,1,1,'')
INSERT INTO T_IMPORT_Kunde
SELECT
Level2.firstName
,Level2.middleInitial
,Level2.lastName
,Level2.gender
,Level2.age
,Level3.streetAddress
,Level3.city
,Level3.state
,Level3.postalCode
FROM OPENJSON(@json)
WITH (
customers nvarchar(max) AS JSON
) AS Level1
CROSS APPLY OPENJSON(Level1.customers)
WITH (
firstName nvarchar(max)
,middleInitial nvarchar(max)
,lastName nvarchar(max)
,gender nvarchar(max)
,age nvarchar(max)
,address nvarchar(max) AS JSON
,phoneNumbers nvarchar(max) AS JSON
) AS Level2
CROSS APPLY OPENJSON(Level2.address)
WITH (
streetAddress nvarchar(max)
,city nvarchar(max)
,state nvarchar(max)
,postalCode nvarchar(max)
) Level3Dieses Skript führt die erzeugten Zeilen, unter Berücksichtigung des verwendeten Zeilentrennzeichens, wieder in einen Parameter zusammen und fügt die Daten in eine andere Import-Tabelle ein. Alternativ kann dies auch in eine Prozedur ausgelagert werden, welche dann im Skripttask aufgerufen wird.
Fazit
Wenn alle Voraussetzungen erfüllt sind, funktioniert der Import sowie die OPENJSON-Funktion äußerst stabil. Im Gegensatz zu Importen mit SSIS, bricht der Import nicht ab, wenn sich die Metadaten ändern. Neu hinzugefügte Schlüssel werden einfach ignoriert und können nach Belieben in der WITH-Klausel hinzugefügt werden. Auch das Fehlen eines Attributs in der Quelldatei führt zu keinem Fehler, sondern lediglich zu einem NULL-Eintrag in der jeweiligen Spalte. Auch die Implementierung und Wartung des Imports ist einfach und übersichtlich, sodass die Implementierung eines soliden Prozesses möglich ist. Das entstehende Skript kann hierzu in einer Prozedur gespeichert und im Rahmen des PreProcess des Transform ausgeführt werden. Alternativ kann das Skript oder die Prozedur in ein SSIS-Paket ausgelagert werden, in dem analog zu anderen Flatfile-Formaten, die Importdateien verschoben werden können.
