Seit der Version 213 unterstützt DeltaMaster Modeler die Teilerzeugung des relationalen Snowflake-Schemas. Dies war eine der größten Änderungen in der Version und dient primär der Unterstützung von großen Projektumgebungen. Dabei werden in den neuen inkrementellen Modi nur die Objekte neu erzeugt, die von den letzten Änderungen betroffen sind.
Damit wir möglichst flexibel in der Projektarbeit bleiben und auch verschiedene Alltagssituationen (z. B. im Support) unterstützen, gibt es mehr als einen inkrementellen Modus. Die Unterscheidung der verschiedenen Option und deren Einsatzmöglichkeiten bilden das Thema dieses Blogbeitrags.
Hintergrund
Warum kamen wir überhaupt auf die Idee das Snowflake-Schema nur noch inkrementell aufzubauen? Letztlich waren es viele Anfragen aus dem Projektumfeld, die gezeigt haben, dass der alte „Wir-machen-immer-alles-platt“-Ansatz nicht mehr zeitgemäß ist. Zu häufig werden in den Modellen große Datenmengen gehalten und der komplette Neuaufbau eines Modells nimmt im Projektalltag zu viel Zeit in Anspruch.
Dies wurde insbesondere häufig hinterfragt, wenn nur kleine Änderungen im Modell notwendig waren, wie zum Beispiel die Erweiterung einer einzelnen Measure in einer kleinen Faktentabelle. Warum in dem Fall auch alle anderen (großen) Faktentabellen neu aufgebaut werden mussten, war zu Recht unverständlich. Weiterhin war es unschön, das Modell immer komplett neu aufbauen zu müssen, selbst wenn die Modelländerungen sich eigentlich nur auf Prozeduren auswirkten und nicht auf die Tabellen selbst (z. B. das Ergänzen fehlender Dimensionselemente aus den Fakten).
Der inkrementelle Ansatz unterstützt diese zentralen Anforderungen. Dabei wird jeweils geprüft, welche Objekte von einer Modelländerung betroffen sind. Bei einer Änderung in den Fakten ist dies in der Regel nur die Faktentabelle(n) selbst. Bei Dimensionsänderungen die Tabellen aller Dimensionsebenen sowie die Fakten, welche mit der betroffenen Dimension verknüpft sind. Dabei werden die betroffenen Objekte weiterhin neu gebaut. Sprich, zunächst gelöscht und dann neu erstellt. Dies ist zwar noch nicht optimal, war aber unter Kosten-Nutzen-Aspekten die vernünftigste Lösung und sollte in der Projektpraxis auch nicht allzu schädlich sein, weil man mit dem richtigen Modus trotzdem die Tabelleninhalte erhalten kann. Näheres am Ende des Artikels.
Architektur
Um die Funktionsweise und Möglichkeiten der neuen Version zu verstehen, muss man zunächst die neue Architektur verstehen. Bis zur Modeler Version 212 wurden die Snowflake-Objekte direkt aus der EXE heraus erzeugt, sprich, sie waren gekapselt, so dass man an den T-SQL-Code der Objekte erst nach deren Erzeugung herankam. Zunächst mussten die Objekte erstmal erzeugt bzw. geändert werden. Ab der Version 213 ist eine Zwischenebene eingezogen worden, die den Code aller Snowflake-Objekte offenlegt. Das hat den entscheidenden Vorteil, dass man den Code einfacher zwischen Umgebungen übertragen kann (Stichwort: Dev, Test, Prod) und dass man auch an den Code ohne dessen Ausführung herankommt. Genau diese machen wir uns in bestimmten Create-Snowflake-Modi zunutze. Folgendes Schaubild verdeutlicht die Architekturänderung:
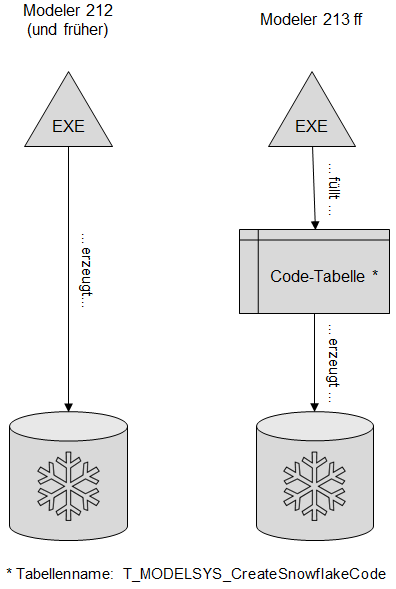
Abbildung 1: Create-Snowflake-Architektur früher und heute
Die vier Modi
Überblick
Mit der neuen Architektur eröffnen sich einige neue Einsatzmöglichkeiten und unterstütze Szenarien für die Änderung und Erweiterung eines Snowflake-Schemas.
Welche Variante dabei ausgeführt wird, hängt an der Einstellung in der Modeler GUI:
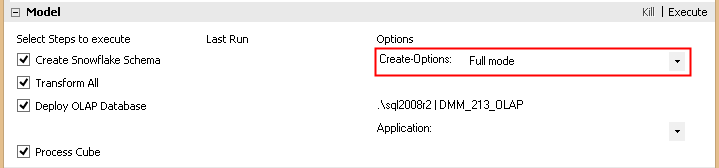
Abbildung 2: Selektionsmöglichkeit der Create-Snowflake-Modi in der GUI
Abhängig davon wird beim Klick auf „Execute“ eine der vier verfügbaren Varianten ausgeführt.
Es existieren ein vollständiger Modus sowie drei Varianten der inkrementellen Ausführung:
- Full Mode
- Incr. mode: code & db objects (incl. tables)
- Incr. mode: code & db objects (wo tables)
- Incr. mode: only Snowflake-code
WICHTIG: Um die inkrementelle Erzeugung nutzen zu können, muss zwingend mindestens einmal eine vollständige Erzeugung im „Full Mode“ durchgeführt werden.
Im Folgenden werden die verschiedenen Varianten erläutert.
Full Mode
Erzeugt werden:
Tabellen: alle
Views: alle
Prozeduren: alle
Code: alle
Der „Full Mode“ funktioniert prinzipiell exakt so wie das „Create Snowflake“ in älteren Modeler-Versionen. Sprich alle Objekte des Snowflake-Schemas werden bei einer Ausführung gelöscht und neu erzeugt. Einziger Unterschied ist, dass auch der Full Mode jetzt die oben beschriebene Code-Tabelle verwendet, um seine Objekte aufzubauen und zu löschen.
Der Full Mode eignet sich grundsätzlich für alle kleinen Modelle bei denen Ladezeiten keine Rolle spielen. Obendrein ist er empfehlenswert wenn sehr viel an einem Modell verändert wurde. In dem Fall würden voraussichtlich die Laufzeitvorteile einer inkrementellen Variante vom Overhead der inkrementellen Erzeugung „aufgefressen“ werden. In so einem Fall wäre die Nutzung der Backup-/Restore-Prozeduren in Kombination mit einem „Full Mode“ vermutlich die effizientere Variante.
Incr. mode: code & db objects (incl. tables)
Erzeugt werden:
Tabellen: nur die geänderten und die davon abhängigen
Views: alle
Prozeduren: alle
Code: alle
Ausgeschrieben würde der Modus „Incremental mode: Code & Database objects (including tables)“ heißen, aber dafür hatten wir nicht genug Platz in der GUI…
Es handelt sich dabei um den eigentlichen (und vermutlich am häufigsten genutzten) inkrementellen Modus, da hier nach Ausführung keinerlei manueller Eingriff mehr notwendig ist.
Wichtig bei allen inkrementellen Varianten zu verstehen ist, dass der Code aller nicht datenhaltenden Objekte (Views & Prozeduren) immer komplett neu erstellt wird (also nicht inkrementell). Die inkrementelle Behandlung bezieht sich grundsätzlich nur auf die Tabellen und die zugehörigen Schlüssel. Eine inkrementelle Behandlung der programmatischen Objekte war nicht wirklich notwendig und wäre deutlich aufwendiger geworden.
Weiterhin ist es wichtig zu verstehen, welche Objekte von einer Modellanpassung betroffen sind. Da dieses Thema etwas ausladender ist, konzentrieren wir uns im vorliegenden Blogbeitrag auf die wichtigsten Änderungen, nämlich die von „normalen“ Fakten- und Dimensionsebenenobjekten. Dies sind Anpassungen in den Berichten: „Levels“, „Level source columns“, „Level attributes“, „Level attribute source columns“ sowie “Measure groups”, “Measure group source table”, “Meas.grp. dimensions”, “Meas.grp. dimension source columns”, “Meas.grp. measures”, “Meas.grp. measure source columns”, “Meas.grp. info” und “Meas.grp. info source columns”.
Werden in den Fakten (also allen „Meas.grp….“ Berichten) Änderungen vorgenommen, betreffen diese immer nur die Faktentabelle selbst. Dies dürfte der Regelfall für die Nutzung der inkrementellen Logik sein. Werden Dimensionen bzw. Dimensionsebenen verändert (also in allen „Level…“ Berichten) wirkt sich dies auf die Ebenentabelle selbst, auf alle an den Level angebundenen Fakten (!) und alle Kinderebenen unterhalb des geänderten Levels (!) aus. Würde also beispielsweise die Ebene „Monat“ in einem typischen Modell geändert, wären auch die meisten Faktentabellen von der Änderung betroffen. Auch hier wäre dann im Falle einer inkrementellen Ausführung die Nutzung der Snowflake-Backup- und -Restore-Routinen vermutlich angebracht.
Wie oben bereits erwähnt, ist es wichtig, dass vor der ersten Nutzung dieses inkrementellen Modus einmal ein Snowflake-Schema im „Full Mode“ erzeugt wird. Andernfalls können die zu ändernden Objekte nicht sauber identifiziert werden.
Incr. mode: code & db objects (w/o tables)
Erzeugt werden:
Tabellen: keine
Views: alle
Prozeduren: alle
Code: alle
Genau genommen handelt es sich hier gar nicht um eine inkrementelle Verarbeitung, weil die Objekttypen für sich jeweils entweder gar nicht oder komplett erneuert werden. In dem Fall wird alles außer den Tabellen neu erstellt. Sprich die Daten bleiben in jedem Fall unberührt von dem Lauf.
Gedacht ist dieser Modus, um alle Modelländerungen schnell ins Modell zu bekommen, welche die Tabellenstruktur nicht verändern. Also zum Beispiel eine Anpassung der Quelltabelle oder –spalte (welche ja nur die Prozeduren und Views betrifft) oder auch das Aktivieren der Option „Add missing Dim.elem. from MG Source table“ aus dem Bericht „Meas.grp. dimension source columns“ (auch „DimProc“ genannt). Letzteres ist ein häufiger Fall aus dem Supportumfeld bei dem Fakten mit fehlenden Stammdaten geliefert werden. Im Grunde fehlt hier nur eine P_DIM-Prozedur um das Auffüllen der Dimensionselemente aus den gelieferten Fakten zu erreichen – genau das leistet dieser Modus.
Weiterhin ist dieser Modus auch gut nutzbar, um zum Beispiel eine Measure in einer großen Tabelle zu ergänzen. Die Anpassung der Tabelle kann man manuell per ALTER TABLE ausführen (so dass die Daten erhalten bleiben) und anschließend lässt man über diesen Modus die komplette Programmlogik außen herum erzeugen. Gegen einen manuellen Eingriff ins Snowflake-Schema spricht grundsätzlich nichts.
Auch für diesen Modus ist es wichtig zuvor einmal einen „Full Mode“ auszuführen.
