Es ist mittlerweile kein Geheimnis mehr, dass DeltaMaster eine exzellente Planungsoberfläche ist. Fast jedes zweite Projekt dreht sich um das spannende Thema Planung. Das Management der eingegebenen Anwenderdaten in den Tiefen des Microsoft SQL Servers ist da schon um einiges geheimnisvoller. Will man ein performantes OLAP-Planungssystem entwickeln, muss man sich mit dem Thema Datenlogistik und der speziellen Art der Plandatenspeicherung in den Analysis Services auseinandersetzen. Die sogenannte “Rückverdichtung” ist eine Möglichkeit, die Klippen zu umschiffen. Sie wird im nachfolgenden Blogbeitrag dargestellt.
Die Basisarchitektur
Um die Notwendigkeit der Rückverdichtung zu verstehen, muss man zunächst die Architektur der Analysis Services verstehen. Unter einem SQL-Server-Würfel liegt immer eine relationale Faktentabelle (“T_FACT_…”), welche alle dargestellten Würfeldaten auf der untersten Ebene enthält. In einem Planungssystem liegen hier meist die Ist-Daten. Wird der Würfel verarbeitet, werden alle Daten dieser Tabelle in den Würfel geladen. Die Analysis Services kümmern sich dann lediglich noch um die Aggregation der geladenen Werte. Das Schaubild verdeutlicht die Architektur (klicken zum Vergrößern):
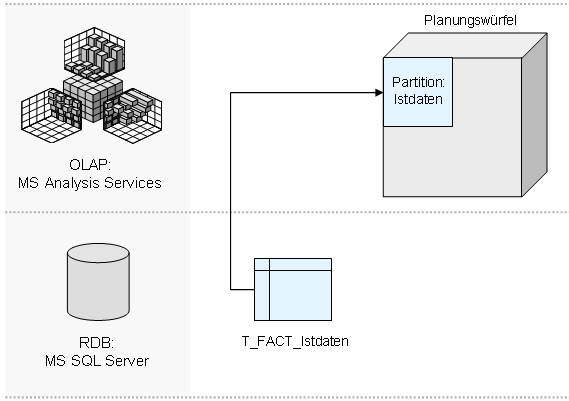
Diese Architektur gilt sowohl für rein lesende Reportingdaten, als auch für eingegebene Plandaten. Erfasst ein Anwender Zahlen in dem OLAP-Würfel, werden diese ebenfalls in eine relationale SQL-Server-Tabelle (“T_WriteTable_…”) geschrieben und nicht etwa direkt in den Würfel:
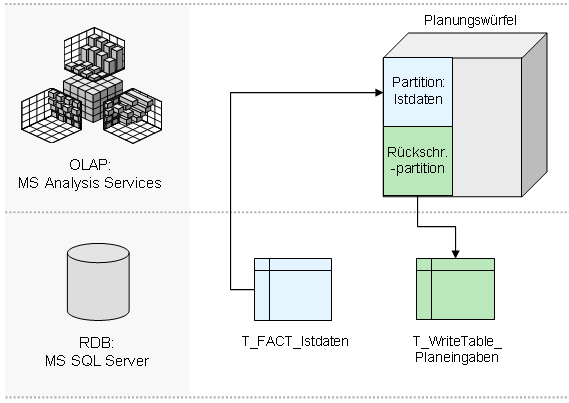
Die Problemstellung
Diese Rückschreibtabelle entspricht in ihrer Struktur grob der Struktur der Faktentabelle, enthält allerdings noch zusätzlich Audit-Informationen. In jedem eingegebenen Datensatz werden der Zeitpunkt der Änderung und der Anwender vermerkt, der den Satz geändert hat. Und damit nähern wir uns dem Kern des Problems. Die Tabelle speichert wirklich jede Änderung der Daten und nicht den absoluten Wert einer Zelle.
Nehmen wir folgendes Beispiel:
- Aufruf des Berichts, Zelle zeigt den Wert 50:

- Eingabe des Werts 45:
![]()
- Eingabe des Werts 52:

erzeugt folgenden Datensatz in der Rückschreibtabelle:

Diese Logik der Datenspeicherung ist hervorragend, um nachzuvollziehen, was auf der Datenbank tatsächlich geändert wurde, und wird auch immer wieder gern von Wirtschaftsprüfern gefordert. Daher ist die Grundidee der Speicherung von Änderungen nicht verkehrt. Problematisch ist diese Art der Datenspeicherung jedoch unter dem Performanceaspekt. Die Menge der Datensätze, die in einer Planungsrunde erzeugt wird, kann um ein Vielfaches über der Menge an Basiszellen im Würfel liegen. Insbesondere wenn man das sogenannte “Splashing”, also die Eingabe auf Summenelementen, nutzt. Wird im Splashing-Verfahren in eine leere Zelle eingegeben, wird unterhalb dieser Zelle der komplette theoretische Datenraum im Würfel mit entsprechend kleinen Werten beschrieben. Die OLAP-Entwickler unter der Leserschaft wissen, was das bedeutet – unser interner Highscore liegt bislang bei 47 Millionen erzeugten Datensätzen mit nur einer Eingabe…
Die Menge an Datensätzen in der Planungstabelle ist insbesondere in SQL-Server-Systemen der Version 2005 ein Problem. Hier können Rückschreibepartitionen nur als ROLAP-Partition angelegt werden, was bedeutet, dass alle Aggregationen zur Abfragezeit berechnet werden. Das allein ist noch kein Problem. Dramatisch wird es erst, wenn man das Abfrageverhalten bei steigender Anzahl Datensätze in der Rückschreibetabelle beobachtet. Der SQL Server verhält sich hier leider nicht linear, wie man es erwarten würde. In einem großen Datenmodell konnten wir beispielsweise einen exponentiellen Performanceeinbruch beobachten. Ein Planungsbericht, der vorher knapp 5 Sekunden Ladezeit hatte, brach auf eine Ladezeit von über 5 Minuten ein, nachdem die Rückschreibetabelle mit knapp 2 Millionen Datensätzen gefüllt war. Die 2 Millionen konnten wir reproduzierbar als ungefähre Grenze des Performanceeinbruchs ausloten. Allerdings hängt das maßgeblich vom jeweiligen Datenmodell ab und kann sich in einer anderen Umgebung vollkommen anders verhalten. Fakt ist jedoch, dass Maßnahmen ergriffen werden müssen, um die Menge an Datensätzen in der Rückschreibetabelle klein zu halten. Nur so kann langfristig eine hervorragende Systemperformance erzielt werden – und diese ist definitiv einer der kritischsten Erfolgsfaktoren eines Planungssystems.
Alles besser mit SQL Server 2008?
Eine der lang erwarteten Neuerungen der SQL-Server-Version 2008 war die MOLAP-Planung. Sprich: Die Rückschreibepartition kann erstmals auch als echte MOLAP-Partition angelegt werden. In MOLAP-Partitionen können, im Gegensatz zu in ROLAP-Partitionen, Aggregationen vorberechnet werden. Das führt insbesondere bei Analysen auf aggregierten Ebenen zu Performancegewinnen. Schaut man jedoch unter die Motorhaube des neuen SQL Servers, wird man schnell etwas desillusioniert. Die Basisarchitektur hat sich nicht wirklich verändert. Nach wie vor existiert die beschriebene relationale Rückschreibetabelle mit entsprechender Änderungslogik. Daher ist der zu erwartende Performanceeinbruch vermutlich nicht ganz so groß, aber auch für eine MOLAP-Partition gibt es angenehmere Szenarien, als 47 Millionen Datensätze verwalten zu müssen. Von daher empfiehlt es sich auch in der 2008er Version, die Größe der Rückschreibetabellen möglichst klein zu halten.
Einmal Verdichten und zurück
Was also tun? Einfach Löschen geht natürlich nicht. Die Datensätze gruppieren und alle wertvollen Audit-Informationen verlieren ist auch keine charmante Lösung. Wie so oft liegt die Wahrheit dazwischen. Üblicherweise erweitern wir die Datenbank um zwei weitere relationale Tabellen und den Würfel um eine Partition. Zum einen wird eine Kopie der ursprünglichen Faktentabelle angelegt, die sogenannte WriteBack-Tabelle (“T_WriteBack_…”). Hierin werden die verdichteten Plandaten gespeichert. Das bedeutet, alle eingegebenen Änderungen werden konsolidiert, und das Ergebnis wird in die WriteBack-Tabelle geschrieben. Damit enthält die WriteBack-Tabelle letztlich wieder den tatsächlichen Wert der Zelle. Um bei der Gruppierung die Audit-Informationen nicht zu verlieren, wird schließlich noch eine Kopie der Rückschreibetabelle angelegt, in der bei jedem Rückverdichtungsprozess eine 1:1-Kopie der gespeicherten Änderungen abgelegt wird. Diese Archivtabelle (“T_WriteTable_…_Archiv”) wird nicht direkt im Würfel als Partition angebunden, sondern dient nur als Datenspeicher, um jederzeit nachvollziehen zu können, wann was von wem ins System eingegeben wurde. Diese Tabelle ist eine nicht zu unterschätzende Informationsquelle bei der späteren Systemvalidierung. Die Architektur für eine Rückverdichtungslogik sieht also folgendermaßen aus:
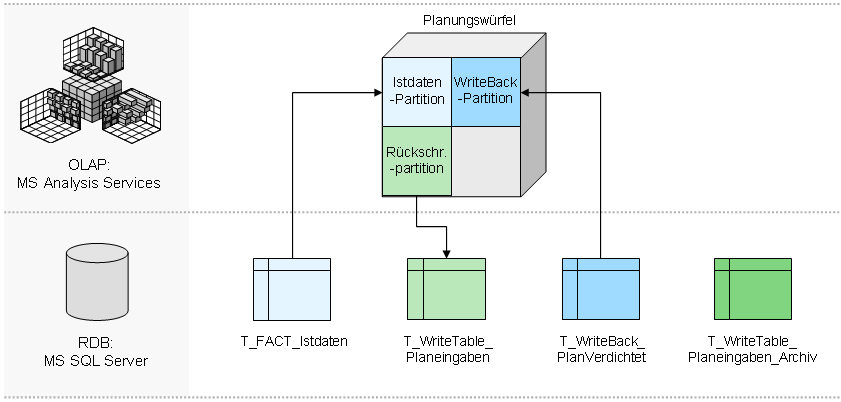
Sind die Tabellen generiert, fehlt “nur” noch der Datenfluss, bei dem sich folgendes Vorgehen bewährt hat:
- Sicherung aller Plandaten von der Rückschreibtabelle in die Archivtabelle
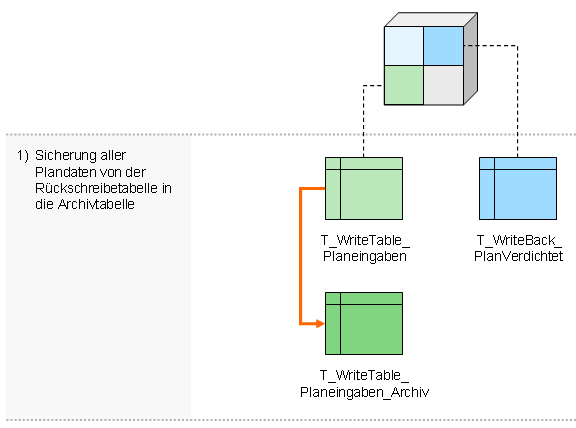
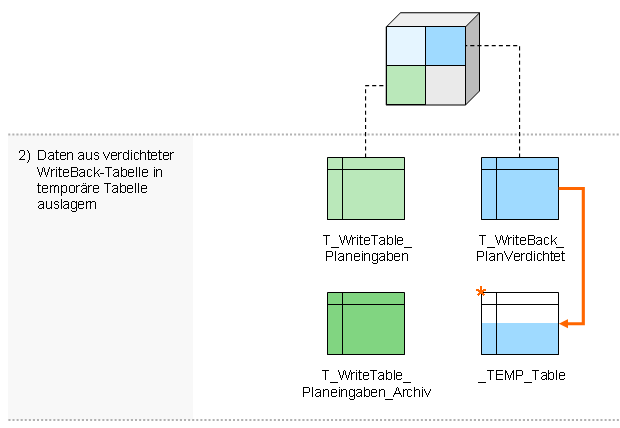
- Daten aus verdichteter WriteBack-Tabelle in temporäre Tabelle auslagen
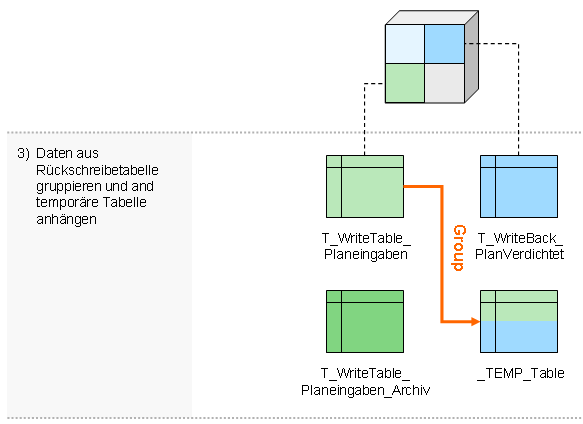
- Daten aus Rückschreibtabelle gruppieren und an temporäre Tabelle anhängen
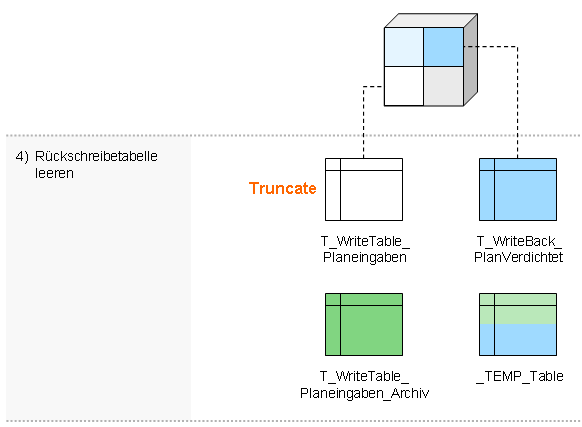
- Rückschreibtabelle leeren
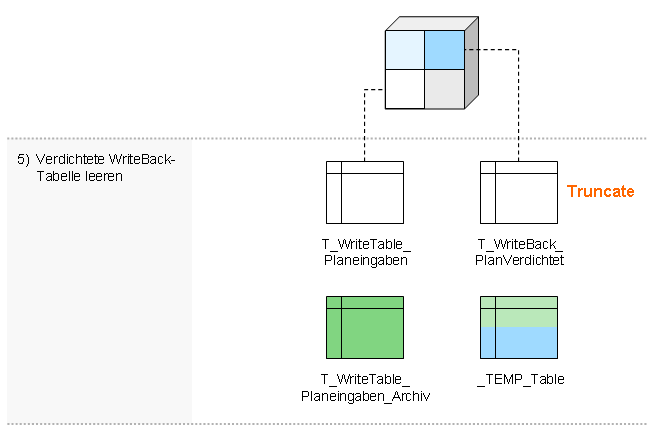
- Verdichtete WriteBack-Tabelle leeren
- Alle Sätze aus temporärer Tabelle gruppiert in WriteBack-Tabelle einfügen
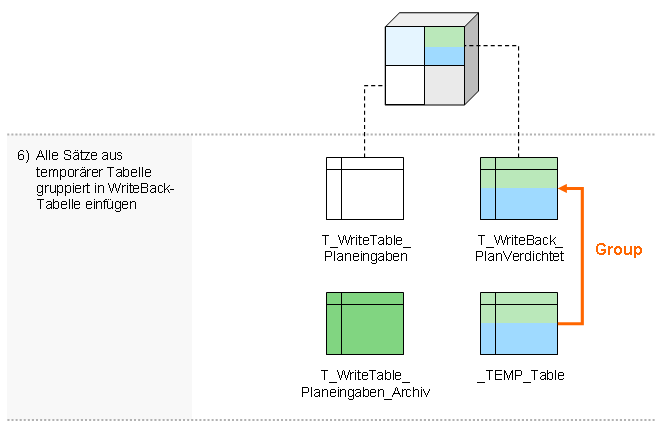
- Temporäre Tabelle löschen
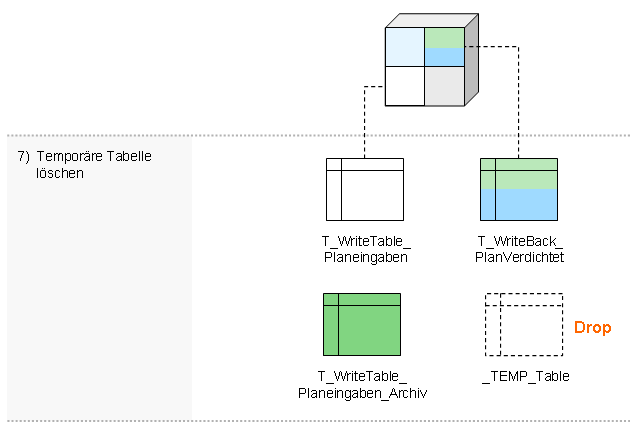
Der siebenstufige Standardprozess (siehe Beispiel in Link) wird üblicherweise in die nächtlichen Aufbereitungsroutinen eingebunden, sodass die Rückschreibetabellen jede Nacht aufgeräumt werden.
Die Grenzen der Rückverdichtung
Der dargestellte Prozess sollte nur für Rückverdichtungen genutzt werden, wenn nicht gleichzeitig auf dem System eingegeben wird. Andernfalls kann es theoretisch zwischen Schritt 3 und 4 dazu kommen, dass neue Daten in die Rückschreibtabelle geschrieben werden, welche aber im Schritt 3 noch nicht in die temporäre Tabelle gesichert wurden. Diese würden dann im nachfolgenden Schritt gelöscht werden. Doch auch hier gibt es verschiedene Lösungsmöglichkeiten. Ein projekterprobter Ansatz ist die teilweise Rückverdichtung der Rückschreibetabelle. Bei der Sicherung der Daten kann man beispielsweise von der zuletzt gespeicherten Eingabe in die Rückschreibtabelle eine Millisekunde zurückgehen und nur alle Daten vor diesem Zeitpunkt verdichten und später löschen. So kann der Verdichtungsprozess auch parallel während der Plandateneingabe durchgeführt werden, ohne Daten zu verlieren. Das ist insbesondere dann wertvoll, wenn in der heißen Planphase tagsüber Millionen von Werten generiert wurden und die Systemperformance am Boden ist. Der einzige Ausweg ist dann die Rückverdichtung im laufenden Betrieb.
Hat man die Rückverdichtung im Einsatz, muss man außerdem sehr genau darauf achten, dass die nächtliche Verarbeitung des Würfels ohne Fehler durchläuft. Andernfalls können die Folgen verheerend sein. Da die Plandaten durch die Rückverdichtung aus der ROLAP-Partition gelöscht und in die verdichtete MOLAP-Partition geschrieben werden, sind diese erst wieder nach erfolgreicher Verarbeitung sichtbar. Schlägt die Verarbeitung fehl, sieht man die zuletzt eingegebenen Daten nicht im Würfel. Die Reaktion der Anwender darauf ist meist die gleiche: Unwissend, dass die Daten nach wie vor in der relationalen Datenbank gespeichert sind, gibt man die Daten meist einfach erneut ein. Wird dann der Würfel wieder ordnungsgemäß verarbeitet, sind alle Werte verdoppelt. Um hier nicht das Vertrauen der Anwender zu verlieren, hat sich eine Sperrlogik bewährt, welche Eingaben im Fehlerfall verhindert.
Weiterhin ist die Pflege der Rückverdichtungsprozesse und der zugehörigen Tabellen recht aufwändig. Wird beispielsweise eine Kennzahl im Würfel erweitert, sind alle Tabellen und Prozesse anzupassen. Die Anpassung wird zusätzlich durch die interne Struktur der Rückverdichtungstabelle erschwert. Der SQL Server ergänzt alle Spaltennamen um einen laufenden Index. Da weiterhin zuerst die Kennzahlen und dann die Dimensionen in den Rückschreibetabellen angelegt werden, bedeutet eine Erweiterung einer Kennzahl die Umbenennung aller nachfolgender Spalten der Rückschreibetabelle (und natürlich der zugehörigen Archivtabelle) sowie die Anpassung aller Rückverdichtungsprozesse. Darum ist der manuelle Aufwand für die Pflege der Rückverdichtung nicht zu unterschätzen.
Der Retter der Faulen
Da unsere Maxime von jeher war, unsere Beratungsprojekte möglichst schlank zu halten, haben wir jene Standardanforderung in Planungssystemen mit Hilfe von DeltaMaster Modeler automatisiert. Die Darstellung zeigt den verbleibenden Arbeitsaufwand, um die Rückverdichtung im Modeler zu konfigurieren und aktuell zu halten:
Nach der Konfiguration legt Modeler automatisch alle notwendigen Tabellen (Rückschreibe-, WriteBack- und Archivtabelle) an, kümmert sich um den laufenden Index und generiert vollautomatisch die gehörigen Rückverdichtungsprozesse in Form von SQL-Prozeduren.
Sollten Sie Ihre Rückverdichtung noch manuell bauen, sprechen Sie doch einmal Ihren Bissantz-Berater an. Der zeigt Ihnen gerne noch weitere Möglichkeiten, Ihre OLAP-Datenbanken mit Hilfe von DeltaMaster Modeler effizienter zu entwickeln.
