Software Change Management (SCM)-Process in der Praxis
Die meisten Anwendungssysteme – und somit auch unsere DeltaMaster-Welt – werden in einer Mehrsystemlandschaft betrieben. Typisch in aktuellen IT-Infrastrukturen sind 2- oder 3-Systemlandschaften. In einer 2-Systemlandschaft sprechen wir von einem Entwicklungssystem (DEV) und einem Produktivsystem (PROD). In einer 3-Systemlandschaft wird zusätzlich noch ein Testsystem (QS) für unterschiedliche Benutzergruppen und Testszenarien zwischengeschaltet. Grundsätzlich ist die Verwendung von solchen Mehrsystemlandschaften dringend zu empfehlen. Nur so können notwendige und gewünschte Änderungen separat vom produktiven System entwickelt, getestet und vom Kunden fachlich abgenommen werden.
Eine Mehrsystemlandschaft bedeutet aber auch einen Mehraufwand während der Entwicklungszyklen. Es muss ein Prozess definiert sein wie die Entwicklungen von DEV zu PROD möglichst automatisiert übertragen werden können. Außerdem müssen in geeigneten Intervallen die produktiven Daten vom PROD auf das DEV zurückgespielt werden, um möglichst repräsentative Testergebnisse bereits während der Entwicklung gewährleisten zu können.
Schematische Darstellung:
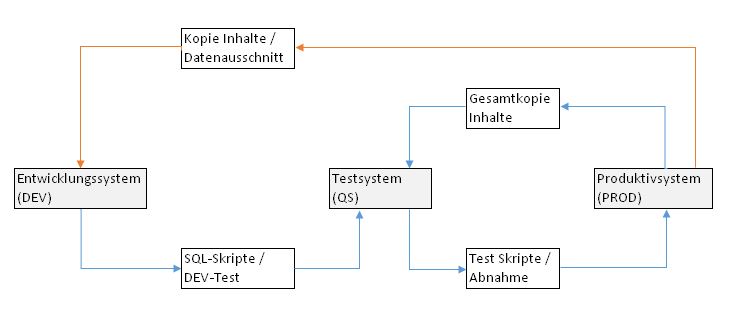
Abbildung 1: Sequenzdiagramm, in Rot der in diesem Blog betrachtete Prozessschritt
In der Praxis wird häufig ein Backup der produktiven Quelldaten in der Entwicklungsdatenbank eingespielt. Allerdings bedeutet dies auch, dass während der Entwicklung die Verarbeitungszeit auf dem DEV meist größer ist als auf dem produktiven System. Somit wird unnötigerweise die Weiterentwicklung künstlich verlangsamt; unter Umständen auch bedingt durch meist weniger leistungsfähige Hardware auf DEV. Die Zeit ist aber genau das, was wir effizient nutzen wollen. Wie können wir also möglichst aussagekräftige Testergebnisse bei kleinen Verarbeitungszeiten erreichen?
Genau dieser Umstand ist mir kürzlich in einer relativ großen Infrastruktur begegnet. Bei der Recherche bin ich auf eine sehr elegante Funktion des SQL-Servers gestoßen – diese möchte ich heute einmal im Detail vorstellen.
Szenario
Als Beispiel dient unsere bekannte Chair-Demodatenbank (entspricht PROD). Zusätzlich legen wir parallel eine neue, leere Datenbank Chair_Sample (entspricht DEV) an.
Schaffen wir uns zunächst einen Überblick über die Kombinationen von Wertarten und Vertriebsbereichen in unserer produktiven Datenbank:
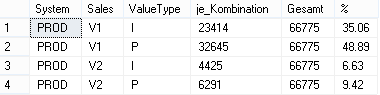
Abbildung 2: Überblick Verteilung
Insgesamt enthält die Quelltabelle T_Import_Deckungsbeitragsrechnung 66775 Datensätze. In dem erwähnten Kundenprojekt haben wir den gleichen Lösungsweg auf einer Basistabelle mit ca. 42 Millionen Datensätzen in einer Ausführungszeit von circa 22 Sekunden implementiert.
Die Gründe für die Beibehaltung der Datenverteilung unter gleichzeitiger Minimierung ihrer absoluten Anzahl sind:
- Periode: Die Zeitreihe soll möglichst vollständig bleiben, um auch DeltaMaster Analysemethoden wie zum Beispiel die Zeitreihenanalyse testen zu können.
- Wertart: Wichtig ist, dass auch hier alle Elemente vorhanden sind; z. B. in der Berichtsentwicklung von Abweichungselementen. Das Layout in den Pivot Tabellen und Kombicockpits soll dabei nicht verändert werden.
- Jegliche projektspezifische Dimension (hier: Sales)
- Test der Aufbereitung während der Transformation: Ein einfacher Ausschnitt würde eventuelle Probleme in den Daten der Merkmale wie z. B. Kostenstellen, Kostenarten oder Konten verschleiern und erst bei Ausführung auf der produktiven Datenbank einen Fehler ergeben.
- Strukturelle Funktion mit zusammengesetzten Schlüsseln: Im erwähnten Kundenprojekt waren mandantenabhängige Dimensionshierarchien implementiert. Der Schlüssel besteht aus Mandant und Kostenstelle, wobei die Dimension basierend auf den Bewegungsdaten erstellt werden musste. Das Quellsystem konnte noch keine echten Stammdaten liefern, da es sich noch in einer früheren Projektphase befand.
Im einfachsten Fall würden wir ein Select Top 1000 von der Tabelle aus dem produktiven System als Basis in unsere Entwicklungsdatenbank übernehmen. Mit der geringen Anzahl an Datensätzen in der Chair-Datenbank bliebe sogar die Datenverteilung einigermaßen erhalten.
Aber: Die Verteilung der Merkmalskombinationen hängt bei dieser Methode von der Datenbanksortierung und eben auch der Gesamtanzahl der Datensätze ab.
Verändern wir den Wert für die Ergebnismenge von TOP 1000 zum Beispiel auf TOP 10000 steigt natürlich auch wieder die Kombinatorik, aber eben auch die Gesamtanzahl und somit die Transformationszeit. Wünschenswerter ist es in diesem Fall, eine Art zufälligen und steuerbaren Mix für unsere DEV-Datenbank zu übernehmen. Zufällig, um bei wiederholter Ausführung andere Daten in der Entwicklung zu haben und nicht „ebenfalls zufällig“ eine funktionierende Kombination der Merkmale.
Die Lösung
Es gibt ein solches Hilfsmittel im Microsoft SQL-Server. Es heißt schlicht TABLESAMPLE.
Die Anwendung ist kinderleicht:

Select *
FROM
[Chair].[dbo].[T_Import_Deckungsbeitragsrechnung]
TABLESAMPLE (1 PERCENT)Im FROM-Bereich der Abfrage einer Tabelle wird der TABLESAMPLE-Befehl einfach ergänzt. Danach folgt in Klammern entweder eine relative (siehe Abbildung) oder eine absolute Anzahl der zurückzuliefernden Ergebniszeilen. Absolut erfolgt die Angabe einfach mit TABLESAMPLE (1288 ROWS)
Einige Einschränkungen bestehen jedoch: Die Funktion kann nicht angewendet werden bei
- Tabellen, die über LinkedServer (Verbindungsserver) eingebunden sind.
- Tabellen, die aus einer Tabellenwertfunktion zurückgeliefert werden.
- Tabellen, die über OPENXML abgeleitet wurden.
Microsoft weist darauf hin, dass es sich um Stichproben und nicht um echte zufällige Datensätze handelt. Hintergrund ist die physische Speicherverwaltung in SQL-Server und wie die Datentabelle in den Speicherseiten vorliegt. Für das hier beschriebene Szenario kann die Funktion auch noch um die Erweiterung SYSTEM ergänzt werden. Die Verwendung ist optional, sorgt aber für die Verwendung der einzigen echten Stichprobenmethode.
Beim Testen des Befehls fällt auf, dass sich im Unterschied zu der TOP-Funktion mit jeder Ausführung die Anzahl der Zeilen ändert. Wenn gewünscht, kann aber auch dies unter Verwendung von REPEATABLE (beliebige Zahl) fixiert werden. Dies ist aber nicht notwendig, denn man möchte durchaus eine gewisse Zufälligkeit innerhalb seines eingeschränkten Abfrageergebnisses erreichen.
Führen Sie sich noch einmal Abbildung 1 vor Augen. In der Praxis kann diese Funktion sehr elegant in einer Prozedur (s. Anhang) gekapselt und dann in einem automatisierten Prozessschritt auf einem beliebigen SQL-Server ausgeführt werden. Der Aufruf der Prozedur sieht wie folgt aus:
![]()
exec P_BC_TableSample 'Chair', 'Chair_Sample', 'dbo',
'T_Import_Deckungsbeitragsrechnung', 'Sales', 'PERCENT', '2'Im Ergebnis sehen wir nun folgende Verteilung der Daten in unserer Importtabelle (PROD vs. DEV):
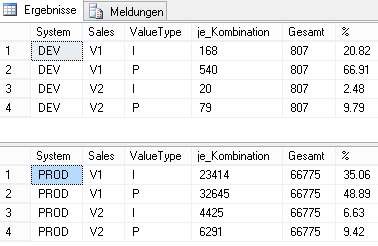
Abbildung 3: Relative Verteilung der Daten
Wie man sehr gut erkennen kann, ist die relative Verteilung der Daten in den beiden Datenbanken nicht gleich, aber das Verhältnis je Kombination gemessen an der Gesamtanzahl ist ähnlich. Somit ist die Kombination der Daten für den Zweck bestmöglicher Testergebnisse repräsentativ. Ferner handelt es sich auch nicht um exakt 2 Prozent der Menge von Quelldaten, sondern um eine Variation dieses Faktors.
Fazit und Ausblick
Die beschriebene Prozedur ist noch nicht zu 100 % dynamisch. Sie könnte aber als Grundlage für den DeltaMaster Modeler dienen, so dass auf Knopfdruck Testtabellen erstellt werden können.
Es ist immer erstaunlich, welch nützliche Funktionen bereits von den Microsoft-Entwicklern im Produkt integriert sind. Leider kennt man einfach zu wenige.
Wir können die Verwendung dieser Funktion sehr empfehlen. Kleiner Aufwand, große Wirkung.
Anhang – Die Prozedur

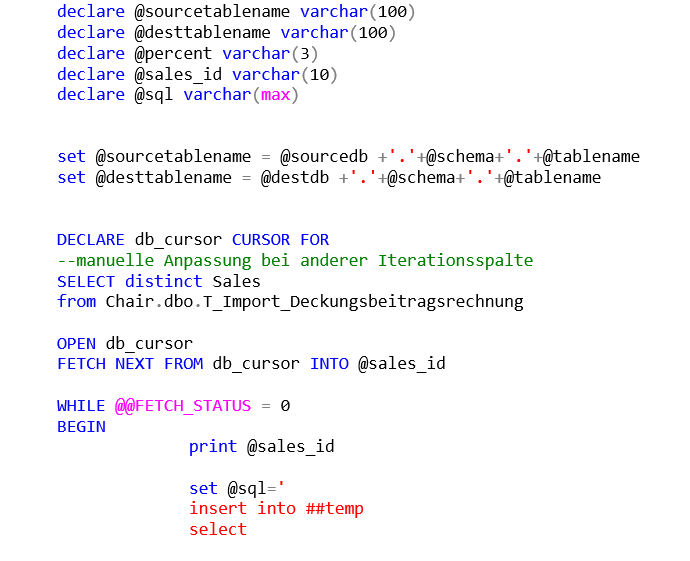

create procedure P_BC_TableSample
(
@sourcedb varchar(100)
,@destdb varchar(100)
,@schema varchar(100)
,@tablename varchar(100)
,@partition varchar(100)
,@sample varchar(10)
,@Value varchar(3)
)
as
BEGIN
CREATE TABLE ##temp(
[InvoiceNo] [int] NULL,
[Color] [varchar](255) NULL,
[Product] [varchar](255) NULL,
[Customer] [varchar](255) NULL,
[Sales] [varchar](255) NULL,
[Month] [varchar](255) NULL,
[Valuetype] [varchar](255) NULL,
[TimeUtility] [varchar](255) NULL,
[Discount] [float] NULL,
[Material] [float] NULL,
[Labour] [float] NULL,
[Revenues] [float] NULL,
[SD] [float] NULL,
[Volume] [float] NULL,
[Counter] [int] NULL
);
declare @sourcetablename varchar(100)
declare @desttablename varchar(100)
declare @percent varchar(3)
declare @sales_id varchar(10)
declare @sql varchar(max)
set @sourcetablename = @sourcedb +'.'+@schema+'.'+@tablename
set @desttablename = @destdb +'.'+@schema+'.'+@tablename
DECLARE db_cursor CURSOR FOR
--manuelle Anpassung bei anderer Iterationsspalte
SELECT distinct Sales
from Chair.dbo.T_Import_Deckungsbeitragsrechnung
OPEN db_cursor
FETCH NEXT FROM db_cursor INTO @sales_id
WHILE @@FETCH_STATUS = 0
BEGIN
print @sales_id
set @sql='
insert into ##temp
select
*
FROM ' + @sourcetablename +
' TABLESAMPLE ('+@Value+ ' '+@Sample+')
WHERE '+@partition+' = '''+@sales_id+'''
'
print @sql
exec(@sql)
FETCH NEXT FROM db_cursor INTO @sales_id
END
CLOSE db_cursor
DEALLOCATE db_cursor
exec ('truncate table ' + @desttablename)
exec ('
insert into ' +
@desttablename + '
Select
*
from
##temp '
)
exec ('drop table ##temp')
END
goNützliche Links / Quellen
Technische Funktionsweise von TABLESAMPLE
https://technet.microsoft.com/de-de/library/ms189108(v=sql.105).aspx
Dynamic SQL
http://www.sommarskog.se/dynamic_sql.html
