In diesem Blogbeitrag wird gezeigt, wie durch die „GROUP BY“-Syntaxerweiterung „ROLLUP“ relativ einfach eine Art „relationaler Cube“ erschaffen werden kann. Außerdem enthält der Blogbeitrag eine Prozedur, die auf Grundlage eines DeltaMaster-ETL-Modells direkt einen „relationalen Cube“ in Form einer View erstellt.
Einleitung
Dass wir uns als Berater auf die Ergebnisse der Aggregationsberechnungen des SQL Server Analysis Services (SSAS) verlassen können, wird in unserem täglichen Arbeitsleben immer wieder unter Beweis gestellt. Der SSAS speichert beim Verarbeitungsprozess die Aggregationen in einem speziellen Format ab, was zu den schnellen Antwortzeiten bei der Abfrage des daraus entstehenden Cubes führt. Der Nachteil für viele ist wiederum, dass damit die doch so vertraute Welt der Tabellen und der Abfragesprache SQL verlassen wird und man sich in die unbekannte Welt der Multidimensionalität und des MDX begibt. So schlimm ist es zum Glück dann doch nicht. Aber der Wohlfühlfaktor ist bei vielen Kunden und Beratern in der relationalen Datenbankwelt doch ein Stück weit höher als in der multidimensionalen.
Wenn ein Ergebnis in DeltaMaster angezweifelt wird, dann tritt man gerne den Beweis für dessen Richtigkeit an, indem die Prozesskette von vorne nach hinten durchgegangen wird, bis man sich schlussendlich auf der relationalen Ebene wiederfindet. Der Nachweis auf Basisebene ist dann über die Faktentabelle schnell erbracht. Wenn jedoch die Ergebnisse der Aggregationen angezweifelt werden, so wird es schon etwas kniffliger. Erstmal müssen die Merkmale (Dimensionen) an die Faktentabelle gejoint werden, um dann per „GROUP BY“ die Aggregationen nachstellen zu können. Das ist aufwendig und deckt in diesem Moment auch immer nur die Aggregation ab, die in der Fragestellung aktuell analysiert werden soll. Will man dann doch z.B. das Ergebnis der nächsthöheren Ebene eines Merkmals wissen, so geht das Umstellen der SQL-Syntax wieder von neuem los.
Wäre es hier nicht sehr angenehm, wenn auf eine View oder Tabelle zugegriffen werden kann, in der die Aggregationen über sämtliche Merkmale und Ebenen bereits ausgerechnet sind und das Ergebnis nur noch gefiltert werden muss, wie es im Cube auch der Fall ist? Dieser Blogbeitrag zeigt genau dafür ein Konzept auf und enthält eine Prozedur, die eine solche View anhand der FACT-ID automatisch erstellt.
Umsetzung
Die Zauberformel bei der Umsetzung einer solchen Anforderung heißt „ROLLUP“. Die „ROLLUP“-Syntax stellt eine Erweiterung/Untersyntax des „GROUP BY“ dar und kann in ein und demselben SELECT-Statement Gruppierungen auf mehreren Ebenen gleichzeitig vornehmen. Verdeutlichen wir das anhand eines einfachen Beispiels. Wir wollen relational das Jahres-, sowie das Quartalsergebnis über alle Merkmale einer Faktentabelle ermitteln. Mit dem „GROUP BY“-Befehl würden wir hierzu folgendermaßen vorgehen:

SELECT
D0101.JahrID,
FACT.[WertartID],
FACT.[PeriodenansichtID],
FACT.[KumulationID],
FACT.[KundeID],
FACT.[ProduktID],
FACT.[StoffgruppeID],
FACT.[VertriebID],
FACT.[EinheitID],
SUM(FACT.[Absatz]) Absatz_Aggregiert
FROM T_FACT_01_Deckungsbeitragsrechnung AS FACT
LEFT JOIN T_DIM_01_03_Monat AS D0103
ON D0103.MonatID = FACT.MonatID
LEFT JOIN T_DIM_01_02_Quartal AS D0102
ON D0102.QuartalID = D0103.QuartalID
LEFT JOIN T_DIM_01_01_Jahr AS D0101
ON D0101.JahrID = D0102.JahrID
GROUP BY D0101.JahrID, FACT.[WertartID], FACT.[PeriodenansichtID], FACT.[KumulationID],
FACT.[KundeID], FACT.[ProduktID], FACT.[StoffgruppeID], FACT.[VertriebID], FACT.
[EinheitID]
Mit folgendem Ergebnis (Ausschnitt):
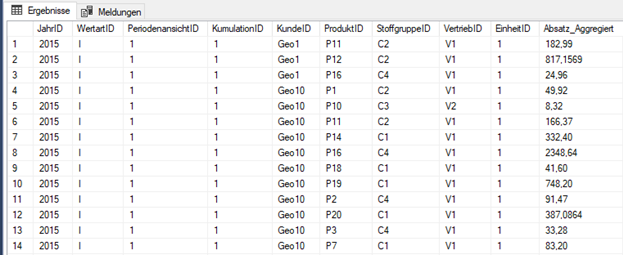
Abb. 1: Ergebnis einer Aggregation per „GROUP BY“ über ein Gruppierungsmerkmal
Wollen wir nun das Aggregationsergebnis auch noch gleichzeitig auf Quartalsebene darstellen, wird es komplizierter. Die „ROLLUP“-Syntax vereinfacht die Umsetzung dieser Anforderung ungemein. Das Statement und das Ergebnis würden in diesem Fall nämlich so aussehen:

SELECT
D0101.JahrID,
D0102.QuartalID,
FACT.[WertartID],
FACT.[PeriodenansichtID],
FACT.[KumulationID],
FACT.[KundeID],
FACT.[ProduktID],
FACT.[StoffgruppeID],
FACT.[VertriebID],
FACT.[EinheitID],
SUM(FACT.[Absatz]) Absatz_Aggregiert
FROM T_FACT_01_Deckungsbeitragsrechnung AS FACT
LEFT JOIN T_DIM_01_03_Monat AS D0103
ON D0103.MonatID = FACT.MonatID
LEFT JOIN T_DIM_01_02_Quartal AS D0102
ON D0102.QuartalID = D0103.QuartalID
LEFT JOIN T_DIM_01_01_Jahr AS D0101
ON D0101.JahrID = D0102.JahrID
GROUP BY ROLLUP(D0101.JahrID,D0102.QuartalID), FACT.[WertartID], FACT.
[PeriodenansichtID], FACT.[KumulationID], FACT.[KundeID], FACT.[ProduktID], FACT.
[StoffgruppeID], FACT.[VertriebID], FACT.[EinheitID]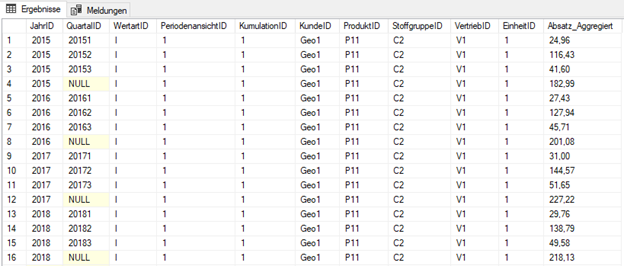 Abb. 2: Ergebnis einer Aggregation per Group By & Rollup über zwei Gruppierungsmerkmale
Abb. 2: Ergebnis einer Aggregation per Group By & Rollup über zwei Gruppierungsmerkmale
In die Klammern der „ROLLUP“-Syntax schreibt man die Spalten der Hierarchieebenen eines Merkmals in absteigender Reihenfolge vom höchsten Level zum niedrigsten Level. Das Rollup führt dann über mehrere Hierarchieebenen gleichzeitig eine Aggregation durch. Damit kann in diesem Beispiel sowohl die Frage über den Jahreswert, als auch über den Quartalswert beantwortet werden. Der Datensatz mit einem Jahreswert hat in der QuartalID-Spalte folgerichtig einen NULL-Wert. Hätte man in diesem Beispiel auch die Monatsebene in das „ROLLUP“ eingeschlossen, hätte der Datensatz in der MonatID-Spalte natürlich ebenfalls einen NULL-Wert.
Dies kann beliebig erweitert werden, sodass man ebenfalls auch Fragestellungen beantworten kann, die eine Gruppierung von mehreren Merkmalen erfordern. Hierzu kann das „GROUP BY“ einfach um weitere „ROLLUP“s erweitert werden. Soll beispielsweise ermittelt werden, wie hoch der Absatz im Jahr 2018 in der Produkthauptgruppe 1 war, kann das Statement wie folgt aussehen.

SELECT
D0101.JahrID,
D0102.QuartalID,
D0601.[ProdukthauptgruppeID],
D0602.[ProduktgruppeID],
D0603.[ProduktID],
SUM(FACT.[Absatz]) Absatz_Aggregiert
FROM T_FACT_01_Deckungsbeitragsrechnung AS FACT
LEFT JOIN T_DIM_01_03_Monat AS D0103
ON D0103.MonatID = FACT.MonatID
LEFT JOIN T_DIM_01_02_Quartal AS D0102
ON D0102.QuartalID = D0103.QuartalID
LEFT JOIN T_DIM_01_01_Jahr AS D0101
ON D0101.JahrID = D0102.JahrID
LEFT JOIN T_DIM_06_03_Produkt AS D0603
ON D0603.ProduktID = FACT.ProduktID
LEFT JOIN T_DIM_06_02_Produktgruppe AS D0602
ON D0602.ProduktgruppeID = D0603.ProduktgruppeID
LEFT JOIN T_DIM_06_01_Produkthauptgruppe AS D0601
ON D0601.ProdukthauptgruppeID = D0602.ProdukthauptgruppeID
GROUP BY
ROLLUP(D0101.JahrID,D0102.QuartalID),
ROLLUP(D0601.ProdukthauptgruppeID,D0602.ProduktgruppeID,D0603.ProduktID)
HAVING 1=1
AND D0601.[ProdukthauptgruppeID] = 1
AND D0602.[ProduktgruppeID] IS NULL
AND D0603.[ProduktID] IS NULL
AND D0101.[JahrID] = 2018
AND D0102.[QuartalID] IS NULL
Abb. 3: Ergebnis der Fragestellung nach dem Absatz im Jahr 2018 der Produkthauptgruppe 1
Denkt man das Konzept des „ROLLUP“s weiter, so können aus der Modelldefinition des DeltaMaster ETL genau die Informationen gezogen werden, die benötigt werden, um eine Art „relationalen Cube“ zu erstellen. Dieser ist dann gleichermaßen über alle Elemente der angebundenen Dimensionen filterbar und gibt einem das gewünschte aggregierte Ergebnis in der relationalen Datenbank aus. Hierfür habe ich folgende Prozedur erstellt, die auf Grundlage eines DeltaMaster-ETL-Modells einen „relationalen Cube“ in Form einer View generiert. Die Prozedur kann über folgende Syntax erstellt werden:
CREATE OR ALTER PROC P_CREATE_relational_Cube (
@FactID int,
@InclDIMs varchar(max) = NULL
) AS
DECLARE @CreateSQL varchar(max),
@FACT_SourceTableName varchar(250),
@FACT_FactName varchar(250),
@DIM int,
@Last_DIM varchar(100) = '',
@DIM_Joins varchar(max),
@DIM_Join_List varchar(max) = '',
@Level int,
@DESC_Level int,
@LevelName varchar(250),
@DESC_LevelName varchar(250),
@RollUp_DIM varchar(250),
@RollUp_DIM_List varchar(max) = '',
@Select_List varchar(max) = '',
@SQL_InclDIMs varchar(max),
@MeasureID int,
@Measure_List varchar(max) = '',
@Measure_Name varchar(250),
@Measure_AggregationType int
DECLARE @SQL_InclDIMs_Table TABLE (DimensionID int)
SET @FACT_SourceTableName = 'T_FACT_' + RIGHT(100 + @FactID,2) + '_' + (SELECT FactName FROM [dbo].[T_Model_Facts] WHERE FactID = @FactID)
SET @FACT_FactName = (SELECT FactName FROM [dbo].[T_Model_Facts] WHERE FactID = @FactID)
-- Definition der zu gruppierenden Dimensionen für den Cursor
IF @InclDIMs IS NULL
BEGIN
SET @SQL_InclDIMs = 'SELECT [DimensionID] FROM [dbo].[T_Model_Fact_Dimension_SourceTable] WHERE FactID = ' + CAST(@FactID as varchar(20))
END
ELSE
BEGIN
SET @SQL_InclDIMs = 'SELECT [DimensionID] FROM [dbo].[T_Model_Fact_Dimension_SourceTable] WHERE FactID = ' + CAST(@FactID as varchar(20)) + ' AND DimensionID IN (' + @InclDIMs + ')'
END
-- Übergabe der zuvor definierten Dimensionen in Tabellen-Parameter
INSERT INTO @SQL_InclDIMs_Table (DimensionID)
EXEC (@SQL_InclDIMs)
--Erstellen von Join- und Select-Liste
DECLARE Cursor_Join_DIM CURSOR FOR
SELECT DimensionID FROM @SQL_InclDIMs_Table
OPEN Cursor_Join_DIM
FETCH Cursor_Join_DIM INTO @DIM
WHILE @@FETCH_STATUS = 0
BEGIN
DECLARE Cursor_Join_LEVEL CURSOR FOR
SELECT DimensionLevelID FROM [dbo].[T_Model_Dimension_Levels] WHERE DimensionID = @DIM
ORDER BY DimensionLevelID DESC
OPEN Cursor_Join_LEVEL
FETCH Cursor_Join_LEVEL INTO @Level
WHILE @@FETCH_STATUS = 0
BEGIN
SET @DESC_Level = (SELECT DESC_DimensionLevelID FROM (SELECT ROW_NUMBER() OVER (ORDER BY
DimensionlevelID DESC) DESC_DimensionLevelID, DimensionLevelID FROM [dbo].[T_Model_Dimension_Levels] WHERE DimensionID = @DIM) t WHERE DimensionLevelID = @Level)
SET @DESC_LevelName = (SELECT DimensionLevelName FROM [dbo].[T_Model_Dimension_Levels]
WHERE DimensionID = @DIM AND DimensionLevelID = @DESC_Level)
SET @LevelName = (SELECT DimensionLevelName FROM [dbo].[T_Model_Dimension_Levels]
WHERE DimensionID = @DIM AND DimensionLevelID = @Level)
SET @DIM_Joins = 'LEFT JOIN T_DIM_' + RIGHT(100 + @DIM,2) + '_' + RIGHT(100 + @Level,2) + '_' + @LevelName + ' AS ' + 'D' + RIGHT(100 + @DIM,2) + RIGHT(100 + @Level,2) + '
ON D' + RIGHT(100 + @DIM,2) + RIGHT(100 + @Level,2) + '.' + @LevelName + 'ID' + ' = ' + CASE WHEN EXISTS (SELECT DimensionLevelID FROM [dbo].[T_Model_Dimension_Levels] WHERE DimensionID = @DIM AND DimensionLevelID = (@Level + 1)) THEN 'D' + RIGHT(100 + @DIM,2) + RIGHT(100 + (@Level+1),2) ELSE 'FACT' END + '.' + @LevelName + 'ID'
SET @DIM_Join_List = @DIM_Join_List + '
' + @DIM_Joins
SET @RollUp_DIM = 'D' + RIGHT(100 + @DIM,2) + RIGHT(100 + @DESC_Level,2) + '.' +
@DESC_LevelName + 'ID'
SET @Select_List = @Select_List + @RollUp_DIM + ',
'
--Erstellen RollUp-Liste (in umgekehrter Reihenfolge der Level)
SET @RollUp_DIM_List = @RollUp_DIM_List + CASE WHEN RIGHT(@Last_DIM,1) <> @DIM THEN '
ROLLUP(' + @RollUp_DIM + (CASE WHEN @Level = 1 THEN'),' ELSE ','END) ELSE @RollUp_DIM +
(CASE WHEN @Level = 1 THEN'),' ELSE ','END) END
SET @LAST_DIM = @Last_DIM + CAST(@DIM as varchar)
FETCH Cursor_Join_LEVEL INTO @Level
END
CLOSE Cursor_Join_LEVEL
DEALLOCATE Cursor_Join_LEVEL
FETCH Cursor_Join_DIM INTO @DIM
END
CLOSE Cursor_Join_DIM
DEALLOCATE Cursor_Join_DIM
--Erstellen der Measure-Liste
DECLARE Cursor_Measures CURSOR FOR
SELECT [MeasureID] FROM [dbo].[T_Model_Fact_Measures] WHERE FactID = @FactID
OPEN Cursor_Measures
FETCH Cursor_Measures INTO @MeasureID
WHILE @@FETCH_STATUS = 0
BEGIN
SET @Measure_Name = (SELECT [MeasureName] FROM [dbo].[T_Model_Fact_Measures] WHERE FactID = @FactID AND MeasureID = @MeasureID)
SET @Measure_AggregationType = (SELECT [AggregationTypeID] FROM [dbo].[T_Model_Fact_Measures] WHERE FactID = @FactID AND MeasureID = @MeasureID)
SET @Measure_List = @Measure_List + CASE WHEN @Measure_AggregationType = 2 THEN 'COUNT(' ELSE 'SUM(' END + @Measure_Name +') AS ' + @Measure_Name + ',
'
FETCH Cursor_Measures INTO @MeasureID
END
CLOSE Cursor_Measures
DEALLOCATE Cursor_Measures
--Eliminieren des letzten Kommas
SET @RollUp_DIM_List = LEFT(@RollUp_DIM_List, LEN(@RollUp_DIM_List) -1)
SET @Measure_List = LEFT(@Measure_List, LEN(@Measure_List) -3)
--Definieren der View
SET @CreateSQL = '
CREATE OR ALTER VIEW V_APP_'+ @FACT_FactName + ' AS
SELECT
' + @Select_List + @Measure_List +'
FROM ' + @FACT_SourceTableName + ' AS FACT
' + @DIM_Join_List + '
GROUP BY ' + @RollUp_DIM_List
PRINT @CreateSQL
--Erstellen der View
EXEC (@CreateSQL)
GO
Die erstellte Prozedur muss anschließend mit zwei Parametern ausgeführt werden, damit sie eine View mit dem „relationalen Cube“ generiert. Der erste Parameter ist die ID der Faktentabelle. Mit dem zweite Parameter können die Dimensionen frei definiert werden, für die überhaupt Aggregationen gerechnet werden sollen. Wird der zweite Parameter frei gelassen, so erstellt die Prozedur den „relationalen Cube“ mit allen angebundenen Dimensionen. Um genau zu definieren welche Dimensionen enthalten sein sollen, muss der zweite Parameter als komma-separierter String angegeben werden (z.B. ‘1,2,5‘). Somit könnte das Ausführen der Prozedur auf unsere Chair-Datenbank folgendermaßen aussehen: (1= Periode, 2= Wertart, 5= Kunden, 6 = Produkte, 7 = Stoffgruppe, 8 = Vertrieb)
![]()
Die Prozedur generiert nun eine View mit der Nomenklatur „V_APP_[Faktenname]“ die wie folgt ausschaut:
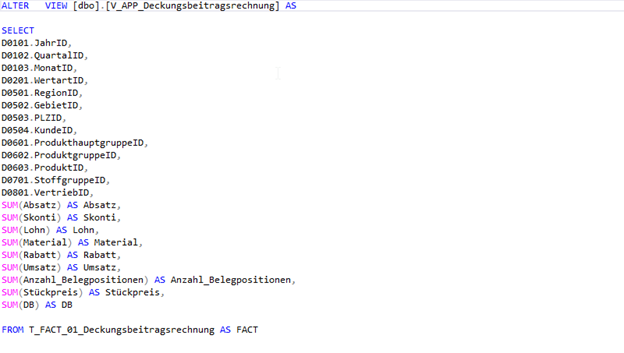
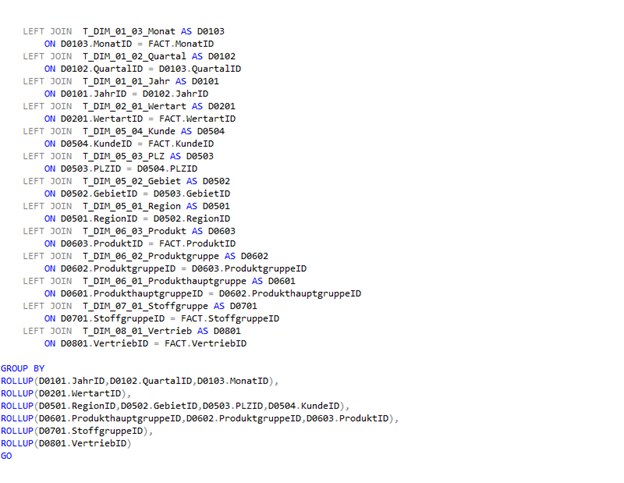
Wenn wir diese View dann anschließend ausführen, sehen wir, welche Größe ein solcher „relationaler Cube“ annehmen kann. Die Berechnung sämtlicher Gruppierungskombinationen lässt die Datenmenge extrem ansteigen und generiert uns in der definierten Konstellation 2.455.130 Datensätze. Zum Vergleich, die Ausgangsbasis, also die Faktentabelle, hat lediglich 38.558 Datensätze.
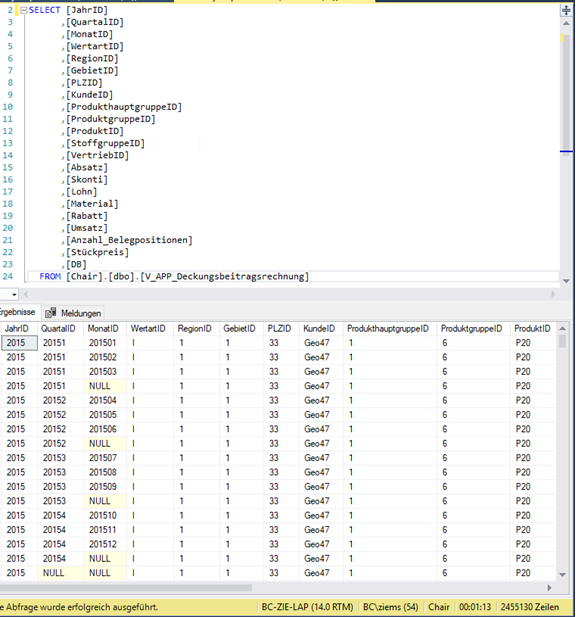 Abb. 4: Ergebnis der abgefragten View des relationalen Cubes
Abb. 4: Ergebnis der abgefragten View des relationalen Cubes
Zum Schluss wollen wir natürlich noch validieren, ob in unserem „relationalen Cube“ auch tatsächlich das gleiche Ergebnis angezeigt wird, wie im OLAP Cube. Hierzu verwenden wir wieder das Beispiel, welches wir zuvor herangezogen hatten. Wir wollen uns das Ist-Ergebnis des Jahres 2018 für die gesamte Produkthauptgruppe der Luxusmodelle (ID = 1) anschauen. Hierzu müssen wir die erstellte View per WHERE-Bedingung filtern und erhalten folgendes Ergebnis:
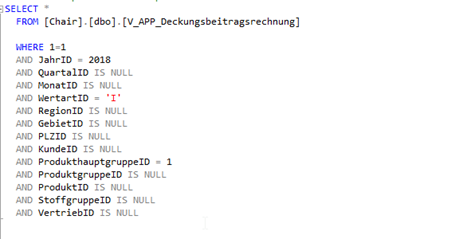
![]()
 Abb. 5: Filterung und Ergebnis der exemplarischen Fragestellung
Abb. 5: Filterung und Ergebnis der exemplarischen Fragestellung
Wenn wir die gleiche Filterung auf dem OLAP Cube über die Sicht von DeltaMaster durchführen, sehen wir, dass in beiden Fällen das gleiche Ergebnis herauskommt.
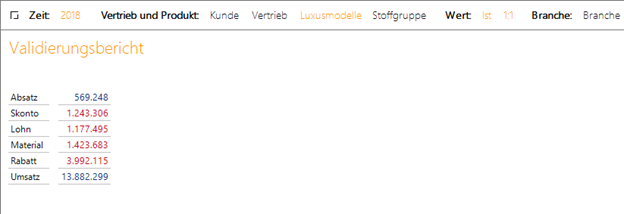 Abb. 6: Ergebnis der exemplarischen Fragestellung in DeltaMaster (auf Grundlage eines OLAP Cubes)
Abb. 6: Ergebnis der exemplarischen Fragestellung in DeltaMaster (auf Grundlage eines OLAP Cubes)
Fazit
Die hier gezeigte Prozedur mit der enthaltenen „ROLLUP“-Funktionalität kann dabei helfen, Fragestellungen in der relationalen Welt zu beantworten, die zuvor erst über die Erstellung eines Cubes beantwortet werden konnten. Ein Wermutstropfen an der Lösung ist jedoch die Einschränkung der „ROLLUP“-Syntax. Diese kann nämlich nur maximal 4096 Groupingsets erstellen. Diese maximale Begrenzung ist leider schon recht schnell erreicht. Bereits bei der Faktentabelle der Deckungsbeitragsrechnung unserer Chair-Datenbank kann die View nicht erstellt werden, wenn nicht mindestens eine Dimension aus der Betrachtung herausgenommen wird. Nichtsdestotrotz kann die Prozedur auch auf größeren Modellen angewendet werden, da sich die Fragestellungen meist nicht über alle Merkmale erstrecken und somit über den zweiten Parameter gut einschränken lassen.

Kommentare
Sie müssten eingeloggt sein um Kommentare zu posten..