In diesem Blogbeitrag wird anschaulich gezeigt, wie die „InMemory“-Technologie von Microsoft im SQL-Server schnell in den operativen Betrieb übernommen werden kann. Dabei wird die Frage “Warum sollte man diese Technologie nutzen?” gelöst und gezeigt, wie man eine speicheroptimierte Datenbank und Tabelle anlegt. Anschließend benchmarken wir die erstellte Lösung.
Überblick: Warum sollte man eine speicheroptimierte Lösung in Erwägung ziehen?
Obwohl PCI-Express SSDs neue Möglichkeiten im Bereich der Datenzugriffsgeschwindigkeiten bieten, sind sie immer noch dem deutlich „CPU-näherem“ Arbeitsspeicher unterlegen. Permanenter Arbeitsspeicher zeichnet sich zwar als Verheißung am Technologie-Himmel ab, steht aber zurzeit nicht zur Verfügung.
In Zeiten exponentiell steigender Datenmengen können bei der Datenverarbeitung bereits kleine Veränderungen eine deutlich größere Datenmenge verursachen, die aber dennoch schnell und umfangreich ausgewertet werden will.
Relationale Anwendungen profitieren hier besonders, wenn wir uns Gedanken über häufig genutzte Objekte machen und diese immer im Arbeitsspeicher griffbereit halten. Außerdem bieten diese speicheroptimierten Datenbankobjekte zahlreiche Detailverbesserungen, die z. B. das „Memory Spilling“ einer Abfrage in eine langsame „tempDB“ verhindern.
Einspruch – hat denn der SQL-Server keinen Cache?
Aber wieso sollte man sich die Mühe machen und quasi von „Hand“ und mit „Kopf“ eine Speicherlösung erarbeiten, wenn es doch bereits umfangreiche Caches gibt? Man sieht doch auf dem Server, dass der SQL-Server-Prozess 80 % Speicher belegt – obwohl gerade kaum Abfragen stattfinden?
Aufgrund der Komplexität möglicher SQL-Abfragen und Installationen cacht Microsoft SQL-Server hauptsächlich nur:
- Ausführungspläne und
- Seiten aus Speicherdateien – also Rohdaten …
- … jedoch keine Abfrageergebnisse!
Das ist ein gewaltiger Unterschied, den man insbesondere bei BI Anwendungen, die unzählige Transformationen mit Datenbestand durchführen, schnell zu spüren zu bekommt.
Technische Voraussetzungen
Zwar gibt es bereits seit SQL Server 2014 die Möglichkeit, speicheroptimierte Objekte anzulegen, doch diese unterliegen diversen Beschränken wie z. B. maximal 256 GB Speicher für Tabellen, die auch nach einem Neustart befüllt sein sollten – dazu später mehr – und keiner Möglichkeit Fremdschlüssel zusetzen. Im operativen BI-Betrieb daher eher untauglich.
Doch mit SQL-Server 2016 fielen diese Einschränkungen. Ein guter Grund sich diese neue Möglichkeit jetzt genau anzusehen und vorhandenen Arbeitsspeicher optimal auszunutzen, um z. B. Faktentabellen schneller aufzurufen.
Für einen optimalen Betrieb sollten neben der Größe der zu speichernden Objekte noch ca. 25 % Overhead für Berechnungen und eingangs erwähnte „tempDB“ bei der Systemplanung einberechnet werden.
Vorbereiten der Datenbank
Es ist nicht notwendig eine neue Datenbank anzulegen, wenn man ein bisheriges System speicheroptimieren möchte. Im folgenden Beispiel werde ich jedoch bei Null beginnen und auch das Erstellen der Datenbank dokumentieren.
Dateigruppen und Dateien (Filegroup und File)
Jede Tabelle/jedes Objekt einer SQL-Server-Datenbank benötigt einen physikalischen Speicherort in einer Datei auf einem Datenträger. Einzelne Dateien werden in Dateigruppen verwaltet. Dieses Konzept findet insbesondere bei der Partitionierung größerer Datenmengen Anwendung.
Auch speicheroptimierte Tabellen benötigen einen Speicherort in einer Datei, die dieser Logik folgt, obwohl es doch zunächst dem Konzept der Speicherung im Arbeitsspeicher widerspricht, einen Pfad im Dateisystem für eine Datei anzugeben. Vergessen wir dabei jedoch nicht, dass auch die Definitionen der speicheroptimierten Tabellen irgendwo gespeichert werden müssen, wenn unser Server heruntergefahren oder neugestartet wird. Dazu später jedoch mehr. Die speicheroptimierte Datei hat den Dateityp „FILESTREAM“.
Die speicheroptimierten Dateien benötigen eine eigene Dateigruppe mit dem Typ „MEMORY OPTIMIZED DATA“. Von dieser Dateigruppe kann es nur eine einzige pro Datenbank geben.
Wir können diese Datei und Dateigruppe durch das UI des SQL-Server Management Studios erstellen oder aber mit Hilfe von T-SQL (Abbildung 1).
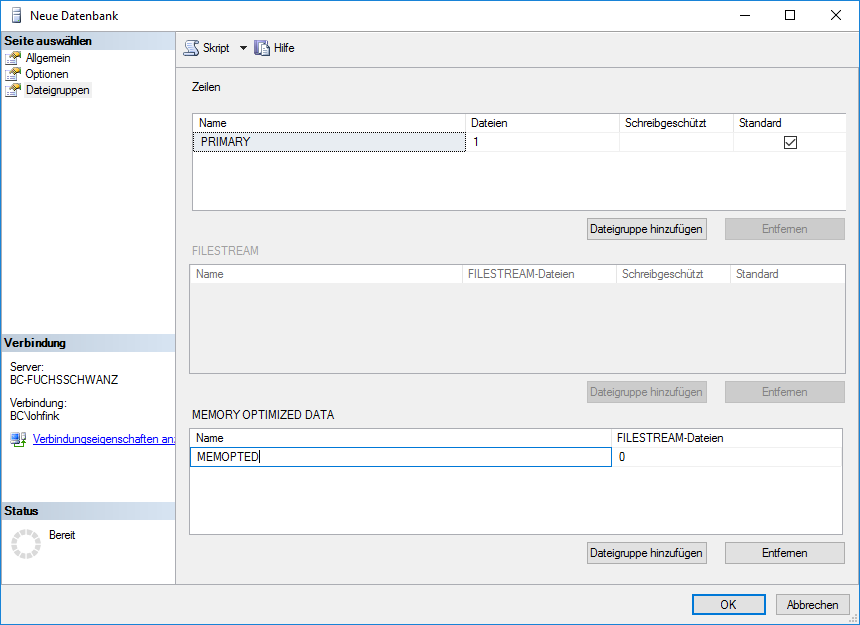
Abbildung 1: Neue Datenbank
Anschließend erstellen wir eine speicheroptimierte Datei innerhalb der eben erstellten Dateigruppe im Datenbank-Dialog (Abbildung 2).
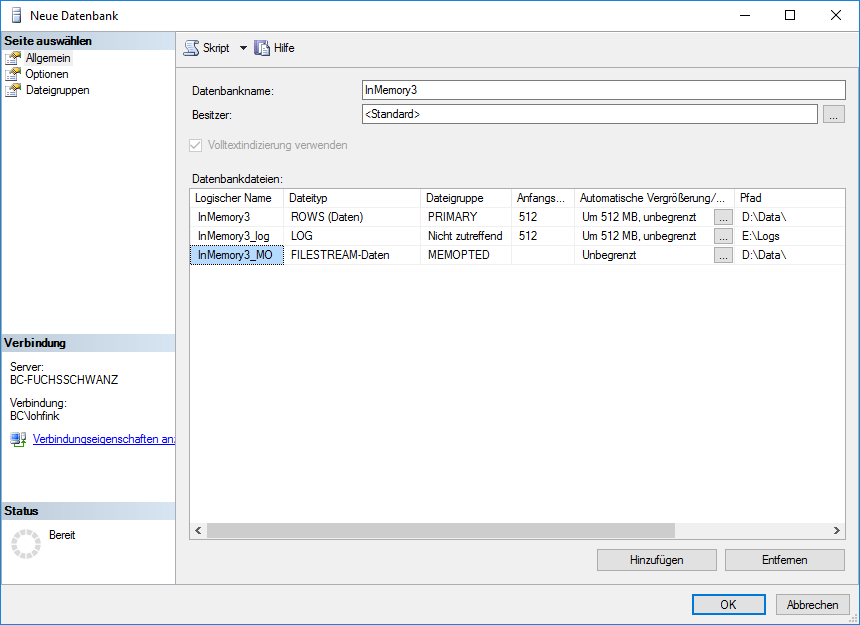
Abbildung 2: Neue Datenbank
Oder einfach per T-SQL-Transaktionen in einer Datenbank ohne speicheroptimierte Dateigruppe:
-- Anlegen einer Memory-Optimized-Filegroup
ALTER DATABASE CURRENT
ADD FILEGROUP MEMOPTED
CONTAINS MEMORY_OPTIMIZED_DATA
GO
ALTER DATABASE CURRENT
ADD FILE (
name = 'InMemory3_MO'
,filename = 'D:\Data\InMemory3_MO'
) TO FILEGROUP MEMOPTED
GOAusführungsisolation (Isolation Level)
Möchte man Transaktionen durchführen, die Daten aus speicheroptimierten Tabellen mit klassischen Daten auf der Festplatte vereinen, so muss man sich Gedanken über die Ausführungsisolation machen:
Um die Möglichkeit von Veränderungen an den auf Festplatte geschriebenen Daten durch andere Transaktionen während des Zusammenführens (Ladens) mit den schnellen speicheroptimierten Daten zu kontrollieren, muss ein entsprechender Ausführungsisolationslevel gewählt werden, der die gemeinsame Verwendung von klassischen und speicheroptimierten Objekten erlaubt:
| Isolation Level | Auswirkungen |
| SNAPSHOT | Transaktionen mit erfolgreichem „Commit“ werden bei Abfragen auf das Objekt berücksichtigt. |
| REPEATABLE READ | Zusätzlich wird überprüft, ob während eines „Commits“ ein anderer „Commit“ durchgeführt wurde. Der langsamere „Commit“ schlägt fehl. |
| SERIALIZABLE | Die Datenbank arbeitet mehr oder weniger im sequenziellen Modus und verarbeitet Transaktionen nicht mehr gleichzeitig. |
Wir entscheiden uns für einen normalen BI-Betrieb für den Isolation Level „Snapshot“, da wir keine Overhead aus möglichen Datenveränderungen erwarten, wenn wir zu festgelegten Zeiten ETL durchführen.
Diese Einstellung setzen wir am besten per T-SQL:
-- Optimierung für Transaktionen zwischen klassischen
-- und speicheroptimierten Objekten
ALTER DATABASE CURRENT
SET MEMORY_OPTIMIZED_ELEVATE_TO_SNAPSHOT = ON;
GOErstellen einer speicheroptimierten Tabelle
Indizes
Eine speicheroptimierte Tabelle muss mindestens einen Index besitzen. Klassische gruppierte Indizes werden nicht unterstützt. Daher kommen nur nicht gruppierte „ColumnStore“-Indizes oder der neue „Hash“-Index in Frage.
Für BI-Anwendungen ist in der Faktentabelle der „ColumnStore“-Index vorzuziehen, für Dimensionstabellen ein „Hash“-Index oder ein nicht gruppierter Index. In diesem Artikel wird jedoch nicht weiter auf die richtige Indexwahl eingegangen.
Speicheroptimierung und Durability
Neben dem Index müssen wir bei der Erstellung der Tabelle noch den Speicherort – unsere speicheroptimierte „FILESTREAM“-Datei angeben. Außerdem sollten wir uns über das eingangs erwähnte Problem der langfristigen Speicherung unserer Tabelle Gedanken machen. Möchten wir, dass die Tabelle beim Neustart des Servers leer ist, weil sie z. B. per Agent-Job als Ergebnis eines ETL-Prozesses automatisch neu befüllt werden würde? Oder möchten wir lieber eine Mischung aus klassischer und speicheroptimierter Architektur – also eine Tabelle, die beim Neustart sofort befüllt ist und gleichzeitig komplett im Arbeitsspeicher vorliegt?
| Durability | Auswirkungen |
| SCHEMA_ONLY | Nur die Tabellen-Definition, also das „CREATE“-Statement und alle Schlüssel etc. werden gespeichert. Nicht jedoch die Daten selbst. Der Begriff „SCHEMA“ ist auf den ersten Blick irreführend und hat nichts mit Datenbank-Schemata zu tun. |
| SCHEMA_AND_DATA | Nach einem Neustart des SQL-Servers verhält sich diese Tabelle genau wie eine klassische Tabelle und ist bereits gefüllt. Die Geschwindigkeit des Dateispeicherortes spielt für UPDATE, INSERT etc. eine Rolle, da eine Synchronität von Festplatte und Arbeitsspeicher gewährt werden muss. |
So könnte die Erstellung unserer Tabelle per T-SQL aussehen:
CREATE TABLE [dbo].[T_Import_FACT](
[PID] [bigint] NOT NULL PRIMARY KEY NONCLUSTERED
,[DIM1_ID] [bigint] NOT NULL
,[DIM1_1_ID] [bigint] NOT NULL
,[DIM2_ID] [bigint] NOT NULL
-- usw.
) WITH (MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_AND_DATA);
GOEine Änderung am Index ist später leider nicht möglich – wir sollten uns hier bereits bei Erstellung ausreichend Gedanken machen.
Befüllen und Benutzen der Tabelle
Nach der Erstellung der Tabellen können wir diese mit Daten befüllen. Dabei müssen wir nichts „Neues“ erfinden. Wir können die Tabelle ganz normal mit einem vorhandenen SSIS-Prozess oder einer anderen Methode mit Daten befüllen. Für einen schnellen Test reicht auch der Rechtsklick-Dialog des SQL-Server Management Studios.
Benchmark
Als Benchmark dienen uns Abfragen über 1,2 Milliarden Datensätze. Die klassischen Tabellen wurden auf NVMe SSDs installiert, um einen Vergleich mit aktuellster Technik zu ermöglichen. Alle Testabfragen wurden via DeltaMaster 6.1.6 mehrfach auf die Datenbank geschickt, damit der SQL-Server die entsprechenden Abfragepläne optimieren konnte und Caches Verwendung fanden.
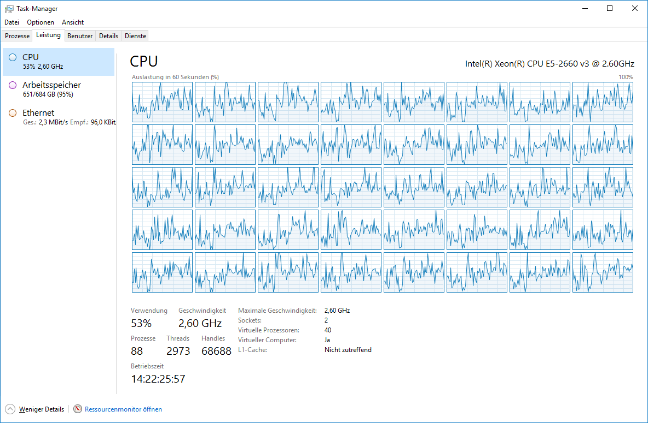
Grundsätzlich kann man feststellen, dass Abfragen auf klassische Tabellen unseren Testserver nicht „zum Glühen brachten“, da die SSDs nicht schnell genug für Datennachschub sorgen konnten.
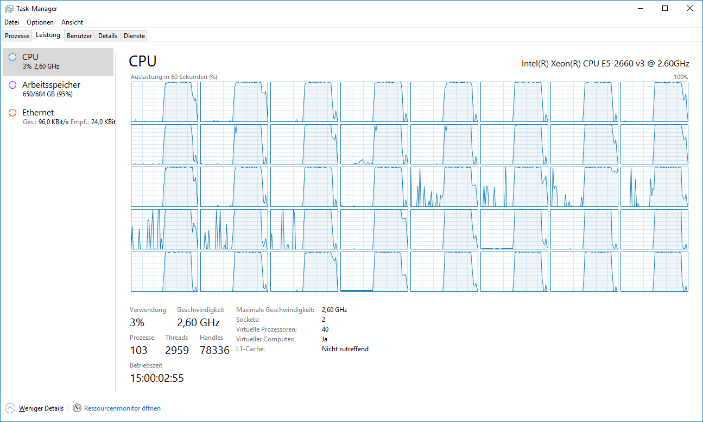
Abfragen auf speicheroptimierte Tabellen konnten unsere CPUs wirklich zum Glühen bringen.
Die höhere Spitzenlast und daraus konsequent kürzere Abfragezeiten habe ich noch einmal in dieser Tabelle zusammengefasst.

Mit zunehmender Komplexität der Abfragen relativiert sich die Geschwindigkeit der Datenabfragen gegenüber der Berechnungsgeschwindigkeit zunehmend.
Fazit
„MEMORY OPTIMIZED“ ist keine leere Floskel und bietet zahlreiche Möglichkeiten häufig genutzte Objekte in Datenbanken ohne zusätzliche Software – in vielen Fällen auch ohne zusätzliche Hardware – wesentlich zu beschleunigen. Es gibt immer noch einige Einschränkungen, die den Umgang mit speicheroptimierten Tabellen im Entwicklungsbetrieb eher unangenehm gestalten, wie z. B. die fehlenden Möglichkeiten Indizes zu verändern. Dennoch bieten speicheroptimierte Tabellen im operativen Betrieb – und dort insbesondere bei Tabellen, die bei Abfragen oft transformiert werden – einen wesentlichen Mehrwert. Vorhandene DeltaMaster-Anwendungen und Versionen müssen nicht verändert werden und können bereits jetzt auf speicheroptimierte Objekte zugreifen.
