Was für viele Informatiker und Mathematiker zur Routine geworden ist, ist noch längst nicht im Kreis aller Business-Intelligence-Architekten angekommen: reguläre Ausdrücke. Sie stellen eine mächtige Möglichkeit dar, die Produktivität bei der Entwicklung von BI-Systemen zu erhöhen. Durch geschickte Nutzung lassen sich beispielsweise mit wenigen Befehlen seitenweise T-SQL-Statements erweitern. Dieser Blogbeitrag zeigt den Einsatz von regulären Ausdrücken im Kontext von Microsoft SQL Server.
Reguläre Ausdrücke in der Theorie
Der Begriff “regulärer Ausdruck” (engl. regular expression, Abk. RegEx oder RegExp) entstammt in der Informatik der Theorie der sogenannten formalen Sprachen im Zusammenhang mit “regulären Sprachen” und “endlichen Automaten”. Abstrakt gesprochen ist ein regulärer Ausdruck eine Zeichenkette, welche der Beschreibung von Mengen und Untermengen von Zeichenketten mithilfe bestimmter syntaktischer Regeln dient.
Konkret: Eigentlich ist ein regulärer Ausdruck nichts anderes als ein Such- oder Filterkriterium, um Texte nach bestimmten Mustern zu durchsuchen. So könnte man beispielsweise alle Wörter suchen, welche mit dem Buchstaben “A” beginnen. Was zugegebenermaßen noch nicht allzu revolutionär ist. Als Besonderheit lassen sich die regulären Ausdrücke auch für eine Textersetzung verwenden. In der Ersetzung kann man dabei Teile des gesuchten Texts wiederverwenden. Beispielsweise könnte man “Ein Apfel” mit “Ein Apfel hängt im Apfelbaum” ersetzen, ohne in der Ersetzung den Baumtyp (“Apfel”) hart zu codieren. Was dies im Rahmen von T-SQL-Programmierung bringt, darauf kommen wir später zurück.
Grundlagen
Um sich effektiv die Grundlagen zu erarbeiten, empfiehlt es sich, das SQL Server Management Studio zu öffnen und die Beispiele selbst nachzuvollziehen.
Um reguläre Ausdrücke im SQL Server nutzen zu können, muss zunächst die “herkömmliche” Suchlogik aus- und die Nutzung der regulären Ausdrücke eingeschaltet werden:
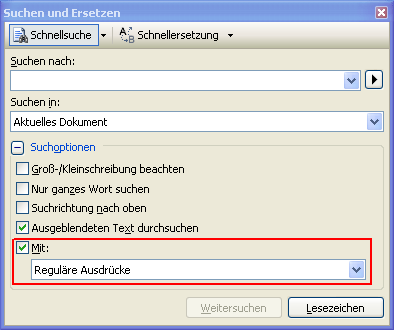
Werden die regulären Ausdrücke aktiviert, erweitert sich der Suchdialog um ein kleines Dreieck neben dem Feld “Suchen nach”. Hierin ist bereits eine Liste der häufig verwendeten regulären Ausdrücke zu sehen:
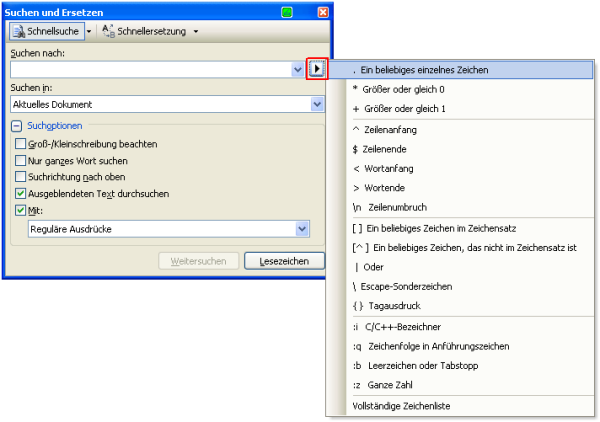
Höchstwahrscheinlich hat jeder Anwender schon mit ähnlichen Konstrukten gearbeitet. Sucht man im Windows Explorer nach Dateien, verwendet man nahezu intuitiv ein “*” (z. B. “Monatsbericht*.das”). Hierbei handelt es sich zwar nicht um einen regulären Ausdruck im eigentlichen Sinne, das Grundprinzip ist jedoch das Gleiche: Suchen nach einem gewissen Suchmuster.
Ein wenig verwirrend ist, dass regulärer Ausdruck nicht gleich regulärer Ausdruck ist. Es gibt keinen weltweit einheitlichen Standard. Vielmehr haben sich mehrere sogenannte “Notationen” herausgebildet, z. B. Basic Regular Expressions (BRE) oder Extended Regular Expressions (ERE). Weiterhin gibt es verschiedene Dialekte, je nach Programmiersprache und –umgebung. SQL Server verwendet auch einen eigenen Dialekt, in dem beispielsweise die geschweiften Klammern eine eigene, SQL-Server-spezifische Bedeutung haben.
Gemein ist allen Dialekten, dass man in verschiedene Zeichengruppen unterscheiden kann.
Ganz allgemein gesprochen gibt es:
- Terminale Zeichen (oderZeichenliterale), welche sich immer selbst bedeuten
(z. B. bedeutet “A” immer, dass auch nach einem “A” gesucht wird), und - Metazeichen, welche als regulärer Ausdruck interpretiert werden und eine gewisse Wirkung auf die Suchlogik haben (z. B. zeigt “+” an, dass das vorherige Zeichen bzw. die Zeichengruppe ein- oder mehrmals vorkommen muss – es wird nicht nach “+” selbst gesucht).
Einige Zeichen können ihre Bedeutung je nach Anwendung verändern. So kommt es beispielsweise bei einem “-” darauf an, an welcher Stelle es innerhalb des regulären Ausdrucks verwendet wird (dazu später mehr).
Soll ein Metazeichen selbst gesucht werden (z. B. ein Text mit “-”), muss das Metazeichen mit einem Backslash verwendet werden (der Backslash ist das Escape-Zeichen; in dem Beispiel ergibt sich also “\-”).
Metazeichen
Schauen wir uns die Metazeichen näher an.
Das altbekannte “*”, das schon in DOS-Tagen einen beliebigen Teil des Dateinamens vertreten hat, funktioniert innerhalb der regulären Ausdrücke ganz anders. Es ist hier einer der sogenannten Wiederholungsoperatoren (Quantifizierer). Die folgenden Zeichen braucht man besonders oft:
| Bedeutung | Syntax |
| Ein beliebiges Zeichen (Wildcard) | . |
| 0 oder mehr Vorkommen | * |
| 1 oder mehr Vorkommen | + |
| n-maliges Vorkommen | ^n |
Folgender Test im SQL Server zeigt die Funktionsweise. Hier wird lediglich das altbekannte Sternchen nachgebaut:
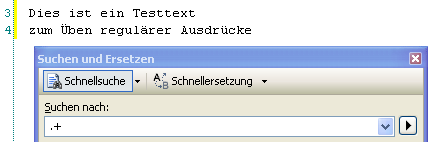
In dem gezeigten Beispiel würde die Verwendung “.+” oder “.*” auch tatsächlich einen Unterschied machen. “.+” würde nur die im Screenshot gezeigten Zeilen 3 und 4 finden. “.*” hingegen auch die Leerzeilen 1 und 2. In diesen Zeilen kommt das Suchkriterium (ein beliebiges Zeichen) 0-mal vor. Daher werden sie vom “*” gefunden.
Im zweiten Beispiel suchen wir nun etwas spezifischer nach dem ein- oder mehrmaligen Vorkommen des Buchstabens “A”:
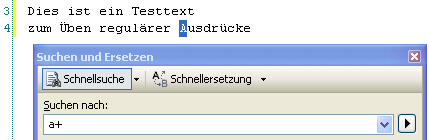
Man kann also die terminalen Zeichen einfach mit den Metazeichen kombinieren.
Bei den terminalen Zeichen übersteuert dabei der Suchdialog von SQL Server den eigentlichen regulären Ausdruck. Normalerweise würde die Suche nach “a+” hier keinen Treffer ergeben, weil das gefundene A kein Kleinbuchstabe ist. Man hätte hier nach “A+” suchen müssen. Der Suchdialog interpretiert hier aber ausschließlich die gesetzte Option “Groß-/Kleinschreibung beachten”.
Mit dem Quantifizierer “^n” kann man nun nach einer exakten Anzahl gleicher Buchstaben suchen. In unserem Beispiel wird nach zwei hintereinander folgenden Buchstaben T gesucht:
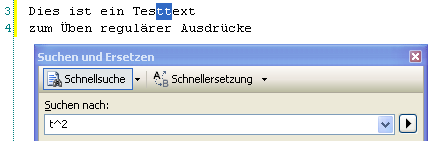
Das ginge mit einer Suche nach „TT“ zwar auch; der Quantifizierer kann aber auch hinter einem anderen Ausdruck mit Metazeichen stehen, sodass dann nach einer Wiederholung des variablen Musters gesucht wird.
Neben dem allgemeinen Suchen mit Wildcards kann man noch näher spezifizieren, wo ein Suchmuster gefunden werden soll. Dazu verwendet man beispielsweise die gängigen Optionen für Wort- und Zeilengrenzen:
| Bedeutung | Syntax |
| Zeilenanfang | ^ |
| Zeilenende | $ |
| Wortanfang | < |
| Wortende | > |
An der Stelle bemerkt man bereits, dass der Zirkumflex-Akzent (“^”) ebenfalls in verschiedenen Bedeutungen verwendet werden kann. Im weiteren Artikel folgen sogar noch weitere Anwendungsmöglichkeiten.
Möchte man nun nach allen Zeilen suchen, die mit dem Buchstaben D beginnen, sieht die Suche wie folgt aus:
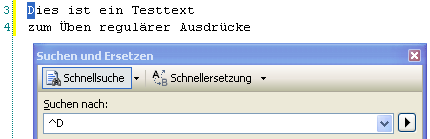
Sollen alle Wörter gesucht werden, welche auf “t” enden, muss der Wortende-Operator auch ans Ende des regulären Ausdrucks gestellt werden (analog dazu auch der Zeilenende-Operator “$”):
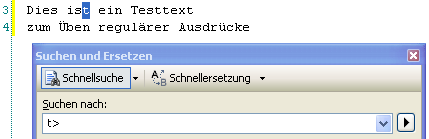
Nutzt man Anfangs- und Endoperatoren, kann man eine höhere Suchperformance erzielen (z. B. ist “^Testtext” schneller als “Testtext”). Von daher sollten diese Operatoren in größeren Suchoperationen tunlichst angewendet werden.
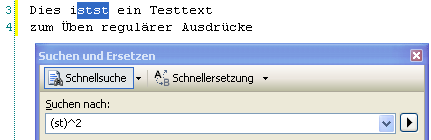
Berücksichtigen sollte man bei allen Suchoperationen auch die Bindung der Metazeichen. In folgendem Beispiel ist bewusst ein Schreibfehler untergebracht und aus dem Wort “ist” das Wort “istst” gemacht. Sucht man nun vermeintlich nach dem doppelten Vorkommen von den Buchstaben “ST”, bekommt man zunächst ein unerwartetes Ergebnis:
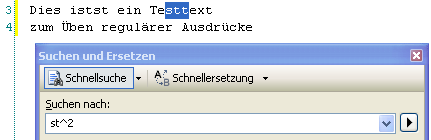
Die Bindung des Quantifizierers “^2″ bezieht sich nur auf den direkt zuvor genannten Ausdruck, in dem Fall also das “t”. Will man tatsächlich nach dem doppelten “st” suchen, muss man die Buchstaben gruppieren. Das geschieht über einen Gruppierungsoperator:
| Bedeutung | Syntax |
| Gruppierung von Ausdrücken | ( ) |
Alle anderen Quantifizierer (“+”, “*”) verhalten sich ebenso.
Die Bindung hat auch Relevanz für folgenden regulären Ausdruck:
| Bedeutung | Syntax | Beschreibung |
| Oder | | | Entspricht dem Pipe-Zeichen |
Über den Oder-Ausdruck kann man nach alternativen Inhalten suchen, also etwa: “beginnt mit A oder B”. In dem Fall ist die Bindung des Oder-Ausdrucks schwächer als die der hintereinander geschriebenen Buchstaben. In dem nachfolgenden Beispiel ist das Wort “toller” vor “Testtext” ergänzt. Mit dem Suchausdruck wird die Bindung deutlich. Gefunden wird “ein” und “toller”, nicht aber “Testtext”:
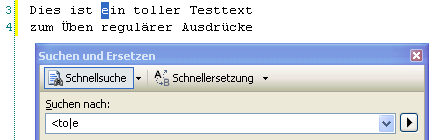
Das liegt daran, dass hier nach dem Wortbeginn “to” oder “e” gesucht wird – und nicht, wie vielleicht angenommen, nach einem fixen “t” und einem nachfolgenden Buchstaben “o” oder “e”. Von daher ist die Bindung genau anders als bei den Quantifizierern.
Zu beachten ist beim Oder-Ausdruck weiterhin, dass immer das erste zutreffende Zeichen im zu durchsuchenden Text gefunden wird. Sucht man also nach “A” oder “P” im Wort “Apfel”, so wird das “A” gefunden.
Neben der Möglichkeit, nach einem einzelnen Zeichen zu suchen, bieten die regulären Ausdrücke noch die Möglichkeit, nach ganzen Zeichensätzen zu suchen. Zeichensätze werden wie folgt initiiert:
| Bedeutung | Syntax |
| Kennzeichnung Zeichensatz | [ ] |
| Kennzeichnung negierter Zeichensatz | [^ ] |
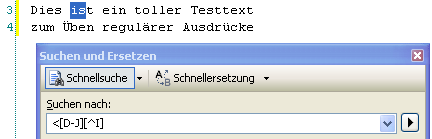
Der Zeichensatz wird zunächst immer als ein Zeichen aus dem genannten Zeichensatz interpretiert. Sucht man also nach ^[A-C] wird eine Zeile gesucht, welche mit einem Buchstaben A, B oder C beginnt. Da wir mit geordneten Zeichensätzen arbeiten, ist die Verwendung einer Von-bis-Logik unproblematisch. Zu beachten ist, dass hier das Minus als “bis”-Operator interpretiert wird. Würde man dagegen nach ^[A-C-] suchen, würde das Minus-Zeichen als weitere Suchoption verwendet (also Zeilen die mit A, B, C oder – beginnen). Möchte man den Zeichensatz negieren und nach Wörtern suchen, welche explizit keines der genannten Zeichen enthalten, verwendet man wieder den Zirkumflex-Akzent, diesmal allerdings in den eckigen Klammern (z. B. [^A-C]).
In nachfolgendem Beispiel sind die oben beschriebenen Zeichensatz-Optionen kombiniert worden:
Neben dem expliziten Aufzählen von Zeichensätzen können auch existierende Variablen verwendet werden. Im SQL Server wären das beispielsweise:
| Bedeutung | Syntax | Beschreibung |
| Alphanumerisches Zeichen | :a | Entspricht dem regulären Ausdruck [a-zA-Z0-9] |
| Alphabetisches Zeichen | :c | Entspricht dem regulären Ausdruck [a-zA-Z] |
| Dezimalzahl | :d | Entspricht dem regulären Ausdruck [0-9] |
Suchen und Ersetzen mit regulären Ausdrücken im SQL Server
Nachdem nun das grundlegende Verständnis für reguläre Ausdrücke geschaffen ist, beschäftigen wir uns mit konkreten Anwendungsfällen im SQL Server.
Die eben gelernten ausgefeilten Suchmöglichkeiten stiften zwar an sich schon einen hohen Nutzen. Allerdings kann die echte Stärke der regulären Ausdrücke erst in Kombination mit einer Ersetzung ausgespielt werden.
Stellen wir uns beispielsweise vor, dass wir ein T-SQL-Statement haben, in dem auf Views und Tabellen zugegriffen wird. Jetzt möchten wir aus allen Tabellen (Präfix “T_”) die Zeichenkette “_Archiv” entfernen, nicht jedoch aus den Sichten (Präfix “V”). Die Anforderung würde die “normale” Such- und Ersetzungsfunktion bereits überfordern. Hier könnten wir zwar die Zeichenkette durch einen Leerstring ersetzen, dies allerdings nur global für Tabellen und Views.
Nähern wir uns nun zuerst der Suche nach den Tabellennamen. Mit folgendem regulären Ausdruck könnten wir alle Tabellennamen identifizieren:
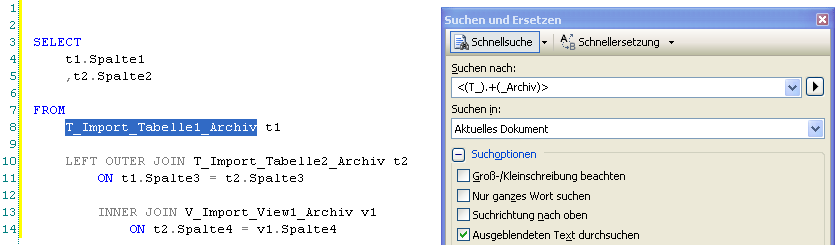
Wir finden alle Wörter, welche mit “T_” beginnen, dann beliebig viele Zeichen haben und anschließend mit “_Archiv” enden (die runden Klammern wurden der Übersichtlichkeit halber verwendet, sie hätten in dem Fall auch weggelassen werden können).
Der entscheidende Trick in der Ersetzungslogik ist nun die sogenannte Rückwärtsreferenz (engl. Backreference) auf den Suchausdruck in Kombination mit dem Auseinanderschneiden des Suchausdrucks in mehrere Teilausdrücke.
Teilausdrücke definiert man im SQL Server über geschweifte Klammern (Achtung, diese haben in anderen Dialekten andere Bedeutungen). Wir teilen also den Suchausdruck auf in den zu behaltenden Teil (“T_Import_TabelleX”) und den zu entfernenden Teil (“_Archiv”), indem wir die Teilausdrücke jeweils in geschweiften Klammern einschließen. Auf diese Teilausdrücke kann man nun im Ersetzungsausdruck zugreifen (= Rückwärtsreferenz). Die Teilausdrücke werden intern durchnummeriert. Über ein Backslash, gefolgt von dieser aufsteigenden Nummer kann man anschließend auf den Teilausdruck zugreifen, wie man in folgendem Beispiel sieht:
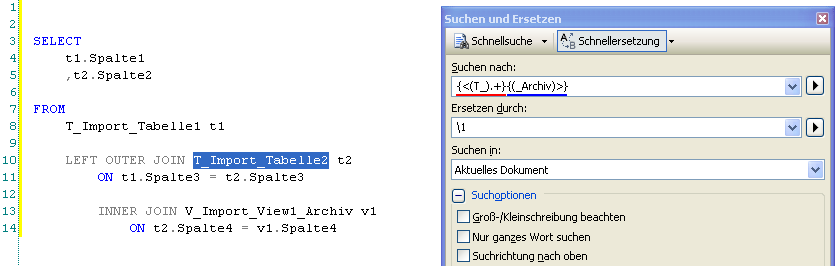
Der rote Teilausdruck ist somit Teilausdruck 1 und der blau markierte stellt Teilausdruck 2 dar. Im Ersetzungsfeld wird indes nur der Teilausdruck 1 verwendet und 2 wird ausgelassen. Da im Teilausdruck 1 “T_Import_Tabelle1″ enthalten ist, der Text “_Archiv” jedoch in Teilausdruck 2 steht, erreichen wir den gewünschten Effekt.
Die Verwendung der Rückwärtsreferenz ist auch im Suchstring selbst möglich.
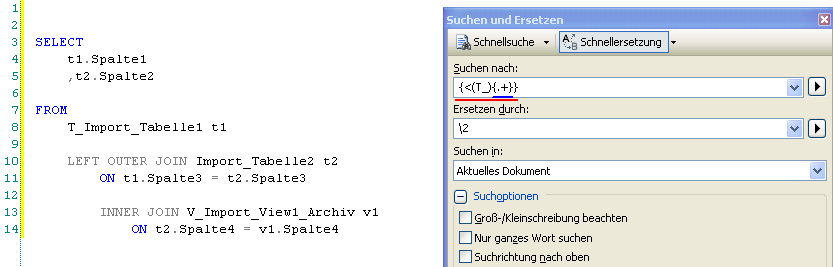
Die Teilausdrücke können auch ineinander geschachtelt werden. Dabei wird immer von außen nach innen nummeriert (sprich: das Auftreten der öffnenden Klammer bestimmt die Nummerierung).
In nachfolgendem Beispiel enthielte also Teilausdruck 1 “T_Import_TabelleX” und Teilausdruck 2 “Import_TabelleX”:
Ein wesentlicher Aspekt bezüglich den bereits dargestellten Quantifizierern muss an dieser Stelle noch dargestellt werden. Die gezeigten Quantifizierer “+” und “*” sind wortwörtlich gierig (engl. greedy). Sie umfassen immer so viele Zeichen wie möglich, nicht so viele wie nötig. Nehmen wir das Wort “Testwort”. Hier ist der Buchstabe “t” mehrfach enthalten. Suchen wir jetzt nach dem regulären Ausdruck “t{.+}t” und verwenden den Teilausdruck 1 in der Ersetzung weiter, so ist dort nicht etwa “es” enthalten (weil dies der Text zwischen dem ersten und dem zweiten “t” ist), sondern der Text “estwor”. Probieren Sie nachfolgendes Beispiel selbst aus:
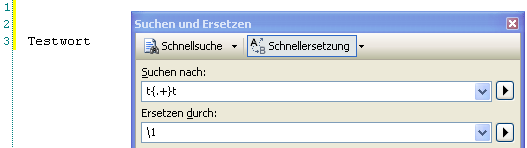
Der Ausdruck “.+” holt sich also so viele Zeichen, wie gerade noch möglich sind. Da der letzte Buchstabe des Wortes ebenfalls ein “t” ist, kann der reguläre Ausdruck so gerade noch gefunden werden und die Wildcard hat sich den maximal möglichen Text gezogen.
Um dies zu verhindern, existieren im SQL Server noch zwei weitere Quantifizierer:
| Bedeutung | Syntax | Beschreibung |
| 0 oder mehr Vorkommen | @ | Entspricht *, aber nur so viel wie nötig |
| 1 oder mehr Vorkommen | # | Entspricht +, aber nur so viel wie nötig |
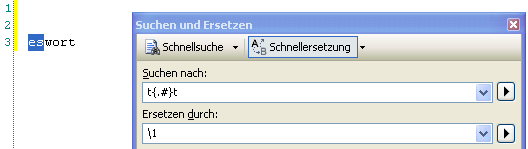
Verwenden wir statt dem eben gezeigten Beispiel den Ausdruck “t{.#}t” erhalten wir innerhalb des Teilausdrucks 1 erwartungsgemäß lediglich den Text “es” zurück. Da das Suchkriterium jetzt nur “Test” findet, ist das Ergebnis der Ersetzung also “eswort”:
Erzeugt man einen großen Teilausdruck, der alle Zeichen umfasst, arbeitet die Ersetzung im Übrigen trotz allem zeilenweise. Mit dem Wissen könnte man aus einem echten SQL-Statement mit wenigen Mausklicks einen zusammengesetzten String generieren:
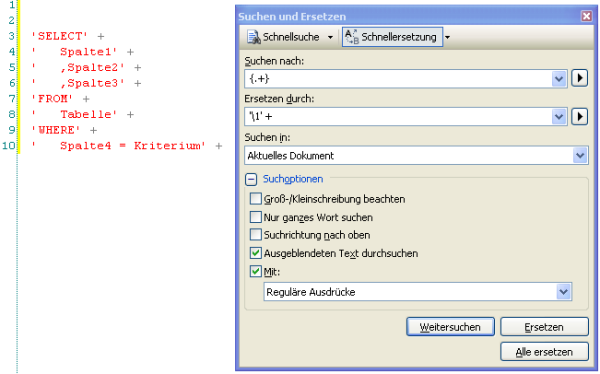
Nun braucht man lediglich das letzte “+” zu entfernen und die Parameterzuweisung (“SET @Variable = “) ergänzen, fertig.
Abschließend sehen wir uns noch eine Übung an, wie sie tagtäglich häufig vorkommt. Weiß der Datenbankentwickler in dem Fall nicht um reguläre Ausdrücke, ist zeitraubende Handarbeit angesagt.
Wir wollen eine ganze Reihe INSERT-Statements um einen “WHERE .. NOT IN..” Part erweitern. Dabei müssen wir selbstverständlich den jeweiligen Wert aus dem INSERT-Teil wiederverwenden (diesen wollen wir ja vor dem Einfügen auf Existenz in der Zieltabelle überprüfen). Es existieren also mehrere INSERT-Statments nach folgendem Muster:
INSERT INTO T_Import_Tabelle SELECT ‘A1′, ‘A1_Text’, ‘A1_Attribut’
Ziel ist es, das Statement folgendermaßen umzubauen:
INSERT INTO T_Import_Tabelle SELECT ‘A1′, ‘A1_Text’, ‘A1_Attribut’ WHERE ‘A1′ NOT IN (SELECT Spalte FROM T_Import_Tabelle GROUP BY Spalte)
Mit dem erworbenen Wissen sollten Sie nun selbst in der Lage sein, die Ersetzung vorzunehmen. Probieren Sie es doch einmal selbst aus.
Hier ist eine mögliche Lösung der Aufgabe:
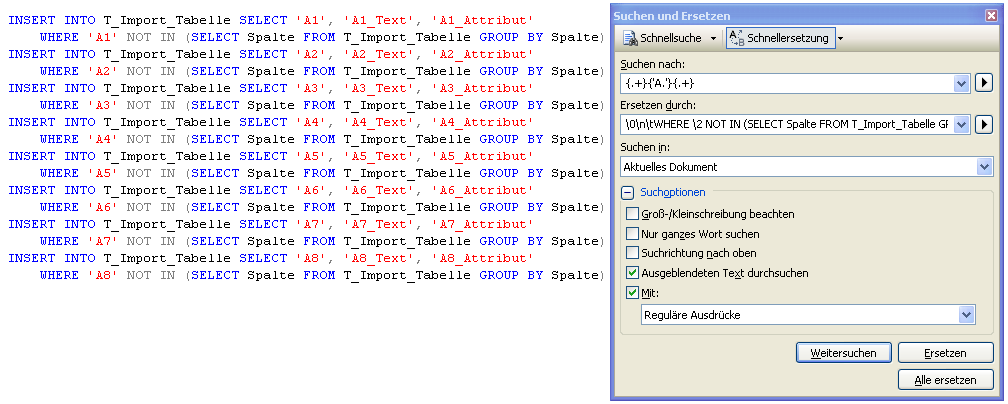
In dem gezeigten Beispiel wird der String in drei Teile zerlegt. Entscheidend ist, dass in dem mittleren Teil noch das “A” qualifiziert wird. Wird dies weggelassen, werden auch die Teile zwischen den ersten jeweiligen Werten (‘, ‘) gefunden. Auch hier kommen zwei einfache Hochkommata sowie zwei beliebige Zeichen dazwischen vor.
In der Ersetzung wurde noch mit zwei Besonderheiten gearbeitet. Zum einen mit “”. Hiermit werden einfach alle Teilausdrücke adressiert (man spart sich also “\1\2\3″). Weiterhin wurde mit “\n” und “\t” gearbeitet. Dies ist lediglich für die spätere Formatierung gedacht. Vor den ergänzenden “WHERE NOT IN”-Text wird ein Zeilenumbruch (= “\n”) sowie ein Tabulator (“\t”) eingefügt.
Abschließend wird einfach zwischen dem “WHERE” und dem “NOT” auf den zweiten Teilausdruck referenziert und somit der Teilausdruck 2 wiederholt. Eigentlich ganz einfach und ungemein effizient. Beim manuellen Erweitern von mehreren hundert Statements wäre einige unnötige Zeit verbraucht worden.
Eine vollständige Liste aller im SQL Server anzuwendenden Befehle finden Sie direkt bei Microsoft unter nachfolgendem MSDN-Link.
Weitere Anwendungen im SQL Server
Neben der Nutzung von regulären Ausdrücken direkt im SQL Server Management Studio können diese auch direkt in T-SQL verwendet werden. Hierzu muss man allerdings zunächst eine neue sogenannte CLR-benutzerdefinierte Funktion in den SQL Server einbinden. CLR steht für Common Language Runtime und ist eine neue Möglichkeit für die Nutzung von benutzerdefinierten SQL-Server-Erweiterungen ab der SQL-Server-Version 2005. Die weiteren Details zum Einbinden der CLR-Funktion und der Nutzung von regulären Ausdrücken in T-SQL sind nicht Bestandteil dieses Artikels. Eine ausführliche Anleitung findet sich direkt im Microsoft Developer Network unter folgendem Link.
