Ob man ein OLAP-Modell auf einem Snowflake- oder Star-Schema aufsetzt ist fast schon eine philosophische Frage, auf die es keine eindeutige Antwort gibt. Es gibt Argumente für das eine wie für das andere Modell. Kürzlich gab es im Rahmen einer Performanceoptimierung in einem Hybridplanungssystem ein schlagendes Argument für ein Star-Schema – die SQL-Server-interne Star-Join-Optimization. Scheinbar setzt Microsoft wieder öfter auf Star-Schemas und hat deren Verwendung intern für Abfragen optimiert. Die Auswirkungen (unter anderem auf die RealTimeOlap-Abfragen) sind deutlich spürbar. Bleibt die Frage wie man mit DeltaMaster ETL zu einem Star-Schema kommt? Schließlich wird hier immer ein Snowflake-Schema erstellt. Überraschenderweise ist der Weg dahin gar nicht so weit – zumindest wenn man auf Hybridplanung setzt. Glauben Sie nicht? Dann lesen Sie diesen Blogbeitrag und staunen.
Warum sich der Umbau auf ein Star-Schema lohnen kann?
Kürzlich saßen wir an einem Hybridplanungssystem, welches nicht die gewünschte Performance zeigte. Es war insbesondere beim Lesen signifikant langsamer als die baugleiche OLAP-Variante. Nach einigen Recherchen wurde deutlich, dass beim Lesen der Planungsmasken sehr viele RealTimeOlap-Abfragen gegen die Hybrid-ROLAP-Partitionen abgesetzt werden. Diese ließen sich mit diversen Komponenten aus den Berichten und der Datenbank erklären. Hauptverursacher für eine hohe Anzahl Abfragen waren das Berichtswetter, das Cube-Script, sowie das Zellfreigabe-MDX der Pivot-Tabelle. Durch Deaktivierung des Wetters und Optimierung des Cube-Scripts konnte ich einige Abfragen „einsparen“, allerdings hatte dieses Vorgehen seine Grenzen. Blieb nur die Laufzeit der einzelnen Abfragen, welche mit 20 ms nicht gerade lang waren. Allein über die hohe Anzahl wurde diese Zeit spürbar. Nach vielen Versuchen und Enttäuschungen erinnerten wir uns an die Star-Join-Optimization der neueren SQL-Server-Versionen. Da wir den SQL-Server 2014 einsetzten, sollte ein Versuch gestartet werden. Die Ergebnisse waren überragend. Einzelne ROLAP-Abfragen waren bis zu 70% schneller, die gesamte Laufzeit des Berichtslesens reduzierte sich um bis zu 50%. Damit war der vielbesagte Fast=True-Schalter gefunden und es konnten zufrieden die Optimierungsversuche eingestellt werden.
Wie man mit DeltaMaster ETL und Hybridplanung zum Star-Schema kommt?
Der Weg zum Star-Schema ist erstaunlich kurz. Praktischerweise haben wir bei der Entwicklung der Hybridskripte ein wenig „vorausgedacht“ und liefern bereits seit vielen Versionen die denormalisierten Dimensionsviews mit aus, die für ein Star-Schema notwendig sind.
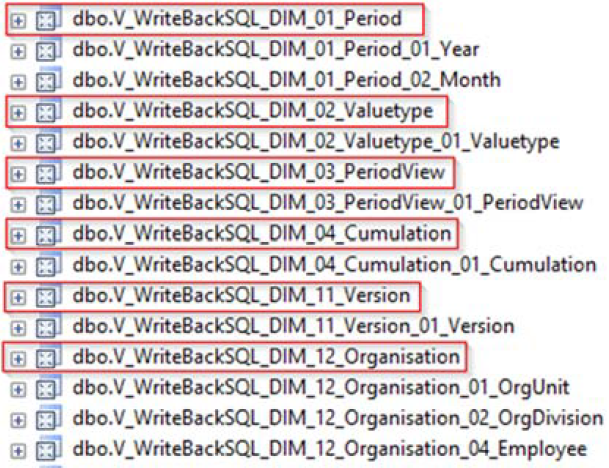
Abbildung 1: Denormalisierte Dimensionsviews aus der Hybridplanung
Dem aufmerksamen Leser wird auffallen, dass es für die Dimensionen mehr als nur eine View gibt. Die Erklärung dafür ist einfach. Die markierten Views sind die vollständig denormalisierten Views, die alle Ebenen und Attribute einer Dimension enthalten. Diese sind nur für den Zweck der späteren Nutzung in einem Star-Schema erstellt worden. Die restlichen Views existieren (wie am Namen unschwer zu erkennen) pro Ebene und werden für den eigentlichen Rückschreibvorgang verwendet. Hier sind aus Speicher- und Performancegründen nur die Ebenen und Attribute enthalten, die für das Rückschreiben notwendig sind. Bezeichnungen oder ähnliches sind hier nicht enthalten. Wie viele dieser Views auf welcher Ebene erstellt werden, hängt von den Ebenen ab mit denen die Dimension an den Rückschreib-MeasureGroups angebunden ist.
Wichtig: In älteren Hybridskriptversionen wurden die Views zwar auch schon angelegt, allerdings noch nicht mit dem vollständig korrekten Spaltenaufbau. Um nachfolgende Schritte auszuführen, ist mindestens die Skriptversion 36 notwendig.
Beide View-Typen werden bereits vollautomatisch materialisiert, so dass auch bei der späteren Abfrage keine Zeit mehr auf der Strecke bleibt.

Abbildung 2: Materialisierte denormalisierte Dimensionsviews
Somit muss „nur noch“ DeltaMaster ETL überzeugt werden, das Modell auch als Star-Schema aufzubauen und nicht wie bisher als Snowflake-Schema. Im ersten Moment mag man meinen, dass das ein
„Showstopper“ ist. Allerdings ist das Vorhaben gar nicht so wild. Wenn man sich vorstellt, wie das fertige Ergebnis einer Dimension in SSAS aussieht, ändert sich daran in einem Star-Schema ja eigentlich gar nichts. Es müssen wie bisher alle Attribute, Hierarchien und Ebenen angelegt werden und das mit den identischen Eigenschaften. Das Einzige was sich ändert sind die Quelltabellen der Attribute, sogar die Spaltennamen bleiben gleich. Damit ist die Anpassung mehr als „überschaubar“.
Die Views die den OLAP-Aufbau in DeltaMaster ETL steuern, beginnen mit „V_Model_OC“¹.
Die Views, welche die relevanten Tabellennamen für die Dimensionen und die zugehörigen Attribute enthalten, sind:
- V_Model_OC_Dimensions_Attributes
- V_Model_OC_Dimensions
- V_Model_OC_DSV_Objects
- V_Model_OC_DSV_Relationships
Wir haben zunächst mal die originalen Views mit dem Suffix „_Orig“ gesichert. Dies ist nötig, da an verschiedenen Stellen auf die Originale zugegriffen werden muss.
Anschließend haben wir nicht die Views selbst angepasst, sondern neue Views mit den Anpassungen erstellt und in den oben genannten Views auf die neuen Views verwiesen. Warum? Ganz einfach – ein unbedachtes Meta-Model-Update und alle o.g. Views wären wieder auf DeltaMaster-ETL-Auslieferungszustand zurückgesetzt. Deshalb haben wir die Logik in Views mit Suffix „_Hybrid“ ausgelagert und verweisen per SELECT * auf diese. Das wäre im Zweifel schnell wieder rekonstruiert.
Hier nun ein Beispiel für solch eine neue View:
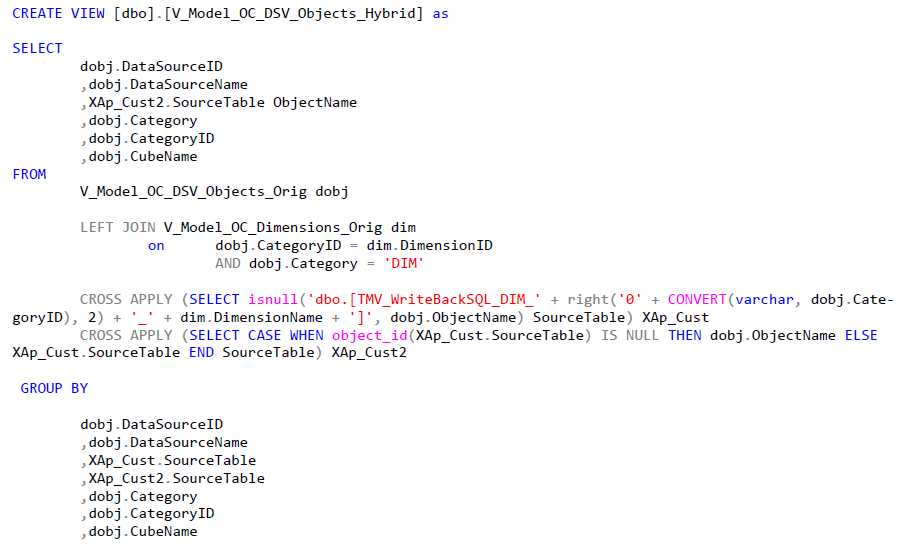
CREATE VIEW [dbo].[V_Model_OC_DSV_Objects_Hybrid] as
SELECT
dobj.DataSourceID
,dobj.DataSourceName
,XAp_Cust2.SourceTable ObjectName
,dobj.Category
,dobj.CategoryID
,dobj.CubeName
FROM
V_Model_OC_DSV_Objects_Orig dobj
LEFT JOIN V_Model_OC_Dimensions_Orig dim
on dobj.CategoryID = dim.DimensionID
AND dobj.Category = 'DIM'
CROSS APPLY (SELECT isnull('dbo.[TMV_WriteBackSQL_DIM_' + right('0' + CONVERT(varchar, dobj.Cate‐
goryID), 2) + '_' + dim.DimensionName + ']', dobj.ObjectName) SourceTable) XAp_Cust
CROSS APPLY (SELECT CASE WHEN object_id(XAp_Cust.SourceTable) IS NULL THEN dobj.ObjectName ELSE
XAp_Cust.SourceTable END SourceTable) XAp_Cust2
GROUP BY
dobj.DataSourceID
,dobj.DataSourceName
,XAp_Cust.SourceTable
,XAp_Cust2.SourceTable
,dobj.Category
,dobj.CategoryID
,dobj.CubeNameWie man gut sieht, wurde lediglich der ObjectName manipuliert. Dieser wird nur verwendet, wenn die neue View (bzw. TMV) auch tatsächlich existiert. Bei den Fakten und bei Dimensionen die nicht vom Hybridwriteback betroffen sind, soll der alte Tabellenname verwendet werden.
Das Ergebnis sieht folgendermaßen aus:
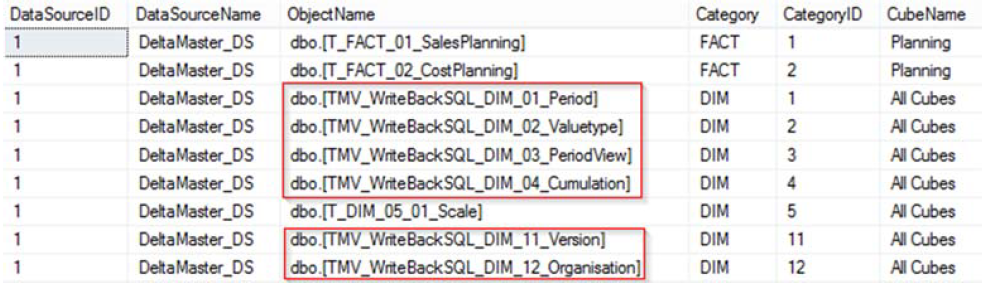
Abbildung 3: Angepasste View V_Model_OC_DSV_Objects
Die eigentliche View welche anschließend von DeltaMaster ETL verwendet wird, sieht dann folgendermaßen aus:

ALTER VIEW [dbo].[V_Model_OC_DSV_Objects] as
SELECT
*
FROM
V_Model_OC_DSV_Objects_HybridSelbiges wird dann für die anderen drei OC-Views wiederholt. Der Code zur Ermittlung des Namens sowie die Prüfung auf Existenz sind immer wieder gleich.
Anschließend muss dann nur noch ein „Deploy OLAP Database“ per DeltaMaster-ETL-GUI gestartet werden. Wenn alles funktioniert hat, sieht das Ergebnis ungefähr so aus:
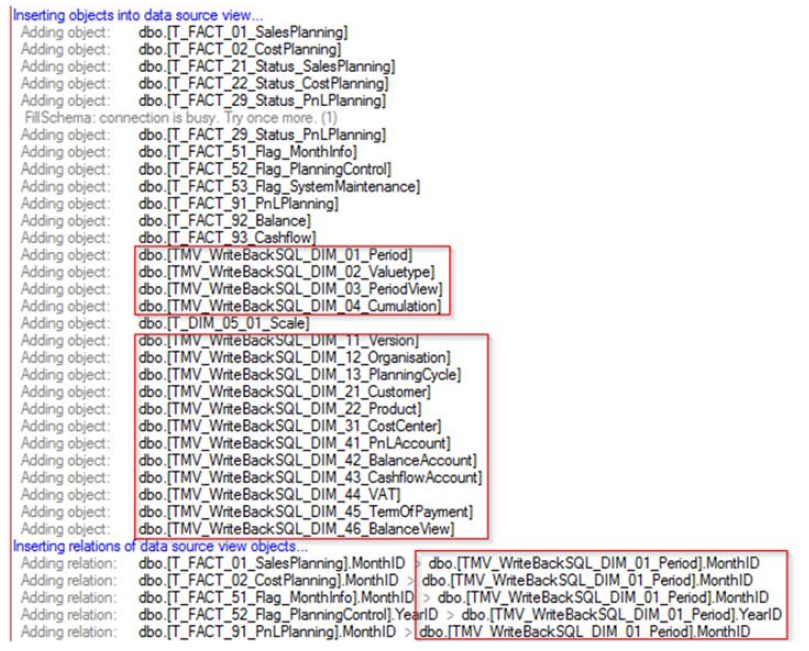
Abbildung 4: Deploy-Log-Einträge eines erfolgreichen Umbaus
In den Log-Meldungen ist deutlich zu sehen, dass nicht auf die Snowflake-Tabellen, sondern auf die denormalisierten TMVs zugegriffen wird.
Klingt abgefahren – ist aber so. Mehr ist nicht zu tun. Hier der Beweis aus den SQL Server Data Tools:
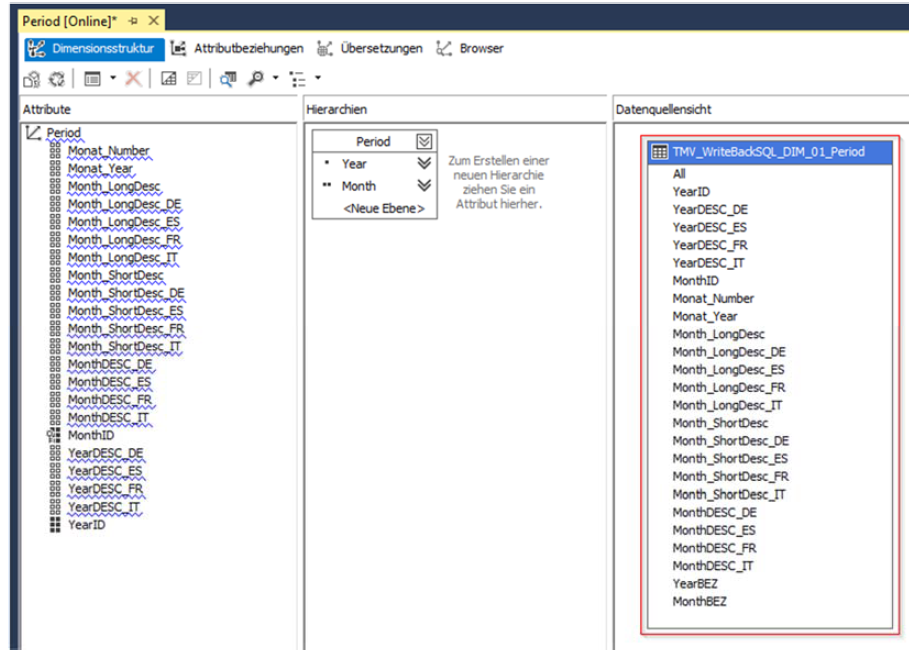
Abbildung 5: Dimension basierend auf Star-Tabelle
Und sonst?
Der oder die ein oder andere mag sich jetzt fragen, wann DeltaMaster ETL Star-Schemas unterstützt? Die Frage ist berechtigt und wird auch nicht ewig unbeantwortet bleiben. Aktuell geplant ist in die nächste Version die Hybridplanung nahtlos zu integrieren, inklusive dem oben beschriebenen optimalen Modelldesign. Aus Gründen der Kompatibilität zu Altmodellen wird es das Snowflake-Schema dann allerdings weiterhin geben und die Denormalisierung wird weiterhin über den oben beschriebenen View-Layer samt Materialisierung erfolgen. Andernfalls ist das Risiko zu hoch, dass wir Bestandsmodelle nach einem Update „kaputt“ machen. Einzig der Namensraum für die Startabellen könnte sich noch ändern, so dass diese eher in der Nähe des Snowflake-Schemas und nicht bei den Rückschreibtabellen liegen. T_DIM_01_Periode (ohne Ebenensuffix) könnte hier die optimale Wahl sein.
Dennoch denken wir auch noch einen Schritt weiter und überlegen schon auch generell eine Wahl zwischen Snowflake- und Star-Schema anzubieten. Wenn wir bei der oben beschriebenen Logik mit den alten Snowflake-Tabellen und dem abgeleiteten Star-Schema bleiben, sollte dies sogar relativ „schmerzfrei“ möglich sein. Für eine echte Alternativlösung mit direkter Befüllung der Star-Tabellen müssten wir noch eine ganze Reihe weiterer Anpassungen vornehmen und auch überlegen wie wir mit der Eindeutigkeit von Elternzuordnungen umgehen. Die Design-Entscheidungen sind hier noch nicht endgültig getroffen und es wird auch noch ein paar Versionen länger dauern bis wir dort sind.
Damit sind wir am Ende des heutigen Artikels angelangt. Wir hoffen, dass das Fast=True-Flag in vielen Planungsprojekten weiterhilft. Und wer mal spicken möchte, wie der Umbau live aussieht, muss einfach nur einen Blick in die neue Chair International V2.0 werfen. Das war nämlich das System, welches optimiert wurde und aus dem die oben gezeigten Beispiele stammen.
¹OC steht für „Olap Creator“
