Im Artikel Über die Nutzung des PIVOT- und UNPIVOT-Operators wurde bereits beschrieben, wie mit Hilfe des PIVOT- und UNPIVOT-Operators Tabellen, in denen die Werte, die später als Kennzahlen analysiert werden sollen, von einer zeilen- in eine spaltenorientierte Struktur und zurück überführt werden können. Dabei liegen die Daten aber bereits in der Datenbank. Sollen die Daten jedoch gleich im „richtigen“ Format in der Datenbank gespeichert werden, müssen sie schon vor dem Import entsprechend umgewandelt werden. Bei der Nutzung des SQL-Servers als Datenbank-Managementsystem stehen für die Abbildung komplexer ETL-Prozesse die SQL Server Integration Services (SSIS) zur Verfügung. Hier befinden sich zur Lösung oben genannter Fragestellung die Datenflusskomponenten PIVOT und UNPIVOT. Dieser Artikel soll die Nutzung dieser beiden Datenflusskomponenten beim Import von Währungskursen aus einer Textdatei in eine Datenbank genauer beschreiben.
Die Datenflusskomponente UNPIVOT
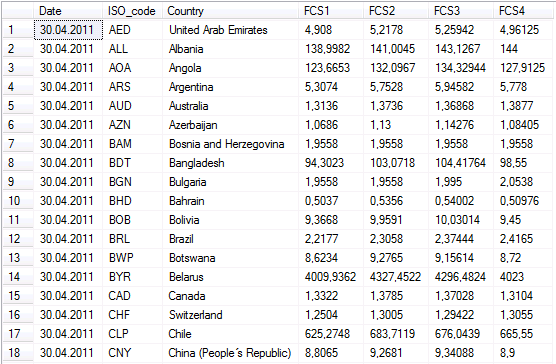
Der folgende Screenshot stellt einen Ausschnitt einer Textdatei dar, in der sich Umrechnungskurse der jeweiligen Landeswährungen in die Währung Euro befinden. Die Besonderheit liegt darin, dass die Kurse zeilenweise zwar pro Tag, aber spaltenweise pro Quartal (FCS1 – FCS4) abgelegt sind.
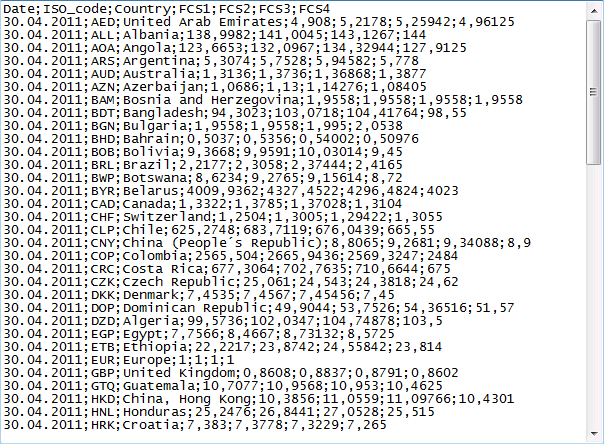
Um die Umrechnungskurse datenbankseitig besser verarbeiten zu können, wäre es hilfreich, die Kurse in nur einer Spalte (Currency_Rate) und die Information über das Quartal in einer weiteren Spalte (Quarter_ID) zu speichern.

Beim Import der Daten mit Hilfe der SSIS wird im Datenflusstask zwischen der Quelldatei und der Zieltabelle die Datenflusskomponente UNPIVOT genutzt.
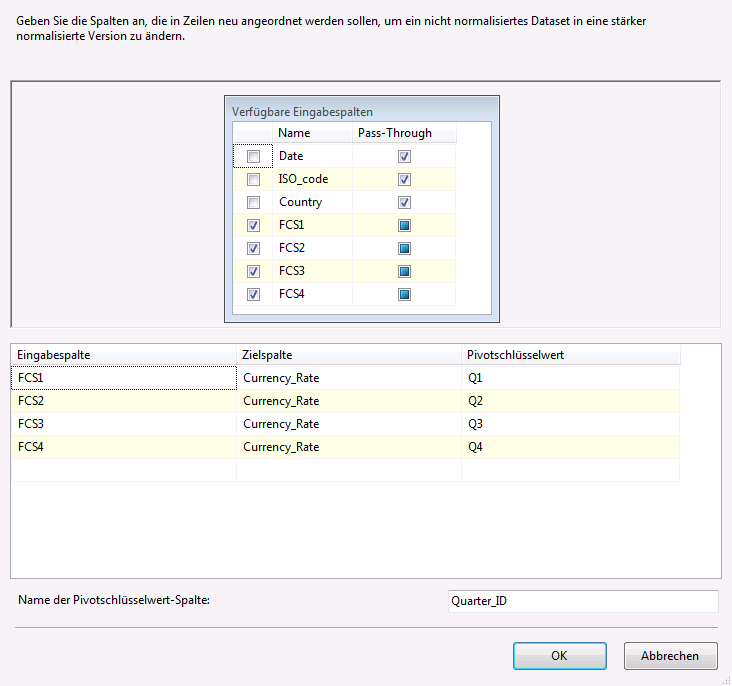
Im Transformations-Editor der UNPIVOT-Komponente (aufrufbar durch Anklicken des Eintrages „Bearbeiten“ im Kontextmenü der Komponente) müssen entsprechende Einstellungen getroffen werden, um die Daten in das gewünschte Format zu überführen.
Im oberen Bereich der verfügbaren Spalten muss zunächst unterschieden werden, welche Spalten 1:1 weitergegeben und welche Spalten umgewandelt werden sollen. Im gezeigten Beispiel sollen die Inhalte der Spalten Date, ISO_code und Country 1:1 weitergegeben werden. Dafür müssen Häkchen in der Spalte Pass-Through der entsprechenden Zeile gesetzt werden. Die Inhalte der Spalten FCS1 – FCS4 sollen in eine neue Spalte überführt werden. Dafür müssen Häkchen in der ersten Spalte der entsprechenden Zeile gesetzt werden. Anschließend muss im unteren Bereich unter „Zielspalte“ definiert werden, wie die Spalte heißen soll, in die die Kurse überführt werden sollen. Im gezeigten Beispiel wurde diese Spalte Currency_Rate benannt. In der Spalte Pivotschlüsselwert wird definiert, welche Quartalsinformation zum jeweiligen Kurs übergeben werden soll. Diese Information wird in der Spalte abgelegt, für die im Feld Name der Pivotschlüsselwert-Spalte angegeben wurde, im gezeigten Beispiel Quarter_ID.
Nach korrekter Einstellung im Transformations-Editor und der Definition des Datenflusszieles kann der Datenimport durch Ausführen des Datenflusstasks gestartet werden. Das Ergebnis der Umwandlung kann durch eine Abfrage der Zieltabelle zum Beispiel im SQL Server Management Studio begutachtet werden.
Die Datenflusskomponente PIVOT
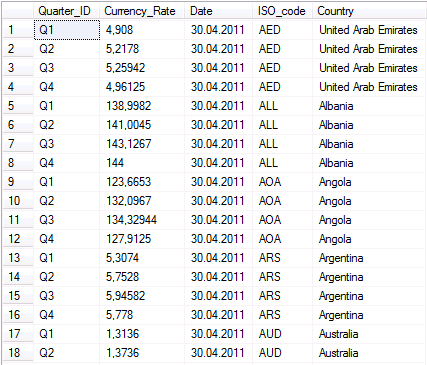
Die Datenflusskomponente PIVOT kann genutzt werden, wenn Daten während des Imports in ein spaltenorientiertes Format umgewandelt werden müssen. Soll also folgende Quelldatei, welche im Wesentlichen dem Ergebnis des oben aufgeführten Transformationprozesses mit Hilfe der UNPIVOT-Datenflusskomponente entspricht, in ein spaltenorientiertes Format überführt werden,
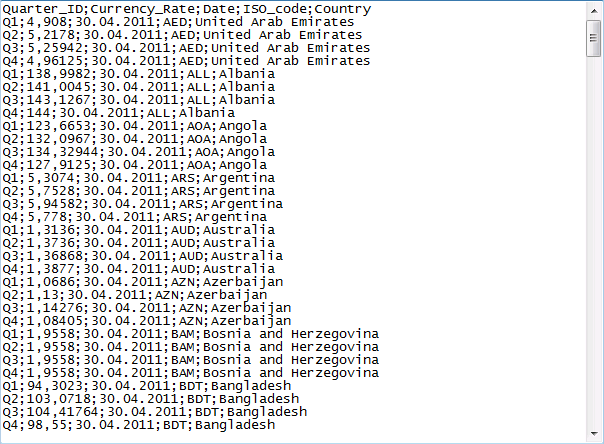
müssen folgende Einstellungen im Datenflusstask vorgenommen werden. Zwischen der Quelldatei und der Zieltabelle wird die PIVOT-Datenflusskomponente platziert.
Anschließend muss der Transformationsprozess im erweiterten Editor der PIVOT-Datenflusskomponente detailliert definiert werden.
Die Einstellungen auf der Registerkarte Komponenteneigenschaften können in aller Regel standardmäßig übernommen werden. Auf der Registerkarte Eingabespalten werden dann die Spalten aktiviert, welche beim Import berücksichtigt werden sollen.
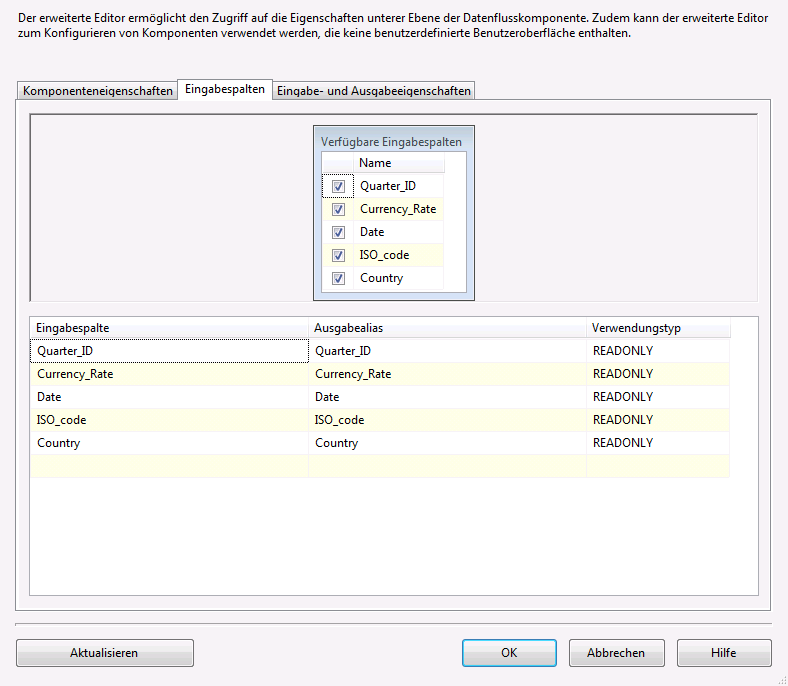
Danach wird auf der Registerkarte „Eingabe- und Ausgabeeigenschaften“ festgelegt, welche Spalten umgewandelt werden und wie diese heißen sollen.
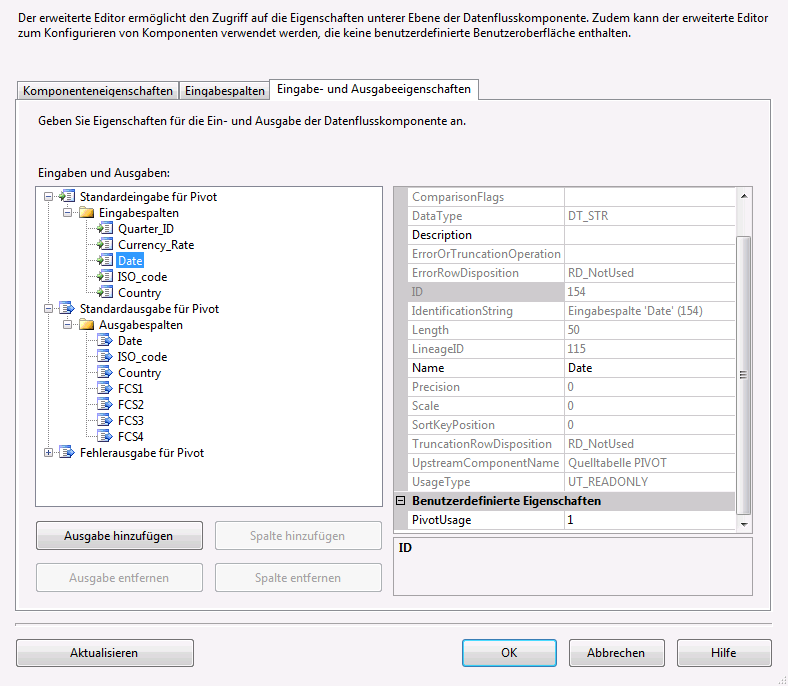
Zunächst muss für jede Eingabespalte im Feld PivotUsage im Eigenschaftenfenster der jeweiligen Spalte deren Verwendung definiert werden. Im gezeigten Screenshot wird für die Spalte Date der Wert 1 definiert. Diese Einstellung bewirkt, dass der Inhalt der Spalte jedem Datensatz hinzugefügt wird, dabei werden Datensätze mit demselben Schlüssel zu einer Zeile zusammengefasst. Für die Spalten ISO_code und Country wird ebenfalls der Wert 1 im Feld PivotUsage definiert, denn auch die Inhalte dieser Spalten sollen in der Ausgabe bzw. Zieltabelle als Bestandteil eines eindeutigen Zeilenschlüssels enthalten sein. Würden diese Spalten bei der Transformation unberücksichtigt bleiben, würden die Kurse der einzelnen Länder auf einen Tageswert summiert werden, was wiederum zu falschen Umrechnungskursen führen würde.
Für die Spalte Quarter_ID wird im Feld PivotUsage der Wert 2 gesetzt. Mit diesem Wert wird die Pivotspalte definiert, d.h. aus jedem Spaltenwert wird eine Spalte erstellt.
Für die Spalte Currency_Rate wird im Feld PivotUsage der Wert 3 gesetzt. Dieser Wert bewirkt, dass die Inhalte diese Spalte bei der Transformation als Ergebnis in die Pivotspalten abgelegt werden.
Folgende Tabelle, die einen Auszug aus der SQL-Server Hilfe darstellt, beschreibt die einzelnen Optionen im Detail.

Ausgabespalten werden durch Anklicken des Buttons Ausgabe hinzufügen im unteren Bereich der Registerkarte Eingabe- und Ausgabeeigenschaften eingefügt. Auch hier müssen für jede Ausgabespalte spezielle Einstellungen vorgenommen werden.
Für die Ausgabespalten muss im Eigenschaftenfenster im Feld SourceColumn der Herkunftsbezeichner der Quellspalte angegeben werden. Den Herkunftsbezeichner findet man unter den entsprechenden Eingabespalten im Feld LineageID. Im folgenden Screenshot verweist die Ausgabespalte Date auf die Eingabespalte mit dem Herkunftsbezeichner (LineageID) = 115, was der Eingabespalte Date entspricht. Die Ausgabespalte ISO_code verweist auf die Eingabespalte ISO_code und die Ausgabespalte Country verweist auf die Eingabespalte Country.
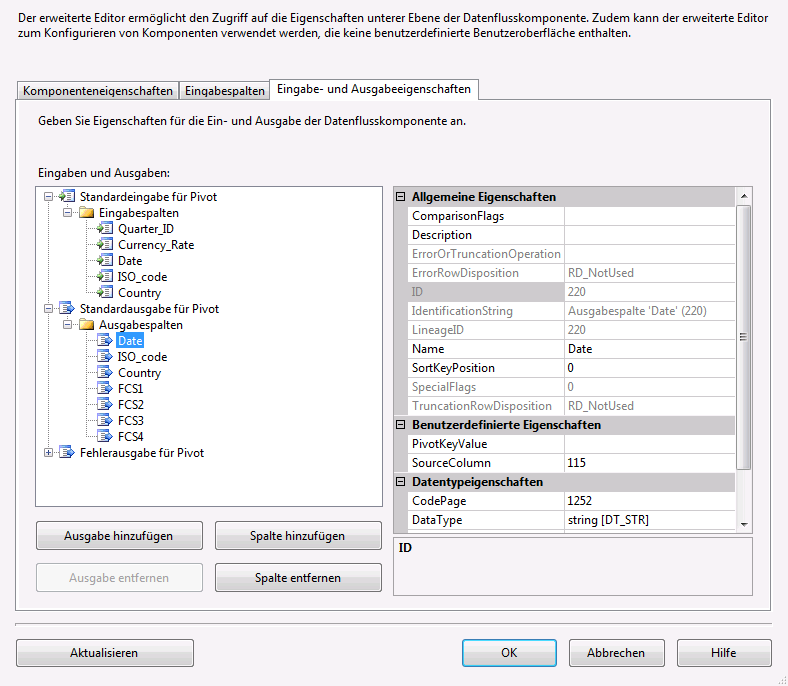
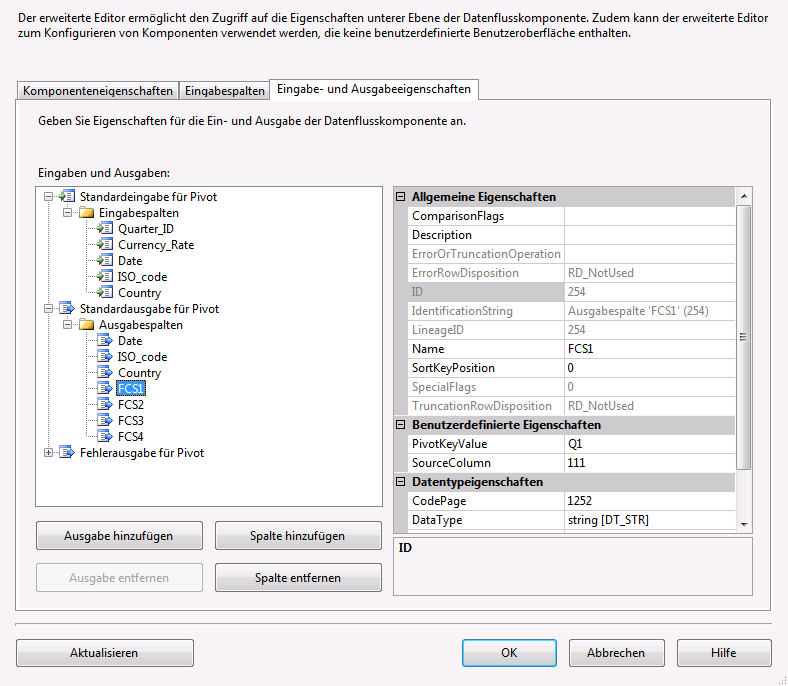
Die Ausgabespalten FSC1 – FSC4 verweisen alle auf die Eingabespalte Currency_Rate mit der LineageID= 111. Zusätzlich zur SourceColumn muss bei diesen vier Ausgabespalten im Feld PivotKeyValue der Wert des jeweiligen Quartals (Q1 – Q4), welche in der Eingabespalte Quarter_ID vorkommen kann, angegeben werden.
Auch in diesem Fall kann nach korrekter Einstellung im erweiterten Editor der PIVOT-Datenflusskomponente und der abschließenden Definition des Datenflusszieles, der Datenimport durch Ausführen des Datenflusstasks gestartet werden. Das Ergebnis der Umwandlung kann ebenfalls durch eine Abfrage der Zieltabelle, zum Beispiel im SQL Server Management Studio, begutachtet werden.