Das Verständnis von Ausführungsplänen ist eine der Grundvoraussetzungen, um ein effizientes Performancetuning von SQL-Code durchführen zu können. Eine der aussichtsreichsten Optimierungsmaßnahmen ist beispielsweise die Indexoptimierung, für die Ausführungspläne zahlreiche wichtige Hinweise liefern. Dieser Blogbeitrag beschäftigt sich mit der Funktionsweise der wichtigsten in den Ausführungsplänen von SQL Server auftretenden Operatoren, die für Tuningmaßnahmen genauer betrachtet werden sollten. Es werden Hinweise gegeben, warum welcher Operator von SQL Server gewählt wird und welche Probleme sich dahinter verbergen können.
Bedeutung von Ausführungsplänen für die Performanceoptimierung
Wer regelmäßig SQL-Code erstellt, wird sicherlich das eine oder andere Mal auf langlaufende Ausführungszeiten bei deren Ausführung gestoßen sein. Im täglichen Projektgeschäft bleibt dann meist nicht genügend Zeit, sich mit den Ursachen auseinanderzusetzen. Als Sofortmaßnahmen werden gerne Abfragen materialisiert, was hilfreich sein kann, aber auch zusätzliche Verwaltungsschritte und Speicherplatz im Datenbanksystem erfordert. Manchmal wird die eingesetzte Hardwareausstattung mit schnelleren Komponenten ausgestattet, bei virtuellen Systemen ist das gelegentlich auch kurzfristig machbar. Manchmal wird auch anhand der Betrachtung des SQL-Codes auf Verdacht indiziert.
SQL-Statements lassen sich hinsichtlich der Optimierung von Ausführungszeiten anhand der Ausführungspläne des SQL Servers systematisch untersuchen. Nur Ausführungspläne zeigen, wie ein Statement tatsächlich zerlegt und abgearbeitet wird. So wird bspw. schnell sichtbar, ob die Ausführung eines Joins für lange Ausführungszeiten verantwortlich ist oder eine implizite Konvertierung Probleme verursacht. Operatoren mit hohen Kosten fallen schnell auf und sollten genau analysiert werden, Operatoren im kleinen einstelligen Prozent-Kostenbereich dagegen sind sicherlich nicht die ersten Anlaufstellen für effektives Tuning.
Allerdings sollte man beim Untersuchen von langlaufenden SQL-Statements beachten, dass Ausführungspläne von vorhandenen Bedingungen abhängen, wie der Größe des verfügbaren Arbeitsspeichers oder der jeweiligen SQL-Server-Konfiguration. Eine Testumgebung ist für ein Performancetuning möglicherweise wenig hilfreich, wenn die beteiligten Tabellen nur einen Teil der Daten enthalten, die das Produktivsystem verarbeiten wird. Der SQL-Server-Optimierer wird dann möglicherweise von einer anderen Datenselektivität ausgehen – es werden unter Umständen unbrauchbare Indizes vorgeschlagen. Das Produktivsystem kann über eine andere Speicher-/Prozessor- oder I/O-Konfiguration verfügen, was die Auswahl der Join-Strategie des Optimierers beeinflusst.
Um kostenintensive Operationen in Ausführungsplänen optimieren zu können, sollte man deren Arbeitsweise genau kennen. Nur dann lässt sich beurteilen, ob SQL Server bereits optimale Bedingungen vorfindet oder Anpassungen im SQL-Code, an Datenbankobjekten, Konfigurationseinstellungen oder der Hardware notwendig sind. Bspw. lässt sich ein Flaschenhals im I/O System nicht vollständig durch Tuningmaßnahmen von SQL-Code und Datenbankobjekten beseitigen, sondern erfordert zusätzlich eine Untersuchung und Optimierung der eingesetzten Hardware.
Im Folgenden werden nun einige Operatoren aus Ausführungsplänen vorgestellt, die wichtige Hinweise auf mögliche Performanceprobleme geben. Grundkenntnisse über Ausführungspläne sind dafür notwendig.
Table Scan, Index Scan, Index Seek, RID Lookup, Key Lookup
Diese Gruppe von Operatoren bezieht sich auf das Lesen von Tabellen und Indizes. Ein Scan-Vorgang bedeutet, dass grundsätzlich eine Tabelle oder ein Index komplett gelesen wird. Bei einem Seek-Vorgang wird ein Index durchsucht und kann Folgeoperatoren wie Key Lookups beinhalten.
 Table Scan: Eine Tabelle wird komplett gelesen, um daraus die benötigten Daten zu selektieren.
Table Scan: Eine Tabelle wird komplett gelesen, um daraus die benötigten Daten zu selektieren.
- Arbeitsweise: Der Table Scan wird immer auf einem sogenannten Heap (Haufen) ausgeführt, also einer Tabelle, die keinen Index enthält. Aber auch wenn ein oder mehrere nicht-gruppierte Indizes vorhanden sind, führt SQL Server dennoch einen Table Scan durch, wenn diese Indizes für die jeweilige Konstellation als nicht geeignet angesehen werden, d. h. deren Selektivität als zu gering beurteilt wird oder vollständig ungeeignet ist. Ein Index auf einer Spalte, die nur wenige verschiedene Werte enthält, weist eine geringe Selektivität auf. SQL Server tendiert dann dazu, das komplette Lesen der Basistabelle als effektiver anzunehmen als vorhandene Indizes zu durchsuchen, da größere Teile der Basistabellen benötigt werden, auch wenn ein Index prinzipiell passen würde.
SQL Server wird aber auch bei guter Index-Selektivität kleinere Tabellen immer komplett lesen, da das gegenüber einer Durchsuchung des Index als schneller angesehen wird. Eine Grenze, ab der SQL Server sich gegen einen Scan entscheidet, hängt auch von der eingesetzten Hardware ab, dabei v. a. von dem ermittelten Antwortzeitverhalten des I/O-Systems.
- Tuning: Ein Table Scan ist ein starker Hinweis auf fehlende oder suboptimale Indizes. Geeignete Indizes zu ermitteln, rentiert sich, wenn die Kosten für den Table-Scan-Operator signifikant sind. Ein Table Scan, der bspw. 1% der gesamten Verarbeitungszeit im Ausführungsplan aufweist, ist sicherlich (zunächst) kein geeigneter Optimierungskandidat. Aber Vorsicht! Ein Blick auf die nachfolgenden Operatoren ist nötig. Folgt bspw. auf den Table Scan ein teurer Index-Spool-Operator, dann ist es dennoch sinnvoll, über einen geeigneten Index nachzudenken.
Das Finden eines geeigneten Index würde den Rahmen dieses Blogbeitrags sprengen und ist somit ein Thema für einen späteren Beitrag. Daher sollen folgende Hinweise zur Vorgehensweise ausreichen:
- Prüfen der Prädikate des Scan-Operators und der Ausgabespalten, also derjenigen Spalten, die aus einer eingelesenen Tabelle tatsächlich benötigt werden. Die Prädikate sind in jedem Fall Kandidaten für einen geeigneten Index. Werden Ausgabespalten bspw. in späteren Join-Operatoren als Prädikate aufgegriffen, sind diese ggf. ebenfalls Indexkandidaten während reine Ausgabespalten Kandidaten für eine reine Inkludierung in einen nicht-gruppierten Index sein können.
- Prüfen der Selektivität von Spalten, die als Indexkandidaten in Frage kommen. SQL Server tendiert dazu, Indizes zu verwenden, die eine möglichst hohe Selektivität aufweisen, wobei bei Indizes aus mehreren Spalten die Reihenfolge wichtig ist. Die Spalte mit der höchsten Selektivität ist zumeist an erster Stelle im Index zu setzen, wobei SQL Server nicht immer zum Schluss kommt, dass diese Vorgehensweise optimal ist. Gelegentlich ist ein Ausprobieren mit verschiedenen Reihenfolgen nötig, wobei bei jedem Versuch ggf. der Plancache des SQL Servers geleert werden sollte, bevor ein neuer Ausführungsplan für die veränderten Bedingungen untersucht wird.
 Clustered Index Scan: Einlesen eines gruppierten Index (engl. gruppiert = clustered), d. h. einer Tabelle, die einen Clustered Index aufweist.
Clustered Index Scan: Einlesen eines gruppierten Index (engl. gruppiert = clustered), d. h. einer Tabelle, die einen Clustered Index aufweist.
- Arbeitsweise: Effektiv wird eine Tabelle mit einem gruppierten Index komplett durchsucht. Die Datenseiten der Tabelle sind in diesem Fall bereits entsprechend dem vorgegebenen Index sortiert und bilden somit den Index selbst. Daher wird von einem Index Scan gesprochen. Das komplette Lesen des Index (also der gruppiert indizierten Tabelle) erfolgt, weil bspw. eine WHERE-Klausel bei der Abfrage fehlt oder aber der SQL Optimierer zum Schluss kommt, dass wesentliche Teile des Index aufgrund der Abfrage ohnehin benötigt werden. Das komplette Einlesen ist somit effizienter als das Durchsuchen des Index. Wenn die Abfragebedingungen (Prädikate) sich auf Spalten beziehen, die nicht vom Index in geeigneter Weise abgedeckt sind, erfolgt immer ein Clustered Index Scan.
- Tuning: Der gruppierte Index hilft in diesem Fall also nur bedingt, da dennoch die ganze oder ein wesentlicher Teil der Tabelle gelesen wird. Jedoch ist der Index zumindest bedingt hilfreich, da die bereits sortierte Reihenfolge der Tabelle später evtl. benötigte Sortierungen vermeiden kann. Ein Beispiel wäre ein nachfolgender Sort-Operator zur Vorbereitung eines Merge Joins, der so entfällt. Ein Tuning erfolgt analog den Hinweisen beim Table-Scan-Operator. Man sollte dabei beachten, dass gruppierte Indizes v. a. bei sogenannten Bereichssuchen effektiv sind, wie BETWEEN, >, <, >=, <= in der WHERE-Klausel.
 Nonclustered Index Scan: Entsprechend dem Schlüsselwort „Scan“ wird der nicht-gruppierte Index komplett eingelesen.
Nonclustered Index Scan: Entsprechend dem Schlüsselwort „Scan“ wird der nicht-gruppierte Index komplett eingelesen.
- Arbeitsweise: Der nicht-gruppierte Index wird nicht durchsucht, sondern es werden sämtliche Indexseiten auf Blattebene komplett gelesen. Diese Operation ist langsamer als ein Index Seek, jedoch vermeidet SQL Server möglichst Zugriffe auf die physische Tabelle. Dadurch vermindert sich die Menge zu lesender Daten bzw. Datenseiten und entsprechender I/O-Zugriffe, auch wenn der Index komplett gelesen wird. Beim Index Scan ist für den Optimierer aber ersichtlich, dass die meisten Zeilen eines Index benötigt werden, d. h. ein sequentielles Lesen ist effizienter als ein Durchsuchen. Andererseits werden die meisten oder alle benötigten Daten im Index gefunden (bspw. auch durch gezielte Verwendung von Include-Spalten).
- Tuning: Das Durchsuchen eines nicht-gruppierten Index wird aufgrund bspw. einer impliziten oder expliziten Typkonvertierung verhindert. Gerne wird bspw. eine implizite Konvertierung zwischen nvarchar- und varchar Spalten nicht beachtet. Ein weiterer Grund können Skalarfunktionen in den Suchprädikaten sein. SQL Server weiß in diesen Fällen zwar, dass die benötigten Daten im Index vorhanden sind, kann diese jedoch nicht effektiv selektieren und liest daher den ganzen Index, was gegenüber dem Lesen der Basistabelle aber noch vorteilhaft ist, da sich dort die benötigten Daten üblicherweise auf mehr Datenseiten verteilen.
 Clustered Index Seek: In einer Tabelle wird über den gruppierten Index zugegriffen.
Clustered Index Seek: In einer Tabelle wird über den gruppierten Index zugegriffen.
- Arbeitsweise: SQL Server kann gezielt Blöcke einer Tabelle mit Hilfe des gruppierten Index suchen und herauspicken, ohne die komplette Tabelle laden zu müssen.
- Tuning: Wird ein gruppierter Index von SQL Server durchsucht, d. h. im Sinne eines Index verwendet, ist dies zumeist optimal. Voraussetzung ist eine WHERE-Bedingung, also ein oder mehrere Suchprädikate, die vom Index abgedeckt sind. Ein gruppierter Index eignet sich besonders für Bereichssuchen. In anderen Fällen kann ggf. ein nicht-gruppierter Index effizienter sein – v. a., da Ausgabespalten im Index inkludiert werden können, was bei einem gruppierten Index nicht möglich ist. Weiterhin ist ein gruppierter Index suboptimal, wenn häufig Datenänderungen der Spalten des gruppierten Index vorkommen, da dies den Index stark fragmentieren kann und zusätzlich vorhandene nicht-gruppierte Indizes beeinflusst.
 Nonclustered Index Seek: Es wird der Indexbaum eines nicht-gruppierten Index durchsucht.
Nonclustered Index Seek: Es wird der Indexbaum eines nicht-gruppierten Index durchsucht.
- Arbeitsweise: SQL Server sieht die Verwendung eines nicht-gruppierten Index als vorteilhaft an und durchsucht den Index gezielt nach Daten. Im Idealfall ist der Index abdeckend, so dass keine Zugriffe auf die Basistabelle nötig sind.
- Tuning: Diese Operation ist gegenüber einem Index Scan im Vorteil, da gezielt einzelne benötigte Datenseiten über den Index herausgepickt werden können. Wird der Index im Zuge einer Bereichssuche verwendet (wie BETWEEN, >, <, >=, <=) ist ggf. ein gruppierter Index dennoch besser geeignet. Es sollte geprüft werden, ob sich dem Nonclustered Index Seek ein RID-Lookup-Operator anschließt. Das ist dann ein Hinweis darauf, dass der Index nicht abdeckend ist, also nicht alle benötigten Daten selbst bereitstellen kann, sondern aus der zugeordneten Basistabelle die Datenseiten mit den benötigten Daten gelesen werden müssen. In diesem Fall sollten fehlende Spalten direkt in den Index aufgenommen oder nicht indiziert als Include-Spalten dem Index hinzugefügt werden. Weiterhin ist es möglich, dass der Index auch bei vollständiger Abdeckung noch verbesserbar sein könnte, da ggf. die Indexspalten in einer noch optimaleren Reihenfolge angeordnet eine noch höhere Selektivität aufweisen könnten.
 RID Lookup: Über die in einem nicht-gruppierten Index gespeicherte RowID wird direkt auf die Datenseite der Basistabelle zugegriffen.
RID Lookup: Über die in einem nicht-gruppierten Index gespeicherte RowID wird direkt auf die Datenseite der Basistabelle zugegriffen.
- Arbeitsweise: Wenn in einem Index-Suchvorgang eines nicht-gruppierten Index nicht alle benötigten Spaltenwerte gefunden werden, d. h. der nicht-gruppierte Index nicht abdeckend ist, dann müssen die fehlenden Werte aus den Datenseiten der Basistabelle gelesen werden. Über die RowID des Index wird dann direkt auf die Datenseite der Basistabelle zugegriffen. Der RID Lookup wird auch immer im Zuge eines Nested Loop Joins angelegt. Hierbei werden Zeilen aus einer Tabelle selektiert, die nicht indiziert ist (Heap). SQL Server setzt temporäre Bookmarks, also eine Art Index, um bereits selektierte Zeilen im Wiederholungsfall schneller erneut lesen/finden zu können.
- Tuning: Das Auftauchen dieses Operators deutet auf eine suboptimale Konstellation hin, im Grunde immer auf nicht abdeckende Indizes. Die Prädikate eines vorangegangenen Non-Clustered-Index-Seek-Operators sollten nochmals untersucht werden, um fehlende Spalten in den dort verwendeten Index aufzunehmen.
 Key Lookup: Ein gruppierter Index wird durchsucht, dieser ist jedoch nicht abdeckend.
Key Lookup: Ein gruppierter Index wird durchsucht, dieser ist jedoch nicht abdeckend.
- Arbeitsweise: Es wird ähnlich dem RID Lookup eine Bookmark-Liste angelegt. Die einzelnen Bookmarks verweisen auf die benötigten Datenseiten des gruppierten Index (Tabelle). Hierbei wird der Schlüssel des gruppierten Index (RowID) als Bookmark verwendet, um die benötigten Daten zu ermitteln. Ein Key Lookup wird auch einem Nested Loop Join beigefügt, der die Ergebnisse zweier Operationen zusammenführt. Dies erfolgt analog dem RID Lookup jedoch auf Basis eines gruppierten Index.
- Tuning: Ein für eine Abfrage nicht abdeckender gruppierter Index wird verwendet. Es besteht daher Optimierungspotential, indem weitere Spalten in den Index aufgenommen werden. Allerdings ist das Aufnehmen von beliebig vielen Spalten beim gruppierten Index nicht unbegrenzt empfehlenswert.
Spool-Operatoren
Spool-Operatoren speichern immer Zwischenergebnisse einer Operation in der Tempdb, wenn eine Wiederverwendung zu erwarten ist, um das wiederholte Erstellen der Eingabezeilen für bestimmte Operatoren zu vermeiden. Das ist jedoch nur möglich, wenn keine sogenannte Datenbindung besteht, d. h. Daten bspw. nicht aus Funktionen stammen. Das temporäre Objekt des Spools kann ein Index sein oder eine Tabelle, das nach Beendigung einer Abfrage wieder gelöscht wird. Wird also das gleiche SQL-Statement erneut ausgeführt, wird das Spool-Objekt erneut angelegt. Daher sind diese Operatoren ein wichtiger Hinweis auf möglicherweise fehlende Indizes.
Spool-Operatoren sind ein gutes Beispiel dafür, mit welchen (cleveren) Strategien der SQL Optimierer versucht, nicht optimalen Bedingungen selbst auf die Sprünge zu helfen. Sie lassen sich jedoch nicht parallel ausführen, d. h. SQL Server verarbeitet diese nur sequenziell. Der Grund hierfür ist das Locking der Spool-Tabelle/des Index in der Tempdb. Beispiele, wann Table-Spool-Operatoren auftreten können:
- TOP-Operator, d. h. es wird vermieden immer wieder bspw. die Top 10 Ergebniszeilen erneut zu ermitteln.
- SET ROWCOUNT(number) wurde auf einen „zu hohen“ Wert gesetzt (Rowcount bewirkt, dass die Verarbeitung der Abfrage durch SQL Server beendet wird, sobald die angegebene Anzahl von Zeilen zurückgegeben wurde)
- Joins, die eine große Datenmenge zurückgeben, zumeist ausgeführt auf nicht indizierten Tabellen
- Oder-Abfragen
- UDFs (User defined functions) können Table Spools auslösen
- Veraltete Index Statistiken (SQL Server verschätzt sich)
- Allgemein Abfragen, die eine hohe Anzahl Daten aus einem nicht-gruppierten Index ergeben
Je nach Situation greift SQL Server auf verschiedene Typen von Spool-Operatoren zu:
![]() /
/ ![]() Table Spool: Der Operator liest Eingabezeilen und legt diese als Kopie in einer versteckten Tabelle der Tempdb ab.
Table Spool: Der Operator liest Eingabezeilen und legt diese als Kopie in einer versteckten Tabelle der Tempdb ab.
- Arbeitsweise: Der Table-Spool-Operator kann in einem Ausführungsplan mehrfach auftreten, da der Ausführungsplan immer die logische Abfolge der Operationen zeigt. So kann es sich beim Auftauchen mehrerer Zugriffe auf einen Table Spool physikalisch jedoch um einen einzigen Vorgang handeln, da das Spool-Objekt nur einmal tatsächlich erstellt wird, aber mehrmals abgefragt wird.
Es gibt zwei verschiedene Vorgehensweisen beim Erstellen der Spool-Objekte: Eager Spool und Lazy Spool. Ein Spezialfall hiervon ist der Window Spool-Operator.
- Typ 1 – Eager Spool: Diese (logische) Table Spool Variante lädt alle benötigten Zeilen, sobald die erste Zeile aus dem Spool angefordert wird. Eager bedeutet sinngemäß „arbeitsfreudig“ und zählt zu den sogenannten „blocking operators“.Der Eager Spool dient unter anderem der Optimierung von nicht-gruppierten Indizes beim Update. Die Daten werden komplett geladen, Index-Update-Operationen auf den gelesenen gespoolten Daten mehrfach ausgeführt.
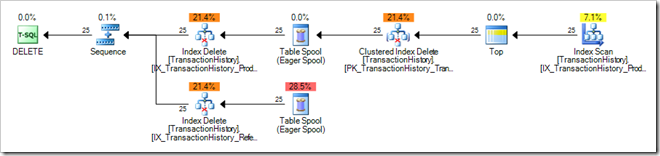
Abb. 1: Eager Spool beim Datenupdate
Beim Update oder Löschen von Datenzeilen einer gruppiert indizierten Tabelle müssen auch alle nicht-gruppierten Indizes aktualisiert werden. SQL Server kann bei wenigen Mengen auf ein Per-Row Update zugreifen, d. h. Update direkt auf der Datenzeile der Tabelle. Bei vielen Zeilen wird ein sogenanntes Unordered Prefetch ausgeführt. Dabei liest SQL Server diese in die Spool-Tabelle ein und führt den Index-Update auf dem ersten nicht-gruppierten Index aus, danach auf dem zweiten usw. wobei das wiederholte Lesen aus der Basistabelle vermieden wird. Der Spool enthält somit die Menge aller Datenspalten, die durch nicht-gruppierte Indizes abgedeckt sind.
Der Eager Spool wird von SQL Server zudem verwendet, um eine komplette Trennung von Lese- und Schreibphasen einer Update-Abfrage zu erreichen (sog. „Halloween“-Effekt).
Tuning: Eager Spools können in bestimmten Situationen nicht vermieden werden, bspw. beim Datenupdate. Ansonsten ist zu untersuchen, ob nicht indizierte Tabellen im Spiel sind und indiziert werden können, sodass SQL Server den Indexzugriff als effektiver errechnet.
- Typ 2 – Lazy Spool: Das Wort Lazy („faul“) deutet auf die genaue Arbeitsweise des Operatortyps hin. Das Zwischenspeichern der Werte geschieht nur auf Anforderung, d. h. erst wenn der Vateroperator des (logischen) Lazy Spools eine Datenzeile verlangt, fordert der Spool-Operator diese von seinem Eingabe-Operator an und speichert diese im Spool-Objekt.Tuning: Lazy Spools sind zwar eine Strategie, um die Abfrageperformance zu verbessern, jedoch deutet deren Auftreten darauf hin, dass ggf. keine optimale Indizierung vorliegt. Das Schreiben in die Tempdb kann massive I/O-Operationen auf dem physischen Festplattensystem hervorrufen, während ggf. alternative Abfragestrategien im Speicher des SQL Servers abgearbeitet werden können, so bspw. wenn stattdessen ein geeigneter Index eingelesen werden kann.
- Variante – Window Spool: Ebenfalls als logische Typen Eager bzw. Lazy Spool verfügbar und v. a. ab Windows 2012 Server mit seinen erweiterten Window-Funktionen. Der Operator speichert Ergebnisse von Window-Funktionen in der Tempdb, wobei diese alternativ auch im Speicher gehalten werden können. Der Operator speichert sich hierbei die für die Ermittlung des Ergebnisses einer Window-Funktion benötigten Eingabezeilen entsprechend der Window-Definition für jede Ausgabezeile.Window-Funktionen sind in gewissem Sinne für multidimensionale Vorgänge auf relationaler Basis bei typisch betriebswirtschaftlichen Fragestellungen geeignet. Es wird mittels Window-Funktion über eine Menge von Zeilen bspw. pro Zeile ein Ranking, Summe, Aggregat, Lag, Lead usw. ermittelt. Entsprechende Abfragen können auch klassisch mit Group by, Subqueries und Joins etc. erreicht werden, jedoch ist dann ein wiederholtes Ermitteln der Ergebnisse nötig, da die speziellen Window Spools nicht eingesetzt werden.
 Nonclustered) Index Spool: Fügt Zeilen entsprechend eines Suchprädikats in eine temporäre Tabelle ein und indiziert diese.
Nonclustered) Index Spool: Fügt Zeilen entsprechend eines Suchprädikats in eine temporäre Tabelle ein und indiziert diese.
- Arbeitsweise: Der Index-Spool-Operator beinhaltet ein Suchprädikat „SEEK:()” in der Suchspalte. Hierbei untersucht („scannt“) dieser seine Eingabezeilen entsprechend dem Prädikat und fügt eine Kopie jeder Zeile in eine versteckte Tabelle der Tempdb ein. Hierbei wird ein nicht-gruppierter Index auf diesen Zeilen angelegt. Es steht dann eine Tabelle zur Verfügung, auf der eine Indexsuche durchgeführt werden kann, bei der entsprechend dem Suchprädikat die benötigten Zeilen zurückgegeben werden können.
- Tuning: Index Spools können ein Hinweis auf nicht optimal definierte oder fehlende Indizes sein. Es gibt jedoch Situationen, in denen dieser Vorgang ruhig bestehen bleiben kann, bspw. wenn aufgrund bereits indizierter Spalten mittels SUM-Operator Summen in großer Menge gebildet werden. Diese indiziert SQL Server dann selbständig zur weiteren Verwendung. Solche Werte stattdessen von vorneherein in indizierter Form anzubieten ist ggf. nicht einfach zu erreichen und auch nicht unbedingt effektiv bereitstellbar.
Die von SQL Server temporär indizierten Daten sind v. a. effektiv verwendbar bei wiederholten Leseoperationen in Schleifen (Joins).
Join-Operatoren
Aus logischer Sicht sind Joins Verknüpfungen zweier Eingabequellen, also von Tabellen und/oder Sichten. Im Abfrageplan finden sich drei verschiedene physikalische Join-Operatoren, die je nach Situation nach einer anderen Strategie arbeiten.
Für die beiden Eingabequellen eines Joins wird von einer äußeren und einer inneren Eingabe gesprochen. Ein Join-Operator besitzt somit logischerweise immer zwei Eingabequellen. Die beiden Eingabequellen eines Join-Operators sind rechts davon angeordnet. Die obere Eingabequelle ist somit die äußere Eingabe, die untere Eingabequelle entspricht der inneren Eingabequelle.
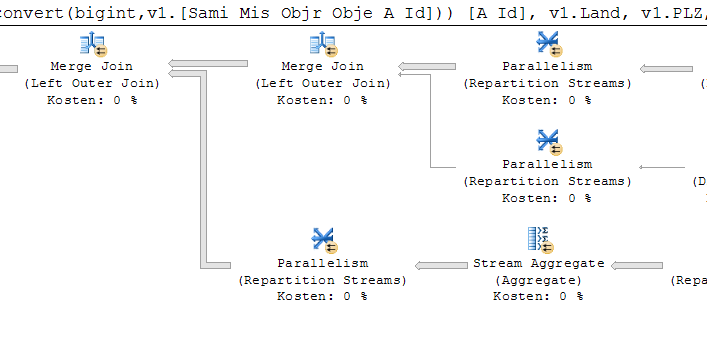
Abb. 2: der Merge Join ganz links besitzt eine äußere Eingabequelle, deren Eingabezeilen das Resultat eines weiteren Merge Joins sind. Die innere Eingabequelle ist das Resultat eines Repartition-Operators. SQL Server entscheidet selbst, welches die äußere oder innere Eingabe ist und dreht Join-Bedingungen gegenüber der Formulierung im SQL-Statement durchaus um.
 Nested Loop Join: Arbeitet am getreuesten nach dem Prinzip einer doppelten Schleife.
Nested Loop Join: Arbeitet am getreuesten nach dem Prinzip einer doppelten Schleife.
- Arbeitsweise: Für jede einzelne Zeile der äußeren Eingabequelle wird jede Zeile der inneren Eingabequelle entsprechend der Join-Bedingung untersucht. Die äußere Eingabe wird hierbei einmal komplett gescannt, d. h. eingelesen. Die innere Eingabe wird dann für jede äußere Eingabezeile gescannt. Sind Indizes vorhanden, kann diese Vorgehensweise recht effizient ausgeführt werden, v. a. für die innere Eingabe. Ist eine 1:1-Verknüpfung zwischen den Tabellen vorhanden (bspw. mittels Schlüsselbeziehung), kann beim Finden der ersten Zeile in der inneren Eingabe die innere Schleife abgebrochen werden.
Gelegentlich sortiert SQL Server die Eingaben zuvor, wenn er zum Schluss kommt, dass die Lokalität der gesuchten Daten durch die Sortierung nahe beieinanderliegt.
- Anwendung: Der SQL-Server-Optimierer bevorzugt diesen Join-Operator, wenn die äußere Eingabe relativ klein ist und die innere Eingabe für die am Join beteiligten Spalten bevorzugt Indizes aufweist, da die Eingabe dann bereits sortiert ist. Je größer der Größenunterschied zwischen äußerer und innerer Eingabe ist, umso effizienter arbeitet dieser Operator. Im Unterschied zum Merge Join werden Spalten aber nicht zwingend sortiert oder sortiert erwartet.
- Voraussetzungen: Im Grunde keine. Der Nested Loop Join-Operator setzt keinen Gleich-Join (Eqijoin) voraus, sondern ist sogar der einzige Join-Operator, der reine Gleich-Join / Ungleich-Joins bearbeiten kann! Unterstützt Inner, Outer und Cross Join, Cross und Outer Apply, Left Semi und Left Anti-Semi Join, aber kein Right und Full Outer Join, sowie Right Semi und Right Semi-Anti Join, wenn es sich um Ungleich-Joins handelt.
- Tuning: Wenn ein Nested Loop Join auftaucht, der mit sehr großen Eingabemengen hantiert, müsste SQL Server normalerweise auf andere Join-Typen ausweichen. Es können somit mehrere Probleme vorliegen: SQL Server nimmt die Anzahl der Eingabezeilen falsch an (veraltete/falsche Statistiken!) oder es liegt ein reiner Ungleich-Join vor, so dass SQL Server keine andere Strategie wählen kann. Ggf. steht aber auch nicht genügend Arbeitsspeicher für einen Merge- oder Hash Join zur Verfügung. Dann kann ein Speicherausbau hilfreich sein, evtl. hilft auch eine Tabellenpartitionierung.Nimmt SQL Server bspw. die Anzahl Eingabezeilen falsch an, kann auch versucht werden, einen vermutlich besseren Join-Typ zu erzwingen und die Abfragezeit zu vergleichen.
Beispiel zum Erzwingen eines Hash-Match-Joins:SELECT * FROM Table1 A -- kleinere Eingabequelle OUTER HASH JOIN Table2 B -- größere Eingabequelle
 Hash Match: Bildet aus den Zeilen der kleineren (äußeren) Eingabequelle Hashschlüssel und vergleicht diese mit auf gleicher Weise errechnetem Hashschlüssel der Zeilen der größeren (inneren) Eingabequelle.
Hash Match: Bildet aus den Zeilen der kleineren (äußeren) Eingabequelle Hashschlüssel und vergleicht diese mit auf gleicher Weise errechnetem Hashschlüssel der Zeilen der größeren (inneren) Eingabequelle.
- Arbeitsweise: Hashing bedeutet, dass für jede Eingabezeile des Hash-Operators aus dessen Inhalt ein repräsentativer Wert gebildet und in einer temporär existierenden Hashtabelle abgelegt wird. Das Suchen in Hashwerten ist schneller als in den eigentlichen Tabellenzeilen. Die Hashes werden dabei in gleich große Gruppen eingeteilt. Da der Hash Match bspw. einen Inner Join ausführt, wird die Hashtabelle für die Eingabeabfrage/Tabelle erstellt, von der aufgrund u. a. von Statistiken angenommen wird, dass diese die kleinere Anzahl Eingabezeilen liefert (Vorsicht vor veralteten Statistiken oder ungleich gefüllten Tabellen bspw. beim Übergang von Test- zu Produktivsystem!).Das HASH:() Prädikat zeigt die Liste der für die Ermittlung des Hashwertes herangezogenen Spalten.Nach dem Erstellen der Hashtabelle wird für jede Zeile der inneren Eingabe mit dem gleichen Hashalgorithmus ebenfalls deren Hashwert berechnet und geprüft, ob dieser in der Hashtabelle eine Übereinstimmung findet. Die Übereinstimmung wird dann noch daraufhin überprüft, ob ggf. ein Prädikat der Abfrage (angezeigt im Plan mittels RESIDUAL:()) zutrifft. Wenn mehrere Joins der gleichen Abfrage die gleiche(n) Join-Spalte(n) verwenden, gruppiert SQL Server diese in einem sogenannten Hash-Match-Team.Beim Hash Match Join werden vier Arten unterschieden, die von der Größe der Hashtabelle und dem verfügbaren Arbeitsspeicher abhängen, den SQL Server verwenden kann:
- „In Memory Join“: der Arbeitsspeicher reicht für die Hashtabelle aus.
- „Hybrid-Hash Join“: der verfügbare Arbeitsspeicher reicht nur knapp nicht aus. Es wird ein kleiner Überschuss in die Temdb transferiert, der größte Teil der Hashtabelle verbleibt weiterhin im Speicher.
- „Grace Join“: der Arbeitsspeicher reicht deutlich nicht aus, die Speicherung der Hashtabelle erfolgt daher komplett in der Tempdb.
- „Rekursive Join“: der Arbeitsspeicher reicht deutlich nicht aus und der Join-Vorgang ist so exzessiv, dass auch in der Tempdb Vorgänge in Teile zerlegt (partitioniert) werden müssen.
- Anwendung: Der Hash Match wird gerne bei umfangreicheren parallelisierbaren Joins eingesetzt, da sich dieser gut skalieren lässt, kann aber durchaus bereits bei einer scheinbar einfachen Distinct-/Union- oder Aggregate-Abfrage (bspw. Sum) auftauchen, da diese Operatoren eine Sortierung der Eingabezeilen und/oder Entfernung von Duplikaten erfordern, die recht teuer sein kann. Der Hash Match wird bevorzugt bei Joins, bei denen die äußere Eingabequelle signifikant weniger Zeilen beinhaltet als die innere Eingabequelle, die beteiligten Eingabequellen jedoch allgemein einen großen Umfang besitzen. Zudem wird der Operator auch bevorzugt, wenn Joins mit großen Abfragen keine sortierten Ausgabezeilen erfordern und keine in Bezug auf die Join-Prädikate sortierten Eingabezeilen.
- Voraussetzungen: SQL Server muss sicherstellen, für den Hash Match Join genügend verfügbaren Speicher garantiert zu bekommen. Die kleinere Eingabequelle muss in den Arbeitsspeicher passen. Wenn der Arbeitsspeicher für die Hashtabelle nicht ausreicht, wird die Tempdb (mit)benutzt, was exzessive I/O-Vorgänge nach sich zieht. Auch hier kann sich der Optimierer deutlich verschätzen, wenn zu wenige Eingabezeilen angenommen werden.
Der Hash Match setzt das Vorhandensein mindestens eines Gleich-Joins (equijoin) voraus. Somit ist sein Algorithmus nicht auf reine Ungleich-Joins anwendbar.Da der Hash Match auch mit einer größeren Anzahl unsortierter Eingabezeilen umgehen kann, kann dies ein Hinweis auf fehlende Indizes sein, da diese normalerweise eine Sortierung vorgeben, für die stattdessen der Merge-Join-Operator effizienter wäre. - Tuning: Beim Auftreten des Hash-Match-Operators ist zu prüfen, ob nicht eine effizientere Join-Methode in Frage käme. Ein Hinweis sind Annahmen bzgl. der Anzahl der Eingabezeilen der beteiligten vorgelagerten Operatoren, bei denen sich der Optimierer bspw. aufgrund falsch ermittelter Statistiken irren kann.
 Merge Join: Arbeitet mit wechselseitiger Verknüpfung und Vergleich sortierter Eingabequellen.
Merge Join: Arbeitet mit wechselseitiger Verknüpfung und Vergleich sortierter Eingabequellen.
Arbeitsweise: Der Merge Join arbeitet mit bereits sortierten Eingabezeilen. Entweder werden daher die Eingabequellen nach der Verknüpfungsspalte vorsortiert oder aber stammen aus einem Index.
Im Detail wird zunächst eine Zeile jeder Eingabequelle entsprechend den Join-Prädikaten miteinander verglichen. Bspw. wird bei einem Inner Join das Verknüpfungsergebnis zurückgegeben, wenn beide Eingabezeilen bzgl. der Join-Bedingung gleich sind. Dafür wird die zweite Eingabezeile solange durchsucht, bis der verglichene Wert der Eingabezeile in der Sortierreihenfolge von der Rangfolge her gleich oder höher steht. Solange gleiche Werte auftauchen, werden Resultate zurückgegeben, bis ein höherrangiger Wert ermittelt wird. Wird in der zweiten Eingabequelle kein Wert gefunden, wird die nächste Zeile der ersten Eingabequelle geholt.
Beim Left Join wird die Zeile der ersten Datenquelle beibehalten und ggf. Ausgabespalten der zweiten Eingabe mit NULL in die Resultatzeile aufgenommen. Im Falle eines Inner Joins wird auch die Zeile der ersten Datenquelle stattdessen komplett verworfen. Die Join-Operation wird dann mit der nächsten Zeile der ersten Eingabequelle fortgesetzt, der Vergleich mit der zweiten Eingabequelle setzt mit der Zeile fort, die zuletzt gelesen wurde.
Umfangreiche Resultatsets werden in der Tempdb zwischengespeichert. Das ist insbesondere dann der Fall, wenn die beiden sortierten Listen Mehrfacheinträge enthalten dürfen, also nicht Unique sind.

Obenstehende Tabelle veranschaulicht die Arbeitsweise des Merge Joins:
- Blaue Pfeile: Als Wert der nächsten Zeile der sortierten Eingabequelle wird der Wert 15678 gefunden. Die Suche durch die Eingabezeilen der zweiten Eingabequelle wird solange fortgeführt, bis entweder ein gleicher Wert in der zweiten Eingabequelle gefunden wird oder ein größerer Wert. Im Beispiel wird die Eingabezeile 15678 der zweiten Eingabe zu einem Resultat führen. Der nachfolgende Wert 15679 ist höherranging und führt zum Abbruch der Suche für den Wert 15678.
- Rote Pfeile: Danach wird mit der nächsten Eingabezeile der ersten Quelle fortgesetzt, hier der Wert 15679, markiert durch die roten Pfeile. Dieser wird ebenfalls in der zweiten Eingabequelle gefunden, in diesem Fall gleich zweimal, was zwei Ergebniszeilen hervorbringt, da der nachfolgende Wert 15684 zum Abbruch führt.
Erst wieder für den Wert 15684 wird ein übereinstimmendes Ergebnis ermitteln. Da SQL Server vorher schon weiß, dass der anstehende Vergleichswert der zweiten Eingabe bereits höherwertig ist als der folgende Wert 15682 der ersten Eingabe, kann ohne Vergleichsversuch die erste Eingabe solange durchlaufen werden, bis dort ein gleicher oder höherrangiger Wert gefunden wird.
Wann immer Duplikate in einer der Eingabequellen vorhanden sind, müssen alle gleichwertigen Zeilen der zweiten Eingabe nochmals durchlaufen werden, d. h. es wird nochmals bis zum unmittelbar davorliegenden rangniedrigeren Wert zurückgesetzt und die gleichrangigen gefundenen Zeilen durchlaufen. One-to-many oder Many-to-Many Merge Joins können im Ausführungsplan in den Eigenschaften des Operators erkannt werden anhand des MERGE:() Prädikats der Argumentliste des Operators.
Das Ergebnis einer Merge-Join-Verknüpfung wird nach dem Verknüpfungsattribut sortiert weitergegeben.
- Anwendung: Der Merge Join ist im Grunde die effizienteste Join-Art, v. a. bei größeren Eingabequellen. Der Optimierer wird diesen bei umfangreicheren Join-Operationen verwenden, v. a., wenn die beiden Eingabequellen sortiert sind. Sind diese nicht sortiert, wird abgewägt, ob eine Vorsortierung noch immer kostengünstiger wäre als der Einsatz eines Hash-Matches, der jedoch zusätzlichen Speicher und Operationen für die Erzeugung einer Hashtabelle benötigt. Ist für einen Hash Match nicht genügend garantierter Speicher in der Tempdb für die Hashtabelle vorhanden, kann dieser nicht ausgeführt werden. Der Optimierer wird versuchen, auf den Merge Join zurückzugreifen.
- Voraussetzungen: Der Merge Join erfordert, dass beide Eingabequellen in sortierter Form im Arbeitsspeicher liegen. Reicht dieser nicht aus, wird ein Hash Match ausgeführt, da dort nur die kleinere Eingabequelle im Speicher liegen muss. Für sehr umfangreiche Operationen ist es also daher wahrscheinlich, dass SQL Server dennoch auf den Hash Match Join ausweicht, es sei denn, die Voraussetzungen für den Hash Match sind ebenfalls nicht erfüllt, wodurch dann der Nested Loop Join zur Anwendung kommt.
Reine Ungleichheitsbedingungen (bspw. a.date <> b.date) können von diesem Join-Typ nicht erfüllt werden. Der Merge Join benötigt daher mindestens eine Gleichheitsbedingung, ansonsten wäre eine Navigation in sortierten Listen wenig effizient.
Der Merge-Join-Operator steht für Inner Join, Left Outer Join, Left Semi Join, Left Anti Semi Join, Right Outer Join, Right Semi Join, Right Anti Semi Join, und Union Logical Operationen zur Verfügung. Nähere Informationen finden Sie in folgenden Dokumente:
-
- http://support.microsoft.com/kb/197297/de
- http://technet.microsoft.com/en-us/library/ms175913%28v=sql.105%29.aspx
- Tuning: Wird im Abfrageplan ein Merge Join mit vorangestelltem Sortieroperator gefunden, sollte geprüft werden, ob für die Spalten, die der Sortierung unterliegen, nicht besser von vornherein ein Index angelegt wird. Ggf. muss auch geprüft werden, ob eine umgekehrte Sortierung einzelner Indexspalten bzw. deren Reihenfolge im Index hilfreich wäre.
Fehlerhafte Statistiken können zu einer unnötigen Merge-Join-Verwendung mit evtl. unnötiger zeitraubender Vorsortierung führen, die bei kleineren Tabellen mittels Nested Loop Join effizienter abgearbeitet werden können.
Sind jedoch größere sortierte Eingabequellen vorhanden ohne dass SQL Server den Merge Join einsetzt, sollte der verfügbare Speicher geprüft werden. Eine solch ungünstige Konstellation sollte auf jeden Fall gefunden werden, bspw. anhand exzessiver I/O-Aktivitäten der Operation, da die Ausführungszeiten eines Joins sich deutlich verlängern, wenn SQL Server nicht den optimalen Join-Typ einsetzen kann.
Zu beachten ist sowohl beim Merge Join als auch beim Hash Match, dass für das Laden der Eingabequellen in den Arbeitsspeicher (beim Hash Match zumindest der kleineren Tabelle) dieser durch physikalisches RAM abgedeckt ist. Bietet Windows Speicher über den virtuellen Speicher (Swapfile) an, kann dies zu massiver Performanceverschlechterung führen. Der Arbeitsspeicher der eingesetzten Hardware sollte ggf. erhöht und Windows so konfiguriert werden, dass SQL Server Arbeitsspeicherseiten exklusiv sperren kann.
Im Zusammenhang mit Join-Operatoren spielt der Compute-Skalar-Operator eine wichtige Rolle:
 Compute Skalar: Der Operator wertet einen Ausdruck aus und erstellt einen berechneten skalaren Wert.
Compute Skalar: Der Operator wertet einen Ausdruck aus und erstellt einen berechneten skalaren Wert.
- Arbeitsweise: Der Ergebniswert des Skalaroperators dient der direkten Rückgabe an den Benutzer oder wird an anderer Stelle in der Abfrage ausgewertet. Ein Beispiel für beide Fälle ist ein Filterprädikat oder Join-Prädikat (bspw. Skalarfunktionen, wie die isnull-Abfrage).
- Tuning: Taucht der Operator vor einem Join-Operator auf, ist Vorsicht geboten. Der SQL-Code sollte genau untersucht werden, da offenbar als Join-Prädikat das Ergebnis einer Skalaroperation (bspw. Skalarfunktion) verwendet wird. Dies kann ein Hinweis darauf sein, dass SQL Server nachfolgende Joins ohne Indexverwendung ausführen muss, da der Skalaroperator eine effektive Indexverwendung verhindert und/oder SQL Server zwingt, auf einen suboptimalen Join-Typ zurückzugreifen.
