Große Datenmodelle bedürfen oft sehr langer Aufbereitungszeiten. Täglich müssen neue Daten eingelesen und verarbeitet werden. Da bei einem standardmäßig aufgesetzten Aufbereitungsprozess täglich alle Daten immer wieder neu verarbeitet werden, kann es passieren, dass das zur Verfügung stehende Zeitfenster für die Verarbeitung der Daten nicht mehr ausreicht und so evtl. andere Prozesse gestört werden oder wichtige Daten nicht rechtzeitig zur Verfügung stehen. Durch die Verwendung von Partitionen ist es möglich, diesen Verarbeitungsprozess stark zu verkürzen. Dabei werden die Daten nach Zeitscheiben (i. d. R. Jahre) getrennt in verschiedenen Tabellen abgelegt. Damit besteht die Möglichkeit bei der täglichen Verarbeitung nur noch die Partitionen aufzubereiten, bei denen sich tatsächlich etwas geändert hat bzw. in die neue Daten eingefügt wurden.
Voraussetzung
Voraussetzung für die Verwendung von Partitionen, welche jeweils Daten für ein Jahr enthalten sollen, ist, dass pro Partition eine Quelle mit den entsprechenden Daten angegeben wird. Dies kann über Sichten erreicht werden bei denen im Where-Statement auf das jeweilige Jahr eingeschränkt wird. Um eine optimale Performance beim Befüllen des Datenmodells zu erreichen, ist es jedoch empfehlenswert, die Quelltabellen schon physisch nach Jahren getrennt zur Verfügung zu stellen. An den Namen der Tabelle hängt man als Postfix das Jahr der enthaltenen Daten. Eine Tabelle, welche die Daten für das Jahr 2009 enthält, könnte zum Beispiel T_Import_Fact_2009 genannt werden.
Konfiguration in der Modeler-Eingabeanwendung
Um mit DeltaMaster Modeler ein Modell zu erstellen, welches Partitionen enthalten soll, müssen folgende Einstellungen in der Modeler-Eingabeanwendung vorgenommen werden.
Measuregroups
Bei der Definition der Measuregroups muss für alle Measuregroups, die Partitionen enthalten sollen, im Bericht „MeasureGroups“ in der Spalte „Partition per SrcTab“ der Eintrag „Yes“ gewählt werden. Dieser Eintrag bewirkt, dass bei der Erstellung des Datenmodells pro angegebener Quelle eine Faktentabelle erzeugt wird.

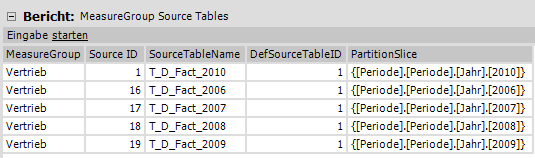
MeasureGroup Source Tables
Bei der Anlage der Measuregroupsourcetables muss im Bericht „MeasureGroup Source Tables“ pro Partition eine Zeile erstellt und im Feld „SourceTableName“ der Name der entsprechenden Quelltabelle ausgewählt werden. Der erste Eintrag spiegelt immer die Partition des aktuellen Jahres wieder. Alle folgenden Einträge werden in aufsteigender Reihenfolge, beginnend bei der Partition mit den ältesten Daten, erstellt. Als „Source ID“ wird für die Partition in der ersten Zeile die ID 1 gewählt werden. Für die Partitionen, welche die Daten der vergangen Jahre enthalten und nicht immer wieder neu aufbereitet werden sollen, sollte als ID das Jahr plus 10 gewählt werden. Für das Jahr 2009 würde die ID entsprechend 19 lauten. Dies ist wichtig, um bei der Befüllung des Datenmodells die Measuregroups ab einer fest zu definierenden ID auszuschließen.
In der Spalte „DefSourceTableID“ wird auf die ID der ersten Partition verwiesen. Hierdurch werden alle Konfigurationen der ersten Partition automatisch übernommen.
In der Spalte „PartitionSlice“ sollte per Freitexteingabe ein MDX-Set definiert werden, welches MDX-Abfragen einen Hinweis auf die Daten der entsprechenden Partition gibt. Fehlt diese Angabe, müssen bei jeder Abfrage zunächst alle Partitionen abgefragt werden, um die Partition zu finden, welche die Daten des gesuchten Jahres enthält.
Model Create und Transform All
Bei der Erstellung des Modells mit Modeler über der Funktion „Create Snowflake Schema“ wurden folgende Faktentabellen erzeugt:
T_FACT_01_Vertrieb_01 = Fakten des aktuellen Jahres 2010
T_FACT_01_Vertrieb_16 = Fakten des Jahres 2006
T_FACT_01_Vertrieb_17 = Fakten des Jahres 2007
T_FACT_01_Vertrieb_18 = Fakten des Jahres 2008
T_FACT_01_Vertrieb_19 = Fakten des Jahres 2009
Die fortlaufende Nummer entspricht dem zweistelligen Jahr plus 10, z. B. für das Jahr 2006: 06 +10 = 16. Die Nummer 01 entspricht immer dem aktuellen Jahr.
Bei der Ausführung des „Transform All“ werden die einzelnen Faktentabellen nun mit den Daten des entsprechenden Jahres befüllt.
Anpassungen am Metadatenmodell
P_Transform_10_DeleteFactTables
Da bei jeder Aufbereitung der Daten über die Funktion „Transform All“ alle Fakten- und Dimensionstabellen über den Befehl „truncate table“ geleert werden, muss die Prozedur „P_Transform_10_DeleteFactTables“ händisch angepasst werden. Für alle Partitionen, welche nicht ständig neu aufbereitet werden sollen, wird der Truncate-Befehl auskommentiert oder aus der Prozedur entfernt. Damit bleiben die einmal importierten Daten in den Tabellen enthalten.
ALTER Proc [dbo].[P_Transform_10_DeleteFactTables] as truncate Table [T_FACT_01_Vertrieb_01] -- truncate Table [T_FACT_01_Vertrieb_16] -- truncate Table [T_FACT_01_Vertrieb_17] -- truncate Table [T_FACT_01_Vertrieb_18] -- truncate Table [T_FACT_01_Vertrieb_19]
Wichtig: Da bei der Ausführung von „Create Snowflake Schema“ im Modeler die Prozedur „P_Transform_10_DeleteFactTables“ neu erzeugt wird, muss sie danach immer erneut angepasst werden.
P_Transform_13_P_Facts_Ausführen
Damit die Daten bei der Ausführung von „Transform All“ nicht mehrfach in die Partitionsfaktentabellen importiert werden, muss zusätzlich die Prozedur „P_Transform_13_P_Facts_Ausführen“ überarbeitet werden. Es muss sicher gestellt werden, dass nur die Partitionen mit einer ID < 16 befüllt werden, es sei denn die entsprechende Partition enthält noch keine Daten. Damit werden nach dem Ausführen von „Create Snowflake Schema“ in Modeler und dem damit verbundenen Löschen und Neuerzeugen der Faktentabellen auch diese Partitionen wieder neu befüllt. Der folgende T-SQL-Code zeigt den Teil der Prozedur, der dies bewerkstelligt.
…
-- Start Anpassung für Partitionierung
Declare @RowCount bigint
declare @Source_Table_Name varchar(100)
declare @sql varchar(1000)
SELECT @FactID = FactID FROM dbo.F_SYSLOG_GetIDsByFactProcName(@sp_name)
SELECT @SourceTabID = SourceTableID FROM dbo.F_SYSLOG_GetIDsByFactProcName(@sp_name)
if @SourceTabID > 15
Begin
select @Source_Table_Name = 'T_FACT_' + RIGHT('0' +
convert(varchar(2),a.FactID),2) + '_' +
b.FactName + '_' + RIGHT('0' +
convert(varchar(2),a.SourceTableID),2)
from
dbo.T_Model_Fact_SourceTable a
left join
dbo.T_Model_Facts b
on a.FactID = b.FactID
where
a.FactID = @FactID and
a.SourceTableID = @SourceTabID
set @sql = 'select top 1 * from ' + @Source_Table_Name
exec (@sql)
select @RowCount = @@ROWCOUNT
End
if @SourceTabID <= 15 or (@SourceTabID > 15 and @RowCount = 0)
-- Ende Anpassung für Partitionierung
…
Erweiterung der Prozedur P_Transform_All
Da wie oben bereits erwähnt, bei jeder Ausführung der Transformation zuerst die Fakten- und danach die Dimensionstabellen geleert werden, ist es notwendig, die Schlüsselbeziehungen (Constraints) zwischen den nicht zu leerenden Partitionsfaktentabellen und den Dimensionstabellen temporär zu entfernen. Wird dies nicht getan, können die Dimensionstabellen nicht erfolgreich geleert werden. Dafür kann man sich zweier Prozeduren bedienen, welche seit der Modeler-Version 209 beim Anlegen des Metadatenmodells automatisch erzeugt werden.
Mit der Prozedur „P_BC_Drop_FKConstraint” werden die Constraints der Faktentabellen gelöscht, welche nicht neu befüllt werden sollen.
Nach der erfolgreichen Befüllung aller Dimensionstabellen werden mit der Prozedur „P_BC_Create_FKConstraint“ die Constraints der Faktentabellen neu erstellt.
Anschließend werden die leeren Faktentabellen befüllt.
Die Aufrufe zum Löschen und Neusetzen der Constraints integriert man in die Prozedur „P_Transform_All“.
ALTER proc [dbo].[P_Transform_All] as -- Log einschalten exec dbo.P_SYSLOG_StartTransformation exec dbo.P_SYSLOG_Reset -- Constraints löschen exec P_SYSLOG_Exec 'P_BC_Drop_FKConstraint' -- Löschen Dims und Facts exec P_SYSLOG_Exec 'dbo.P_Transform_10_DeleteFactTables' exec P_SYSLOG_Exec 'dbo.P_Transform_11_DeleteDimTables' -- Füllen Dims exec P_SYSLOG_Exec 'dbo.P_Transform_12_P_DIMs_Ausfhren' -- Constraints neu setzen exec P_SYSLOG_Exec 'P_BC_Create_FKConstraint' -- Füllen Facts exec P_SYSLOG_Exec 'dbo.P_Transform_13_P_FACTs_Ausfhren' exec P_SYSLOG_Exec 'dbo.P_Transform_14_P_ELEMDEL_Ausfuehren' -- Log ausschalten exec dbo.P_SYSLOG_StopTransformation
Alternativ kann auch ein Update der Dimensionstabellen vorgenommen werden. Diese Funktion wird im Modeler pro Hierarchieebene im Bericht „Level Source Columns“ über die Spalte „Insert update“ aktiviert und bewirkt, dass neue Elemente aus den Stammdatentabellen in die Dimension eingefügt bzw. an die entsprechende Stelle umgehängt werden. Ein Nachteil dieser Vorgehensweise ist, dass man beim Befüllen der Dimensionstabellen keinen Hinweis bekommt, wenn Elemente mit doppelten Schlüsseln vorhanden sind, da vorhandene Elemente einfach überschrieben werden.
Im folgenden Screenshot ist zu sehen, dass nach der Durchführung dieser Anpassungen und dem erneuten Ausführen der Transformation nur noch die Partition mit der ID 1 neu befüllt wird.
![]()
Einstellungen auf der OLAP-Datenbank
Beim Erzeugen der OLAP-Datenbank über den Punkt „Deploy and Process Cube“ in Modeler wurden ebenfalls Partitionen in den gewählten Measuregroups angelegt und mit den entsprechenden Partitionsfaktentabellen verknüpft.
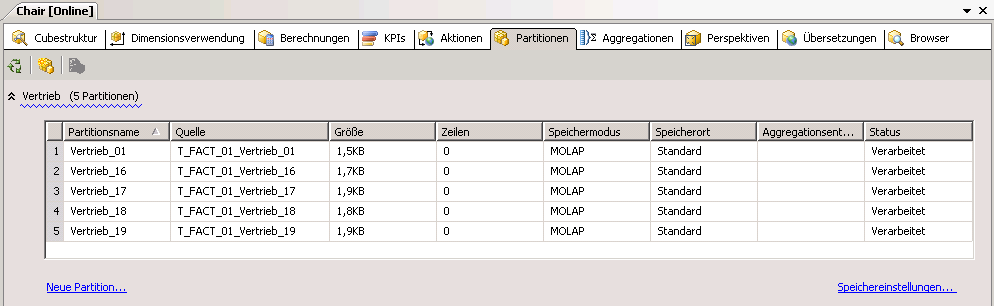
Somit ist es auch bei der Befüllung der OLAP-Datenbank möglich, nur noch die Partitionen aufzubereiten in deren Faktentabellen neue Daten importiert wurden.
Erfahrungen haben gezeigt, dass selbst bei der kompletten Aufbereitung der OLAP-Datenbank erheblich Zeit eingespart werden kann, da die Partitionen parallel verarbeitet werden.
