Uuuund Action! Wie im ersten Teil dieses Blogthemas beschrieben, schauen wir uns heute die vorbereiteten partitionierten Tabellen in Aktion an. Im ersten Teil haben wir im SQL Server die notwendigen Partitionierungsobjekte angelegt und diese bereits auf eine Faktentabelle angewendet. Im zweiten Teil versuchen wir jetzt, neue Daten in die Faktentabelle zu importieren. Dies geschieht nicht wie sonst üblich per DELETE und INSERT, sondern mit einem sogenannten „Partition Swap“. Der vorliegende Artikel zeigt die notwendige Syntax, beleuchtet die Restriktionen und zeigt wie viel Optimierung die Partitionierung wirklich bringt.
Wie war das nochmal?
Werfen wir zunächst nochmal einen kleinen Blick zurück auf den ersten Teil und die dort durchgeführten Schritte. Wir hatten damals die Erstellung der Partitionierungsobjekte in folgende Einzelschritte zerlegt:
- Erstellung der Partitionierungsfunktion (mit Definition der Blockgrenzen)
- Erstellung eines Partitionsschemas (mit Zuordnung der Partitionen zu(r) Dateigruppe(n))
- Anwenden des Partitionsschemas auf die Tabelle(n)
Dabei haben wir in Schritt eins eine links-basierte, horizontale Partitionierung über Monate gewählt und eine zugehörige Partitionierungsfunktion eingerichtet. Im Zuge der sprachlichen Konsistenz habe ich für den zweiten Teil alle Funktionen und Objekte von „Umsatz“ bzw. „Menge“ in „Turnover“ bzw. „Quantity“ umbenannt. Die geänderten Skripte sind wieder über einen Link am Ende des Artikels herunterzuladen.
Weiterhin haben wir in Teil eins ein einfaches Partitionierungsschema erstellt und die Funktion unserer einen existierenden Dateigruppe zugewiesen. Wir wissen längst: hätten wir die Partitionen auf mehrere Dateigruppen aufgeteilt, hätten wir die Performance durch die parallele Nutzung mehrerer Prozessoren noch weiter optimieren können. Aus Gründen der Vereinfachung verzichten wir jedoch für diesen Test auf die Aufteilung.
Der dritte Schritt war schließlich die Anwendung des Partitionierungsschemas auf die entsprechende Tabelle. Dabei wird einfach das CREATE TABLE Statement um eine Zeile erweitert und die Spalte definiert, über die partitioniert werden soll. Auch hier haben wir uns natürlich gemerkt: der Datentyp der Tabellenspalte muss dem verwendeten Datentyp in der Partitionierungsfunktion entsprechen.
Neben der erwähnten Umbenennung haben wir für den zweiten Teil noch ein paar Änderungen vorgenommen. Um den Speicher und die Laufzeiten noch etwas zu quälen, haben wir die beiden Dimensionsspalten „Customer“ und „Product“ von varchar in nvarchar verändert, außerdem noch eine Dimension „Company“ sowie „SalesRep“ ergänzt. Schließlich wollen wir ein möglichst langsames Laufzeitverhalten beim normalen DELETE & INSERT beobachten können und dann den „Partition Swap“ daneben halten.
Klappe 1 die Erste
Wie geht es nun weiter? Wie bereits im ersten Teil beschrieben, wollen wir nun Daten eines neuen Monats in die Faktentabelle importieren und den ältesten Monat entfernen. Nachfolgende Darstellung soll dies erneut verdeutlichen:
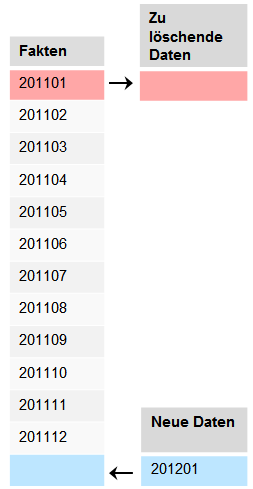
Bei der Nutzung von „normalen“ Bordmitteln würde man dies über einfach DELETE- und INSERT Statements bewerkstelligen.
Bei Anwendung der Partitionierung nutzt man den schon mehrfach erwähnten „Partition Swap“. Hierbei müssen für die zu verändernden Partitionen strukturidentische Tabellen zu der eigentlichen Faktentabelle erstellt werden, die quasi die neuen Daten für die Partitionen enthalten. Der mitdenkende Leser wird nun einwenden: neu, wir wollen doch unter anderem Daten löschen? Richtig, die neue Partitionstabelle wird in dem Fall einfach strukturidentisch, aber leer erstellt. Anschließend wird die gefüllte Partition der „normalen“ Faktentabelle, in unserem Fall also die Daten von Januar 2011, durch die leere Partition der neuen Tabelle ersetzt. Im Falle der neuen Daten geschieht dies genau anders herum. Dort wird zunächst eine neue, leere Partition in der „normalen“ Faktentabelle geschaffen und diese dann durch die strukturidentische, gefüllte Neutabelle ersetzt. Das vorher gezeigte Schema ist durch die zwei neuen notwendigen Tabellennamen erweitert:
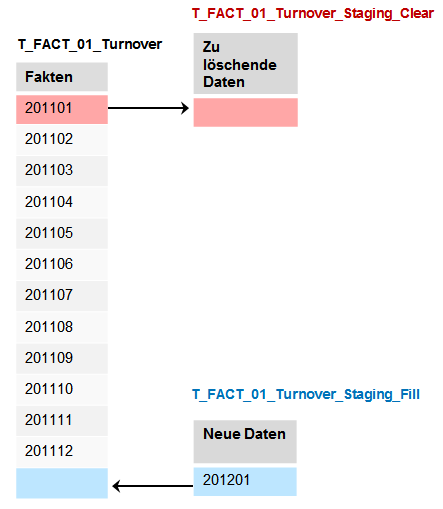
Folglich wurden die Skripte zur Tabellenerzeugung um zwei Tabellen erweitert.
Die Tabelle für die neuen Daten aus Januar 2012:
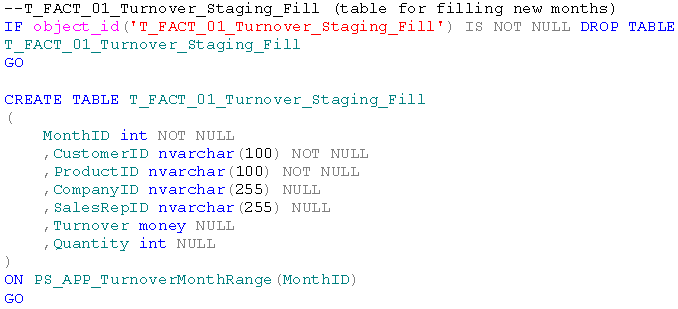
Hierbei ist wichtig, dass auf diese Tabelle auch das erstellte Partitionsschema angewendet wird. Nur so weiß der SQL-Server beim späteren Tausch der Partitionen, welche Partitionen der beiden Ta-bellen zueinander gehören.
Die (Dummy-)Tabelle zum Löschen der Daten muss dem Partitionsschema interessanterweise nicht zugeordnet werden, da diese ohnehin immer leer ist:
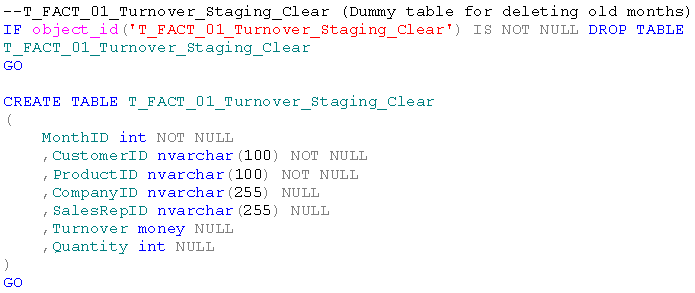
Wenn auch in unserem Fall unkritisch, ist es trotzdem für die Partitionierung essentiell, dass neben der korrekten Anwendung des Partitionsschemas alle Faktentabellen die gleichen Indexe und Schlüssel aufweisen. Andernfalls ist ein Tausch von Partitionen zwischen den Tabellen nicht mög-lich. Die Fremdschlüssel auf unserer neuen Ladetabelle erstellen wir nach der Befüllung mit den neuen Monatsdaten.
Weiterhin ist zu beachten, dass alle Staging-Tabellen in der gleichen Dateigruppe liegen müssen, wie ihr Partitionsziel, mit dem sie getauscht werden sollen.
Damit sind alle Vorbereitungen für das Datenladen getroffen.
Rock’n’Roll
Um einen ersten Überblick über die Partitionen zu erhalten und um die weiteren Datenbewegun-gen monitoren zu können, erweitern wir das Statement aus dem ersten Teil um die beiden neuen Tabellen:
Im Ergebnis sehen wir zunächst die gefüllte Haupttabelle mit den zwölf Partitionen sowie die (noch) leeren Staging-Tabellen:
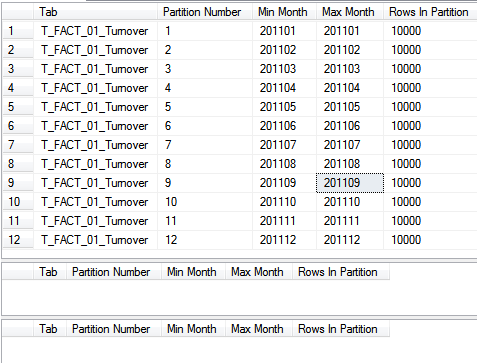
Nun löschen wir zunächst die Altdaten aus der Faktentabelle. Da alle Objekte bereits vorbereitet sind, ist das Vorgehen denkbar einfach. Wir können direkt den Tausch der Partitionen anwenden, dafür genügen wenige Zeilen SQL-Code:

In dem Statement verändern wir also die Tabelle T_FACT_01_Turnover in der Form, dass wir die Partition mit der ID 1 durch selbige aus der Tabelle T_FACT_01_Turnover_Staging_Clear austau-schen. Bereits in wenigen Millisekunden ist der Tausch vollzogen.
Prüft man nun den Inhalt der Tabellen, sieht man, dass der Tausch und damit das Löschen tatsäch-lich funktioniert haben. Die Daten des Januars 2011 stehen jetzt in unserer Staging-Tabelle. Die Faktentabelle enthält keine Daten für diesen Monat mehr:
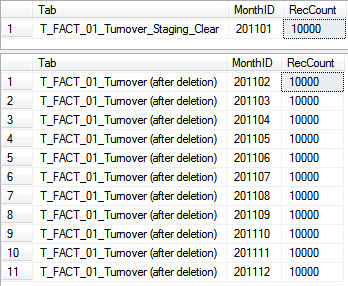
Die Partitionen haben sich nun ebenfalls geändert. Man sieht in der Faktentabelle wird keine Parti-tion mit der ID 1 mehr gezeigt. Dafür taucht diese nun in der Löschtabelle auf:
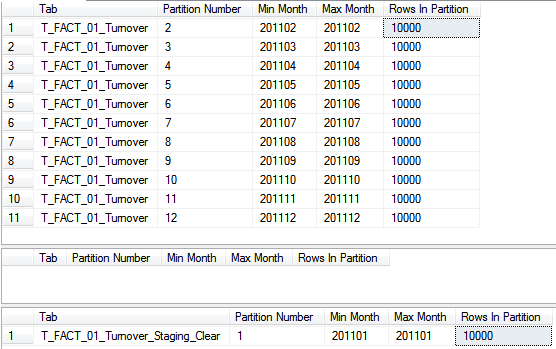
Wichtig zu verstehen ist allerdings, dass die Partition mit der ID 1 nach wie vor auch in der Fakten-tabelle existiert. Die Partitionen behalten also auch nach dem Switch ihre ID und existieren in den Tabellen weiter. Sie werden in den Prüfbefehlen nur nicht angezeigt, weil keine Datensätze in dieser Partition mehr existieren. Um das Löschen final abzuschließen, wird folglich empfohlen, diese erste leere Partition aus der Faktentabelle zu entfernen. Dies passiert über einen sogenannten „Partition Merge“, bei dem die Partitionierungsfunktion mit folgender Syntax angepasst wird:

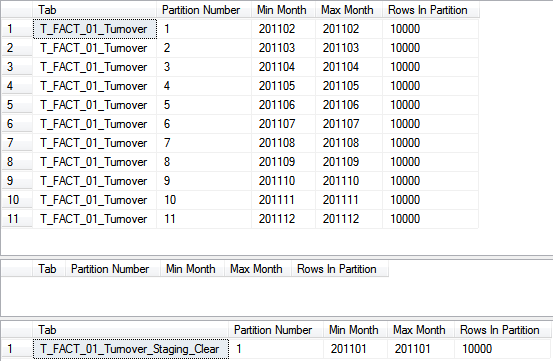
Durch die links-basierte Definition der Partitionierungsfunktion ist der „Merge“ wieder etwas abs-trakt von der Syntax her. Wir erinnern uns die erste Partition wurde mit dem Monat 201101 ange-geben, was so viel bedeutet hat wie alle Daten <= 201101 sollen in dieser Partition landen. Zum Löschen oder „Mergen“ (um im IT-ler-Deutsch zu bleiben) wird nun einfach selbige Grenze wieder angegeben, was dazu führt, dass diese Grenze entfernt und die Daten zu der nächsten Partition hinzugefügt werden. Die Partitionen 1 und 2 werden also zu einer einzigen zusammengefasst und erhalten die neue ID 1, alle anderen Partitions-IDs werden um eine Nummer reduziert. Jetzt existie-ren nur noch 11 Partitionen in der Faktentabelle:
Im nächsten Schritt fügen wird die neuen Daten des Monats Januar 2012 der Faktentabelle hinzu.
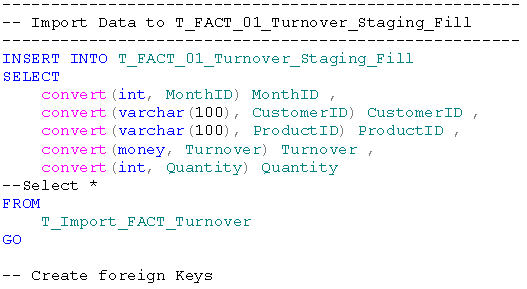
Dazu füllen wir zunächst unsere Ladetabelle T_FACT_01_Turnover_Staging_Fill mit den neuen Da-ten aus unserer Importtabelle T_Import_FACT_Turnover:

Anschließend begutachten wir die neue Verteilung der Partitionen:
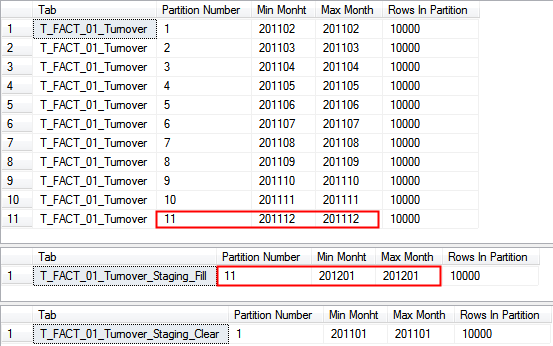
Hierbei sehen wir, dass die neuen Daten in der Partition mit der ID 11 landen, genau wie die Daten aus Dezember 2011. Dies verletzt einen wichtigen Grundsatz der Partitionierung. Bei einem „Partition Switch“ muss das Ziel, also die Partition, in welche die Daten verschoben werden, immer leer sein. Dies ist in dem Fall nicht gegeben. Beim Löschen war dies anders, da das Ziel die ohnehin leere Staging-Tabelle T_FACT_01_Turnover_Staging_Clear war. Jetzt verschieben wir die Daten allerdings anders herum, also von der Staging-Tabelle in die Faktentabelle.
Folglich müssen wir uns zuerst ein leeres Ziel schaffen und eine neue Partition in der Faktentabelle eröffnen. Auch hierzu verändern wir wieder die Partitionierungsfunktion, wenden diesmal allerdings einen sogenannten „Partition Split“ mit folgendem Befehl an:

Auch hier wird wieder die neue Grenze der links-basierten Partition mitgegeben. In dem Fall wird also die Partition 11 als > 201111 und <= 201112 definiert und eine neue zwölfte Partition geschaffen, welche alle Daten > 201112 enthält. Unsere Prüfstatements für die Partitionen verdeutlichen dies:
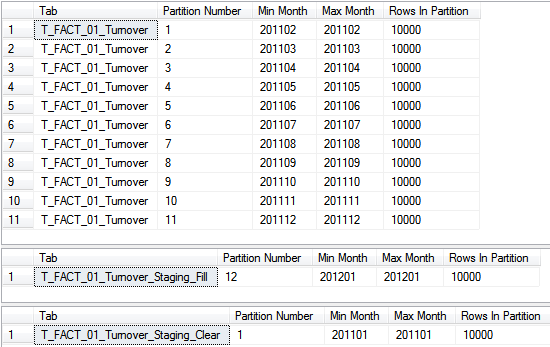
Nun haben wir mit der Partition 12 ein leeres Ziel in unserer Faktentabelle geschaffen und können genau wie vorhin den „Partition Switch“ durchführen. Achtung: diesmal verschieben wir von der Staging-Tabelle in die Faktentabelle. Daher wird der ALTER Befehl diesmal auf die Staging-Tabelle angewendet:
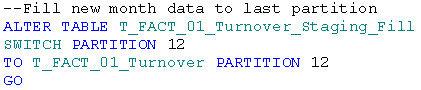
Im Gegensatz zum vorher durchgeführten Split, der bei der Arbeit mit Partitionen die längste Lauf-zeit in Kauf nimmt, ist dieser Switch in wenigen Millisekunden erledigt.
Der abschließende Blick auf unser Prüfstatement zeigt den Erfolg der Aktion:
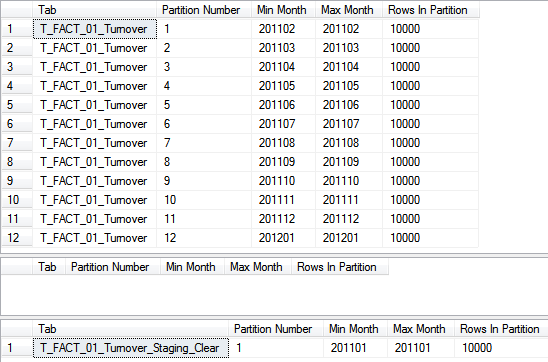
Wenn man den Prozess nun konsequent zu Ende denkt, fehlt eigentlich nur noch das echte Lö-schen der Altdaten. Dies kann mit einem einfachen TRUNCATE oder einem echten DROP der Ta-belle T_FACT_01_Turnover_Staging_Clear erledigt werden.
The Oscar goes to…
Nachdem wir nun den ganzen Zauber hinter uns gebracht haben, ist die Frage angebracht, was das alles eigentlich bringt?
Im Vergleich zum Vorgehen mit DELETE und INSERT zunächst mal deutlich mehr Komplexität. Würde man den „traditionellen“ Weg wählen, würde man zum Löschen lediglich folgenden Befehl absetzen müssen, wenn man das Löschen abhängig von dem Inhalt der neuen Daten durchführen würde (bei der Partitionierung können wir uns diesen Zugriff auf die Neudaten sparen, da wir wis-sen, dass die zu löschenden Daten immer komplett in unserer Partition 1 zu finden sind):

Die Unterschiede in der Laufzeit beim Löschen sind eklatant! Bei durchgeführten Tests mit einhun-derttausend Datensätzen pro Monat hat der „Partition Switch“ mit großem Abstand „gewonnen“. Dieser hat in unserer Testreihe im Schnitt 15 Millisekunden gedauert, wohingegen das Löschen per DELETE im Schnitt ca. 1100 Millisekunden in Anspruch genommen hat. Damit ist die Partitionie-rung beim Löschen knapp um den Faktor 73 schneller! Das ist definitiv Oscar-reif.
Bei einer Million Datensätze hat sich der Abstand etwas verringert aber mit Faktor 22 (2,5 Sekunden gegenüber 55 Sekunden) ist die Beschleunigung immer noch immens.
Beim Laden von neuen Daten würde man direkt auf die Importtabelle zugreifen und diese in die Faktentabelle schreiben. Der Befehl dafür würde folgendermaßen aussehen:
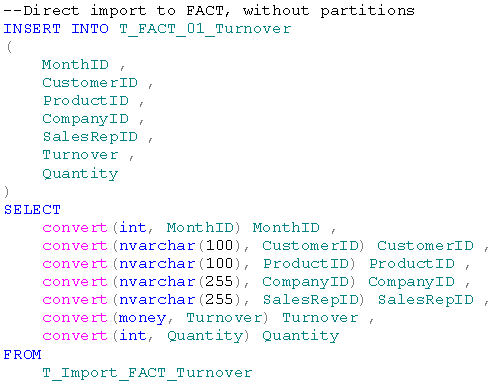
Dabei würde man nur einen einzigen Befehl ausführen, beim Partitionieren würde man drei Schrit-te benötigen. Die Laufzeitunterschiede sind hier allerdings deutlich geringer als beim Löschen beo-bachtet. Auch hier war der Testfall mit einhunderttausend Datensätzen die Referenz. Im Schnitt wurde dabei folgendes Ergebnis erzielt (aufgeschlüsselt nach Einzelschritten):

Der Beschleunigungsfaktor liegt hier also nur bei mageren 1,6. Bei großen Datenmengen mögen das auch schon die entscheidenden Minuten sein, allerdings kann man beim Löschen doch deutlich mehr herausholen.
Von daher kann man zusammenfassend feststellen, dass die Partitionierung von Tabellen in jedem Fall etwas bringt, wenn auch nicht in jedem Fall gleich viel.
Spannend könnte durchaus noch der Test mit den verteilten Dateigruppen sein. Aber wer weiß, vielleicht gibt es ja einen Teil 3?!
Uuuund CUT!
Material
Das Zusatzmaterial zum Download befindet sich auf der Blog-Seite.
