Dieser Blogbeitrag erläutert, wie bei der Erstellung eines Tabular-Modells mit Parent-Child-Hierarchien umzugehen ist. Anhand eines Beispiels zeigen wir, wie eine entsprechende Dimension erstellt wird und welche DAX-Funktionen hierfür benötigt werden.
Ausgangslage
Aktuell ist es in einem Datenmodell, das mit Microsoft Tabular erstellt wurde, nicht möglich, eine Parent-Child-Hierarchie zu erstellen, wie wir sie aus Microsoft Analysis Services kennen. Ob diese Funktion noch kommen wird, ist nach aktuellem Kenntnisstand nicht bekannt. In einem Tabular-Modell muss jede Hierarchie einer Dimension eine definierte Anzahl an Ebenen haben, wobei für jede Ebene eine Spalte in der Dimensionstabelle vorhanden sein muss. Es gibt aber die Möglichkeit, mittels DAX-Funktionen basierend auf einer Parent- und einer Child-Spalte eine reguläre Hierarchie zu modellieren.
Als Beispiel wird die AdventureWorks-Datenbank verwendet. Die Tabelle DimEmployee (Abbildung 1) enthält mit den Spalten EmployeeKey (ChildID) und ParentEmployeeKey (ParentID) alle Voraussetzungen für eine klassische Parent-Child-Hierarchie. Die Spalten FirstName und LastName werden im Tabular-Modell zur berechneten Spalte FullName zusammengefasst und als Bezeichnung verwendet.
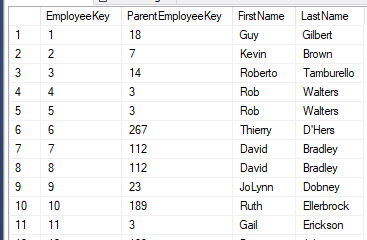
Abbildung 1: Auszug aus der Tabelle DimEmployee
Grundlegendes Wissen über die Modellierung eines Datenmodells mit Microsoft Tabular wird für diesen Blog vorausgesetzt.
Modellierung der Parent-Child-Hierarchie
Die Hierarchie einer jeden Dimension in einem Tabular-Modell muss eine fest definierte Anzahl an Ebenen haben. Damit basierend auf einer Child- und einer Parent-Spalte dennoch eine Hierarchie erstellt werden kann, werden zwei Hilfsspalten benötigt. Diese werden als berechnete Spalten im Visual Studio in der Dimensionstabelle angelegt.
In der ersten Hilfsspalte HierarchyPath (Abbildung 2) wird der Pfad vom obersten Parent-Element bis zum Element der jeweiligen Zeile ermittelt.
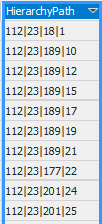
Abbildung 2: HierachyPath
Der erste Eintrag gibt die ID des obersten Parent-Elements an. Getrennt durch das Pipe-Symbol werden die nächsten IDs der Hierarchie angezeigt. Die letzte ID ist immer die ID des Elements der aktuellen Zeile.
Dieser Pfad lässt sich mit Hilfe der DAX-Funktion Path ermitteln. Die Syntax dieser Funktion ist:
PATH(<ID_ColumnName>, <ID_ParentColumnName>)
Die Path-Funktion ermittelt ausgehend von ID_ColumnName – in unserem Beispiel die Spalte EmployeeKey – den gesamten Hierarchie-Pfad. Basierend auf dieser Spalte lässt sich die zweite Hilfsspalte PathLength ableiten. Sie gibt die Anzahl der Hierarchie-Ebenen des jeweiligen Pfades an. Hierfür wird die DAX-Funktion PathLength verwendet. Diese hat folgende Syntax:
PATHLENGTH(<HierarchyPath_ColumnName>)
In unserem Beispiel wird die Spalte HierarchyPath angegeben. Für die Beispiele aus Abbildung 2 würde immer eine Pfadlänge von 4 angegeben werden. Mit Hilfe dieser Spalte lässt sich die maximale Pfadlänge und somit die Anzahl der benötigten Ebenen ermitteln.
Anschließend muss je Ebene eine berechnete Spalte angelegt werden. Mit diesen berechneten Spalten wird die Dimension modelliert. Logisch sieht der Ausdruck wie folgt aus (n = Nummer der jeweiligen Ebene):
Wenn: Pfadlänge >= n
Dann: Nehme den Namen des Elements an n-ter Stelle des Hierarchiepfades
Sonst: Nehme den Wert der Spalte von Ebene n-1
Hierfür müssen die drei DAX-Funktionen If, LookupValue und PathItem miteinander verschachtelt werden.
Die Funktion LookupValue gibt den Wert eines Feldes zurück, dessen Zeile die angegebene Bedingung erfüllt. Die Syntax dieser Funktion ist:
LOOKUPVALUE(<result_ColumnName>, <search_ColumnName>, <search_value>)
Die Funktion PathItem gibt das Element eines Pfades an einer bestimmten Position zurück. Die Syntax dieser Funktion ist:
PATHITEM(<path>, <position>, [<type>])
Der Type-Parameter ist optional und gibt den Datentyp des Rückgabewertes an.
Der Code für die n-te Ebene in unserem Beispiel ist demnach:

Da die erste Ebene immer vorhanden sein wird, kann für diese auf die If-Funktion verzichtet werden.
Wenn die Möglichkeit besteht, dass die Parent-Child-Hierarchie eine weitere Ebene bekommt, kann für einen solchen Fall ohne Probleme vorgesorgt werden. Es können beliebig viele berechnete Spalten für beliebig vielen Ebenen erzeugt werden. Sobald die maximale Pfadlänge erreicht wurde, wird immer der Sonst-Teil der If-Funktion genutzt und das Element der vorherigen Ebene übernommen. Sollte der Hierarchie-Pfad einmal länger sein, als Ebenen vorgesehen wurden, kann das Tabular-Modell aber weiterhin ohne Problem bereitgestellt werden. Der Grund hierfür ist, dass die Verknüpfung der Dimensionstabelle zu der Faktentabelle nicht über eine der berechneten Spalten erfolgt, sondern über die Spalten mit der ChildID. Somit würden in einem solchen Fall in unserem Beispiel nicht für jeden Mitarbeiter die Bewegungsdaten angezeigt werden, auf den aggregierten Ebenen stehen aber immer die kompletten Summen. Dieser Umstand hat den Vorteil, dass das Modell immer zur Verfügung steht und die Summen immer stimmen. Gleichzeitig kann es aber passieren, dass erst nach längerer Zeit festgestellt wird, dass eine oder mehrere Ebenen fehlen und für die entsprechenden Elemente keine Daten angezeigt werden, da sie nicht in der Dimension enthalten sind.
Die beiden Hilfsspalten müssen nicht zwingend physisch im Tabular-Modell vorhanden sein. Die Referenzen auf die Spalten PathLength und PathItem können auch durch die Funktionen in den Spalten ersetzt und direkt in den Code der Ebenenspalten integriert werden.
Es muss abgewogen werden, ob die berechneten Spalten für informative Zwecke behalten werden sollen, um z. B. leichter QS-Checks durchzuführen, oder ob die Tabelle im Tabular-Modell möglichst schlank sein soll, dafür der Code der Ebenenspalten aber etwas komplexer.
Was bei dieser Überlegung nicht vergessen werden darf, ist, dass zumindest beim ersten Erstellen bekannt sein muss, wie tief die Hierarchie ist. Auch für spätere Anpassungen, wenn weitere Ebenen notwendig sind, ist die Spalte PathLength hilfreich.
Wenn auf die Hilfsspalten verzichtet werden soll, würde der Code für die n-te Ebene wie folgt aussehen:


