Dieser Blogbeitrag beschäftigt sich mit der Optimierung von T-SQL Code des SQL Servers. Es geht hierbei also um Möglichkeiten, Abfragen beispielsweise effizienter zu formulieren und dabei unter anderem den SQL Server Optimierer zu unterstützen. Der Blogbeitrag stellt hierbei eine Sammlung typischer Fälle vor, die beim Schreiben von SQL Code auftreten, ohne Anspruch auf Vollständigkeit zu erheben.
Motivation
Die Performance von BI-Anwendungen ist aus zwei Gründen ein Thema:
- Anwender empfinden die Antwortzeiten von BI-Anwendungen als unterschiedlich „langsam“.
- Administratoren sehen sich mit nicht ausreichenden Zeitfenstern für Datenaktualisierungen konfrontiert.
Beide Gründe sollten Auslöser für systematische Untersuchungen der zugrundeliegenden Datenbanken und Umgebungen nach sich ziehen. Dabei ist auch das Verhalten der Anwender individuell und insgesamt zu berücksichtigen.
Die Gründe für langsam empfundene Verarbeitungszeiten lassen sich in zwei Klassen einteilen:
- Die Last auf dem ausführenden System ist insgesamt zu hoch. Ein einzelner Prozess oder mehrere Prozesse haben keinen optimalen Zugriff auf die vorhandenen Ressourcen. Die vorhandenen Ressourcen sind nicht optimal konfiguriert oder falsch aufeinander abgestimmt
- Abfragen und andere Prozesse innerhalb des ausführenden Systems sind ineffizient formuliert.
Die letzten beiden Beiträge „Hardwareempfehlungen für BI-Anwendungen“ und „SQL-Server Tuning“ beschäftigten sich mit der ersten Form möglicher Gründe. Dieser Beitrag geht nun auf die zweite Form ein, die den relationalen Teil des SQL Servers in den Vordergrund rückt.
Ineffizient formulierte Abfragen und Prozesse sind nicht zwingend „langsam“, als „langsam“ empfundene Abfragen und Prozesse sind wiederum nicht zwingend ineffizient formuliert. Ineffizient formulierte Abfragen sind dennoch oft noch schnell genug, sodass sich eine Optimierung nicht lohnen mag. Optimieren sollte immer zu einem signifikanten Verkürzen von Abfragezeit und/oder dem Minimieren des Ressourcenverbrauchs führen. Verarbeitungszeiten von Abfragen und anderen Prozessen sind daher immer zuerst in Relation zu der gestellten Aufgabe zu betrachten. Ist jedoch ein offensichtlich nicht weiter optimierbarer Vorgang weiterhin ungenügend langsam, müssen alternative Lösungswege gefunden werden.
Ein wesentlicher Teil der möglichen Optimierungsmaßnahmen eines BI-Systems, das nach unserer Vorgehensweise bei Bissantz & Company aufgebaut wird, betrifft die Verarbeitungszeit zur Transformation von Daten in das zugrundeliegende Data Warehouse. Die Optimierung des Data Warehouses und der dadurch versorgten Datenwürfel selbst wird Thema eines späteren Artikels sein.
Die vielen Möglichkeiten zur Messung von I/O-Zahlen, CPU-Auslastungen etc. werden nicht näher erläutert. Stattdessen findet sich nachfolgend eine Sammlung von Tipps (ohne Anspruch auf Vollständigkeit), die beim Design von T-SQL Objekten helfen soll.
Einfache vermeidbare Performancebremsen beim Schreiben von SQL-Abfragen
Beim Arbeiten mit T-SQL fällt auf, dass der SQL Server Optimierer, der die Abfragepläne vor Ausführung einer SQL-Abfrage erstellt, spätestens seit Version 2008 des SQL Servers viele Unsauberkeiten selbst erkennt und entsprechend vermeidet. Insofern werden triviale Fehler beim Schreiben von SQL Code erkannt und ausgemerzt (Probleme wie implizite Konvertierungen können jedoch entgehen):
- UNION/UNION ALL: Union eliminiert beim Verknüpfen von zwei oder mehreren Abfragen identische, d. h. doppelte Datensätze. Dazu wird intern eine zeitaufwändige Group by-Abfrage mit anschließender Sortierung ausgeführt. Nur dann, wenn doppelte Datensätze unerwünscht und nicht anderweitig vermieden werden können (beispielsweise mittels WHERE-Einschränkungen), muss auf Union zugegriffen werden. In allen anderen Fällen ist Union All schnell und einfach.
Zählen von Datensätzen, um lediglich eine Anzahl zu ermitteln (ohne WHERE-Filterung): Dazu dient Count (*). Dies führt jedoch zu einem sogenannten „Table Scan“, d. h. die komplette Tabelle, auf die sich eine Abfrage bezieht, wird gelesen. Es genügt jedoch, Count auf eine bestimmte Spalte der Tabelle auszuführen. Dies führt zwar noch immer zu einem kompletten Lesen aller Zeilen, jedoch lädt der SQL Server nur die Daten der betroffenen Spalte in den Speicher. Sehr große Tabellen können durch eine solch scheinbar simple Operation den Speicher des SQL Servers dennoch erheblich belasten.
Alternative:
SELECT rows FROM sysindexes WHERE id = OBJECT_ID (´table_name´) AND indid < 2
Der SQL Server weiß, wie viele Spalten sich in einer Tabelle befinden. Daher kann dieser Wert aus den Metadaten des SQL Servers abgefragt werden.
- SELECT *
Ein bekanntes Beispiel. Die Auflösung von * erfordert zusätzliche Operationen seitens des SQL Servers. Man kann jedoch diskutieren, ob diese wirklich ins Gewicht fallen. Wichtiger ist der sorglose Umgang mit Select * und seinen Varianten in immer wieder verwendetem Code, wie Views oder Prozeduren, weniger in Ad-Hoc-Abfragen. Der SQL Server liest grundsätzlich nur die Spalten der betroffenen Tabellen, die in einer Abfrage benötigt werden. Unnötig abgefragte Spalten, auch in Unterabfragen und JOINS, sollten daher immer vermieden werden, um Speicherplatzverschwendung vorzubeugen und weiterhin die Anzahl der Leseoperationen einzuschränken. Dies dient der Entlastung von Netzwerk und Festplatten.
Es ist zudem sehr unwahrscheinlich, dass mit Select * ein abdeckender Index erreicht wird.
Oft möchte man möglichst alle Daten aus einem Vorsystem selektieren, um darauf später zugreifen zu können. Diese sollen auch gerne mal noch einige Verarbeitungsstufen lang mitgezogen werden bis hin zu Materialisierungen. Besser ist es jedoch, sich auf die Spalten und Zeilen zu beschränken, die wirklich benötigt werden. - Ein weiteres Problem entsteht, wenn mittels Abfragen
SELECT INTO DestinationTable (Fld1, Fld2, Fld3) SELECT * FROM SourceTable
die Quelltabelle nachträglich erweitert wird:
ALTER TABLE SourceTable ADD Fld4 INT
Dies kann dazu führen, dass durch diese triviale Änderung ein ganzer Aufbereitungsprozess hängen bleibt. Der SQL Code ist nicht sicher genug. Ein späteres SELECT INTO wird fehlschlagen.
- „Set Nocount on“: die Option erzeugt eine zusätzliche Last, besonders bei Prozeduren, die sehr viele iterative Abfragen in Schleifen ausführen. Die Information, wie viele Datensätze von einer Abfrage betroffen waren, ist während der Entwicklung allgemein hilfreich. Der SQL Server ermittelt und sendet diese Information jedoch auch, wenn Abfragen beispielsweise in Prozeduren oder eingebetteten Programmierungen verwendet werden. Dies führt zu einem zusätzlichen Ermittlungsaufwand und Netzwerkverkehr. Per Default ist diese Option nicht gesetzt und sollte bei feststehendem oder eingebettetem Code besser gesetzt werden, da ein Anwender in seinem Frontend diese Resultate ggf. nie zu sehen bekommt.
Filterung von Datensätzen – JOINS und die WHERE-Klausel
Funktionsaufrufe
Kandidaten für lange Abfragezeiten sind Funktionsaufrufe in SQL Code, die zu iterativen Vorgängen führen, wie beispielsweise beim Anwenden auf jede einzelne Zeile einer Tabelle. Dies betrifft selbstgeschriebene als auch die T-SQL eigenen „Built-In“ Funktionen.
In der WHERE-Klausel oder in JOINS sind Funktionen besonders gefährlich, da sie für den SQL Server Optimierer eine Black Box bilden. Funktionsparameter sind dynamisch und zudem vor Ausführung unbekannt, weshalb der SQL Server Optimierer nicht sicher ermitteln kann, welche Spalten in welcher Weise abgefragt werden, um hierfür Indizes heranzuziehen.
Beispiel: Einer unserer Kunden trennte Mandantendaten in einzelne identisch aufgebaute Datenbanken auf und unterschied diese nur anhand der Mandantennummer, die er als Teil des Datenbanknamens einsetzte. Dabei wurde die Funktion DBNAME() unter anderem in der WHERE-Klausel von Select-Statements innerhalb von Prozeduren aufgerufen, um somit eine Filterung der Quelldaten nach Mandant durchzuführen:
WHERE MANDT = ‘M_AfterSales_‘ + DBNAME())‘
Abgesehen von der Zeit, die die wiederholten Prozeduraufrufe benötigen, führte diese Funktion dazu, dass für die Datenfilterung keinerlei Indizes mehr angewendet wurden. Die Funktion diente darüber hinaus als Teil von JOIN-Kriterien und im Aufbau von Spalten.
Abhilfe schaffen folgende Schritte:
- Vor Beginn einer Abfrage in Prozeduren den Datenbanknamen mittels DBNAME() ermitteln und in eine Variable schreiben.
- In einer View ggf. mit WITH arbeiten. Der SQL Server Optimierer kann in diesem Fall den Wert der Variablen als fix erkennen und vermeidet den langsameren Funktionsaufruf.
Weitere Beispiele:
-
WHERE DATEPART(YEAR, ModifiedDate) = 2013 AND DATEPART(MONTH, Modi-fiedDate) = 4
wird optimiert zu:
WHERE ModifiedDate >= '20130101' AND ModifiedDate < '20130401' AND ModifiedDate >=’20130430’
-
SELECT * FROM jobs WHERE (job_id + 7) = 14
Dieses Beispiel verhindert ebenfalls eine Indexverwendung.
Beim JOIN von Spalten verwendete mathematische oder Textoperatoren, die beispielsweise Verknüpfungen ausführen, verhindern auch dort die Indexverwendung.
SUBSTRING, LIKE und ähnliche Funktionen
Beispiel:
SELECT * FROM big_sales WHERE SUBSTRING(stor_id,1,2) = '63'
Bei SUBSTRING (und ähnlichen Funktionen) kann ein Index nicht verwendet werden, bei LIKE kommt es auf die Formulierung an:
- WHERE MATNR like ‘100A%‘: schränkt eine Abfrage auf alle Materialnummern ein, die mit 100A beginnen. Diese Abfrage ist in der Lage einen Index auf der Spalte MATNR zu verwenden.
- WHERE MATNR like ‘%A57%‘. Der Platzhalter % zu Beginn des Vergleichsprädikats verhindert eine Indexverwendung. Ein sogenannter Fulltext-Index kann hier bedingt eine Verbesserung der Abfragezeit ergeben.
NOT IN
Die Filterung mittels NOT IN ist weniger eine Performance-kritische Konstruktionen, sondern ein Konstrukt, das zu fehlerhaften Daten führen kann. NOT IN verwendet durchaus vorhandene Indizes, weist aber speziell bei Spalten, die NULL erlauben ein Problem auf. Nämlich, dass solche Spalten nie in der Ergebnismenge stehen, da NULL für den NOT IN-Filter weder ja noch nein bedeutet. Besser ist hier eine Abfrage mittels EXISTS oder NOT EXISTS geeignet.
Interessant, jedoch nur bedingt einsetzbar, sind Operatoren wie EXCEPT, Outer APPLY/Cross APPLY oder JOINS. Apply und JOINS scheinen gegenüber NOT EXISTS jedoch teurer zu sein. Hierfür verweisen wir auf folgenden interessanten Beitrag: http://www.sqlperformance.com/2012/12/t-sql-queries/left-anti-semi-join
Weitere Fälle, die die Indexverwendung in der WHERE-Klausel verhindern (können):
- Abfragen, bei denen das Suchargument Werte verschiedener Spalten der gleichen Tabelle vergleicht.
- Abfragen, bei denen für das Suchkriterium Operatoren verwendet werden und für die:
- bei den an der Suche beteiligten Spalten auf beiden Seiten des Operators Statistiken fehlen.
- die Selektivität der Abfrage sehr ungleich verteilt ist, speziell bei Ungleichoperatoren (beispielsweise eine indizierte Spalte mit Millionen Postleitzahlen, von denen jedoch nur sehr wenige nicht dem Wert 78359 entsprechen).
- Abfragen, bei denen Variablen verglichen werden, deren Werte zum Zeitpunkt der Ausführungsplanerstellung nicht bekannt sind (also variieren können), verhindern ebenfalls eine Indexverwendung und können auf Ausführungspläne auch andere Auswirkungen haben.
Beispiel: WHERE CONVERT(INT, my_column) = @my_val.
Hinweis: Normalerweise helfen die Prädikate einer WHERE-Klausel dem SQL Server Optimierer die Abfrage zu verbessern, indem er versucht, für die beteiligten Spalten geeignete Indizes zu verwenden. Allgemein sind daher Einschränkungen in WHERE-Klauseln beschleunigend, wenn Indizes verwendet werden können.
Subqueries
Unterabfragen sind für den SQL Server Optimierer nicht ideal. Es kommt vor, dass der Optimierer Unterabfragen durch reguläre oder Outer Joins ersetzt. Das ist nicht generell schlecht, jedoch unsicher, da die gewählte JOIN-Variante auf Annahmen basiert.
Unterabfragen lassen sich am besten durch die explizite Angabe von JOINS ersetzen. Dadurch wird erreicht, dass die Reihenfolge, in der die beteiligten Tabellen verknüpft werden sollen, dem SQL Server Optimierer mitgeteilt wird.
Weiterhin sind die Ergebnisse einer Unterabfrage distinct. Um eindeutige Ergebnisse zurückzugeben, sind also zusätzliche Operationen nötig. Sofern eine Unterabfrage lediglich als ein Kriterium benötigt wird, sind die zusätzlichen Operationen reine Zeitverschwendung.
Daher kann es sich lohnen zu prüfen, ob eine Unterabfrage nicht durch einen explizit formulierten JOIN ersetzt werden kann. Wird die Abfrage bei gleichem Ergebnis dadurch merklich beschleunigt, hat sich der Aufwand gelohnt. Ein typisches Beispiel hierfür kann eine Unterabfrage sein, die Summen mittels SUM() errechnet. Die Unterabfrage ist innerhalb der Oberanfrage eingebettet und wird bei jedem Iterationsschritt abgearbeitet. Das ist typischerweise eine teure Operation.
Beispiel zweier alternativer Abfragen mit gleichem Ergebnis:

SELECT st.stor_name AS 'Store',
ISNULL((SELECT SUM(bs.qty)
FROM sales AS bs
WHERE bs.stor_id = st.stor_id), 0) AS 'Books Sold'
FROM stores AS st
WHERE st.stor_id IN
(SELECT DISTINCT stor_id
FROM sales)
SELECT
st.stor_name AS 'Store',
SUM(bs.qty) AS 'Books Sold'
FROM stores AS st
JOIN sales AS bs ON bs.stor_id = st.stor_id
GROUP BY st.stor_name Das zweite Statement als JOIN-Lösung führt dazu, dass die Summierung am Schluss durchgeführt wird; im ersten Beispiel hingegen findet dies für jede einzelne Zeile der Abfrage statt. Siehe dazu auch folgenden Beitrag: http://www.techrepublic.com/blog/the-enterprise-cloud/optimize-sql-server-queries-with-these-advanced-tuning-techniques/179/
Indizes
Im Folgenden sind typische Fallen bei der Erstellung und Verwendung von Indizes zusammengestellt:
- Für gruppierte Indizes sollten nur Spalten gewählt werden, die sich selten ändern. Vor allem, wenn nicht gruppierte Indizes auf derselben Tabelle existieren. Die nicht gruppierten Indizes speichern in diesem Fall die Schlüsselspalten des gruppierten Index. Änderungen am gruppierten Index ziehen Änderungen an den nicht gruppierten nach sich, wenn beispielsweise Zeilen gelöscht werden.
- Indizes auf Textspalten ergeben häufig nur mäßige Verbesserungen der Performance. Texte eignen sich hierfür schlecht, da textbasierte Indizes selbst sehr viel Speicher und Lesezeit benötigen gegenüber einer Durchsuchung der Basistabelle selbst. Es gibt keine generelle Angabe, ab welcher Feldlänge ein normaler Index auf einem Textfeld keine Vorteile mehr ergibt, auch wenn man hin und wieder Vorschläge liest, wie beispielsweise 30 Zeichen. Hier gilt es schlichtweg auszuprobieren und die Abfragezeiten zu messen.Textbasierte Indizes können sehr viel Speicher belegen. Passt ein Index nicht in den Arbeitsspeicher, sieht sich der SQL Server gezwungen, den Index wiederholt vom langsameren Festplattensystem zu lesen. Weiterhin benötigt der SQL Server zum Lesen von großen textbasierten Indizes entsprechend länger. Besonders prekär ist die Situation bei Unique-Indizes auf Textfeldern, da für die Unique-Prüfung viel Zeit benötigt wird. Im Falle eines gruppierten Index kommt eine aufwändigere Sortierung hinzu.Es gibt zumindest für JOINS, die auf Textfeldern basieren zwei Lösungsansätze: Für sehr große Feldlängen sollte auf den Full-Text-Index ausgewichen werden (zumal die Summe aller Zeichen in einem ein- oder mehrspaltigen Index 900 Byte nicht überschreiten darf). Dieser kann auch bei Einschränkung in where-Bedingungen hilfreich sein, beispielsweise auch bei where xy like ‚%textstück%‘.Da wir im BI-Umfeld jedoch eher Textlängen im Bereich unter 100 Zeichen haben und häufig JOINS auch über Textfelder bilden, bietet es sich an, stattdessen einen künstlichen Index auf Basis eines zusätzlich zu erzeugenden numerischen Feldes anzulegen:Beispiel:
ALTER TABLE Production.Product ADD cs_Pname AS CHECKSUM(Name); GO CREATE INDEX Pname_index ON Production.Product (cs_Pname); GO
(Quelle: http://technet.microsoft.com/de-de/library/ms189788.aspx)
Der Rückgabewert ist vom Typ Int, was für eine indizierte Spalte gut geeignet ist, denn je kleiner die Feldlänge einer Indexspalte ist, umso kleiner (und damit schneller und ressourcensparender) wird ein Index. Bei Checksum weist Microsoft auf die geringe Möglichkeit hin, dass sich nicht immer die Prüfsumme ändert, obwohl sich ein Wert eines Input-Feldes für die Funktion geändert hat. Eine noch sicherere Methode kommt aus der Verschlüsselungstechnik, von denen der SQL Server verschiedene Algorithmen bereithält.
Beispiel für eine SHA1-Verschlüsselung:
DECLARE @HashThis nvarchar(4000); SELECT @HashThis = CONVERT(nvarchar(4000),'dslfdkjLK85kldhnv$n000#knf'); SELECT HASHBYTES('SHA1', @HashThis); GODer Rückgabewert ist vom Typ Varbinary. Quelle: http://technet.microsoft.com/de-de/library/ms174415.aspx
- Index-AbdeckungIn JOINS oder WHERE-Bedingungen ist es wünschenswert, wenn der SQL Server auf einen Index zugreifen kann, der alle beteiligten Spalten beinhaltet, d. h. abdeckt. Dadurch können für Operationen Daten rein aus dem Index gelesen werden. Probleme bestehen dabei jedoch darin, dass solche Indizes bei komplexen Bedingungen häufig viele Spalten beinhalten und oft auch nur für bestimmte SQL-Codestellen einmalig benötigt werden. Eine leicht andere Abfragesituation erfordert wiederum einen anderen Index. Nur ein vollständig abdeckender Index, der alle beteiligten Spalten beinhaltet, verhindert, dass der SQL Server zumindest in Teilen auf die beteiligten Basistabellen zugreifen muss.Je mehr Spalten in den Index mit aufgenommen werden, umso größer und vielstufiger wächst der Index. Er benötigt entsprechend mehr Speicher und mehr Leseoperationen, wird also zunehmend schlechter. Bei Indizes, die viele Spalten umfangreicher Tabellen abdecken – vor allem bei geringer Selektivität – ist häufig das einzelne Indizieren von Spalten die bessere Lösung. Es sollte hierbei jedoch nicht wahllos jede Spalte indiziert werden, sondern wirklich nur diejenigen, die in komplexen Operationen benötigt werden. Der SQL Server würde ansonsten Indizes permanent aktualisieren, die nicht benötigt werden, was wiederum Zeit kostet und die zudem Arbeitsspeicher belegen. Aktualisierungen der Indizes sind aufwendige und damit sehr teure Vorgänge. Bei vielen Spalten ist es umso wahrscheinlicher, dass genau dies passiert, wobei man beachten sollte, dass dies generell vor allem Transaktionssysteme betrifft, bei BI-Anwendungen jedoch zumindest die (nächtliche) Aufbereitung.Spalten, die zwar abgefragt, aber nicht Gegenstand von JOIN-, WHERE- oder Sortieroperationen sind, sollten besser nur via Include-Spalte in den Index aufgenommen werden, um ansonsten nötige intensive RID-Lookups zu vermeiden, wenn diese als Ausgabe benötigt werden.Der SQL Server benötigt im Übrigen eine sehr hohe Selektivität in indizierten Tabellenspalten, bis wirklich auf einen nicht abdeckenden Index überhaupt zugegriffen wird.Gruppierte Indizes sind übrigens vor allem ideal für Gruppierungen (MIN(), MAX(), AVG()) und Bereichssuchen ( >, <, between etc.).
- Zusammengesetzte Schlüssel – composite keysAus zwei oder mehreren Spalten kombinierte Indizes können ineffizient sein, wenn die Reihenfolge der Spalten ungünstig gewählt wurde. Der SQL Server erstellt beispielsweise für Primärschlüssel selbständig einen gruppierten (Clustered) Index. Entsprechend der Anzahl von Primärschlüsselspalten geht damit die Erstellung eines kombinierten gruppierten Index einher.
Die Reihenfolge der Spalten im Index wird festgelegt, indem der Index (und damit die Tabelle) nach der ersten, dann nach der zweiten Indexspalte usw. sortiert wird. Statistiken werden nur für die erste Spalte gespeichert. Werden mehrere am Index beteiligte Spalten bei einer Abfrage in der WHERE-Klausel verwendet, kann der SQL Server eine Indexsuche durchführen.
Eine Indexsuche ist auch möglich, wenn nur die erste Spalte des Index in einer Abfrage vorkommt. Wird jedoch nur die zweite Spalte abgefragt, wird der Index nicht verwendet, sondern es erfolgt ein „Table Scan“. Der Grund ist die interne (B-Tree) Indexstruktur, in der die Suche zuerst in der ersten sortierten Spalte erfolgt, die in diesem Fall jedoch die abgefragte Spalte nicht abdeckt. Die Abfrage der zweiten Spalte erfolgt nicht mit Bezug auf das oberste Sortierkriterium des Index, das mit der ersten Spalte festgelegt wird.
Beispiel: Vor- und Nachname sind sortiert wie in einem Telefonbuch. Es wird nach dem Nachnamen gesucht, dann nach dem Vornamen. Für eine ausschließliche Abfrage des Vornamens ist die Sortierung eines Telefonbuchs zuerst nach Nachnamen, dann nach Vornamen in einem Ort nicht hilfreich.Kombinierte Indizes sind daher nur bedingt hilfreich. Sollte jedoch in der Mehrheit nach Vornamen abgefragt werden, so ist es besser, den kombinierten Index umgekehrt in der Spaltenreihenfolge anzulegen. Siehe auch: http://use-the-index-luke.com/sql/where-clause/the-equals-operator/concatenated-keys
- Das Verwenden gefilterter Indizes verkleinert diese. Dies ist allgemein vor allem beim Ausschluss von Null-Werten bei (sogenannten Sparse Columns) sinnvoll, da bei geringer Wertedichte der Indexbaum flacher werden kann.
Bei indizierten Sichten speichert der SQL Server Abfrageergebnisse, d. h. materialisiert Sichten. Gegenüber einer Materialisierung von Sichten in Tabellen bestehen jedoch einige nicht unkritische Voraussetzungen, siehe: http://technet.microsoft.com/de-de/library/ms187864%28v=sql. 105 %29.aspx
Konvertierungen und Indexverwendung
Konvertierung von Datentypen
Konvertierungen von Datentypen bergen die Gefahr, dass der SQL Server in vielen Konstellationen nicht auf bestehende Indizes zurückgreifen kann. Beispielhaft sei die Konvertierung von Datumsfeldern genannt. Diese werden oft nicht sprachneutral verwendet und hängen auch von den Datumsformateinstellungen ab. Zudem führt das Setzen von Sprach- und Formatoptionen in Prozeduren zur Rekompilation, was sich negativ auf die Laufzeiten von Prozeduren auswirkt. Daher ist die Verwendung eines sprachneutralen Formats (wie ISO 8601) von Vorteil. Dieses Format verwendet keine Trennzeichen. Nach Datumsfeldern wird gerne in folgender Weise gesucht:
SELECT JobCandidateID
,EmployeeID
,ModifiedDate
FROM AdventureWorks.HumanResources.JobCandidate_new
WHERE ModifiedDate = '20040123'
Diese Suche führt zu keinem Ergebnis, wenn ModifiedDate vom Typ datetime und ein Zeitanteil vorhanden ist. Der SQL Server konvertiert den String „20130123“ in den Zeitdatentyp datetime, da dieser in diesem Fall eine höhere Präzedenz als der String besitzt und fügt bei fehlendem Zeitanteil 00:00:00.000 hinzu. In der verwendeten Tabelle (ca. 500.000 Datensätze) sind beispielsweise die Werte für das ModifiedDate-Feld in folgender Form gespeichert:
1997-07-24 00:00:00.000 2004-01-23 18:32:21.313
Nur der erste Wert könnte auf diese Weise bei entsprechender Abfrage ohne Angabe des Zeitanteils gefunden werden. Die Abfrage wird daher verändert:
SELECT JobCandidateID
,EmployeeID
,ModifiedDate
FROM AdventureWorks.HumanResources.JobCandidate_new
WHERE CONVERT(char(8), ModifiedDate, 112) = '20040123'
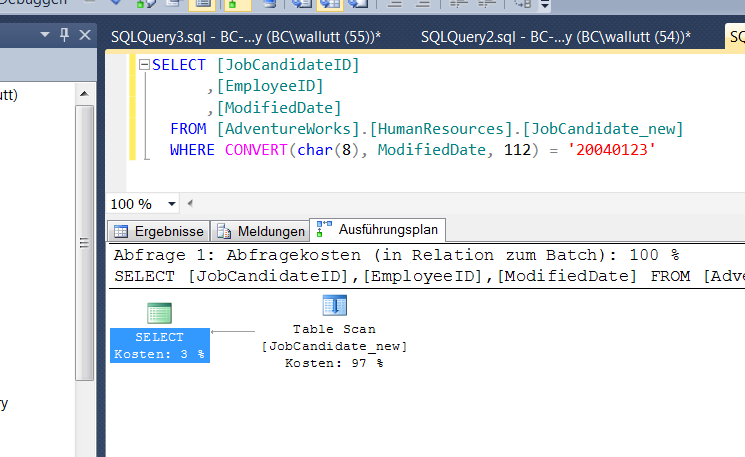
Abb. 1: Abfrage ohne Berücksichtigung des Zeitanteils
Diese Abfrage liefert das erwartete Ergebnis. Die Konvertierung führt aber dazu, dass kein Index mehr verwendet wird, obwohl die Spalte ModifiedDate einen nicht gruppierten Index besitzt. Die Suche verwendet eine Berechnung auf Seiten der Datenspalte, die verhindert, dass der SQL Server auf den Index zugreift.
Eine weitere Variante, in der ebenfalls Datumfunktionen eingesetzt werden:
SELECT JobCandidateID
,EmployeeID
,ModifiedDate
FROM AdventureWorks.HumanResources.JobCandidate_new
WHERE YEAR(ModifiedDate) = '2004' and MONTH(ModifiedDate) = '01' and DAY (ModifiedDate) = '23'
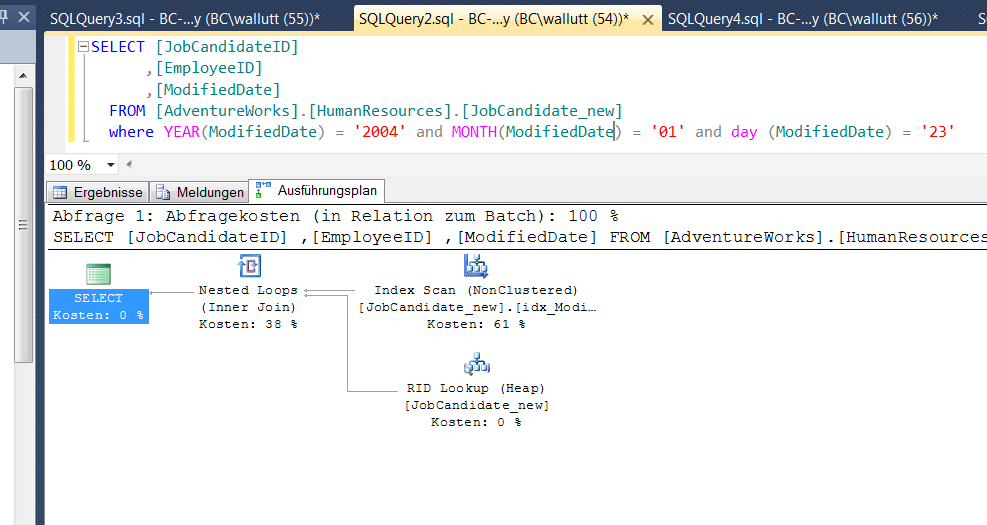
Abb. 2: Verwendung von Datumsfunktionen
Diese Variante führt zu einem gänzlich anderen Ausführungsplan, bei dem der SQL Server Optimierer den Index auf der Spalte ModifiedDate verwendet. Der Index Scan zeigt wiederum, dass der Index der Spalte ModifiedDate jedoch komplett durchsucht wird, was gegenüber einer Index Seek Operation zumindest schlechter ist. Über den RID Lookup werden dann wie in einer Art Bookmark-Tabelle die weiteren benötigten Daten aus den über den Index verlinkten Zeilen der Tabelle gelesen und über einen Nested Loop (wie zu sehen vergleichbar mit einem Inner Join) verknüpft.
Eine weitere Möglichkeit zum Ergebnis zu kommen, bieten Vergleichsoperatoren:
SELECT JobCandidateID
,EmployeeID
,Resume
,ModifiedDate
FROM AdventureWorks.HumanResources.JobCandidate
WHERE ModifiedDate >= '20040123' and ModifiedDate < '20040124'
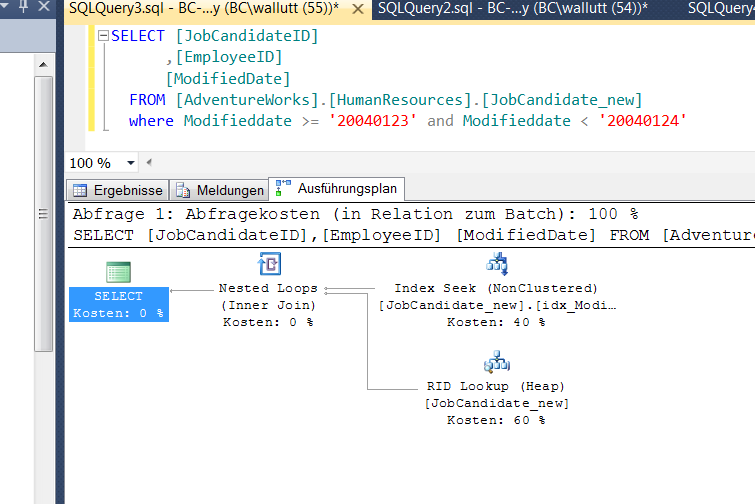
Abb. 3: Verwendung von Bereichen
Das Ergebnis ist wie erwartet: Für die Abfrage kann der SQL Server nun jedoch mit dem für die WHERE-Bedingung vollständig abdeckenden Index der Modifieddate-Spalte arbeiten, wie die Index Seek Operation zeigt. Bei ca. 500.000 Datenzeilen ist diese Operation nahezu auf Knopfdruck erledigt, während beispielsweise der Table Scan bereits eine bemerkbare Verzögerung zeigt. Werden die Ergebnisse dieser Abfragen weiter und mit deutlich höheren Zeilenanzahlen verarbeitet, weiten sich die Unterschiede in den Abfragezeiten exponentiell aus.
Es ist jedoch nicht immer der Fall, dass eine Indexverwendung den besseren Weg gegenüber einem Table Scan darstellt. In den meisten Fällen wird die Indexverwendung aber schneller sein.
Implizite Konvertierung
Abgesehen von Konvertierungsproblemen beim expliziten Einsatz von Konvertierungsfunktionen wird im SQL Code gerne übersehen, dass Spalten ungleicher Datentypen beispielsweise in JOIN- oder WHERE-Bedingungen zu aufwändigen impliziten Konvertierungen führen können.
Beispiel:
SELECT a.MATNR, b.MATNR FROM tabelle1 as a INNER JOIN tabelle2 as b ON a.MATNR = b.MATNR
Spalte a.MATNR ist vom Typ Varchar(50), Spalte b.MATNR vom Typ INT. Der SQL Server konvertiert nun b.MATNR in den Typ varchar, wobei zwei Probleme entstehen:
- Zeitverlust durch Konvertierung
- Langsamer Vergleich auf Basis von Textspalten
Konvertierungen finden aber auch bei verwandten Datentypen wie Varchar nach Nvarchar statt und sollten auch dort vermieden werden. Eine gute Strategie ist es, bereits beim Import von Tabellen, deren Spalten mit denen anderer Tabellen verknüpft werden, die Datentypen zu harmonisieren. Alle nachfolgenden Schritte profitieren davon. Die Konvertierung wirkt sich besonders stark bei JOINS und WHERE-Bedingungen aus, jedoch auch in den Ausgabespalten von Select-Statements. Siehe auch: http://technet.microsoft.com/de-de/library/ms191530.aspx
Generell zu vermeiden
- Cursor: diese Aussage gilt allerdings nicht in jedem Fall. Cursor werden gerne von Programmierern mit wenig mengenorientiertem SQL-Wissen in eingebettetem Code verwendet, aber auch in Prozeduren, bei denen andere Lösungen nicht gefunden wurden.
- Beispiele für eindeutige Warnindikatoren, die sich in Ausführungsplänen für schwergewichtige Operationen zeigen:
- LOOKUP
- PARALLELISM
- SCANS
- SPOOLS
- Hash-JOINS
- Lazy Spool
In manchen Konstellationen sind diese Operationen nicht vermeidbar.
- DateTime2 ist ein „besserer“ DateTime-Datentyp der potentiell weniger Speicher verbraucht. (6-8 Bytes vs. 8 Byte fix), ab SQL 2008
Dynamisches SQL beinhaltet das Risiko einer sogenannten SQL Injection, d. h. Überflutung des Plan-Caches. Jede Ausführung des dynamischen Statements führt zu einem eigenen Abfrageplan im Plan-Cache des SQL Servers, die dabei auch noch identisch sind. Die Speicherkapazität des Plan-Caches wird hierbei schnell überschritten, sodass der Zeitvorteil zur Wiederverwendung von Abfrageplänen verloren geht. Die Ausführung von dynamischem SQL unterbindet zudem die Verwendung von Parametrisierungen, d. h. der SQL Server Optimierer wendet Filterungen beispielsweise der WHERE-Klausel nicht an, die jedoch Aussagen u. a. als Kriterium zur Indexverwendung liefern. Dennoch gibt es gelegentlich Situationen, in denen dynamisches SQL auch Performancevorteile bieten kann. (Siehe auch: Holger Schmeling, SQL Server 2012 Performance Optimierung)
- Automatisch erstellte Unique-Indizes oder Indizes sind schlecht, sie enthalten keine eingeschlossenen Spalten, sind also für viele Abfragen zumeist nicht abdeckend. Für Unique wird automatisch ein Index erstellt, eine manuelle Erstellung ist jedoch der bessere Weg. Indizes auf AutoID Spalten sind zumeist wertlos.
- Filter im Inner Join oder in der WHERE-Klausel: Sofern beides die gleichen Ergebnisse liefert, gibt es keinen Unterschied, ob im JOIN oder der WHERE-Klausel Daten gefiltert werden, sofern es sich um einen Inner Join Der SQL Server behandelt beide Konstruktionen gleich, die Filterung erfolgt in beiden Fällen erst nach der JOIN-Operation.
Microsoft gibt zu diesem Thema folgende Aussage:
„There can be predicates that involve only one of the joined tables in the ON clause. Such predicates also can be in the WHERE clause in the query. Although the placement of such predicates does not make a difference for INNER joins, they might cause a different result when OUTER JOINS are involved. This is because the predicates in the ON clause are applied to the table before the join, whereas the WHERE clause is semantically applied to the result of the join.” (Quelle: http://stackoverflow.com/questions/2509987/which-sql-query-is-faster-filter-on-join-criteria-or-where-clause)
Bei anderen Datenbanken, wie DB2, ist jedoch die Einschränkung im JOIN offenbar die bessere Lösung, auch wenn Filterungen eigentlich prinzipiell in die Zuständigkeit von WHERE-Bedingungen fallen. Der SQL Server Optimierer zeigt hier, dass der SQL Server Abfragen nicht zwingend in der Reihenfolge ausführt, wie man vermutet.
Anmerkung: Die vor langem gebräuchliche Variante, den JOIN komplett in die WHERE-Klausel mithilfe eines kartesischen Produkts zu verlegen, kann wiederum völlig andere Laufzeiten ergeben. Das Verfahren nach ANSI 89 SQL Syntax zeigt nach verschiedenen Quellen im Internet tendenziell einen höheren Ressourcenverbrauch an. Siehe auch: http://www.bennadel.com/blog/ 284-SQL-Optimization-And-ON-Clause-vs-WHERE-Clause.htm
Bei OUTER JOINS kann es schnell passieren, dass die Ergebnismengen voneinander abweichen.
- Sortiereffizienz mit TOPN-Abfrage: Seit SQL Server 2012 gibt es im Ausführungsplan eine eigene Routine hierfür (fetch first)
SELECT TOP 10 * FROM sales ORDER BY sale_date DESC;
Wenn die Datenbank weiß, dass nur zehn Zeilen geladen werden, kann sie ein sogenanntes pipelined order by bevorzugen. Voraussetzung für diese Performanceverbesserung ist jedoch ein Index auf der Spalte sale_date.
Benutzerdefinierte Funktionen: Wie bereits im Kapitel 3.1 gezeigt, sind Funktionsaufrufe für den SQL Server Optimierer nicht ideal. Für benutzerdefinierte Funktionen verhält sich dies ähnlich. Ein anschauliches einfaches Beispiel für benutzerdefinierte Funktionen findet sich unter http://sqlserverplanet.com/optimization/user-defined-functions-and-performance.
Als Abhilfe wird die Verwendung einer „inline table valued function“ vorgeschlagen. Zu bedenken ist jedoch, dass eine solche Alternative nicht immer zur Verfügung steht. Man sollte sich genau überlegen, ob man Codeteile zur Vereinfachung vor allem bei sich wiederholendem Code in Funktionen auslagert.
