Zum Aufbau von OLAP-Modellen in SQL-Server Analysis Services erzeugt der DeltaMasterModeler ein relationales Snowflake-Schema. Um Probleme bei der Aufbereitung des Würfels zu vermeiden, wird das Snowflake-Schema ordentlich mit Fremd- und Primärschlüsseln generiert. Die Sicherstellung der Datenintegrität ist für produktive Anwendungen auch unbedingt zu empfehlen. Leider erschwert einem häufig die strenge Logik das Leben beim Aufbau von Prototypen. Bekommt man beispielsweise Stammdaten mit nicht eindeutigen Bezeichnungen, kann daraus keine Dimension aufgebaut werden, weil die Primärschlüssel-Einschränkung verletzt wird. Im folgenden Artikel wird beschrieben, wie man die Dimension trotz allem aufbauen kann.
Was wir noch verstehen
In einer perfekten Welt sind Stammdaten zu einem Zeitpunkt immer eindeutig und überschneidungsfrei. Leider ist unsere Welt nicht ganz so perfekt und so kommt es (auch in produktiven Systemen) immer wieder vor, dass wir aus unsauberen Stammdaten OLAP-Modelle aufbauen müssen. Für die folgende Betrachtung dient ein einfaches Beispiel, bei dem die Bezeichnung einer Artikelnummer nicht eindeutig definiert ist:
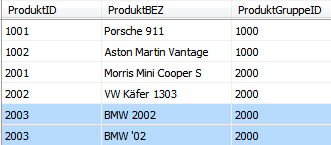
Die Dimension ist in Modeler standardmäßig konfiguriert. Es ist eine Ebene „Produktgruppe“ und eine darunterliegende Ebene „Produkt“ definiert. Für jede Ebene gibt es eine Quelltabelle, welche in dem Bericht „Level Source Columns“ angebunden ist:

Die erfahrenen DeltaMaster-Modeler-Nutzer kennen das folgende Bild nur zu gut. Beim Ausführen des „Transform All“ (= Befüllung des Snowflake-Schemas) kommt es in der Modeler.exe zu folgender Fehlermeldung:
![]()
Der erste gezeigte Fehler 2627 wird dabei direkt durch die doppelt definierte Produktbezeichnung verursacht, der zweite Fehler 547 ist lediglich ein Folgefehler. Beim Versuch, die Faktendaten zu laden, schlägt folgerichtig die Fremdschlüsselprüfung Alarm, da die Dimensionstabelle ja nicht gefüllt werden konnte. Seit der Modeler Version 208 wird auch der verursachende Fehler in einem fertigen Bericht dargestellt. Folgefehler, (wie der o.g. 547,) werden dabei bewusst ausgeblendet, um den Anwender nicht unnötig auf eine falsche Fährte zu locken. Hier die Darstellung des zuvor provozierten Fehlers:

Soweit erst mal nicht viel Neues.
Den Modeler verstehen – Abstieg in die Tiefen der Code-Generierung
Das Problem wird in unserem Beispiel durch abweichende Informationen auf derselben Teilenummer verursacht. In unserer Quelltabelle sind also zwei Datensätze mit einer identischen Produktnummer vorhanden, lediglich die Bezeichnung ist unterschiedlich.
Um auf die Lösung zu kommen, muss man verstehen, wie der Modeler intern versucht, sein Snowflake-Schema zu befüllen. Alle INSERT-Statements zur Befüllung der T_DIM-Tabellen werden grundsätzlich um einen GROUP-BY-Befehl ergänzt. Dieser sorgt dafür, dass es im Falle der Lieferung doppelter Datensätze zu keinem Fehler kommt, wenn die Inhalte komplett identisch sind. Hier das INSERT-Statement für unsere Produkt-Dimension:
Insert Into T_DIM_05_02_Produkt ( [ProduktID], [ProduktGruppeID], [ProduktBEZ] ) Select isnull(Convert(int,ProduktID),'0') [ProduktID], isnull(Convert(int,ProduktGruppeID),'0') [ProduktGruppeID], isnull(Convert(varchar(250),ProduktBEZ),'missing (Produkt)') [ProduktBEZ] From T_Import_Produkt_manuell Group By isnull(Convert(int,ProduktID),'0'), isnull(Convert(int,ProduktGruppeID),'0'), isnull(Convert(varchar(250),ProduktBEZ),'missing (Produkt)') Having isnull(Convert(int,ProduktID),'0') not in (Select [ProduktID] From T_DIM_05_02_Produkt)
Na, klingelt’s schon bei dem ein oder anderen?
Dieses „Grouping“ könnten wir uns natürlich zu Nutze machen, wenn wir es irgendwie schaffen die Bezeichnung aus dem INSERT heraus zu bekommen. Und genau das ist in Modeler konfigurierbar! Evtl. haben Sie sich auch schon über die vielen Spalten im Bericht „Level Source Columns“ gewundert. Nun, diese sind genau für unseren Problemfall gedacht. Über die Spaltenkonfiguration kann definiert werden, welche Teile in das INSERT-Statement mit aufgenommen werden und welche nicht. Dabei sind beispielsweise nicht nur die Key-, GroupKey- und Name-Spalten getrennt steuerbar, sondern auch Attribute, Default Values sowie das Hinzufügen eines UPDATE-Befehls.
Wenn wir nun einfach alle Spalten außer „Insert KEY“ deaktivieren,
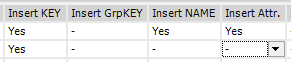
wird beim Ausführen von „Create Snowflake“ ein Statement generiert, mit dem nur die „ProduktID“ eingefügt wird.
Da dort auch das GROUP BY ergänzt wird, erhalten wir damit eine eineindeutige Liste mit ProduktIDs. Das neue INSERT-Statement sieht folgendermaßen aus:
Insert Into T_DIM_05_02_Produkt ( [ProduktID] ) Select isnull(Convert(int,ProduktID),'0') [ProduktID] From T_Import_Produkt_manuell Group by isnull(Convert(int,ProduktID),'0') Having isnull(Convert(int,ProduktID),'0') not in (Select [ProduktID] From T_DIM_05_02_Produkt)
Versucht man nun erneut das Snowflake-Schema zu befüllen, gelingt dies ohne Fehlermeldung. Ein Blick in die Dimensionstabelle zeigt, dass die Produkte mit IDs eingefügt werden konnten:
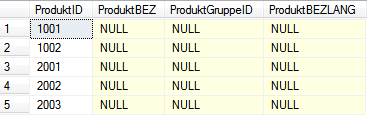
Ein Teilerfolg ist also errungen. Wie aber bekommen wir jetzt die Bezeichnungen dazu, insbesondere wenn diese nicht eindeutig sind?
Ganz einfach – wir machen uns eine „nette“ Eigenschaft von T-SQL zunutze. Wir nutzen ein UPDATE auf die Tabelle. Will man eine Zieltabelle per UPDATE manipulieren und nutzt dazu beispielsweise eine Übersetzungstabelle, deren Datensätze nicht eindeutig sind, so stört das die Abfrageausführung nicht im Geringsten. Das UPDATE wird trotz allem ausgeführt und im Falle nicht eindeutiger Datensätze wird einfach der erste Datensatz verwendet. Das scheint eine etwas „schmutzige“ Lösung zu sein, weil nicht definiert steuerbar ist, welcher Quelldatensatz in die Dimension übernommen wird, aber wie schon erwähnt, bietet sich dieses Vorgehen insbesondere für die schnelle Erstellung von Prototypen an, bei denen es nicht so sehr um inhaltliche Korrektheit geht. Um dies zu erreichen, müssen wir nun in Modeler lediglich die identische Quelltabelle noch ein weiteres Mal anbinden. Hier werden nun alle notwendigen Spalten inklusive der „Insert Update“ Eigenschaft aktiviert:

Damit wird eine neue Befüllungsprozedur für die Dimensionstabelle erstellt, welche ein UPDATE-Statement enthält.
Jetzt wird sich die Ein oder Andere fragen, warum das „Insert KEY“ nach wie vor angeschaltet bleibt? Dann müssten doch die Schlüssel auch wieder mehrfach eingefügt werden, wenn erneut ein Insert über die Keys ausgeführt wird?! Weit gefehlt. Der entscheidende Punkt ist bereits in den oben gezeigten INSERT-Statements enthalten. Alle INSERTS enden mit einem HAVING-Befehl. In unserem Beispiel:
Having isnull(Convert(int,ProduktID),'0') not in (Select [ProduktID] From T_DIM_05_02_Produkt)
Der Teil sorgt dafür, dass nur Produkte mit einer neuen ProduktID der Tabelle hinzugefügt werden. Da dies im ersten INSERT aus der primären Quelltabelle bereits passiert ist, wird kein neuer Datensatz mehr eingefügt.
Der entscheidende Teil ist weiter unten in der neu generierten Prozedur zu finden. Hier findet man das eben konfigurierte UPDATE:
Update d set d.[ProduktGruppeID] = s.GRP, d.[ProduktBEZ] = s.BEZ from T_DIM_05_02_Produkt d inner join (select isnull(Convert(int,ProduktID),'0') [ProduktID], isnull(Convert(int,ProduktGruppeID),'0') GRP, isnull(Convert(varchar(250),ProduktBEZ),isnull(Convert(int,ProduktID),'0')) BEZ from T_Import_Produkt_manuell ) s on convert(int, d.[ProduktID]) = s.[ProduktID]
Das Ergebnis wird dem gestressten PreSales-Consultant vor Freude die Tränen in die Augen treiben:
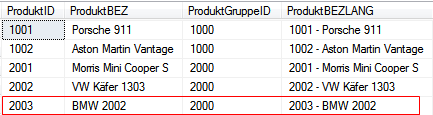
Das UPDATE-Statement konnte beim „Transform All“ erfolgreich ausgeführt werden und die erste Bezeichnung „BMW 2002“ aus der Quelltabelle wurde dem Produkt mit der ID „2003“ zugeordnet. Wie gesagt, die Lösung ist nicht ganz sauber, aber immer noch besser als ein leeres OLAP-Modell. Von daher können wir mit dem Ergebnis nun wenigstens die ganze Power von DeltaMaster auf die Straße bringen.
