Es existieren mehrere Arten von Datenbeziehungen in Datenbanken. In OLAP-Datenbanken finden wir primär die reguläre Beziehung jeder Dimension zu einer oder mehreren Measuregruppen. Bei einer regulären Beziehung ist eine Attributspalte einer Dimension mit einer Spalte in einer Faktentabelle dieser Measuregruppe verknüpft. Zwischen Dimensionen und Faktentabellen können jedoch auch Mehrfachbeziehungen bestehen.
Reguläre Beziehungen “1:n”
In der Regel bezieht sich eine einzelne Zeile in der Faktentabelle auf ein Element einer bestimmten Dimension. Umgekehrt kann sich ein bestimmtes Element einer Dimensionstabelle auf mehrere Zeilen einer Faktentabelle beziehen. Diese Art der Beziehung wird als 1:n-Beziehung bezeichnet und ist zwischen Dimensionen und Faktentabellen die häufigste Beziehung.
Mehrfachbeziehungen – Anwendungsfall m:n-Beziehung
Manche Anforderungen an die Abbildung von Daten können mit 1:n-Beziehungen nicht abgedeckt werden und erfordern fortgeschrittene Entwurfstechniken. Eine dieser Erweiterungen sind m:n-Beziehungen zwischen Zeilen der Faktentabelle und den Dimensionselementen.
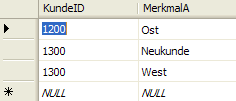
Nehmen wir eine typische Kundentabelle:

Hier kann es durchaus vorkommen, dass für Kunden bestimmte Merkmalsgruppen definiert sind und dem Kunden innerhalb einer Merkmalsgruppe mehrere Ausprägungen zugeordnet sind. Wir sprechen dann von einer Mehrfachausprägung innerhalb eines Merkmals.
Zum Beispiel haben wir für die Besuche des Kunden durch einen Vertriebsmitarbeiter Zielgruppen definiert und weisen dem Kunden mit der ID „1300“ sowohl die Zielgruppe „Neukunde“ als auch die Zielgruppe „West“ zu.
In der Kontakt- bzw. Besuchstabelle wird jeder Besuch des Vertriebsmitarbeiters gespeichert. Daraus ist zu ersehen, dass der Kunde mit der ID „1300“ insgesamt 10 mal besucht wurde.
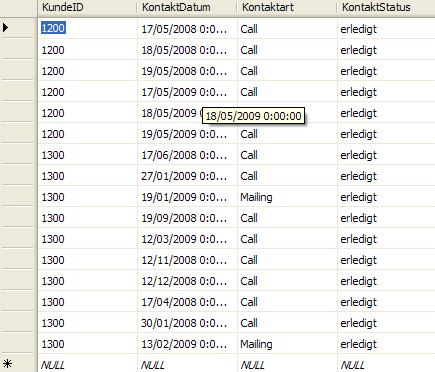
Wie man sieht, fehlen hier die Merkmale. Man kann sie nicht eindeutig einem Besuch zuordnen. Um die Merkmale als weitere Information in dem Analysemodell aufzunehmen, also als eine Dimension anzulegen, müsste man nach dem Prinzip der 1:n-Beziehung auch eine Spalte mit dem Merkmal in der Faktentabelle „Kontakte“ definieren. Dadurch würde man aber die Anzahl der Datensätze vervielfachen, weil für jeden Besuch sowohl ein Datensatz mit der Merkmalsausprägung „Neukunde“ als auch ein weiterer Datensatz mit der Ausprägung „West“ zu speichern wäre. Für die Zählung der tatsächlich durchgeführten Besuche wird man dann aber zu einer fehlerhaften Aussage kommen.
Also benötigen wir eine Möglichkeit, die Merkmale über den Kunden zu summieren. Werden sie in einer Kreuztabelle dargestellt, sollte für jedes Merkmal des Kunden eine 1 erscheinen, aber die Kunden an sich dürfen nicht doppelt gezählt werden. In unserem Beispiel muss der Analysewert „Anzahl_Kunde“ den Wert 2 aufweisen.
Wird die Merkmalsdimension als eine m:n-Dimension eingerichtet, kann diese Art von Summierung bequem durchgeführt werden. Eine zwischengeschaltete Faktentabelle (Hilfs-Measuregruppe) übernimmt dabei die Zuordnung jedes Kunden zu einem oder mehreren Merkmalen. Sie enthält selbst keine Measures, sondern nur Schlüssel für die Dimensionen, die sie miteinander verknüpft.
Modelldefinition mit Hilfe von DeltaMaster Modeler
Zuerst wird die Merkmalsdimension in DeltaMaster Modeler (DMM) angelegt.
Dimension anlegen
Levels definieren

Level Source Columns festlegen (Dafür bedarf es dann der Merkmalstabelle als Quelle)

Nun wird die sogenannte Hilfs-Measuregruppe angelegt.
Measuregruppe anlegen (Facts)
Faktentabelle für die Befüllung der Measuregruppe definieren (Die Hilfs-Measuregruppe hat die gleiche Tabelle als Quelle wie die Dimension MerkmalA)
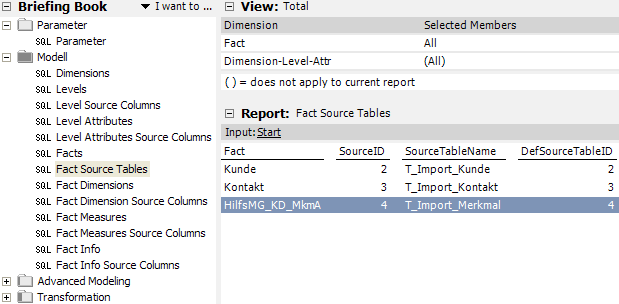
Zuweisung von Dimensionen zur Measuregruppe
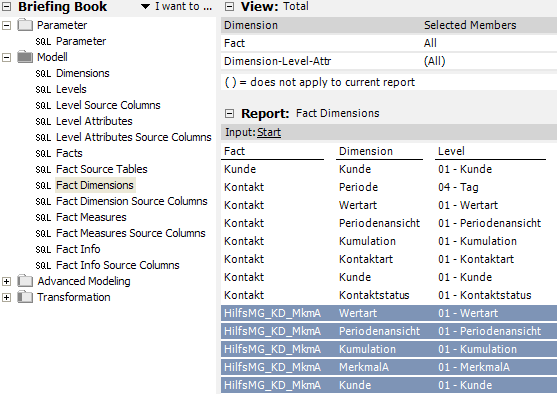
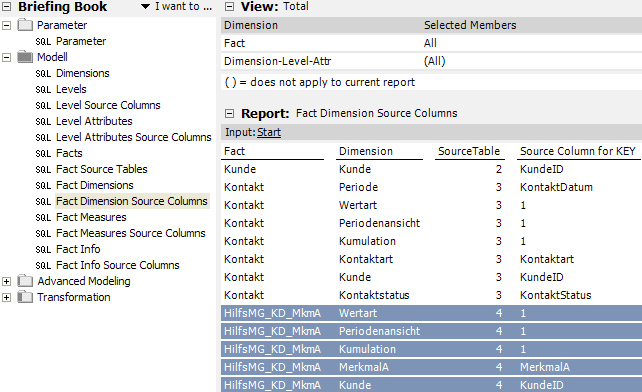
Festlegung der Datenspalten aus der Faktentabelle für jede Dimension
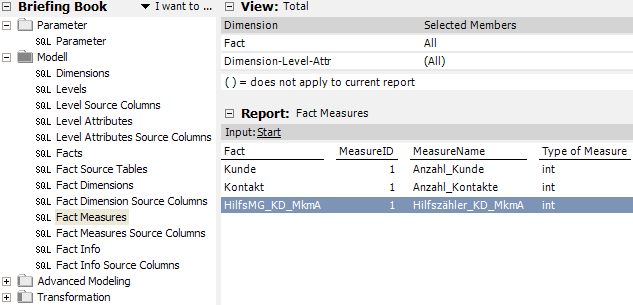
Hilfszähler als Measure anlegen
Hilfszähler mit 1 befüllen
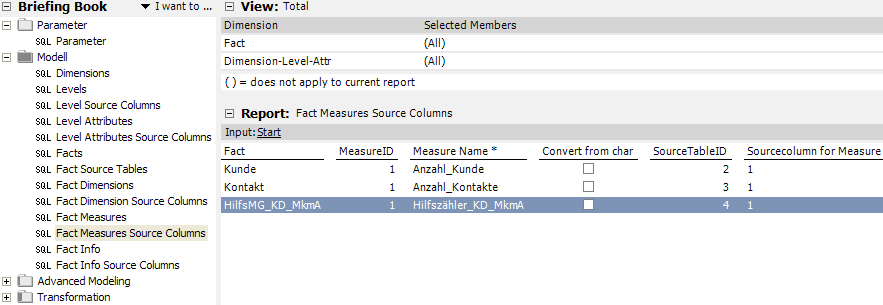
Nachdem über DMM das Snowflake-Schema und das multidimensionale Modell erzeugt wurden, werfen wir mit DeltaMaster einen Blick auf das Modell. Dazu kreieren wir folgendes Pivot-Cockpit:
Es ist klar ersichtlich, dass unser Analysewert „Anzahl_Kunden“ über die Kundendimension die richtige Anzahl an Kunden anzeigt und auch summiert.
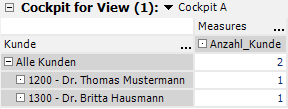
Jetzt modifizieren wir das Cockpit und nehmen statt „Kunde“ die Dimension „MerkmalA“.
Dadurch, dass es im Moment keinen Bezug zwischen der Dimension „MerkmalA“ und der Measuregruppe „Kunde“ (aus der ja der Analysewert „Anzahl_Kunde“ stammt) gibt, liefert die Datenbank inhaltlich falsche Werte an DeltaMaster.
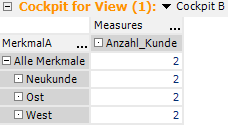
Nun erweitern wir das Cockpit mit dem „Hilfszähler“, um einen Vergleich zu haben. Wir sehen, dass zwar auf der Merkmalsebene richtig gezählt wird, jedoch ist die inhaltliche Anforderung, dass die Summe den Wert 2 statt 3 anzeigt.
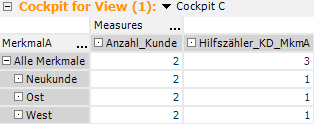
Im nächsten Cockpit wird das nochmals deutlicher, wenn wir die Merkmalsdimension durch die Kundendimension ersetzen.
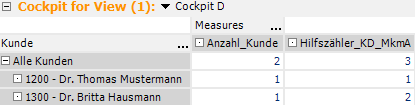
Der Kunde mit der ID „1300“ wird vom Merkmalszähler doppelt gezählt. Ziel ist es jedoch, die Kennzahl „Anzahl Kunde“ sowohl zur Zählung der Kunden als auch zur Zählung der Merkmale heranziehen zu können.
Lösung
Um zu erreichen, dass der Analysewert „Anzahl Kunden“ mit der Dimension MerkmalA zu richtigen Zählungen führt und die Datenbank richtig summiert, werden wir im „SQL Server Business Intelligence Development Studio“ eine m:n-Beziehung zwischen der Measuregruppe „Kunde“ und der Dimension „MerkmalA“ herstellen.
Bei einer m:n-Beziehung werden die Werte getrennt summiert, was bedeutet, dass sie nicht mehr als einmal für das All-Element aggregiert werden.
Wir wechseln zum Cube-Designer der Analysis Services, und klicken dann auf die Registerkarte Dimensionsverwendung.
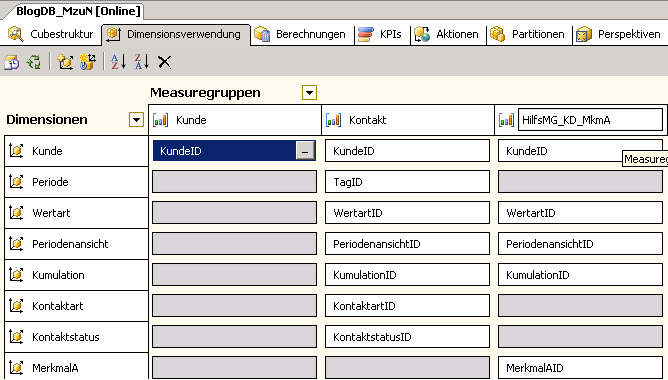
Wie man sieht, ist zwar für die Dimension „MerkmalA“ eine reguläre Beziehung zur Hilfs-Measuregruppe definiert, es fehlt aber eine Beziehung zur Kunden-Measuregruppe.
Nun klicken wir auf die Schaltfläche mit den drei Punkten (…) in der Zelle am Schnittpunkt der Kunden-Measuregruppe und der MerkmalA-Dimension.
Wir wählen im Dialogfeld „Beziehung definieren“ m:n in der Liste Beziehungstyp aus. Danach selektieren wir in der Zwischenmeasuregruppe-Liste die Hilfs-Measuregruppe.
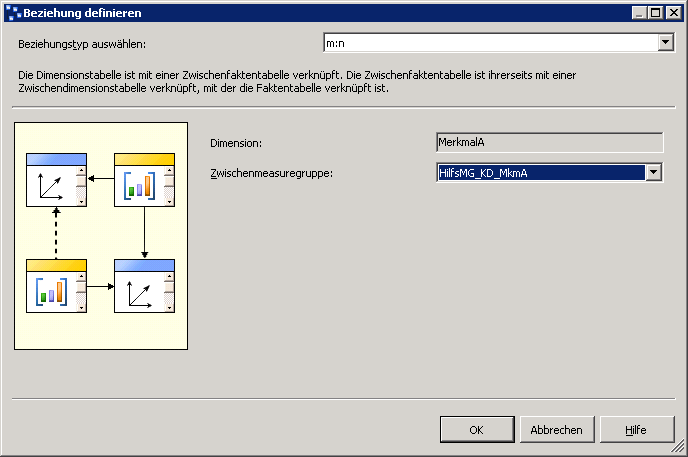
Nach dem wir mit OK bestätigt haben, ist die Zelle am Schnittpunkt nun gefüllt.
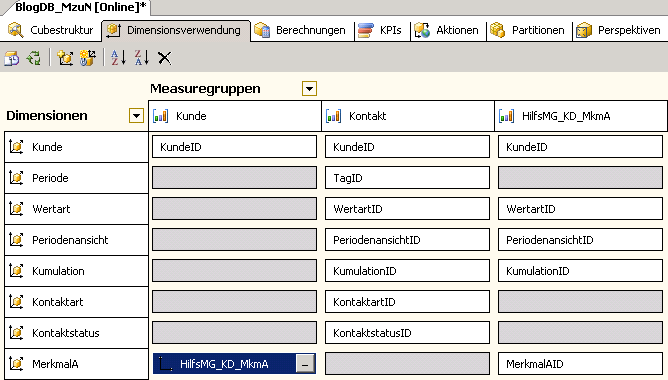
Nachdem wir die Datenbank prozessiert haben, kehren wir zu DeltaMaster zurück und aktualisieren mit F9 die Cockpits und kontrollieren die Werte im Cockpit.
Jetzt liegen die Werte richtig vor. Jedes Merkmal wird mithilfe der Kennzahl „Anzahl_Kunde“ gezählt, aber der Analysewert „Anzahl_Kunden“ weist auf aggregierter Ebene den korrekten Wert aus: Unsere zwei Kunden.
