Dieser Blogbeitrag zeigt einen Lösungsansatz, wie man scheinbar sporadischem (Fehl-)Verhalten von MS SQL Servern auf die Spur kommen kann. Dazu werden SQL Server Datensammler beschrieben und deren technische Umsetzung sowie die Konfiguration der Sammlungsumgebung erläutert. Außerdem wird der Einsatz und der Nutzen in Kundenprojekten aufgezeigt.
Den Phänomenen auf der Spur
Der Titel des heutigen Blogbeitrags mag etwas nüchtern klingen, es verbirgt sich dahinter aber die spannende Frage, wie man dem Verhalten von SQL-Datenbanken über Monate und Jahre auf die Schliche kommt, ohne dazu 24 Stunden, 7 Tage die Woche, 365 Tage im Jahr vor dem Monitor zu verbringen.
Anlass sind die häufig von Anwendern getroffenen Aussagen wie zum Beispiel: „Ab und zu ist das System sehr langsam“, „das Verhalten tritt immer mal wieder auf – jetzt wo Sie da sind aber gerade nicht“. Oftmals schieben wir Berater derartige Äußerungen in das Reich der Phänomene. Da das Problem aktuell nicht auftritt, muss es uns auch nicht beschäftigen. Korrekt an dieser Stelle ist, dass wir uns „jetzt“ nicht damit beschäftigen müssen. Spätestens im Jahresgespräch oder einem anderen Abstimmungstermin gelangen derartige Aussagen aber gern wieder auf den Tisch. Wäre es da nicht fantastisch, wenn das betroffene SQL-Server-System im Hintergrund die verschiedenen Auffälligkeiten sammelte und sich merkt, sodass wir zu gegebener Zeit die Daten sichten und auswerten könnten?
Genau zu diesem Zweck unterstützt uns der Microsoft SQL-Server mit einem sehr nützlichen Werkzeug unter dem schlichten Stichwort „Datensammlung“ (engl. Data Collection).
Was darunter zu verstehen ist, wie es technisch funktioniert und wie die Datensammlung konfiguriert und eingesetzt wird, werde ich im folgenden Blogbeitrag darstellen. Da es sich um langfristige Aufzeichnungen handelt, wird die Auswertung in einem weiteren Artikel erscheinen.
Allgemeines Verfahren in SQL-Server
Die Microsoft SQL-Server implementierte Variante für die langfristige Sammlung von Datenbank-Systeminformationen besteht grundsätzlich aus zwei Teilkomponenten:
- einer zentralen relationalen Datenbank
- verschiedenen, einzeln konfigurierbaren Datensammlern (Quellen von Leistungsinformationen zur Nutzung von SQL-Objekten)
Seit SQL-Server 2008 ist die Datensammlungs-Plattform zur Erhebung, Speicherung und Aufbewahrung des Nutzungsverhaltens in SQL-Server integrativer Bestandteil. Nach erfolgreicher Installation des SQL-Servers kann die Data Collection über das Microsoft Management Studio (kurz: SSMS) genutzt und verwaltet werden.
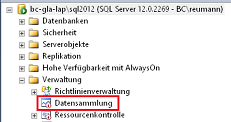
Abbildung 1: Navigation im SSMS
Zu finden ist die Datensammlung auf Serverebene unter dem Knoten „Verwaltung“.
Hinweis: In reinen Reportingsystemen ergibt der Einsatz wenig Sinn, da die Datensammlungen Tabellen- und Prozedurnutzungsinformationen über einen langen Zeitraum speichern und bereitstellen. In Planungssystemen, bei denen größere Arbeitsbelastung und damit auch schlechtere Performance in einem kleineren Zeitraum (Planungsphase) zu erwarten sind, kann es hilfreich sein, derartige Nutzungsinformationen zu sammeln. Gerade im Hinblick auf zukünftige Planphasen kann so ein Optimierungspotential erkannt werden, ohne sich auf „gefühlte“ Antwortzeiten verlassen zu müssen. Laut Microsoft sind derzeit keinerlei Performanceeinbußen durch die Datensammlungsaufträge bekannt. Einzig Speicher-platz für die Sammlungsdatenbank muss vorgehalten werden. Da aber auch hier regelmäßig die Datensätze verdichtet werden, sollte der Bedarf nicht ausufern.
Da wir keine gesicherten Aussagen bei den Recherchen zum Speicherbedarf finden konnten, werden konkrete Werte dazu erst in einem weiteren Blogbeitrag (mit etwas Abstand, um entsprechende Datenmengen in der Aufzeichnung zu haben) genannt werden können.
Bestandteile
Die zentrale Datenbank ist eine rein relationale Datenbank auf einem beliebigen SQL-Server-System. Sie wird vollautomatisch von SQL-Server angelegt, sobald man mit der Konfiguration seiner Langzeitüberwachung startet. Dazu aber später im Abschnitt Konfiguration mehr.
Die Datensammler können in unterschiedliche Typen unterteilt werden. Ein Teil sind .Net Module, die durch die Installationen vom SQL-Server verfügbar sind, andere sind verschiedene generische SQL-Abfragen. Dabei werden die teilweise in das Dateisystem zwischengespeicherten Cacheinformationen mit Hilfe der SQL-Server Integration Services (kurz: SSIS) in die Sammlungsdatenbank importiert.
Die automatische Befüllung der relationalen Datenbank übernimmt der SQL-Server Agent mit unter-schiedlichen Aufträgen. Dieser wiederum erstellt ebenfalls einen Assistenzdialog des SQL-Servers während der Konfiguration.
Die Auswertung erfolgt im Standard ausnahmsweise nicht mit Hilfe von DeltaMaster (wobei dies natürlich möglich ist) sondern mit den Reporting Services des SQL-Servers (kurz: SSRS). Die versierten Anwender unter Ihnen werden jetzt natürlich anmerken, dass damit für das hier vorgestellte Verfahren auch die Reporting Services installiert sein müssen, also Voraussetzung sind. Dem ist nicht so, denn einzelne Teilkomponenten sind zentraler Bestandteil des Datenbankmoduls. Eine zusätzliche Installation von SSRS ist nicht notwendig, weil die benutzten Teilkomponenten zentraler Bestandteil des Datenbankmoduls sind.
Konfigurationsanleitung
Der erste notwendige Schritt zur Inbetriebnahme der Datensammlung ist die Einrichtung der zentralen Datenbank für die Überwachungsergebnisse. Dazu kann einfach der integrierte Assistent über das Management Studio per Rechtsklick auf „Datensammlung – Tasks“ ausgeführt werden:

Abbildung 2: Datenbank einrichten
Im darauffolgenden Dialog kann entweder eine bestehende Datenbank oder eine neue Datenbank ausgewählt werden. Wir erstellen eine neue Datenbank mit Namen „Server_Performance“, alle weiteren Einstellungen lassen wir auf den vorgeschlagenen Standards. Nach Bestätigung des Dialogs wird automatisch eine neue Datenbank angelegt und für die weiteren Schritte in den Assistenten eingetragen.
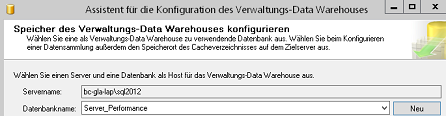
Abbildung 3: Assistent mit Datenbankauswahl /-anlage
Abschließend kann noch ein dedizierter Benutzer oder eine Benutzergruppe der Performance-Datenbank zugeordnet werden. Die Eingabe kann leer bleiben, alle Mitglieder der Serverrolle „sysadmin“ haben bereits vollständigen Zugriff. Ein Klick auf „Fertigstellen“ und schon ist der erste notwendige Schritt zur Konfiguration abgeschlossen; die Datenbank existiert und enthält bereits alle Objekte für die Datensammlung.
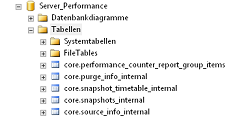
Abbildung 4: Angelegte Objekte
Bereits zu diesem Zeitpunkt hat der SQL-Server die Datenbefüllung und regelmäßige Aktualisierung vorbereitet, zu erkennen an den automatisch angelegten SQL-Agent Aufträgen.
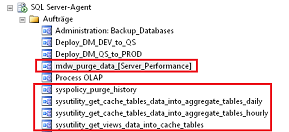
Abbildung 5: Automatische SQL-Agent Aufträge
Bedeutung der einzelnen Aufträge:
- mdw_purge_data_[Server_Performance] = löscht täglich Daten anhand des Ablaufdatums
- syspolicy_purge_history = löscht Reste aus der Ablaufverfolgung
- sysutility_get_cache_tables_data_into_aggregate_tables_daily = Datenverdichtung
- sysutility_get_cache_tables_data_into_aggregate_tables_hourly = Datenverdichtung
- sysutility_get_views_data_into_cache_tables = Datenimport über Materialisierung (alle 15 Min.)
Kommen wir jetzt zu Schritt 2, der eigentlichen Datenerhebung. Die Konfiguration der eigentlichen Datensammelkomponenten erreicht man ebenfalls wieder über das SSMS per rechter Maustaste.
![]()
Abbildung 6: Startassistent Datensammler
SQL-Server unterstützt auch hier wieder mit einem kleinen Dialog. Zunächst muss man den Server und die Zieldatenbank auswählen, zusätzlich kann noch ein separates Verzeichnis zur Zwischenspeicherung der Leistungsinformationen angegeben werden.
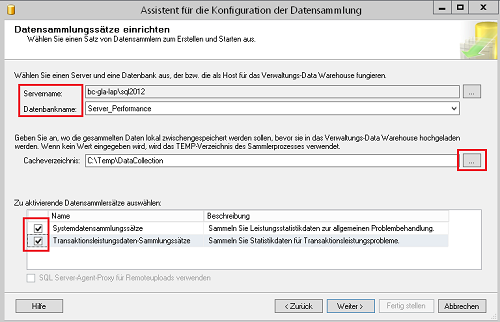
Abbildung 7: Allgemeine Konfiguration
Was versteht Microsoft unter den beiden unterschiedlichen Datensammlersätzen?
- Systemdatensammlungssätze: Informationen zu Abfragestatistiken, Datenträgerverwendung und der Serveraktivität
- Transaktionsleistungsdaten-Sammlungssätze: Nutzungsinformationen zu gespeicherten Prozeduren und Tabellen (T-SQL)
Mit der Bestätigung des Assistenten werden nun die Datensammler generiert und aktiviert. Zusätzlich werden weitere SQL-Agent Aufträge für die Systemsammlungsinformationen angelegt.
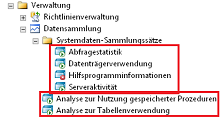
Abbildung 8: Resultierende Datensammler
Das grüne Dreieck zeigt an, dass die Sammler aktiv sind und Daten erheben. Mit der rechten Maustaste kann man einzelne Komponenten deaktivieren, ohne diese gleich löschen zu müssen.
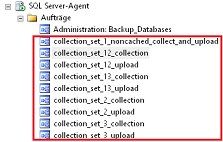
Abbildung 9: Aufträge der Systemdatensammler
Man erkennt, dass zu jedem Systemsammlungssatz zwei SQL-Agent Aufträge gehören. Der SQL-Server differenziert hier zwischen der Sammlung von Leistungsinformationen und der Bereitstellung in der zentralen Datenbank. Versierte Administratoren können so sehr fein auf das jeweilige System angepasste Zeitsteuerungen implementieren, notwendig ist dies aber nicht.
Ergebnis
Nach diesen beiden Konfigurationsschritten ist innerhalb weniger Minuten ein vollständiges Datawarehouse zur Langzeitsammlung von Leistungs- und Aktivitätsinformationen inklusive der zeitgesteuerten Datenbewirtschaftung entstanden.
Nutzen
Das soeben konfigurierte Datawarehouse bietet ab jetzt über die Reportkomponenten einen detaillierten Einblick in die SQL-Server Ereignisse.
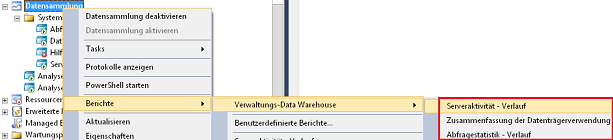
Abbildung 10: Integrierte Statistiken
Die verfügbaren Statistiken und das Vorgehen der Analyse im Zusammenhang mit den Ergebnissen betrachten wir in einem der folgenden Beiträge, da dazu jetzt erst einmal die Sammler ihren Dienst tun müssen.
Tipp: Auch wenn die statistischen Auswertungen vielleicht noch unauffällig sind, werfen Sie gerne einen Blick in die erstellten Datensammler. Sind diese vom Typ „Generic T-SQL Collector“ kann einfach das unter Eingabeparameter verwendete SQL direkt in einer Query ausgeführt werden. Der generierte SQL-Code gibt einen guten Einblick in die Verwendung der Systemtabellen und deren Verknüpfungen.
Fazit
Mit recht kleinem Aufwand kann SQL-Server Informationen selbstständig einsammeln und vorhalten. Solange keinerlei Speicherplatzprobleme auftreten, können automatisch langfristige Informationen für spätere Analyseaufgaben vorgehalten werden, und das ohne Drittsoftware und weitere Kosten. Man ist immer wieder überrascht, was der SQL-Server von Hause aus mitliefert – man muss nur wissen, wo man es findet.
Literatur/Links
Microsoft Developer Network, Datensammlung:
https://msdn.microsoft.com/de-de/library/bb677179(v=sql.120).aspx
Sammlungssatz Zeitpläne:
https://msdn.microsoft.com/de-de/library/bb677210(v=sql.110).aspx
