Bei der multidimensionalen Modellierung gilt es viele Entscheidungen zu treffen. Dabei gibt es oft keine richtige oder falsche Lösung. Daher müssen die Vor- und Nachteile unterschiedlicher Ansätze sorgfältig betrachtet werden, um letztlich einen angemessenen Weg einzuschlagen, d.h. die für die Aufgabenstellung optimale Alternative zu wählen.
Ein typischer Fall ist der Umgang mit Kennzahlen (im OLAP-Fachjargon oft Measures genannt). Im Sinne der Minimaldefinition “Measures sind die eigentlichen Zahlenwerte, die durch Dimensionen näher beschrieben werden” handelt es sich dabei um den Kern einer jeden Business-Intelligence-Anwendung. In der Behandlung dieser zentralen Analyse- und Berichtsobjekte unterscheiden sich jedoch die Philosophien der diversen Technologieanbieter beträchtlich voneinander. In manchen OLAP-Datenbanken existiert kein Unterschied zwischen Dimensionen und Measures, d.h. die Liste der Measures bildet schlichtweg eine weitere Dimension analog zu Zeit, Produkten, Organisation oder Wertart (Ist/Plan).
In anderen Produkten wird zwar bei der Modellierung nicht zwischen Dimensionen und Measures unterschieden, die Kennzahlendimension jedoch typisiert, und die Elemente dieser dadurch speziellen Dimension verfügen über erweiterte Merkmale und Einstellungen – hierzu später mehr. Microsoft dagegen differenziert in Analysis Services grundsätzlich zwischen den beiden Objekten: Dimensionen werden als Stammdaten außerhalb der OLAP-Cubes allgemein modelliert und dann in den Cubes bzw. den darin enthaltenen MeasureGroups verwendet; Measures existieren nur innerhalb ihrer MeasureGroups.
Dieses Konzept ist ein Beispiel unter vielen für die Flexibilität von Analysis Services: Es erlaubt die fallweise Entscheidung über den Umgang mit Kennzahlen. In manchen Situationen wird es sinnvoller sein, die Kennzahlen als Dimension abzubilden und mit einer einzigen “Dummy-Kennzahl” zu arbeiten, in anderen Fällen kann eine umfangreiche Liste von Measures entstehen. Eine Übersicht der Argumente für und wider beider Ansätze sind die Intention dieses Artikels.
Als Beispiel soll ein Ausschnitt aus dem Microsoft-Referenzsystem “FoodMart” dienen. Darin sind neben den Themen Vertrieb und Logistik auch Finanzdaten in Form von Gehaltszahlungen, die pro Filiale und Monat je nach Einsatzbereich auf unterschiedliche Konten gebucht wurden, enthalten. Auch Umsatz und Einstandswerte werden auf entsprechenden Konten verbucht, so dass die Berechnung eines Nettoergebnisses möglich wird:
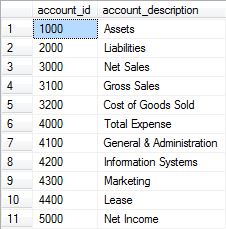
Sollen diese Konten nun als Hierarchie (Dimension) oder als Kennzahlenliste (Measures) abgebildet werden?
Alternative A: Modellierung einer Kontendimension
Die Darstellung der Konten als Dimension hat den grundsätzlichen Vorteil, dass die Repräsentation in Form einer Hierarchie möglich ist und so den Zusammenhang der einzelnen Konten, d.h. die stufenweise Verrechnung der Basiswerte bis hin zu einem Ergebnis, veranschaulicht:
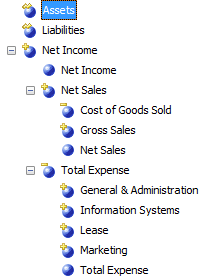
Die Vorteile dieses Ansatzes sind:
- Die hierarchischen Zusammenhänge sind klar erkennbar.
- Vor allem bei Verwendung einer Parent-Child-Struktur sind beliebige Verschachtelungen auch bei Asymmetrie und veränderlichen Strukturen (neue Konten, geänderte Zuordnungen oder Rechenregeln) wartungsfrei abbildbar.
- Über unäre Operatoren oder CustomRollupColumns sind bei Bedarf elementindividuelle Berechnungen möglich (man beachte die kleinen gelben Symbole in den blauen Elementicons in der obigen Abbildung).
Leider ergeben sich auch Nachteile:
- Der Cube enthält lediglich eine Measure, oft schlicht “Saldo” oder “Wert” genannt. Diese Dummy-Measure hat zwangsweise fixe, d.h. für alle Konten identische Eigenschaften. Die wichtigsten hiervon sind auf Datenbankseite der Aggregationsoperator, d.h. die Entscheidung darüber, ob bei der Verdichtung von atomaren Werten z.B. Summen oder Durchschnitte gebildet werden sollen, und im DeltaMaster-Frontend die Additivität (analog zur Aggregation, bestimmt das Verhalten bei abgeleiteten Werten), der BI-Faktor (Markierung für betriebswirtschaftliche positive oder negative Bedeutung) und die Einheit (Stück, Euro etc.).
- Oft ist die Erzeugung von Filterwerten durch den Anwender innerhalb der Anwendung (Analysesitzung) erforderlich, um direkt auf die Werte bestimmter Konten oder Knoten zugreifen zu können.
Alternative B: Modellierung der Konten als Measures
Die Darstellung der Konten erfordert abhängig von der Struktur der bereitgestellten Daten zunächst ein vor allem bei inhaltlichen Änderungen mitunter zeitaufwändiges Transponieren:
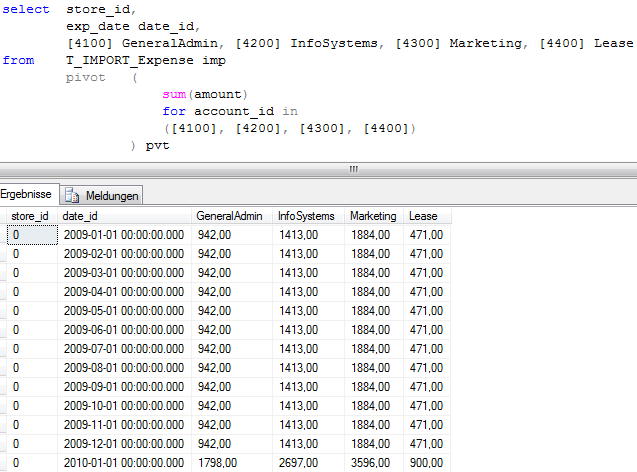
Das Ergebnis sieht dann etwas nüchterner aus, zeigt aber die Zahlenwerte nicht in Kombination mit nur einer Kennzahl, sondern als separate Measures:
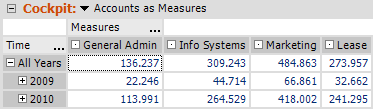
Vor- und Nachteile sind grundsätzlich umgekehrt zu oben skizzierten Kontenlogik. Vor allem der Umstand, dass das benötigte Importformat unter Umständen schwierig zu erzeugen ist (siehe oben: Pivot/Unpivot per SQL; vgl. dazu auch separaten Blogbeitrag) und der damit verbundene Wartungsaufwand bei Änderungen und/oder neuen Kennzahlen sind in vielen Fällen schwerwiegende Argumente gegen diesen Ansatz.
Darüber hinaus fehlen sowohl die abgeleiteten Ergebniskonten. Diese müssen separat und manuell als berechnete Elemente im OLAP-Cube oder in DeltaMaster definiert werden. Die ebenfalls nicht existierende hierarchische Struktur kann in DeltaMaster nachgebildet werden, ist aber ein reines Visualisierungshilfsmittel und unabhängig von der tatsächlichen Aggregationslogik (vgl. dazu DeltaMaster deltas! 5.3.6).
Fazit
Wie so oft existiert kein Königsweg in Form einer allgemeingültigen Präferenz für den einen oder anderen Ansatz. Die hier dargestellten Vor- und Nachteile sollten jedoch im Einzelfall als fundierte Argumentationsgrundlage zur Entscheidungsfindung dienen. Viel Erfolg bei der Anwendung in der Praxis!
Material
Die Beispieldatenbank “AccountsExpenses” für SQL Server / Analysis Services 2005 mit den Daten der in diesem Artikel gezeigten Abbildungen erhalten Sie von uns auf Anfrage selbstverständlich gerne.
