Willkommen zum zweiten Teil des Blogbeitrags über Änderungen von Stammdaten. Wie bereits im ersten Teil angekündigt, werden wir uns heute der Erweiterung der bisher bereits erstellten Transformation widmen. Zunächst ein kleiner Rückblick, was wir schon gemacht haben.
In Teil I haben wir im BI-Development Studio (kurz: BIDS) ein Paket mit einem integrierten Lookup-Task (deutsch: Suche) erstellt. Der Task verglich die Quelldaten bereits mit den vorhandenen Datensätzen in der Zieltabelle auf unserem SQL-Server und mit Hilfe eines kleinen Scripts am Ende des Datenflusses konnten wir neue Datensätze in die Tabelle mit aufnehmen. Darüber hinaus hatten wir den Lookup-Task bereits so konfiguriert, dass die Spalten „Position“ und „Gewicht“ bereits in einer Art „Überwachung“ (im BIDS sprechen wir hier von der Ausgabe für Suchübereinstimmungen) vorgehalten wurden. Zusätzlich hat das SQL-Script dann noch in die Zieltabelle das Importdatum eingetragen bzw. aktualisiert. Das war schon sehr schön, aber wir wollen noch mehr, oder?
Typische Fragen wie: „Wann wurde der Wert denn geändert?“ oder meist noch wichtiger „Was hat sich geändert?“ können wir unseren Kunden so leider noch nicht beantworten. Mit nur ein paar kleinen Änderungen an unserem Importprozess bringen wir auch hier Licht ins Dunkel. Und wie genau? Einfach weiterlesen und mitmachen, es lohnt sich.
Kurz noch einmal zur Datensituation: Uns liegt als .csv Datei der aktuelle Kader des fast neuen deutschen Handballmeisters THW Kiel (Sie sind aktuell noch immer ungeschlagen am 28. Spieltag der Saison mit derzeit 56:0 Punkten!) vor. Ziel soll es nun sein, dass unsere Transformation die Änderungen von Spalteninhalten und zusätzlich neben dem Importdatum auch ein Änderungszeitpunkt mit ausgibt; ein quasi „Abfallprodukt“ davon ist dann sogar eine gesamte Änderungshistorie.
Schauen wir uns jetzt die dafür notwendigen Schritte mal im Detail an. Zum Einsatz möchten wir hier einen neuen, zusätzlichen Transformationstask verwenden, den Conditional Split (deutsch: bedingtes Teilen).
Wir öffnen nun also unser vorhandenes DTSX-Paket, wechseln in die Ablaufsteuerung und ziehen einfach per Drag & Drop aus der Toolbox den Conditional Split Task in das Paket. Nun trennen wir das OLEDB-Ziel T_Import_THW_updates noch vom Lookup Task und setzen an die Stelle den neuen Conditional Split (kurz: Split). Zum Abschluss verbinden wir die freigewordene Ausgabe des Lookups mit dem Split. Unser Paket sollte jetzt wie folgt aussehen:
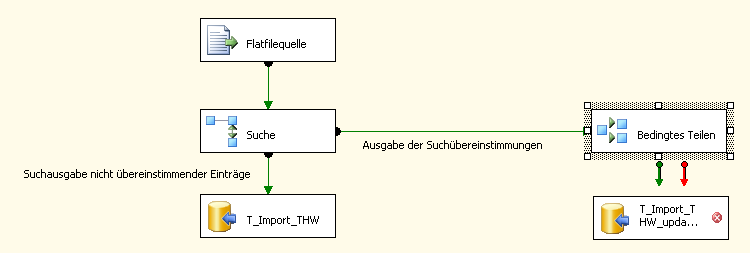
Via Doppelklick auf den Split kommen wir in die Konfiguration des Tasks. Der erscheinende Dialog bietet uns nun in einem 3-geteilten Fenster diverse Einstellungen für die unterschiedlichsten Abfrageprüfungen.
Da wir an dieser Stelle aus diesem Blogbeitrag keine Diashow machen möchten, beschreiben wir nun erst kurz, was für uns zu tun ist. Im Anschluss schauen wir uns dann das Ergebnis an. Ihr könnt natürlich gerne parallel schon einmal den Dialog öffnen.
Wir werden jetzt unserem Ziel entsprechend eine sog. Regel definieren, welche die bereits am Anfang des Artikels erwähnten beiden Spalten auf inhaltliche Änderungen prüft. Dafür ziehen wir uns aus dem oberen linken Bereich aus den Spalten per Drag & Drop die Spalte Gewicht in das untere Fenster an die Stelle Bedingung. Automatisch wird vom BIDS die Reihenfolge auf 1 gesetzt und ein Standardname für die Ausgabe vergeben. An die Bedingung hängen wir nun unseren Vergleichsoperator für „ungleich“ ( != ) und ziehen dann die Vergleichspalte hinzu. Um nun noch die Änderungen für die Spalte „Position“ mit in diese Regel aufzunehmen, ziehen wir uns aus dem rechten, oberen Bereich den Operator für ein logisches OR (Zeichenfolge: ||) dazu und wiederholen den ersten Abschnitt der Konfiguration. Abschließend ändern wir noch den Standardnamen der Ausgabe beispielsweise in „geaenderte Zeilen“. Schauen wir uns jetzt einmal gemeinsam unsere Regel an:

Wie angekündigt, sollten wir uns den gesamten Dialog noch einmal genauer in einer Übersicht anschauen:
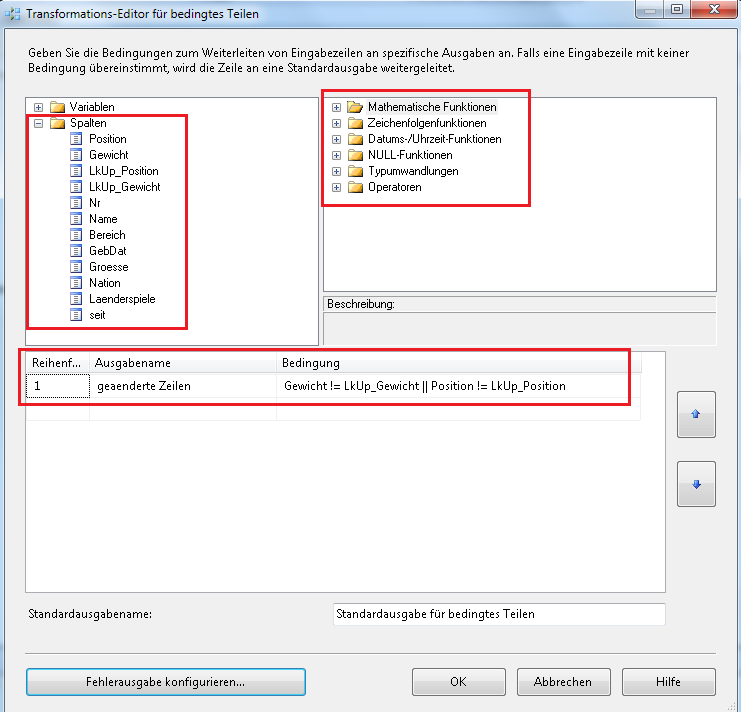
Speziell der rechte, obere Bereich lässt schon erahnen, dass der Split Task eine Vielzahl von Regeleinstellungen zulässt. Beispielsweise lassen sich mit dem logischen AND Operator Prüfungen auf Feldkombinationen verwirklichen oder mit den Datumsfunktionen direkt ein Zeitintervall zwischen zu ladendem Quell- und Zieldatensatz als Kriterium für ein Update festlegen. Hier empfehlen wir: einfach mal durchstöbern.
Zurück zu unserer Transformation. Zum Abschluss der Konfiguration ziehen wir nun die Ausgabe des Split auf unser freigewordenes OLEDB-Ziel T_Import_THW_updates. In dem sich öffnenden Kurzdialog wählen wir einfach die zuvor von uns mit Namen belegte Ausgabe der geänderten Zeilen und bestätigen dies mit OK.
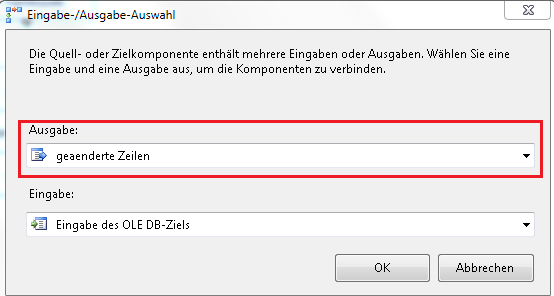
Damit ist die Konfiguration unseres Conditional Splits abgeschlossen. Sind wir jetzt wirklich schon fertig?
Nicht ganz, wir haben ja noch das „Abfallprodukt“ einer Änderungshistorie erwähnt. Dafür legen wir uns einfach auf Basis der T_Import_THW_updates per Script eine weitere Tabelle T_Import_THW_updates_history an. Anschließend nehmen wir noch ein paar kleinere Anpassungen an unserem bereits in Teil I erstellen SQL-Scripts vor und schon entsteht in dieser Tabelle unsere Historie, und das ganz von allein
Nun zum Ergebnis:
Führen wir also unser Projekt jetzt einmal aus – natürlich haben wir vorher in unserer Quelldatei diverse Änderungen vorgenommen.
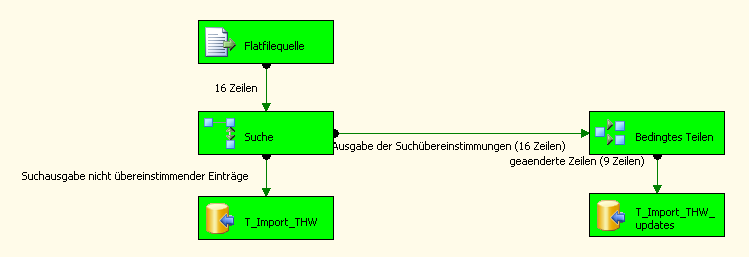
Wer jetzt genau die Änderungen nachvollziehen will, der schaut einfach mal in die Historientabelle T_Import_THW_updates_history…
Und?
Schon genial, oder? Wir hoffen, es hat Spaß gemacht, und freuen uns auf das nächste Mal.
