Heute möchten wir uns einmal mit einer sehr nützlichen T-SQL-Funktion namens CHECKSUM() beschäftigen. An einem Beispiel aus dem Datenladeprozess soll gezeigt werden, wie dieser durch die Verwendung von CHECKSUM() schneller und eleganter gestaltet werden kann.
Wir Modellierer kennen aus unserer täglichen Praxis eine häufig mangelhafte Datenqualität, egal in welcher Form die notwendigen Daten bereitgestellt werden. Gerade in Workshop-Situationen, in denen sehr schnell eine Vielzahl an Kundenwünschen implementiert werden muss, können wir nicht immer einen perfekten ETL-Prozess erwarten. Geht es dann auch noch um Themen wie eine inkrementelle Datenlade-Logik bei großen Datenvolumina, bei der die Rohdaten aber nicht per eindeutigem Schlüssel gefunden werden können, hilft man sich oft mit einer differenzierten JOIN-Bedingung (X=X AND Y=Y AND Z=Z etc.). Das funktioniert grundsätzlich auch sehr gut. Allerdings kann dies die Abfrageperformance negativ beeinflussen, und das gilt es zu vermeiden.
Kleiner Exkurs bezüglich der Delta-Logik:
Wir benötigen zwei strukturgleiche Tabellen: eine als Archivtabelle, eine für die täglichen Importdaten. Als Beispiel wird die Kundentabelle aus der Foodmart-Demodatenbank verwendet. Mittels eines SSIS-Pakets löschen wir zu Beginn den Inhalt der Tabelle customer_CS_updates und importieren anschließend die neuen Daten aus dem Vorsystem (z. B. SAP) in diese. Nach erfolgreichem Import sorgen wir mit einem kleinen SQL-Ausdruck für den Datentransfer von customer_CS_updates nach customer_CS (dient als Archivtabelle). Dazu löscht man alle Datensätze, die sich aktuell in der Tabelle customer_CS_updates befinden aus customer_CS und fügt anschließend alle Datensätze der Tabelle customer_CS_updates in die Archivtabelle ein. Der Löschvorgang ist notwendig, weil der Import auch Datensätze enthalten kann, welche bereits importiert wurden (z. B. nachträgliche Korrekturbuchungen in einem ERP-System).
--Löschen aktualisierter Daten in der Archivtabelle DELETE archiv FROM [dbo].[customer_CS] archiv INNER JOIN dbo.customer_CS_updates upd ON archiv.lname = upd.lname AND archiv.fname = upd.fname AND archiv.city = upd.city GO --Einfügen neue Datensätze INSERT INTO [dbo].[customer_CS] SELECT * FROM dbo.customer_CS_updates GO
Eine Optimierung der Ausführungszeiten für das Löschen und Einfügen der Datensätze können wir mittels Prüfsummen (engl.: Checksum) erzielen, vor allem dann, wenn zur Datensatzidentifizierung mehrere alphanumerische Spalten benötigt werden.
Der Befehl CHECKSUM() existiert bereits seit SQL-Server 2005 und liefert eine Prüfsumme vom Datentyp INT zurück. Dabei kann * als Platzhalter für alle Spalten einer Tabelle oder Sicht, wie auch einer oder mehrerer dedizierter Spalten, verwendet werden. Entwickelt wurde die Funktion, um Hashindizes (Index auf einer CHECKSUM()-Ergebnisspalte) für Gleichheitssuchen erstellen zu können. Einzige Einschränkung hinsichtlich der sinnvollen Verwendung der Funktion ist, dass für die Datentypen „text“, „ntext“, „image“, „cursor“ und „xml“ keine Prüfsumme ermittelt wird. Diese Spalten fließen nicht in die Berechnung der Prüfsumme mit ein.
Nachfolgend wird der Prozess der Delta-Ladelogik genauer untersucht und gezeigt, wie der Einsatz von CHECKSUM() diesen positiv beeinflusst.
--Tabelle für Delta-Importe erzeugen (fiktiv) --SELECT * INTO dbo.customer_CS_updates FROM [dbo].[customer_CS] --Löschen aktualisierter Daten in der Archivtabelle DELETE archiv FROM [dbo].[customer_CS] archiv INNER JOIN dbo.customer_updates upd ON archiv.lname = upd.lname AND archiv.fname = upd.fname AND archiv.city = upd.city GO
Schauen wir uns einmal den Ausführungsplan an:
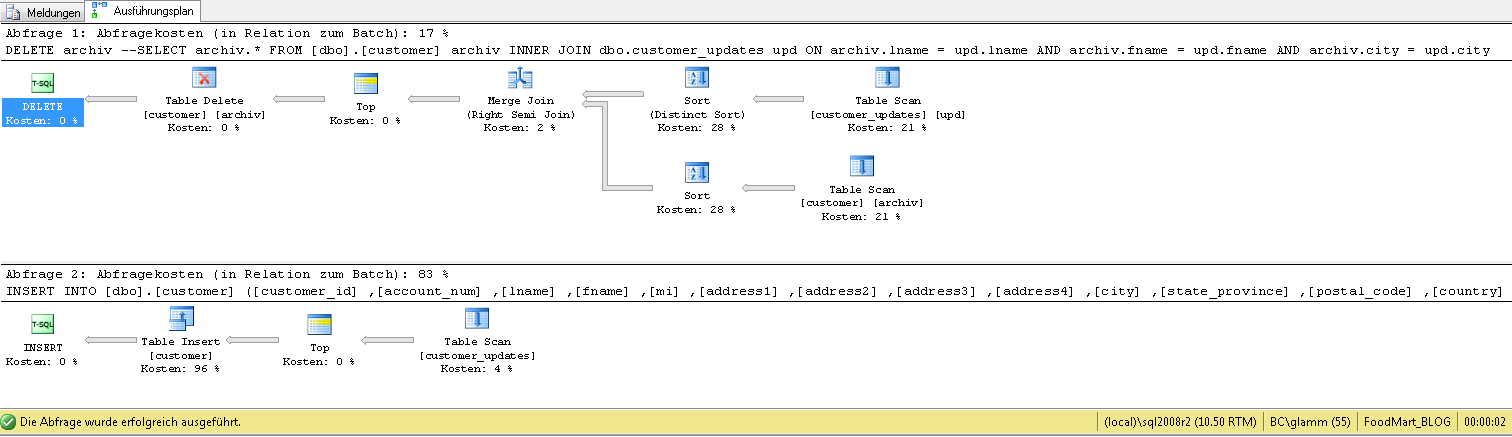
Abb. 1: Ausführungsplan
Man erkennt, dass im oberen Teil für das DELETE-Statement der größte Aufwand bei der Sortierung und dem notwendigen Tabellen-Scan verwendet wird, beim INSERT-Statement aber der eigentliche Batchprozess der Aufwandtreiber ist. Setzen wir für das DELETE in der JOIN-Definition die Prüfsumme ein:
--Löschen aktualisierter Daten in der Archivtabelle DELETE archiv FROM [dbo].[customer_CS] archiv INNER JOIN dbo.customer_updates upd ON CHECKSUM(archiv.lname, archiv.fname, archiv.city) = CHECKSUM(upd.lname, upd.fname, upd.city) GO
Jetzt protokolliert der SQL-Server folgenden Ausführungsplan:

Abb. 2: Ausführungsplan CHECKSUM()
Augenscheinlich ist jetzt die Löschanweisung langsamer, da zusätzlich noch sog. Hash-Matches ausgeführt werden müssen. Man beachte aber auch, dass die eigentliche DELETE-Anweisung nun knapp 1/3 der Kosten benötigt, vorher gingen diese gegen 0. Das bedeutet, dass das Löschen jetzt besser verwaltet wird.
Erweitern wir nun die Tabelle um die Prüfsumme und legen einen Index auf diese, sollte das Ergebnis eindeutiger werden:
--Materialisieren der Prüfsumme ALTER TABLE [dbo].[customer_CS] ADD CS_Customer AS CHECKSUM(lname, fname, city) GO --Erstellung Hash-Index CREATE INDEX CS_Customer_index ON [dbo].[customer_CS](CS_Customer) GO
Schauen wir uns den Ausführungsplan in Abb. 2 im Vergleich zu Abb. 3 an, lässt sich erkennen, dass jetzt das Löschen 90% des gesamten Aufwands für den SQL-Server verbraucht, obwohl der Server einige Operationen zusätzlich ausführen muss.

Abb. 3: Ausführungsplan CHECKSUM() Index
Das ist eine deutlich gesteigerte Effizienz.
Man kann jetzt natürlich argumentieren, dass jeder Index auf einer Tabelle zur besseren Performance führt, und das ist auch (meistens) korrekt. Aber selbst Microsoft schreibt, dass bei langen Schlüsseln (Indizes) der Hashindex der Leistungsfähigere ist. Zugegeben, in diesem Beispiel mit ca. 10.000 Datensätzen wird sich kaum ein Unterschied feststellen lassen. Auf wirklich großen Datenmengen sieht das schon ganz anders aus.
Achtung: Es kann gelegentlich vorkommen, dass sich bei Änderung eines Wertes innerhalb der Parameterliste von CHECKSUM() nicht die Prüfsumme ändert. Dieses Verhalten ist im April 2006 von Microsoft bekannt gegeben worden. Daher wird davon abgeraten, die Funktion für die Prüfung auf geänderte Daten zu verwenden. Dazu sollten besser sog. Hashbytes() verwendet werden.
Eine nützliche Erweiterung der Funktion CHECKSUM() ist BINARY_CHECKSUM(). Diese wiederum gibt die binäre Prüfsumme für die angegebene(n) Spalte(n) zurück. Damit kann beispielsweise auch die Groß-/Kleinschreibung von Zeichenketten unterschieden werden, deshalb eignet sich
BINARY_CHECKSUM() durchaus für die Prüfung von Feldänderungen.
--Case-Sensitivität
SELECT
'CHECKSUM' AS Beispiel
,CHECKSUM('DeltaMaster') AS DeltaMaster
,CHECKSUM('Deltamaster') AS Deltamaster
UNION ALL
SELECT
'BINARY_CHECKSUM' AS Beispiel
,BINARY_CHECKSUM('DeltaMaster') AS DeltaMaster
,BINARY_CHECKSUM('Deltamaster') AS Deltamaster
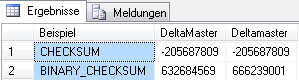
Abb. 4: Beispiel CHECKSUM() und BINARY_CHECKSUM()
Der Vollständigkeit wegen sei hier eine weitere Abwandlung der Prüfsummen-Funktion erwähnt, nämlich CHECKSUM_AGG(). Diese Funktion ermittelt auf ganzzahligen Quellspalten die Prüfsumme und kann ebenfalls zur Nachverfolgung von Wertänderungen verwendet werden. Der einzige Unterschied in der Verwendung gegenüber den obigen Beispielen liegt darin, dass durch Angabe von DISTINCT oder ALL (Standard) die Ermittlung auf entweder nur die unterschiedlichen oder aber auf alle Werte angewendet werden soll. Allerdings sollte man damit vorsichtig sein, denn sobald es innerhalb der auszuwertenden Spalte sehr wenige unterschiedliche Werte gibt, kann das Ergebnis der Prüfsumme in vielen Fällen 0 sein. Dabei würde eine Änderung von beispielsweise 0 auf 1 nicht anhand der Prüfsumme erkannt werden.
--Vorsicht bei CHECKSUM_AGG SELECT num_cars_owned AS Anzahl_Fahrzeuge ,CHECKSUM_AGG(CAST(num_cars_owned AS INT)) AS CHECKSUM_AGG FROM dbo.Customer GROUP BY num_cars_owned GO
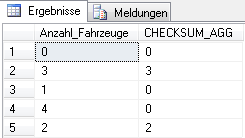
Abb. 5: Beispiel CHECKSUM_AGG()
Ein ähnliches Verhalten kann man auch bei CHECKSUM() und BINARY_CHECKSUM() feststellen. Hier kann man sich aber mit expliziten Konvertierungen oder Konkatenation der Spalten behelfen, um eineindeutige Prüfsummen zu erhalten.

Abb. 6: Beispiel mit Fehlern für CHECKSUM() und BINARY_CHECKSUM()
Man kann gut erkennen, dass bei reiner Konvertierung der Werte von INT nach VARCHAR die Prüfsummen nur leicht abweichend sind, die Kombination mit einer Konkatenation mittels einer Konstanten aber zu einem eindeutigeren Ergebnis führt.
Zum Schluss sollen die weiter oben angesprochenen Hashbytes() kurz erläutert werden. Letztendlich ist auch dies eine abgewandelte Prüfsummen-Funktion, welcher man aber mittels Parameter einen Berechnungsalgorithmus und Werte übergeben kann. Gültige Hashalgorithmen sind:
MD2 | MD4 | MD5 | SHA | SHA1 | SHA2_256 | SHA2_512
Der Rückgabewert ist vom Datentyp VARBINARY.
Wenden wir jetzt einmal die HASHBYTES() auf die gleiche Kombination aus Filiale und Customer an, bekommen wir einen eindeutigen Wert für die Kombination zurück (Hinweis: Die Funktion kann nicht auf Spalten vom Datentyp INT direkt angewendet werden).
--explizite Konvertierung und Verwendung der Hashbytes-Funktion
SELECT
store_id AS Filiale
,customer_id AS Customer
,HASHBYTES('MD5', convert(nvarchar,customer_id) + convert(nvarchar,store_id) ) AS 'HASHBYTES'
,BINARY_CHECKSUM(customer_id, store_id) AS 'BINARY_CHECKSUM'
FROM
dbo.sales_fact_2008
WHERE
customer_id in ('7356', '7357')
GROUP BY
customer_id, store_id
Das Ergebnis:

Abb. 7: Beispiel HASHBYTES()
Die aus den HASHBYTES() zurückgelieferte Prüfsumme lässt sich sehr gut für die Berechnung einer DistinctCount-Kennzahl verwenden, wenn diese z. B. aus alphanumerischen oder zusammengesetzten Spalten abgeleitet werden muss. Hierbei kann man sich sicher sein, dass auch wirklich alle Unterschiede ermittelt werden.
--Beispiel eines DistinctCount
SELECT
count(DISTINCT BINARY_CHECKSUM(lname, city)) AS 'Anzahl eindeutige Nachnamen je Land'
FROM
dbo.customer
Die HASHBYTES() werden oft auch in Verbindung mit symmetrischen oder asymmetrischen Datenverschlüsselungen verwendet, doch damit beschäftigen wir uns beim nächsten Mal.
Wie wir gesehen haben, bietet der bedachte Einsatz von Prüfsummen eine Reihe von Möglichkeiten hinsichtlich Abfrageoptimierungen, Datenänderungen und Datenverschlüsselung. Wenn aber der Datentyp INT mit ins Spiel kommt, empfehle ich dringend den Einsatz der HASHBYTE-Funktion.
Nützliche Links:
