Microsoft Analysis Services erlaubt die flexible Modellierung von Dimensionen und Hierarchien durch die beliebige Kombination von Attributen. In bestimmten Fällen können dabei unerwünschte Effekte entstehen – bis hin zu einer scheinbar fehlerfrei erzeugten und verarbeiteten Datenbank, die aber falsche Datenwerte liefert. Dieser Blogbeitrag liefert einen Blick hinter die Kulissen.
Microsoft Analysis Services ist eine der mächtigsten OLAP-Datenbanken auf dem Markt. Seit Erscheinen der Version 2005, also inzwischen in vierter Generation, gilt das Paradigma der attributbasierten Modellierung: Dimensionen können nicht nur aus einer Hierarchie bestehen, sondern beliebig viele zunächst voneinander unabhängige Merkmale (Attribute) enthalten, die darüber hinaus zu beliebig vielen Hierarchien kombiniert werden können.
Die Datenhaltung, d. h. die physische Speicherung von Basisdaten und (Zwischen-)Summen, erfolgt dabei – im Übrigen genauso wie die Administration von Berechtigungen – stets auf Attributebene. Hierarchien sind demnach eher virtueller Natur. Microsoft unterscheidet in seinen Dokumentationen (empfohlen sei hier einmal mehr der „Analysis Services Performance Guide“) zwischen natürlichen und benutzerdefinierten Hierarchien.
- Natürliche Hierarchien sind solche, zwischen deren Ebenen (Quellattributen) ausschließlich 1:n-Beziehungen bestehen. Einfachstes Beispiel dafür ist eine Zeithierarchie aus den Ebenen Jahr, Quartal, Monat und Tag: Jedes Element hat einen eindeutigen Vorgänger auf der nächsthöheren Ebene, d. h. jeder Tag kann exakt einem Monat zugeordnet werden, jeder Monat seinem Quartal, jedes Quartal genau einem Jahr. In der dem OLAP-System zugrundeliegenden relationalen Datenbank wird dieser Idealfall durch ein Snowflake-Schema mit normalisierten Dimensionstabellen und entsprechenden Constraints abgebildet.
- Benutzerdefinierte Hierarchien entstehen durch die Kombination von Attributen, zwischen denen keine eindeutig hierarchischen Beziehungen bestehen. Microsoft erlaubt die Abbildung in dieser Form bewusst, um individuellen Anforderungen, z. B. hinsichtlich vorgegebener Navigations-/Drill-down-Pfade, gerecht werden zu können. Es entstehen dadurch keine Fehler bei der Verarbeitung, d. h. dem Laden der Daten aus den Quelltabellen in den OLAP-Würfel. Allerdings ist bei der Modellierung unter Verwendung der Microsoft-Bordmittel genau zu bedenken, welche Auswirkung unterschiedliche Konstellationen haben.
DeltaMaster Modeler (DMM) unterscheidet daher zwischen der primären Hierarchie, für die ein Snowflake-Ast gebildet wird, und zusätzlichen Attributen bzw. Hierarchien. Innerhalb der primären Hierarchie besteht die Sicherheit, dass etwaige Fehleinschätzungen hinsichtlich der Ebenenstruktur und/oder inkonsistente Daten spätestens bei der relationalen Datentransformation zu Fehlern führen und nachvollziehbar dokumentiert werden. Der häufigste Fall wird „Kind mit mehreren Vätern“ genannt und tritt z. B. in einer geographischen Kundenhierarchie „Land-Bundesland-Stadt-Kunde“ auf, wenn im Vorsystem für einen Nürnberger Kunden versehentlich das Bundesland Baden-Württemberg eingetragen wird. Bei Modeler-Standardeinstellungen tritt der SQL-Fehler 4 (doppelter Schlüssel) auf. Zur Problembehebung müssen entweder die Rohdaten korrigiert oder die Modeler-Einstellungen geändert werden, indem im Bericht „Level Source Columns“ nur „Insert KEY“ und „Insert Update“ aktiviert wird. Dies führt dazu, dass eine SQL-Prozedur erstellt wird, die zunächst per INSERT nur die eindeutigen Schlüssel in die Dimensionsebene einträgt – im obigen Fall die Stadt Nürnberg also nur einmal. Anschließend trägt diese Prozedur per UPDATE den ersten (!) ermittelten Vorgänger in die Fremdschlüsselspalte ein, die den Bezug zur nächsthöheren Hierarchieebene herstellt – im obigen Fall dummerweise den falschen, da Baden-Württemberg alphabetisch vor Bayern liegt! Das SQL-Kommando ist leicht vorstellbar: Die Gruppierung erfolgt nach dem Schlüssel (GROUP BY Stadt) und der Vorgänger wird durch MIN(Bundesland) ermittelt. Durch die ebenenweise Verarbeitung von der Gesamtsumme bis zur detailliertesten Ebene werden also alle Nürnberger Kunden dem falschen Bundesland zugeordnet. Ein inhaltlich hoher Preis für einen technisch fehlertoleranten Prozess. Daher ist diese Einstellung in produktiven Systemen selbstredend nicht zu empfehlen.
Diese Details sind hier deshalb nochmals ausführlich beschrieben, weil sich Microsoft Analysis Services bei manueller Modellierung mit Business Intelligence Development Studio (BIDS) genauso verhält wie DMM. Das Verständnis dazu ist wichtig, wenn mit dem Bordmittel BIDS gearbeitet werden muss oder mit DMM benutzerdefinierte Hierarchien (Additional Hierarchies) erstellt werden.
Es folgt ein konkretes Beispiel, abstrahiert aus dem verzweifelten Hilferuf meines Hauptkunden vor wenigen Tagen:
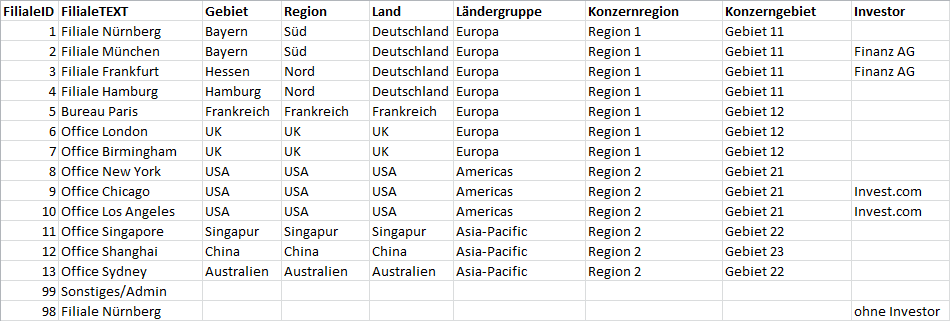
Abb. 1: Beispieldaten meines Hauptkunden
Drei Details fallen ins Auge, die für BC-Consultants mit DeltaMaster Modeler jedoch unproblematisch sind:
- Die Filialen 98 und 99 enthalten sehr wenige Angaben und müssen in einen Dummy-Zweig eingeordnet werden.
- Nur wenige Filialen gehören einem externen Investor.
- Der Text „Filiale Nürnberg“ wurde doppelt vergeben (FilialeIDs 1 und 98).
Die folgenden Hierarchien sollen gebildet werden:
- Organisation: Ländergruppe – Land – Region – Gebiet – Filiale (ID/TEXT) [primäre DMM-Hierarchie]
- Konzernstruktur: Konzernregion – Konzerngebiet – Land [Additional Hierarchy]
- Filialgruppen: Investorenland – Investor – Filialname [Additional Hierarchy]
Das erschreckende Resultat nach korrekter Parametrierung in DeltaMaster Modeler und erfolgreichem Create/Transform/Deploy/Process sieht jedoch wie folgt aus:
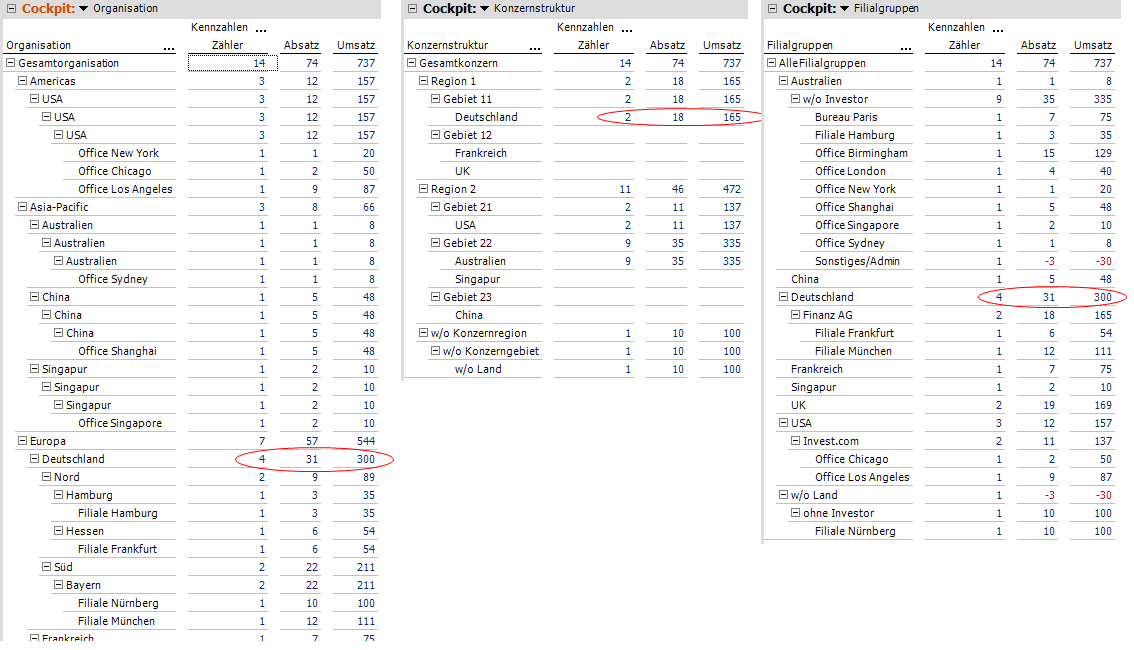
Abb. 2: Fehlerhaftes Ergebnis nach korrekter Parametrierung in DMM
Die primäre Hierarchie „Organisation“ zeigt die korrekte Zwischensumme z. B. für Deutschland; die Additional Hierarchy „Konzernstruktur“ dagegen weist abweichende Zahlen für dasselbe Attribut aus!
Ein Blick in BIDS auf die von DeltaMaster Modeler erstellten Attributbeziehungen zeigt keine Fehler oder Warnungen:
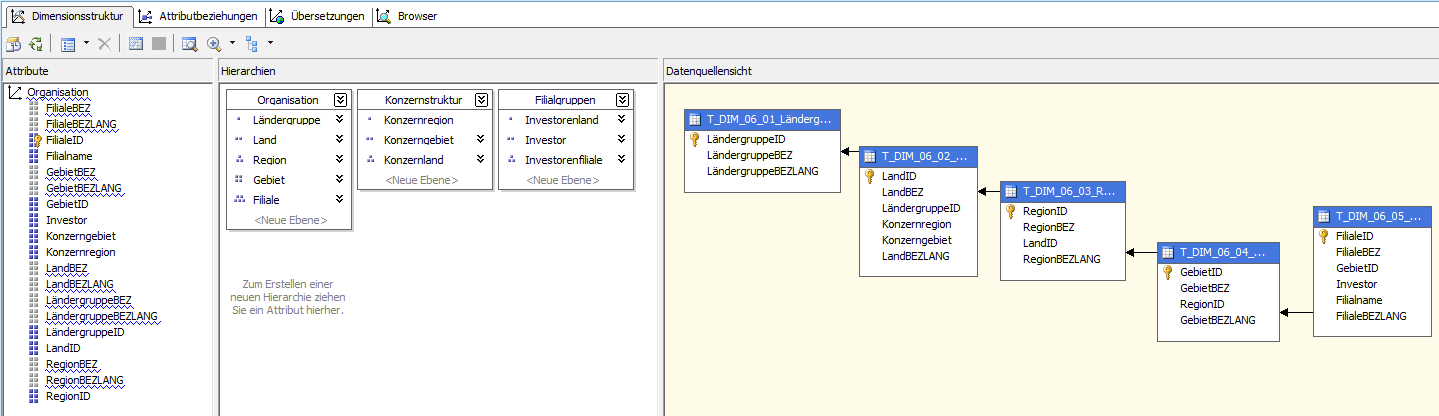
Abb. 3: Dimensionsstruktur im BIDS

Abb. 4: Attributbeziehungen im BIDS
Daher wird per SQL der Zusammenhang zwischen den potenziell problematischen Attributen Filialname, Investor und LandID anhand deren konkreter Ausprägungen geprüft:
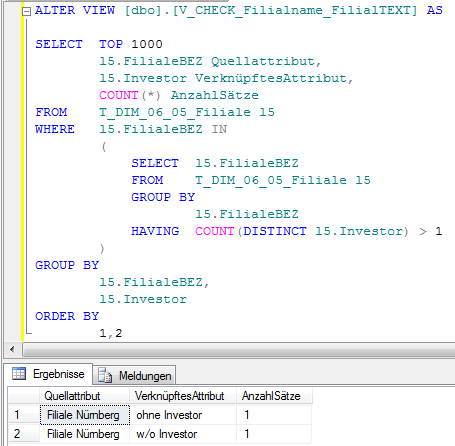
Abb. 5: SQL-Prüfung für Attribut Filialname
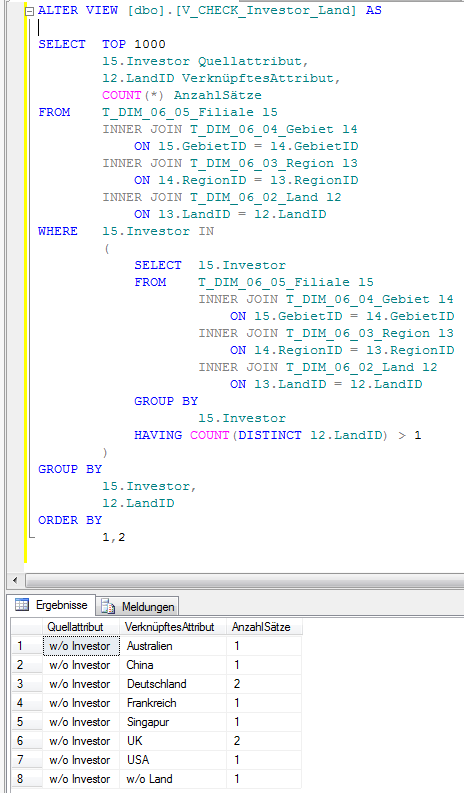
Abb. 6: SQL-Prüfung für Attribute Investor und Land
Streng genommen liegen demnach zwei Probleme vor, interpretierbar wahlweise als Datenschmutz, Versäumnis im ETL-Prozess oder Fehlentscheidung in der Modellierung:
- Wenn Filialnamen zu unterschiedlichen IDs mehrfach vorkommen können, ist das für die primäre Hierarchie bei DMM-Defaulteinstellung „Levels.NameUsage=Attribute“ kein Problem, da die Spalte FilialeTEXT nur als deaktiviertes Textattribut erzeugt wird, um in DeltaMaster als Alias zur Verfügung zu stehen. Bei Umstellung auf „NameUsage=Name“ würde bereits hier beim Transform-Vorgang der oben erwähnte SQL-Fehler 4 auftreten. Keinesfalls darf jedoch die Spalte FilialeTEXT zusätzlich als (aktives) Attribut in einer Hierarchie verwendet werden. Die inhaltliche Inkonsistenz führt dann zwar während der Verarbeitung zu keinem Fehler, aber zur Bildung falscher Zwischensummen auf höheren Ebenen (Investor, Land)!
- Wenn nicht alle Filialen externen Investoren gehören, setzt Modeler einen Defaultwert ein. Dieser gilt jedoch im Falle der hier definierten Hierarchie landesübergreifend, sodass der eingangs beschriebene „Kind-mit-mehreren-Vätern“-Effekt eintritt und der Dummy-Investor „w/o Investor“ dem alphabetisch ersten Vater „Australien“ zugeordnet wird. Ergebnis: Die Umsätze aller Filialen ohne Investor werden nicht ihrem eigentlichen Land, sondern Australien zugeschlagen!
Übrigens meldet BIDS bei Umstellung der Fehlerkonfiguration (DMM-Default: Dimension. ErrorConfiguration=Standard) auf eine geringere Toleranz (UserDefined, KeyDuplicate=ReportAndStop) brav den vorliegenden Fehler. Umso wichtiger ist es also zu bedenken, dass dieser Fehler bei Verwendung von Deltamaster Modeler nicht auftritt und die Probleme daher höchstwahrscheinlich zunächst unbemerkt bleiben.
Erfahrene Experten mögen nun sagen, dass es sich hierbei um triviale Erkenntnisse handelt. Was für alle Beteiligten im konkreten Supportfall jedoch neu war, ist die Beobachtung, dass nicht nur die Hierarchie, die das fehlerverursachende Attribut enthält, falsche Daten zeigt, sondern mitunter auch weitere Hierarchien.
Beispielsweise entsteht nach der Korrektur des augenscheinlichen Problems (d. h. FilialeTEXT aus der Hierarchie Filialgruppen entfernen oder durch FilialeID ersetzen) ein neues, aber nicht minder unbefriedigendes Ergebnis:
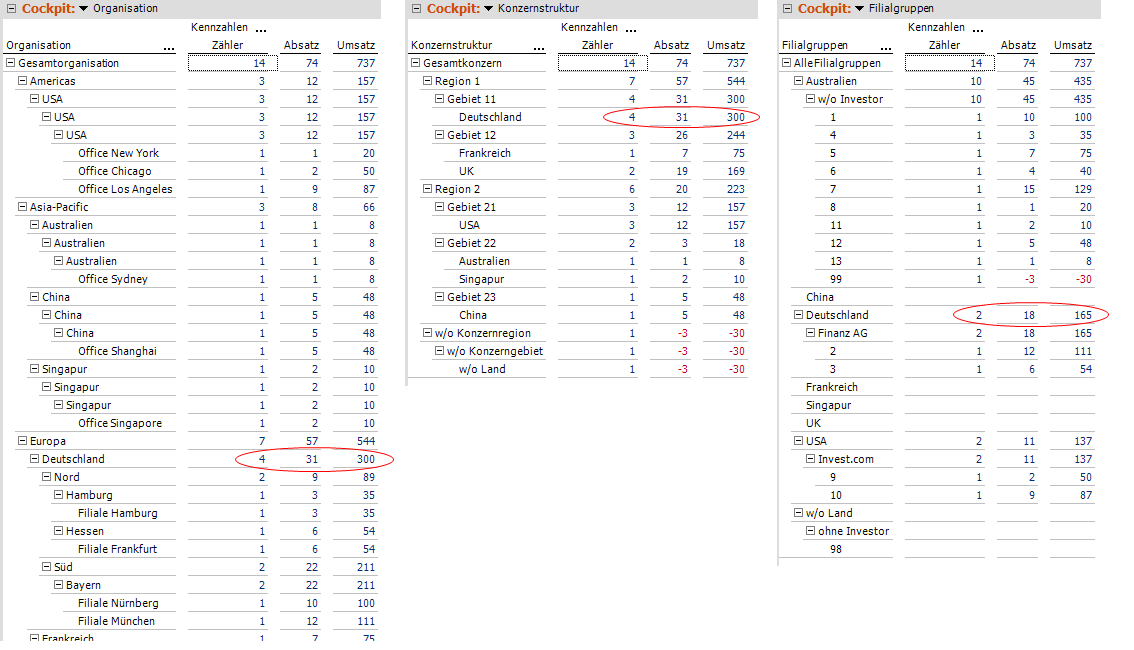 Abb. 7: Weiterhin fehlerhaftes Ergebnis; diesmal in der Hierarchie Filialgruppen
Abb. 7: Weiterhin fehlerhaftes Ergebnis; diesmal in der Hierarchie Filialgruppen
Nun sind die Werte für Deutschland in Organisation und Konzernstruktur identisch und korrekt, aber in der Filialgruppen-/Investorenhierarchie falsch und zudem scheinbar inkonsistent, da nicht additiv.
Im Falle unseres Kunden wurden sogar gleichzeitig in mehreren Additional Hierarchies falsche Werte angezeigt. Der Lerneffekt aus diesem Fall ist also einmal mehr: Vorsicht bei der Hierarchiebildung mit nicht zweifelsfrei eindeutigen Stammdaten!
Die kompletten Beispieldaten zu diesem Blogbeitrag sind im Blog-Archivordner verfügbar. Kunden und Businesspartnern stellen wir sie auf Anfrage gerne zur Verfügung.
