Im letzten Blogbeitrag „Fortlaufend und eindeutig“ wurde die Identitätsfunktion in SQL-Server detailliert betrachtet und ein Anwendungsbeispiel mit verschiedenen Auffälligkeiten beschrieben. In diesem Blogbeitrag wird jedoch ein alternatives Konzept näher erläutert. Seit SQL-Server 2012 bietet das Datenbankmodul ein Objekt namens Sequenz. Was genau eine Sequenz auszeichnet, wofür diese verwendet werden und welche Einschränkungen existieren, wird an dem konkreten Beispiel einer Umstellung von Eingabetabelle mit Identitätseigenschaft zu einer Sequenztabelle verdeutlicht.
Allgemeines
Wie dem Abschnitt weiterführende Links und dem MSDN zu entnehmen ist, sind Sequenzen ein schemagebundenes Objekt, welches numerische Werte generiert. Start- und Endwerte sowie das zu verwendende Inkrement sind benutzerdefiniert steuerbar. Also doch ein Äquivalent zu der Identitätseigenschaft? Nein, denn:
- Sequenzen sind nicht direkt an eine Tabelle gebunden, sie gelten datenbankweit
- Eine Sequenz kann von verschiedenen Tabellen verwendet werden
- Mit der Funktion NEXT VALUE FOR kann die nächste Sequenznummer VOR einer INSERT-Operation abgefragt werden
- Sequenznummern können über separate Spalten auf- oder absteigend sortiert werden
Die allgemeine Syntax für die Erstellung einer Sequenz ist (möglich ist jeder ganzzahlige Datentyp):

CREATE SEQUENCE dbo.SEQ_LieferantenID
AS TINYINT
START WITH 1 --optional, Default startet mit 1
INCREMENT BY 1 --muss ganzzahlig sein
MINVALUE 1 --optional
MAXVALUE 100 --optional
CYCLE --optional, Default ist NO CYCLE
--(= bei Erreichen von MAXVALUE oder Ende des
Datentyps wird eine Ausnahme ausgelöst)
CACHE --optional, Default ist CACHEHinweis: das Präfix SEQ_ ist lediglich eine Empfehlung, sollte bei Verwendung unterschiedlicher Sequenzen in einer Datenbank einheitlich sein!
Der Parameter CACHE dient der Performancesteigerung, beeinflusst direkt die Speicherverwaltung. Im Cache wird nur der aktuelle und die verbleidende Anzahl freier Sequenznummern zwischengespeichert. Achtung! Wird SQL-Server unerwartet heruntergefahren geht die Information verloren. Um das Risiko zu minimieren kann eine Sequenz mit der Option NO CACHE erstellt werden.
Nach der Erstellung einer Sequenz ist diese in der ausgewählten Datenbank unter Programmierbarkeit – Sequenzen zu finden.
Abbildung 1: Sequenzen in Objektexplorer des SSMS
Alternativ können vorhandene Sequenzen und deren aktuelle Konfiguration über das Systemobjekt sys.sequences abgefragt werden.
Wann verwenden?
Die Verwendung von Sequenzen bietet sich immer dann an, wenn ein Wert „vorreserviert“ werden soll, noch bevor der Datensatz in der Tabelle gespeichert wird. Gleiches gilt, wenn ein Schreibvorgang mehrere Nummern vor der Vergabe für parallele Schreibprozesse „sichern“ muss, z. B. bei der Erfassung von Belegkopf und –positionen. Möglich ist dies durch die Systemfunktion sp_sequence_get_range.
Einschränkungen
Die wichtigsten Einschränkungen sind:
- Sequenznummern sind nicht in Transaktionen gekapselt, dies kann in seltenen Fällen zu Lücken in der automatischen Nummerierung führen
- Sequenznummern können nicht in temporären Tabellen verwendet werden
Weitere Details sind den Beispielen im MSDN oder den Links zu entnehmen.
Fallbeispiel
Ausgangslage
In dem Beispiel soll eine Stammdatentabelle mit Lieferanteninformationen von einer Identitätsspalte auf die Verwendung einer Sequenznummer umgestellt werden. Dabei ist zu beachten, dass die bestehenden Inhalte übernommen, die LieferantenID harmonisiert und die Bewegungsdaten entsprechend angepasst werden sollen.
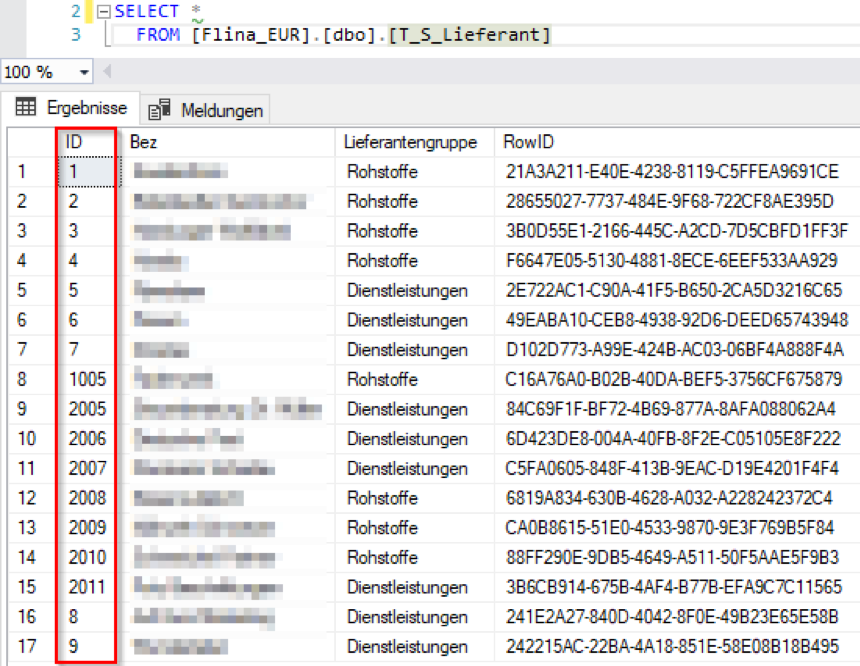
Abbildung 2: aktueller Stand Lieferantentabelle
Man erkennt bereits, dass die bestehende LieferantenID nicht fortlaufend ist, die Identitätsspalte ID bereits durch unerwartete Systemneustarts beeinflusst wurde (Ursache siehe Blogbeitrag „Fortlaufend und eindeutig“). Das soll korrigiert werden.
Schritte zur Umstellung
Folgende Schritte müssen für die gewünschte Umstellung vorgenommen werden:
-
- Entfernen der Identitätseigenschaft auf der Spalte ID
Dankenswerterweise hilft hier DeltaMaster ETL:

EXEC dbo.P_BC_Remove_IdentityFromColumn @TableName = 'T_S_Lieferant' -- varchar(150) ,@ColumnName = 'ID' -- varchar(128)Die Prozedur sichert die Daten temporär, löscht und erstellt die Spalte ID neu und stellt die gesicherten Daten OHNE Identitätseigenschaft wieder her.
- Neunummerierung der bestehenden Datensätze in den Stamm- und Bewegungsdaten
Benötigt werden hier 2 Update-Statements. WICHTIG: erst die Bewegungs- und danach die Stammdaten aktualisieren! Eventuell vorhandene Fremdschlüssel müssen gelöscht und anschließend auf den Bewegungsdaten wiederhergestellt werden.

- Entfernen der Identitätseigenschaft auf der Spalte ID

- Erstellung der Sequenz SEQ_LieferantenID mit Startwert

CREATE SEQUENCE dbo.SEQ_LieferantenID AS TINYINT START WITH 17 --optional, Default startet mit 1 INCREMENT BY 1 --muss ganzzahlig seinAls Startwert wird 17 gewählt, da bereits 17 Datensätze in der Tabelle existieren, der nächste zu vergebende Wert 18 sein soll!
- Erstellung Primärschlüssel

- Verknüpfung der Sequenz mit der Tabelle

- Anpassung der Insert-Prozedur

- OPTIONAL: Absicherung der Spalte gegen Veränderungen
Wenn man sicher gehen möchte, dass die mit der Sequenz nummerierte Spalte nicht auch außerhalb einer DeltaMaster Eingabe verändert werden kann, bietet sich die Verwendung eines DDL-Triggers im Falle von Updates an. Hier ein Lösungsvorschlag für das hier betrachtete Fallbeispiel:

--Bewegungsdaten
UPDATE a
SET a.LieferantID = s.ID_neu
FROM
[dbo].[T_D_Ausgaben] a
INNER JOIN (
SELECT ID, ROW_NUMBER() OVER (PARTITION BY Kommentar ORDER BY BEZ) ID_neu
FROM [dbo].[T_S_Lieferant]
) s
ON a.LieferantID = s.ID
--Stammdaten
UPDATE a
SET a.ID = s.ID_neu
FROM
[dbo].[T_S_Lieferant] a
INNER JOIN (
SELECT ID, ROW_NUMBER() OVER (PARTITION BY Kommentar ORDER BY BEZ) ID_neu
FROM.[dbo].[T_S_Lieferant]
) s
ON a.ID = s.IDALTER TABLE dbo.T_S_Lieferant ADD CONSTRAINT PK_T_S_Lieferant_ID
PRIMARY KEY CLUSTERED (ID ASC)ALTER TABLE dbo.T_S_Lieferant
ADD CONSTRAINT DEF_ID DEFAULT
(NEXT VALUE FOR dbo.SEQ_LieferantenID)
FOR ID--Ermittlung neue Sequenznummer
IF @ID IS NULL SET @ID = NEXT VALUE FOR dbo.SEQ_LieferantenIDCREATE TRIGGER TR_NoUpdate_LieferantenID
ON dbo.T_S_Lieferant
FOR UPDATE
AS
BEGIN
IF UPDATE(ID)
ROLLBACK
RAISERROR('Changing ID not allowed!',16,1)
ENDErgebnis & Test
Die Testergebnisse zeigen, dass grundsätzlich der Einsatz von Sequenzen für die Nummerierung von Datensätzen möglich ist.
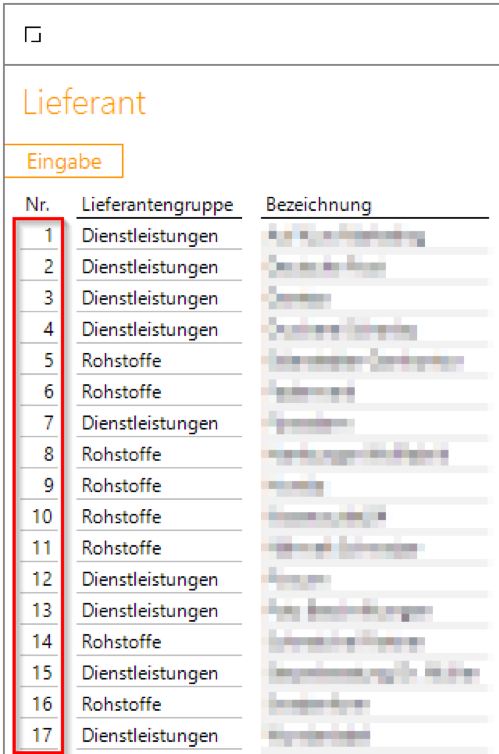
Abbildung 3: Ergebnis nach Neunummerierung durch eine Sequenz
Das Löschen von Datensätzen führt dazu, dass die entsprechende Sequenznummer nicht erneut vergeben wird. Bei der Entwicklung von derartigen Eingabeanwendungen kann man zwar eine Sequenz neustarten, was allerdings in einem Regelbetrieb mit parallelen Schreibzugriffen unpraktikabel ist. Der Befehl für den Neustart einer Sequenz lautet:

Eine dynamische Ermittlung des Startwerts ist nicht möglich!
Ein weiterer interessanter Fakt ist, dass bei Eingabe mehrerer Datensätze in einer „Transaktion“ die Sequenznummer ebenfalls bereits eine Lücke enthält.
![]()
Abbildung 4: Eingabe zweier Datensätze in einer Transaktion
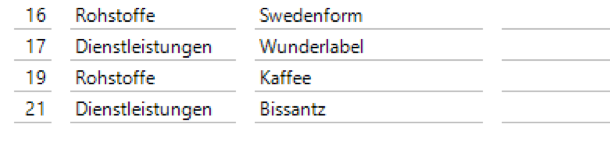
Abbildung 5: Ergebnis = ID mit Lücke
Die Lücke entsteht, weil in diesem Fall in der P_Insert_V_S_Lieferant selbst der NewValue für die ID erzeugt wird, gleichzeitig aber auch im Default-Constraint. Da hier die ID nicht übergeben wurde springt die ID also immer um den Wert 2. Lösungsmöglichkeiten:
- ID selbst in der Tabelle mit NEXT_VALUE_FOR erzeugen, dann aber auch beim Insert an die Tabelle übergeben.
- Keine ID selbst in der Prozedur erzeugen und sich einfach auf den Default-Constraint verlassen.
Fazit
In Datenbankprojekten mit vielen parallelen Schreibzugriffen (z.B. transaktionalen ERP-Systemen) bietet sich die Verwendung von Sequenzen an. Insbesondere die Unabhängigkeit von Tabellen, die fortlaufende Nummerierung bei parallelen Prozessen sind in derartigem Anforderungsumfeld nützlich.
Pragmatischer, und damit vielleicht effizienter in kleineren Planungsanwendungen ist meines Erachtens die Identitätseigenschaft. Diese hat weniger Ausnahmen, in denen Lücken entstehen und ergeben per Definition die Eindeutigkeit einer Tabellenspalte.
Weiterführende Links
https://docs.microsoft.com/de-de/sql/relational-databases/sequence-numbers/sequence-numbers?view=sql-server-ver15
https://docs.microsoft.com/de-de/sql/t-sql/statements/create-sequence-transact-sql?view=sql-server-ver15
https://www.sqlservercentral.com/forums/topic/sequences
https://www.sqlshack.com/difference-between-identity-sequence-in-sql-server/
