Die Extraktion der relevanten Quelldaten aus internen und externen Vorsystemen („Staging“) ist im Vergleich zu den nachgelagerten Prozessen der relationalen Transformation und multidimensionalen Modellierung erfahrungsgemäß sehr individuell. Dieser Beitrag beschreibt einen dynamischen und effizienten Implementierungsansatz mit SQL-Mitteln: Synonyme, Prozeduren und Views.
Handelt es sich beim Quellsystem um eine relationale Datenbank, die vom Zielsystem erreichbar ist (d. h. unserem Microsoft SQL-Datawarehouse), ist meist die direkte Anbindung über einen Linked Server besser als eine manuelle Datenextraktion mittels SQL Server Integration Services (SSIS). Die SQL-Views zum Aufbau der Dimensionen und Measure Groups in unserer Logikschicht greifen dann direkt auf die entfernten Tabellen im Vorsystem zu. Dadurch wird der Schritt der physischen Extraktion vermieden und sowohl Zeit als auch Speicherplatz gespart – so zumindest die Theorie.
In der Praxis können verschiedene Rahmenbedingungen zu folgenden Problemen führen:
- Schlechte Ladeperformance durch langsame Anbindung des Quellsystems – Ursache dafür kann zum Beispiel die Netzbandbreite sein oder ein ineffizienter Provider
- Wiederholter manueller Anpassungsaufwand bei Systemerweiterungen, zusätzlich benötigten Objekten usw., insbesondere bei Mehrmandantensystemen, wenn dieselben Tabellen aus mehreren Quellen zusammengeführt werden müssen
- Konsistenzfehler bei Zugriffen in Echtzeit, etwa wenn im Produktivsystem während der Extraktion neue Kunden angelegt und bebucht werden
In verschiedenen Kundenprojekten haben wir einen dynamischen Ansatz entwickelt, der auf derselben Grundidee basiert und in verschiedenen Varianten implementiert wurde.
Grundsätzlich wird in jedem Fall zunächst per SQL-Prozedur ein Linked Server angelegt bzw. aktualisiert, dessen Parameter in einer Steuertabelle festgelegt werden:
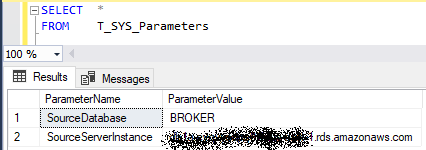
Abbildung 1: Steuertabelle mit Serverparametern

Abbildung 2: Erstellung/Änderung des Linked Servers
Eine zweite Steuertabelle beinhaltet die Liste der relevanten Quelltabellen sowie optional weitere Parameter zu deren Behandlung, z. B. eine Feldliste, Aktivstatus oder zusätzliche Bedingungen:
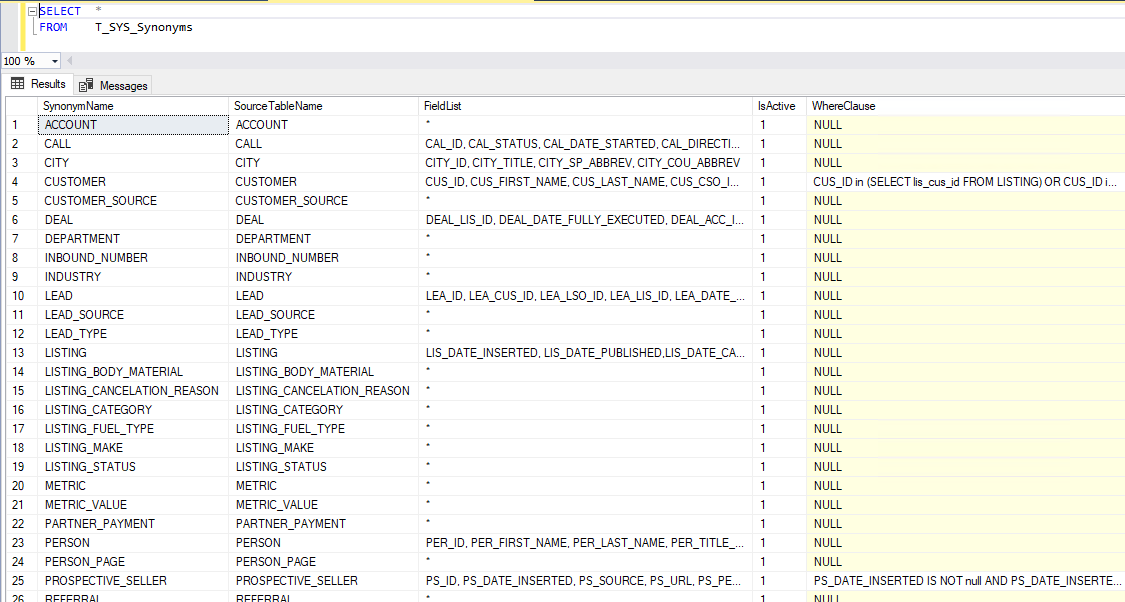
Abbildung 3: Steuertabelle mit Quelltabellen und weiteren Parametern
Die SQL-Prozedur erstellt auf dieser Basis im einfachsten Fall lediglich Synonyme für die Quelltabellen. Im obigen Beispiel, wo bei einem internationalen Kunden der Zugriff aus der MS Azure Cloud auf Amazon AWS erfolgt, entschieden wir uns aufgrund großer Datenmengen in Kombination mit schlechtem Durchsatz zur Materialisierung. Der Performance-Engpass tritt nun nur einmalig beim initialen Laden auf, nicht jedoch mehrfach z. B. durch wiederholte Verwendung der Source Views bei Dimensionen mit mehreren Ebenen. Die optionale Feldliste sowie die WHERE-Bedingung reduziert die zu übertragende Datenmenge dabei zusätzlich auf das erforderliche Minimum.

Abbildung 4: Feldliste und Where-Bedingung
Bei einem weiteren Kunden entstand die Notwendigkeit zu einem Delta-Load-Prozess. Auch dieser wird dynamisch über zwei Parameter in der Synonymtabelle gesteuert. Der von der SQL-Prozedur generierte Code leert und befüllt die jeweilige Zieltabelle entweder komplett neu oder belädt eine strukturgleiche Delta-Tabelle, wobei anschließend in bewährter Logik die Archivtabelle unter Verwendung der Synchronisationskriterien abgeglichen wird.
Das funktioniert in diesem Fall deshalb besonders gut, weil das Vorsystem in allen Tabellen Änderungszeitstempel führt. Durch einen großzügig gewählten Delta-Zeitraum, der hier ebenfalls per Parameter gesteuert wird (in unserem Fall die letzten zehn Tage), werden stets ausreichend viele Daten in die Delta-Tabelle gelesen und so potenzielle Lücken vermieden, selbst wenn der Prozess einmal mehrere Tage ausfällt oder mit unvorhergesehenen Fehlern abbricht.

Abbildung 5: Parameter für den Delta-Load-Prozess in der Synonymtabelle
In einem dritten Kundenbeispiel erzeugt die SQL-Prozedur zusätzlich UNION-Views, um die Daten der zuvor erzeugten Synonyme mehrerer Mandanten dynamisch zusammenzuführen. Dieser Kunde ist ein stetig expandierender Filialbetrieb, weshalb in unregelmäßigen Abständen neue Mandanten für neu eröffnete Standorte oder Webshops hinzukommen. Anstatt für jeden Mandanten sämtliche betroffenen Tabellen auf Anforderung manuell zusätzlich zu importieren, reicht bei unserer Implementierung die Eintragung neuer Datensätze in der Steuertabelle. Dieses Vorgehen vermeidet Stress durch Ad-hoc-Anfragen, minimiert das Fehlerrisiko und spart langfristig viel Zeit und Kosten.
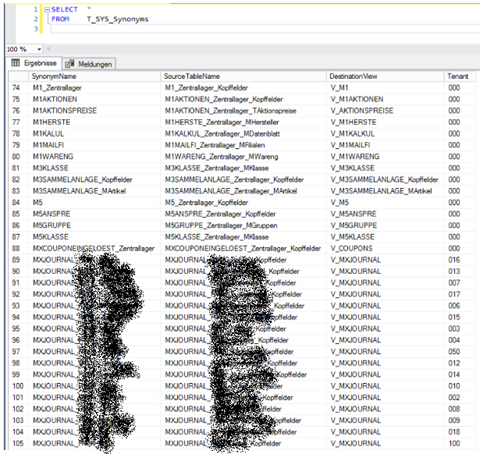
Abbildung 6: UNION-Views in der Synonymtabelle
Unsere Kunden können die Parametrierung und den Aufruf des beschriebenen Prozesses selbst übernehmen, beispielsweise mit einer Pflegeanwendung in DeltaMaster. Eine solche Anwendung nutzt beispielsweise ein Kunde aus dem Bereich Immobilien- und Vermögensverwaltung, denn auch in diesem Geschäft kommen stetig neue Objekte/Mandanten und deren Quelldaten hinzu:

Abbildung 7: Pflegeanwendung für Kunden in DeltaMaster
Gerne stellen wir auf Anfrage den Quellcode bereit und/oder führen individuelle Anpassungen durch.
Perspektivisch lässt sich dieser Ansatz weiter generalisieren und soll künftig auch in DeltaMaster ETL übernommen werden – über ein entsprechendes Update halten wir unsere Kunden in den zugehörigen Release Notes von DeltaMaster ETL auf dem Laufenden.
