In diesem Blogbeitrag wird eine volldynamische Möglichkeit zur Partitionierung von großen Datenmengen vorgestellt. Es werden die Funktionsweise und alle benötigten Datenbank-Objekte sowie die nötigen Einstellungen in DeltaMaster ETL und im Transform-Prozess erläutert. Abschließend wird ein Ausblick hinsichtlich einer vollautomatischen Einrichtung der Logik gegeben.
Einführung
Zu dem Thema Partitionierung wurden bereits einige Beiträge verfasst. Unter anderem auch einer zur dynamischen Partitionierung. In diesem wird ein Ansatz vorgestellt, der sich dadurch auszeichnet, dass je aktueller der Datenstand einer Partition ist, desto geringer ist die Datenmenge dieser Partition. Das hat den Vorteil besonders kurzer Ladezeiten bei Abfragen auf die aktuellen Daten.
Auch ein zweiteiliger Blogbeitrag aus 2011 („Partitionierte Tabellen – Fakten Laden mit Fast = TRUE“) beschäftigt sich mit einer Form der dynamischen Partitionierung. Hier werden in jeder Partition aber die gleichen kleinen Datenmengen (z.B. je Monat eine Partition) gespeichert, wobei beim Hinzukommen einer neuen Datenscheibe die älteste gelöscht wird und alle anderen eine Partition nach hinten „wandern“. Der in diesem Blogbeitrag vorgestellte Ansatz beruht auf dem zweiteiligen Blogbeitrag aus 2011 und stellt eine Prozedur zur Partitionierung dar, die schon vor ca. sechs Jahren das erste Mal produktiv bei einem Kunden eingesetzt wurde.
Im Folgenden werden wir eine Anleitung bereitstellen, wie die Prozedur zur Partitionierung produktiv zu nehmen ist. Die CREATE-Skripte für die Objekte, die nicht von DeltaMaster ETL erzeugt werden, liegen mit diesem Blogbeitrag ab. Eine voll automatische Einrichtung ist leider noch nicht möglich, jedoch ist die Einrichtung der Partitionierung für ein mit DeltaMaster ETL erstelltes Modell im Aufwand überschaubar.
Funktionsweise der Partitionierungslogik
Für diese Form der Partitionierung wird wie bei jeder anderen je Partition eine Faktentabelle benötigt. Der Unterschied ist, dass es zwei weitere Faktentabellen gibt. Wenn beispielsweise immer die letzten 16 Quartale im Modell enthalten sein sollen, werden also 18 Faktentabellen benötigt.
Die ersten beiden Faktentabellen sind, sofern gerade kein Transform stattfindet, leer und die Tabellen 3-18 enthalten die Daten. Dies hat den Grund, dass die T_FACT_01 nur während des Transforms mit den neuen Daten befüllt wird. Anschließend werden diese durch die Prozedur P_APP_TransferDataToPartition in die entsprechende Faktentabelle geladen. Welches Quartal in welche Tabelle geladen werden muss, steht in der T_S_Map. In diesem Beispiel würden in der T_FACT_03 immer das älteste Quartal und in der T_FACT_18 das aktuellste stehen. Zu Beginn des Durchlaufs der Prozedur wird geprüft, ob das höchste Partitionierungsintervall (in diesem Beispiel sind es Quartale) in der T_S_Map zugeordnet ist. Ist dies der Fall werden die Daten der T_FACT_01 entsprechend verteilt und im Anschluss aus der Tabelle gelöscht. Danach kann standardmäßig das Modell prozessiert werden.
SELECT DISTINCT
dbo.F_BC_DateID('q', t.DayID, 0)
FROM
T_FACT_01_Invoice_01 t
WHERE
dbo.F_BC_DateID('q', t.DayID, 0) >= (Select min(QuarterID) from dbo.T_S_Map_FactInvoiceOrders_Quarter)
ORDER BY
dbo.F_BC_DateID('q', t.DayID, 0) ASC
OPEN quarter_cursor
FETCH NEXT FROM quarter_cursor into @QuarterID
WHILE @@FETCH_STATUS = 0
BEGIN
--Init
SET @LoadNewPartition = 0
SET @ErrorOccurred = 0
SET @TargetTableName = NULL
--Search for target table in Mappingtable
SELECT @TargetTableName = FactTableName
-- Select *
FROM dbo.T_S_Map_FactInvoiceOrders_Quarter
WHERE QuarterID = @QuarterID
--Check for new quarter partition
if @TargetTableName IS NULL SET @LoadNewPartition = 1Ist das Ergebnis dieser Prüfung negativ, bedeutet das, dass ein neues Quartal angebrochen ist und das älteste Quartal nicht mehr im Modell enthalten sein muss. Die Zuordnung der einzelnen Quartale zu den Faktentabellen wird nun dynamisch angepasst, wie im Folgenden beschrieben wird und der Abbildung 1 entnommen werden kann.
Zunächst werden alle Partitionen per SWITCH TABLE-Befehl immer eine Faktentabelle „nach oben“ verschoben. Die T_FACT_03 also in die T_FACT_02, die T_FACT_04 in die T_FACT_03 und so weiter. Danach wird die T_FACT_02 geleert, sodass diese und die T_FACT_18 leer sind. Im Anschluss wird die T_S_Map-Tabelle aktualisiert und die Daten der T_FACT_01 werden, wie bereits beschrieben, auf die anderen Faktentabellen verteilt.
DECLARE fact_cursor CURSOR FOR
SELECT [name]
FROM sys.tables
WHERE
[name] like 'T_FACT_01%'
AND [name] not in ('T_FACT_01_Invoice_01', 'T_FACT_01_Invoice_02')
ORDER BY [Name] ASC
OPEN fact_cursor
FETCH NEXT FROM fact_cursor INTO @SwitchSourceTableName
WHILE @@FETCH_STATUS = 0
BEGIN
--Get Switch Target Table name
SET @SwitchTargetTableName = left(@SwitchSourceTableName, len(@SwitchSourceTableName) - 2) + right('0' + convert(varchar, convert(int, right(@SwitchSourceTableName,2))-1),2)
--Do Switch
set @sql = 'ALTER TABLE ' + @SwitchSourceTableName + ' SWITCH TO ' + @SwitchTargetTableName
exec(@sql)
if @@ERROR <> 0
BEGIN
set @ErrorOccurred = 1
END
FETCH NEXT FROM fact_cursor INTO @SwitchSourceTableName
END![]()
Abbildung 1: Transfer der Quartale, beim Hinzukommen eines neuen Quartals
Anleitung zur Einrichtung der Partitionierungslogik
Was wird benötigt?
Standardobjekte:
- V_Import_FACT-View -> enthält zu importierende Daten
- V_Import_FACT_Dummy-View -> leeres Abbild der V_Import_FACT
- n + 2 T_FACT-Tabellen
Objekte der Partitionierungslogik:
- T_S_Map -> Tabelle, die das Mapping der einzelnen Datenscheiben der Partitionierung zu den Faktentabellen enthält
- P_APP_TransferDataToPartition -> Prozedur zum Transfer der Daten in die jeweilige Partition (Hauptprozedur der gesamten Logik)
- P_APP_Update_T_S_Map -> Prozedur zum Update der Mapping Tabelle
- F_APP_NextQuarter -> Funktion zum Ermitteln einer neuen Datenscheibe (hier Quartale)
Notwendige Anpassung an den CREATE-Skripten
1) Anlegen der V_Import_FACT-Views
Zunächst wird eine View angelegt, die die Daten, die in das Modell geladen werden sollen, vorbereitet. Diese View muss nicht die Daten des gesamten Zeitraums abrufen, der im Modell enthalten sein soll. Es genügt die Datenmenge über den Zeitraum für den sich rückwirkend noch Änderungen ergeben können, zum Beispiel einen Monat. Zusätzlich zu der V_Import_FACT wird eine weitere View angelegt. Sie ist eine einfache Kopie der V_Import_FACT mit dem Unterschied, dass sie nicht einfach SELECT ausführt, sondern ein SELECT TOP 0 und somit keine Daten enthält. Als Bezeichnung bietet sich hier an, den ursprünglichen Namen lediglich um das Suffix „_Dummy“ zu erweitern. Der Nutzen dieser View wird später erläutert.
2) Erzeugen der T_FACT-Tabellen und der entsprechenden P_FACT-Prozeduren mittels DeltaMaster ETL
Wie eingangs bereits erwähnt und in Abbildung 1 dargestellt, werden zwei Faktentabellen mehr benötigt, als Partitionen vorhanden sein sollen.
In dem Bericht Measure groups wird wie gewohnt die entsprechende Measuregruppe angelegt. Wichtig ist jedoch, dass die Schalter für Delete Table und Fill Table nicht auf „Yes“ stehen und der Schalter für Partition per src. tbl. auf „Yes“ gesetzt wird. Ansonsten entspricht hier alles dem Standard.
Anschließend werden im Bericht Measure group source tables die Faktentabellen der Partitionen angelegt. Abbildung 2 kann entnommen werden, dass die erste Tabelle die View mit den aktuellen Datensätzen als Quelle hat, während die restlichen Tabellen den Dummy als Quelle haben. Deshalb brauchen diese Tabellen auch nicht gelöscht und gefüllt werden, da deren Quelle immer leer sein wird. Ein weiteres Detail, welches viel Arbeit bei den folgenden Schritten spart, ist, dass die Definition source table ID für alle Partitionen mit der Dummy-View als Quelle die zweite Tabelle ist. Somit müssen die Dimensionen und Kennzahlen der Measuregruppe nur einmal für die erste und die zweite Faktentabelle angelegt werden.
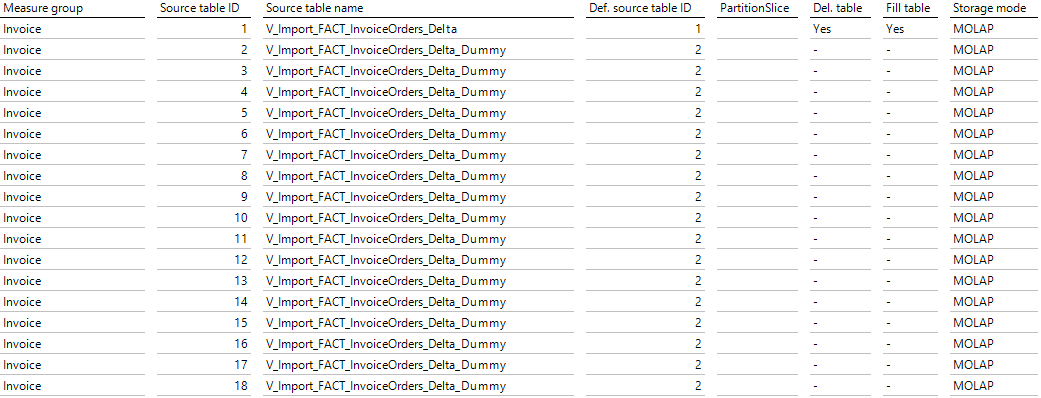
Abbildung 2: DeltaMaster ETL-Bericht Measure group source tables
3) Anlegen der Objekte für die Partitionierungslogik
Nachdem das relationale Modell mit Hilfe von DeltaMaster ETL neu aufgebaut wurde, können nun die Objekte für die Partitionierungslogik angelegt werden.
Hierfür müssen die im Ordner zu diesem Beitrag abgelegten CREATE-Skripte ausgeführt werden. Es ist zu empfehlen den Objekten noch sprechende bzw. modellspezifische Namen zu geben. Außerdem müssen je nachdem ob die Partitionierung nach Quartalen, Monaten oder gar Kalenderwochen erfolgen soll die Spalten der Tabelle und die Verweise in den Prozeduren bzw. der Funktion angepasst werden. Die nötigen Anpassungen werden im Folgenden für jedes Objekt einmal beschrieben.
- T_S_Map
- Umbenennen der Spalte QuartalID nach verwendetem Partitionierungsintervall.
- F_APP_NextQuarter
- Anpassen des Parameters
- Anpassen des CASE-Ausdrucks, sodass immer das nächste Intervall des im Parameter enthaltenen Partitionierungsintervalls ermittelt wird. In diesem Beispiel wird immer das nächste Quartal ermittelt. Die Berechnung für den nächsten Monat, für den Fall, dass eine Partitionierung nach Monaten erfolgt, ist im Skript enthalten und kann bei Bedarf einkommentiert werden.
- P_APP_Update_T_S_Map
- Umbenennen des Parameters QuartalID im gesamten Code der Prozedur
- Umbenennen der Tabelle T_S_Map und der Funktion F_APP_NextQuarter im Code der Prozedur
- P_APP_TransferDataToPartition
- Parameter QuartalID, NextQuartalID und MaxQuarterID im gesamten Code der Prozedur anpassen
- Anpassen des Tabellennamens T_S_Map, Funktionnamens F_APP_NextQuarter und Prozedurnamens P_APP_Update_T_S_Map im Code der Prozedur
- Berechnung der QuarterID in der Definition des Cursors zu Beginn der Prozedur anpassen. Da hier die Funktion F_BC_DateID, die im MeatModell von DeltaMaster ETL enthalten ist, verwendet wird, muss lediglich der Parameter zur Angabe der Zeitebene (z.B. Quartal, Monat, KW) angepasst werden.
- Spaltennamen für die Tabellenvariable @DelCriteriaTab im unteren Teil der Prozedur, der durch den Kommentar „Fill import data to target table“ gekennzeichnet wird, anpassen.
- An derselben Stelle muss die Befüllung der Variablen und der Abgleich mit der T_FACT-Tabelle (hier die Variable @TargetTableName) angepasst werden. Die verwendeten Spalten sind jene, die identifizieren, welche Datensätze aus den Fakten gelöscht werden müssen, da sie bei einem neuen Transform neu geladen werden. Wenn zum Beispiel immer die Daten der letzten x-Tage neu geladen werden, wäre die TagID das entscheidende Kriterium. Es würden alle Datensätze gelöscht werden, deren Tag in der T_FACT_01 steht.
4) Einbinden in den TransformAll-Prozess und Initiales Befüllen
Abschließend muss die Prozedur P_APP_TransferDataToPartition in die Prozedur P_Transform_99_PostProcess eingebunden werden, damit sie im Rahmen des Transformprozesses aufgerufen wird.
Außerdem muss die T_S_Map-Tabelle einmal initial mit der korrekten Zuordnung gefüllt werden. Dies kann manuell erfolgen.
Da zu Beginn alle Faktentabellen leer sind, muss einmal die gesamte Datenmenge in der V_Import_FACT abgefragt werden, damit diese in die T_FACT_01 geladen wird und von dieser auf die entsprechenden Tabellen verteilt wird. Je nachdem, wie groß das Log werden kann und um wie viele Daten es sich handelt, empfiehlt es sich, diese anfängliche Befüllung auf mehrere Teilmengen aufzuteilen.
Ausblick
Da bei der Einrichtung der Partitionierung alle Objekte händisch angepasst werden müssen, ist es nicht unwahrscheinlich, dass zum Beispiel das Anpassen eines Parameters an einer Stelle übersehen wird. Insbesondere die Stellen in der Hauptprozedur, in denen mit dynamischem SQL gearbeitet wird, sind fehleranfällig, da hier keine IntelliSense des MS SQL Management Studios unterstützen kann. Aus diesem Grund möchten wir gerne in einem folgenden Blogbeitrag eine automatisierte Lösung vorstellen, in der anfänglich definiert wird, wie viele Partitionen gewünscht sind und nach welchem Intervall partitioniert werden soll. Basierend auf diesen Eingaben sollen anschließend dynamisch alle Objekte angelegt werden, sodass weniger Zeit für das Einrichten der Logik notwendig ist und mehr Zeit auf das Analysieren der Daten verwendet werden kann.

Kommentare
Sie müssten eingeloggt sein um Kommentare zu posten..