In zwei vorherigen Blogbeiträgen haben wir einen Prozess zur Erkennung bereits vorhandener Datensätze in einer Zieldatenbank gezeigt. Was aber tun, wenn meine Daten zwar auf Feldebene gleich sein sollten, es aber de facto nicht sind? Der Vorname ist in dem einen Fall ausgeschrieben, im anderen Fall nicht. Es haben sich Tippfehler eingeschlichen, und so weiter. Das Ganze dann auch noch in Kombination und das Datenchaos ist perfekt. Aber ein normaler Zustand in der realen Welt der Softwareverwaltung.
Im Rahmen eines Kundenprojektes für ein Kostencontrolling kam die Frage auf, warum im Bereich von Softwarelizenzen stetig steigende Kosten zu verzeichnen sind, wenngleich die Personalstärke auf ihrem Niveau stagniert. Eine Hypothese war, dass unnötige Lizenzen bezahlt werden. Wir wurden um Rat gefragt und daraus entstand die Idee, ein Benutzermanagement mit Hilfe von DeltaMaster einzuführen, damit Änderungen an den Personalstrukturen auch in die Zielsysteme weitergetragen werden. Denn diese bilden schließlich die Basis für die Abrechnung der benutzten Lizenzen. Richtig gelesen, benutzte Lizenzen, welche aber sind das? Ziel sollte sein, alle Benutzer aus den Stammdaten der unterschiedlichsten Systeme je seinem Pendant im Active Directory (AD) zuzuordnen. Welches ist aber sein Pendant, wenn die Inhalte eben nicht genau übereinstimmen? Duplikat oder nicht?
An genau dieser Stelle kam uns die Idee einer sogenannten Fuzzysuche (engl. fuzzy = undeutlich, unscharf). Dabei geht es kurz gesagt um inhaltliche Ähnlichkeiten von Zeichenfolgen, definierbar mit Schwellwerten. Diese ist ein Bestandteil der Integration Services des MS SQL Servers (kurz: SSIS) seit der Version 2005 und kann mit Hilfe des BI Development Studios (kurz: BIDS) in jegliche ETL-Prozesse integriert werden. Lassen Sie uns dieses Helferlein heute einmal genauer unter die Lupe nehmen.
Zunächst benötigen wir mehrere Tabellen, wobei eine die Referenztabelle darstellt, mit der die anderen Tabellen verglichen werden. Wir haben hier ein Beispielskript abgelegt, welches uns drei Tabellen anlegt, mit Benutzerinformationen füllt und eine View als Datentopf erstellt. Es sind hier recht einfach gehaltene Tabellen, in der Praxis werden vermutlich unterschiedliche Spaltennamen, Informationen zum Status und vielleicht noch Gültigkeiten je System eine Rolle spielen. Das ist in der View beliebig anpassbar und somit kein Hindernis.
Nachdem wir im BIDS eine OLE-DB Quelle ausgewählt haben und in dieser die soeben per Skript angelegte Tabelle T_Import_ActiveDirectory eingestellt haben, ziehen wir uns die Fuzzysuche in den Datenfluss und verbinden die OLE-DB Quelle mit dieser. Kommen wir jetzt zu der Konfiguration. Auf dem ersten Register muss der zu vergleichende Datentopf angegeben werden, in unserem Beispiel hier also die View V_Import_Systeme.
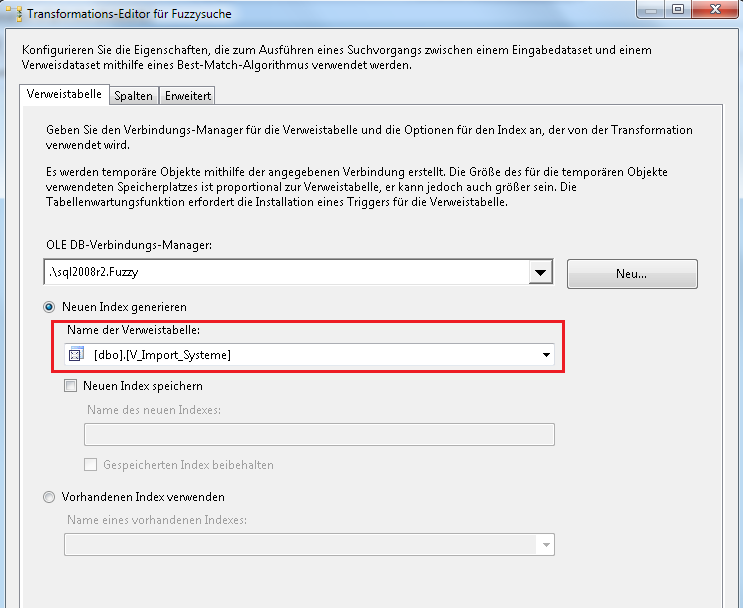
Darüber hinaus hat man hier die Möglichkeit, einen neuen oder bereits bestehenden Index anzulegen bzw. zu verwenden. In der Regel reicht es, vom System einen neuen Index generieren zu lassen, bei sehr großen Tabellen kann der Vergleich naturgemäß sehr lange dauern, dann empfiehlt es sich gegebenenfalls, einen Index über die Schlüsselspalten manuell anzulegen oder einen bereits bestehenden zu nutzen. Die Optimierung und Verfahrensweise zum Umgang mit Indizes soll aber nicht Thema dieses Beitrags sein.
Wir schauen uns jetzt die zweite Registerkarte an. Diese bestimmt jetzt maßgeblich das Ausgabeergebnis.
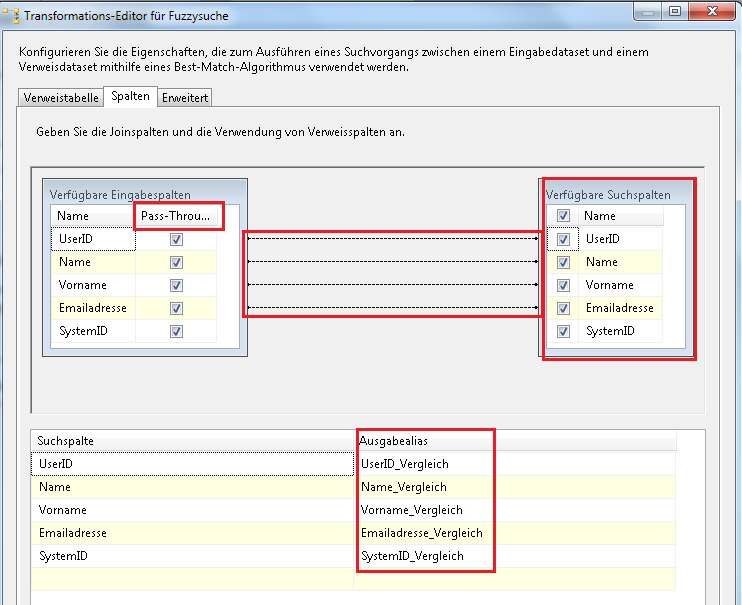
Pass-Through: Hier wird eingestellt, ob die Eingabe Spalte (bei unserem Beispiel also aus der T_Import_ActiveDirectory) mit in das Ergebnis aufgenommen werden soll. Im Standard werden alle Spalten ausgegeben. Wir empfehlen hier, ruhig alle Spalten mit durchzureichen, so hat man im Ergebnis gleich einige Zusatzinformationen.
Verfügbare Suchspalten: Enthalten sind alle Spalten der Verweistabelle. Der Haken je Spalte gibt an, ob für diese Spalte ein Ausgabealias erzeugt wird. Der Ausgabealias wiederum dient dem Task als Metainformation in der Ausgabe der Transformation, dazu später noch eine Anmerkung. Diese Bezeichnung ist frei wählbar.
Durch einen Rechtsklick auf die Pfeile gelangt man in das Menü zur Einstellung der Spaltenzuordnung, der eigentlichen Intelligenz (also die konfigurierbare Unschärfe).
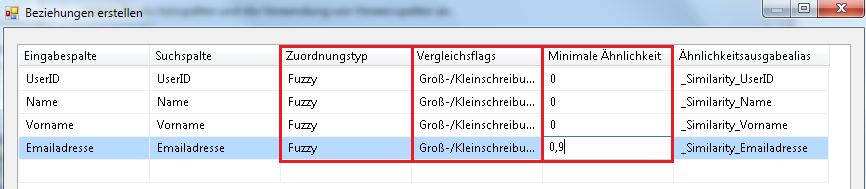
Zuordnungstyp: wird Fuzzy ausgewählt, findet auf diesem Spaltenpaar ein Vergleich statt. Welche Logik verwendet werden soll, wird in der Spalte Vergleichsflags angegeben. Wird Exact eingetragen, wirken sich die Einstellungen in den Vergleichsflags nicht mehr aus und in der Spalte des Schwellwertes wird automatisch eine 1 (=100%) eingetragen.
Vergleichsflags: Manchmal reicht der einfache Vergleich von Zeichenfolgen nicht aus, daher können hier weitere Spezialvergleiche ausgewählt werden, je nach Situation und Quelldaten. Es kann hier beispielsweise das Ignorieren von Symbolen aktiviert werden, aus ABC* wird beim Vergleich mit ABC trotzdem ein 100%-Treffer.
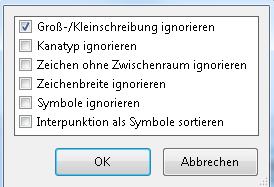
Details zu den Vergleichsflags sind unter diesem Link zu finden.
Minimale Ähnlichkeit: Ist der Zuordnungstyp auf Fuzzy eingestellt, wird hier der Schwellwert angegeben, ab welchem Wert ein Vergleichsergebnis zurückgeben wird. Der gültige Wertebereich liegt zwischen 0 und 1.
Schauen wir uns jetzt den letzten der drei Register an.
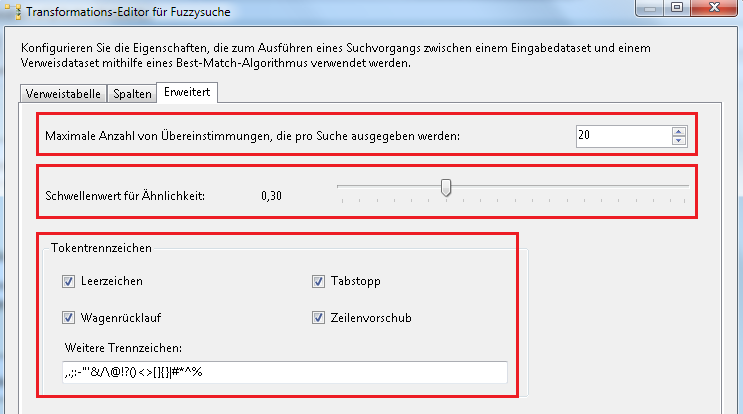
Im oberen Bereich legen wir fest, wie viele Zeilen je Eingabezeile bei gefundenen Übereinstimmungen in die Zieltabelle ausgegeben werden sollen. Es empfiehlt sich, eine größere Anzahl von Übereinstimmungen zu nehmen, um nicht Datensätze auszulassen, deren Vergleich auch interessant sein könnte, nur weil diese Option auf einem geringen Wert steht. Der Standard ist 1.
Darunter ein weiterer Schwellwert. Dieser steuert, welche Datensätze mit in die Ergebnistabelle aufgenommen werden. Es entstehen je Vergleichsspaltenpaar zusätzliche Spalten, in denen die Fuzzysuche den ermittelten Vergleichswert schreibt. Ebenso entsteht eine Wertspalte für die ermittelte Gesamtähnlichkeit über alle Paare hinweg. Je näher der Wert an 1 liegt, desto stärker muss die Ähnlichkeit zwischen Suchwert und Quellwert sein, um als Übereinstimmung zu gelten. Würde man hier den Wert auf 1 Stellen, würde nur 1 Treffer mit 100%iger Übereinstimmung in die Zieltabelle geschrieben werden. Beim Einsatz im Projekt macht es Sinn, mit diesem Wert ein wenig zu spielen und sich die resultierenden Datenmengen anzuschauen.
Durch die Tokentrennzeichen kann zum Abschluss gesteuert werden, ob zusätzliche Trennzeichen in den Daten ignoriert werden sollen. Erfahrungen haben hier bisher kein Beispiel gezeigt, bei dem an dieser Einstellung die Abweichung vom Standard zweckmäßig wäre. Daher die Empfehlung, belassen Sie es bei der Voreinstellung. Aber was ja nicht ist, kann ja noch kommen.
So, nachdem wir hier nun andauernd von Vergleichen, Spaltenpaaren und Schwellwerten gesprochen habe, sollten wir uns das Ergebnis mal vor Augen führen. Dazu benötigen wir noch ein OLE-DB Ziel. Nachdem der Task an die Ausgabe der Fuzzysuche gehängt wurde, können wir mit einem Klick unsere Zieltabelle erstellen lassen, hier im Beispiel T_Import_FuzzyResultat. Die oben bereits erwähnten Metainformationen werden nämlich jetzt vom Assistenten verwendet, um die Tabellenstruktur vorzuschlagen.

Fällt Ihnen etwas auf? Ja genau, es sind einige Spalten aufgrund unserer Fuzzysuche generiert worden, nämlich die eingestellten Eingangsspalten, die Ausgabealiasse und die Fuzzywertspalten. Nachdem das Paket ausgeführt wurde, haben wir jetzt unser Vergleichsergebnis also in der Tabelle T_Import_FuzzyResultat stehen und können dies beliebig mit den uns allseits beliebten und bekannten SQL-Abfragen verarbeiten oder, wie in dem erwähnten Kundenprojekt, mit Hilfe weiterer Views und einer relationalen DeltaMaster-Eingabeanwendung in ein Benutzermanagement überführen.
Ein paar Worte noch zu der Ergebnistabelle. Spannend sind die Ergebnisspalten _Similarity_Spaltename. Die hier abgelegten Werte sind unser Vergleichsergebnis, dargestellt in einer Dezimalzahl zwischen 0 und 1. Nehmen Sie sich ruhig etwas Zeit zum Spielen mit den Einstellungen, Sie werden sehen, es Bedarf immer ein wenig Anpassung an den Stellschrauben, um das in Ihrem Datenumfeld optimale und plausible Ergebnis zu produzieren.
