Beim Arbeiten kommen wir immer wieder mit dem impliziten Verhalten des SQL Servers in Kontakt. Durch dieses an sich erstmal kluge Verhalten werden kleine Fehler oder unsaubere Befehle meist erfolgreich und unauffällig behoben. Leider ist dies aber nicht immer der Fall und so sehen die Ergebnisse teilweise ganz anders aus als man es erwartet. Gerade diese Fälle sind es, die Zeit kosten und im Zweifel auch für Frustration sorgen.
Häufig sind Fehler, deren Ursache eben in diesem impliziten Verhalten liegt, nicht direkt als solche zu erkennen bzw. die Stelle, die dieses Verhalten verursacht, nicht offensichtlich. Dies kann nicht nur dem unbedarften, weniger erfahrenen SQL-Programmierer passieren, sondern im Zweifel auch dem erfahrenen SQL-Profi. Hierfür muss lediglich die Datenlieferung für ein bestehendes Modell nicht dem ursprünglichen Muster entsprechen oder ein Fall einfach nicht beachtet worden sein und erst nach einiger Zeit auftreten.
Aus diesem Grund sollen in diesem Blogbeitrag einige der Stolpersteine beim Arbeiten mit dem SQL Server erläutert werden.
Fallbeispiele
Wann werden Datensätze ohne Vorwarnung abgeschnitten?
Wir haben eine kleine Tabelle angelegt, die ein Feld „TestspalteVarchar10“ enthält. Wie dem Namen entnommen werden kann, hat die Spalte das Datenformat VARCHAR(10). Nun wird folgendes SQL-Statement ausgeführt:
INSERT INTO dbo.Testtabelle
(TestspalteVarchar10)
VALUES ('Ich bin ein String!')
Wie zu erkennen ist, hat der Eintrag, der eingefügt werden soll, eindeutig mehr als zehn Zeichen und sollte deshalb auch abgeschnitten werden. Genau das geschieht auch, und eine Fehlermeldung wird ausgegeben.

Abbildung 1: Fehlermeldung des SQL-Servers
Problematisch wird es jedoch, wenn nun Parameter und Variablen genutzt werden. Hier warnt der SQL Server nicht mehr, wenn der Eintrag zu lang ist und abgeschnitten wird. Führt man nämlich folgendes Statement aus, erfolgt dies ohne Probleme, und es erscheint keine Warnung wie im vorherigen Bespiel.
DECLARE @Test VARCHAR(10) = 'Ich bin ein String!'; PRINT @Test;
Als Ergebnis wird jedoch der String „Ich bin ei“ ausgegeben.
Wenn nun diese beiden Schritte in einer Prozedur kombiniert werden, was im Projektalltag kein ungewöhnliches Vorgehen ist, erfolgt auch keine Prüfung der Länge des Strings. Dies hat zur Folge, dass zwar der String in die Tabelle geschrieben wird, ohne dass ein Fehler auftritt, der geschriebene Wert aber abgeschnitten wird. Dieses Problem tritt selbstverständlich auch dann auf, wenn die Definition der Spalte einen ausreichend langen String zulässt, da die Eingabe schon bei der Übergabe an die Variable „abgeschnitten“ wird. Entscheidend ist also, wie die Variable deklariert ist. Wenn diese nämlich ausreichend lange Strings erlaubt, die Definition der Tabellenspalte aber nicht ausreichend ist, erscheint wieder die bekannte Hinweismeldung.
Konvertieren von FLOAT
Ein Thema, das auch gerne zu Problemen führt, ist die implizite Konvertierung. Wenn wir zum Beispiel gemischte IDs haben (teilweise numerisch, teilweise alphanumerisch), dann definieren wir beim Modellieren des OLAP-Modells den Datentyp des Keys in der Regel als VARCHAR. Wenn nun die numerischen IDs aus einer anderen Quelle kommen als die alphanumerischen IDs und in der Datenbank als FLOAT vorliegen, besteht bei der Konvertierung in VARCHAR die Gefahr, dass die ID nicht mehr als „normale“ Zahlenfolge dargestellt wird, sondern in der wissenschaftlichen Schreibweise. Das kann wiederum dazu führen, dass Mappings nicht funktionieren, da diese Werte nicht als gleich erkannt werden. Die Grenze, ab der dieses Problem auftritt, liegt genau bei 1.000.000. Wenn also die FLOAT-Zahl kleiner ist, passiert nichts, beträgt sie jedoch mindestens 1.000.000, wird sie in die wissenschaftliche Schreibweise konvertiert.
Umgehen kann man das generell, wie folgendes Skript zeigt, indem man zur Konvertierung als Funktion nicht CAST oder CONVERT nutzt, sondern STR.
DECLARE @x float = 1535016; SELECT 'This is a number:' + Convert (VARCHAR(32), @x) AS [CONVERT] SELECT 'This is a number:' + CAST (@x AS VARCHAR(32)) AS [CAST] SELECT 'This is a number:' + STR(@x,18,0) AS [STR]
Das Ergebnis der Abfragen sieht dann wie folgt aus:
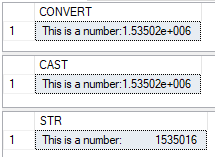
Abbildung 2: Abfrageergebnis
Doch auch die STR-Funktion ist keine fehlerfreie Lösung oder gar ein Allheilmittel. Wenn man nämlich eine Zahl mit Nachkommastellen zu einem String konvertieren möchte, sorgt STR in Verbindung mit Gleitkommazahlen für Ungenauigkeiten, da bei Verwendung dieser Funktion immer eine implizite Konvertierung in FLOAT vorgenommen wird. Alphanumerische Eingaben führen dementsprechend zu einem Fehler. Aber auch Gleitkommawerte können zu Problemen führen, wie das untenstehende Beispiel verdeutlicht.
DECLARE @x float = 33.33;
SELECT 'This is a number:' + CONVERT (VARCHAR(32), @x) AS [CONVERT]
SELECT 'This is a number:' + CAST (@x AS VARCHAR(32)) AS [CAST]
SELECT 'This is a number:' + STR(@x,18,15) AS [STR]
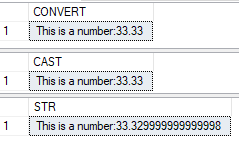
Abbildung 3: Abfrageergebnis
Dieses Problem ist darin begründet, dass FLOAT und REAL ungefähre Datentypen sind. Für genauere Infos zu diesem Thema soll an dieser Stelle auf den Blogbeitrag „FLOAT wie fließen“ vom 02.06.2017 verwiesen werden. Das womöglich größte Problem, das hierdurch bedingt auftreten kann, ist, dass Ver-gleiche in einer WHERE-, CASE- oder IF-Bedingung mit den Operatoren =, <, oder > fehlschlagen können.
Zu diesem Thema bleibt abschließend also nur zu sagen, dass man immer sicherstellen sollte, dass numerische IDs im Datentyp INTEGER vorliegen. Handelt es sich um Gleitkommazahlen, sollte über-legt werden, einen der genauen Datentypen zu verwenden, wobei diese wieder mehr Speicherplatz benötigen. Es muss also immer genau abgewogen werden, wofür man die Werte in der entsprechenden Spalte benötigt, wenn man sich für den Datentyp entscheidet.
Das Problem mit den Prioritäten
Ein weiteres Problem, dass auch im Zusammenhang mit dem vergeben von IDs, insbesondere bei qualitativ eher schlechten Daten, zu Problemen führen kann, ist der Vorrang, den manche Datenty-pen vor anderen haben. Gelegentlich kommt es vor, dass die Spalte, die die IDs enthält, nicht immer vollständig gefüllt ist. In einem solchen Fall bietet sich der COALESCE-Befehl an. Ist eine ID leer, hat also den Wert NULL, möchten wir einfach den Bezeichner verwenden.
DECLARE @BrandID INT = NULL, @BrandName VARCHAR(10) = 'Porsche'; SELECT COALESCE(@BrandID, @BrandName) AS Brand
erscheint nämlich die folgende Fehlermeldung:

Abbildung 4: Fehlermeldung des SQL-Servers
Dieser Umstand mag auf den ersten Blick noch nachvollziehbar sein, da die INTEGER-Spalte vor der VARCHAR-Spalte ausgewertet wird. Wenn man aber als erstes die Spalte mit dem Text auswerten möchte, und falls diese NULL ist, soll die ID verwendet werden, tritt exakt derselbe Fehler auf. Die Reihenfolge der Auswertung ist also nicht relevant. Der Grund hierfür sind die Prioritäten, die der SQL Server beim Auswerten von Abfragen verwendet. Diese sieht wie folgt aus:
1) User-defined data types
2) SQL-Variant
3) XML
4) Date-Datentypen
5) Numerische Datentypen (Gleitkommazahlen von ungenauen zu genauen)
6) Numerische Datentypen (ganzzahlig)
7) BIT
8) TEXT
9) IMAGE
10) TIMESTAMP
11) UNIQUEIDENTIFIER
12) CHAR/VARCHAR/NVARCHAR-Datentypen
13) BINARY
Quelle: https://docs.microsoft.com/de-de/sql/t-sql/data-types/data-type-precedence-transact-sql
Nicht nur Zahlen sind Zahlen
Dieser Abschnitt wird den erfahreneren SQL-Programmierern höchstwahrscheinlich nicht allzu viel neue Erkenntnis bringen, vor allem aber Neulinge in diesem Bereich vor Frust bewahren.
Möchte man auf eine Spalte, in der aufgrund von unsauberen Daten nicht nur numerische Werte enthalten sind, eine Operation durchführen, die lediglich für numerische Werte möglich ist, muss vor-her geprüft werden, welche Werte übergeben werden. Hierfür bietet sich die ISNUMERIC-Funktion an. Jedoch muss, wie im Folgenden dargestellt wird, auch diese Funktion mit Vorsicht genutzt werden.
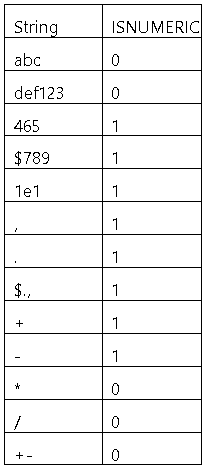
Der Tabelle kann entnommen werden, bei welchen Strings welches Ergebnis für die ISNUMERIC-Funktion ausgegeben wird. Die ersten drei Ergebnisse sollte man erwartet haben, und auch, dass das Dollarzeichen nicht verhindert, dass zum Beispiel Spalten mit Geldbeträgen als numerische Inhalte erkannt werden, ist durchaus schlüssig. Wenn man weiß, dass 1e1 eine wissenschaftliche Schreibweise ist, ergibt sogar dieses Ergebnis Sinn. Doch sogar ein String, der nur das Dollarzeichen, Komma und Punkt enthält, zählt als numerisch. Was man auch bedenken muss, ist, dass nur das + und – als nu-merisch erkannt werden, da sie als Vorzeichen fungieren können, in Kombination aber nicht mehr als numerisch ausgewertet werden.
Wenn man jetzt diese Funktionen nutzen möchte, um zu überprüfen, ob eine Konvertierung in einen numerischen Datentyp möglich ist, wird man unweigerlich Fehler erhalten. Der gewiefte SQL-Programmierer weiß aber auch hier einen Ausweg. Ab SQL Server 2012 kann man die TRYCONVERT-Funktion verwenden, die, wenn die Konvertierung nicht möglich ist, NULL zurückgibt.
Quellen
