Durch Zufall wurde in einem Kundenprojekt festgestellt, dass es bei der Befüllung von Faktentabellen einen großen Unterschied macht, ob für die Tabelle Primary und Foreign Keys definiert sind oder nicht. Konkret wurde in einem DeltaMaster-ETL-Projekt beobachtet, dass die Ausführungszeit von P_FACT-Prozeduren, bei nicht vorhandenen Foreign Keys (die normalerweise auf die Dimensionstabellen verweisen), deutlich niedriger ist als bei vorhandenen Foreign Keys. Auch das anschließende Wiederherstellen der Foreign Keys auf der befüllten Tabelle inklusive Überprüfung der referentiellen Integrität reduziert den Geschwindigkeitsvorteil nicht nennenswert. Dies war Anlass genug, um unterschiedliche Szenarien zu testen und zu bewerten.
Aufbau einer Testumgebung
Zunächst wird in einer Testumgebung mit DeltaMaster-ETL-Modell eine Measuregroup mit drei Partitionen erstellt (jeweils mit eigener Faktentabelle, ETL-Eigenschaft „Partition per Source Table“).
Die drei Basis-Views dieser Partitionen greifen jeweils auf eigene Basistabellen mit unterschiedlicher Anzahl von Datensätzen zu. Die erste Partition enthält 1.000.000, die zweite Partition 5.000.000 und die dritte Partition 10.000.000 Datensätze.
Folgende Befüllungsstrategien sollen für diese Measuregroup betrachtet werden:
- Reguläre DeltaMaster-ETL-Logik, d. h. die Faktentabellen werden geleert und die zugehörigen P_FACT-Prozeduren werden anschließend ausgeführt. Die Foreign Key und Primary Key Constraints bleiben bei dieser Variante unverändert.
- Löschen der Foreign Keys vor der Befüllung der Faktentabellen. Im Anschluss an die Befüllung werden die Foreign Keys unter Prüfung der referentiellen Integrität wiederhergestellt. Die Primary Keys der Partitionstabellen bleiben unberührt.
Dabei werden die DeltaMaster-ETL-Prozeduren P_BC_Drop_T_FACT_FKConstraints und P_BC_Create_T_FACT_FKConstraints genutzt:
exec [dbo].[P_BC_Drop_T_FACT_FKConstraints] @FactID = 6, @PartitionID = 1, @IncludePK = 0; exec dbo.P_BC_Create_T_FACT_FKConstraints @FactID = 6, @PartitionID = 1, @IncludePK = 0, @DoCheck = 1;
- Löschen der Foreign Keys vor der Befüllung der Faktentabellen. Im Anschluss an die Befüllung werden die Foreign Keys ohne Prüfung der referentiellen Integrität wiederhergestellt. Die Primary Keys der Partitionstabellen bleiben unberührt.
exec [dbo].[P_BC_Drop_T_FACT_FKConstraints] @FactID = 6, @PartitionID = 1, @IncludePK = 0; exec dbo.P_BC_Create_T_FACT_FKConstraints @FactID = 6, @PartitionID = 1, @IncludePK = 0, @DoCheck = 0;
- Löschen der Foreign Keys vor der Befüllung der Faktentabellen. Im Anschluss an die Befüllung werden die Foreign Keys unter Prüfung der referentiellen Integrität wiederhergestellt. Auch die Primary Keys der Partitionstabellen werden gelöscht und neu erstellt.
exec [dbo].[P_BC_Drop_T_FACT_FKConstraints] @FactID = 6, @PartitionID = 1, @IncludePK = 1; exec dbo.P_BC_Create_T_FACT_FKConstraints @FactID = 6, @PartitionID = 1, @IncludePK = 1, @DoCheck = 1;
- Löschen der Foreign Keys vor der Befüllung der Faktentabellen. Im Anschluss an die Befüllung werden die Foreign Keys ohne Prüfung der referentiellen Integrität wiederhergestellt. Auch die Primary Keys der Partitionstabellen werden gelöscht und neu erstellt.
exec [dbo].[P_BC_Drop_T_FACT_FKConstraints] @FactID = 6, @PartitionID = 1, @IncludePK = 1; exec dbo.P_BC_Create_T_FACT_FKConstraints @FactID = 6, @PartitionID = 1, @IncludePK = 1, @DoCheck = 0;
- Alle Primary Keys, Foreign Keys, Default Constraints und die Identity-Eigenschaft der Faktentabellen werden vor dem Testlauf gelöscht. Auf dieser Basis werden anschließend die Faktentabellen geleert und neu befüllt.
Um sicher zu sein, dass man stabile Werte erhält, wird jede der Strategien fünfmal in Folge ausgeführt. Das soll verhindern, dass etwaige „Ausreiser“ in den Messergebnissen zu starken Einfluss auf die Gesamtbewertung nehmen. Vor jeder der fünf Wiederholungen werden zudem die Caches geleert.
Ergebnisse und Bewertung

Abbildung 1: Performance der Ladestrategien
Die Ladestrategien werden allesamt mit dem regulären Ladeprozess verglichen. Dieser hat in Summe für die fünf Ausführungen, 1 Stunde und 9 Minuten benötigt.
Offensichtlich ist, dass das Entfernen von Primary Keys keine sinnvolle Option ist (Spalten 4 und 5 in Abbildung 1). Im Vergleich zum regulären Ladevorgang (Befüllungsstrategie 1 in Spalte „Regulär“) ist kaum mit einer Ersparnis zu rechnen. Die positiven Effekte, die durch das Löschen der Foreign Keys entstehen, werden durch die Primary Key-Thematik praktisch vollständig aufgezehrt. Die Ergebnisse werden sogar schlechter als bei der „Regulär“-Variante. Somit sind die Strategien 4 und 5 keine sinnvollen Varianten.
Anders sieht es für die Strategien 2, 3 und 6 aus. Die Strategien zeigen einen deutlichen Performance-Gewinn für alle Szenarien. Im Schnitt sind um die 25% Performance-Verbesserung möglich. Für den Gesamtprozess bedeutet das eine Gesamtzeitersparnis von fast 20 Minuten.
Da der Verzicht der Prüfung auf referentielle Integrität mit einem großen Risiko einhergeht, sind die Befüllungsstrategien 3 und 6 tendenziell mit Vorsicht zu genießen. Zwar sind bei Strategie 3 noch mehr Performance-Steigerungen möglich, jedoch bleiben in den Dimensionsdaten unbekannte Elemente unbemerkt, die in den Fakten-Daten vorhanden sind.
Anders gesagt: es werden keine Foreign Key-Fehler mehr zurückgeliefert. Erst bei der Verarbeitung der OLAP-Datenbank würde sich der Fehler bemerkbar machen. Da die Prüfung eines Fehlers, der bei der Verarbeitung der OLAP-Datenbank auftritt, zumeist um einiges mühsamer ist, als die Fehlerprüfung auf relationaler Ebene, ist vom Einsatz dieser Strategie abzuraten. Die Strategie 6 liefert zudem schlechtere Ergebnisse als die „sichere“ Strategie 2, bei der die referentielle Integrität nach der Befüllung geprüft wird.
Fazit: Muss man vom regulären Prozess (Strategie 1) abweichen, sollte mit Strategie 2 gearbeitet werden, da hier ein deutlicher Performance-Gewinn möglich ist und die referentielle Integrität der Daten gewahrt bleibt.
Exkurs: Kombination von Strategie 2 mit Columnstore-Indizes
Columnstore-Indizes führen durch ihre starke Kompression dazu, dass gerade bei großen Datenmengen der Speicherplatzbedarf stark reduziert werden kann. Daher wird in diesem Szenario zunächst auf den Faktentabellen unserer Testumgebung jeweils ein Columnstore-Index erzeugt. Dafür muss zuvor der Primary Key der Tabellen gelöscht werden, da Columnstore-Indizes nicht in Verbindung mit Primary Keys eingesetzt werden können. Anschließend wird analog Strategie 2 vorgegangen, die aus den vorherigen Tests als Favorit hervorgegangen ist.
Hinweis: entscheidet man sich im Projekt für den Einsatz von Columnstore-Indizes, so muss individuell für deren Erstellung und Verwaltung gesorgt werden. Beispielsweise kann im Postprocess des Schritts „Create relational schema“ (Prozedur P_BC_CreateSnowflake_PostProcess) dafür gesorgt werden, dass zunächst die Primary Keys der betroffenen Tabellen gelöscht werden, um anschließend die Columnstore-Indizes zu erstellen.
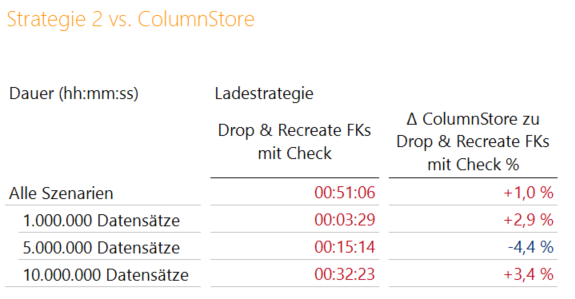
Abbildung 2: Vergleich zwischen Strategie 2 und der Coulmnstore-Index Variante
Das Ergebnis zeigt, dass der Einsatz der Columnstore-Index Variante nur geringen Einfluss auf die Ergebnisse hat. Somit ist eine Kombination der beiden Techniken eine Überlegung wert, da mit Columnstore-Indizes hohe Kompressionsraten möglich sind.
Welche Gründe kann es geben vom regulären Prozess abzuweichen?
Eine Abweichung von der normalen Verarbeitung kommt eigentlich nur in Frage, wenn man Zeitproblemen bei der Verarbeitung hat, z. B. wenn die „Nacht nicht lange genug ist“ für die Verarbeitung, große Faktentabellen aber trotzdem neu geladen werden müssen, also nicht über eine Archiv-Logik gearbeitet werden kann.
Hat man keine Probleme mit der Verarbeitungszeit, ist ein Abweichen vom DeltaMaster-ETL-Standard keinesfalls empfehlenswert. Zudem sollte immer zunächst geprüft werden, ob eine Optimierung nicht auch über einfachere Wege möglich ist (z. B. Indizes, um Joins zu optimieren etc.). Fraglich ist auch, ob die Foreign-Key-Strategie in jedem Fall weiterhilft. Ist z. B. die Logik der Source-View sehr komplex (z. B. durch viele Joins und Common Table Expressions) nützt eine Optimierung beim Schreiben der Daten in die Faktentabelle vermutlich wenig.
Implementierung einer Ladestrategie
Abschließend soll der Frage nachgegangen werden, wie die Ladestrategie 2 in ein DeltaMaster-ETL-Modell implementiert werden kann, ohne den Standard zu zerstören und das Modell für die künftige Nutzung von DeltaMaster ETL unbrauchbar zu machen. Das Ziel muss also sein, dass Meta-Model-Updates und das Ausführen der Schritte „Create relational schema“, „Fill relational schema“, „Create OLAP database“ und „Fill OLAP database“ weiterhin möglich sind.
Da die Ausführung der Faktenprozeduren (Namensraum P_FACT) in einem Schritt von der Prozedur „P_Transform_13_P_FACTs_Ausfhren“ für alle Prozeduren auf einmal übernommen wird, ist es schwierig in diesem Teil des Prozesses Änderungen an den Foreign Keys vorzunehmen.
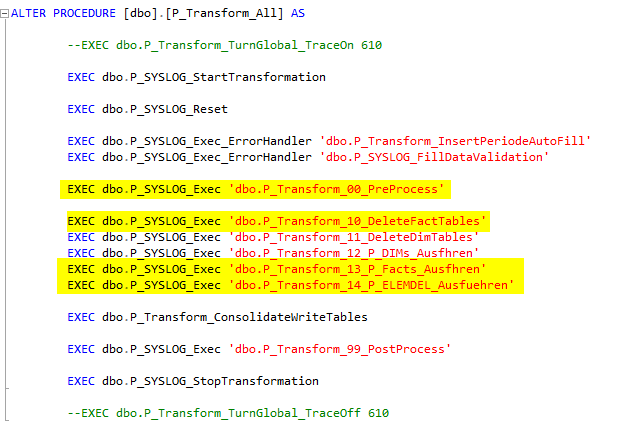
Abbildung 3: Typischer Aufbau der Prozedur P_Transform_All
Es empfiehlt sich also Folgendes:
Im PreProcess des Schritts „Fill relational schema” (Prozedur „P_Transform_All“) kann für die Faktenpartitionen gesteuert werden, ob diese gelöscht oder befüllt werden sollen. Sinnvoll wäre es, dass die T_FACT-Tabellen, die neu befüllt werden sollen, zwar während des regulären Transforms geleert werden, die Neubefüllung jedoch erst nachgelagert stattfindet. Somit kann in der PreProcess-Prozedur P_Transform_00_PreProcess z. B. folgendes Statement eingebaut werden:
UPDATE st set st.DoDeleteTable = 1 ,st.DoFillTable = 0 from dbo.T_Model_Fact_SourceTable st WHERE st.FactID = 6
Es bewirkt, dass die 3 Faktentabellen für unsere Test-Measuregroup (FactID 6) während des Transforms geleert, jedoch nicht neu befüllt werden. Das ist gleichbedeuten mit dem Setzen der Flags „Delete Partition Content“ und „Fill Partition“ im DeltaMaster-ETL-Bericht „Measure Group Source Tables/Partitions“.
Doch an welcher Stelle würde es nun Sinn ergeben, die Fakten der Measuregroup 6 nachzuladen?
Um zu verhindern, dass die Prozedur P_Transform_14_P_ELEMDEL_Ausfuehren in den Fakten nicht benötigte Dimensions-Elemente aus den Dimensionstabellen herauslöscht, die für unsere noch leere Measuregroup 6 eigentlich benötigt werden, sollte der „Eingriff“ zwischen den Prozeduren P_Transform_13_P_Facts_Ausfhren und P_Transform_14_ELEMDEL_Ausfuehren erfolgen. Es empfiehlt sich, die Logik in eine eigene Prozedur auszulagern (z. B. P_APP_Transform_MsrGrp6).
Die Anpassung der P_Transform_All-Prozedur ist unproblematisch, da diese nur bei der initialen Erstellung der Metamodells angelegt wird und anschließend für projektspezifische Zwecke angepasst werden darf. Bei Aktualisierung des Metamodells wird sie nicht überschrieben.
Folgende Schritte sollten in der P_APP-Prozedur durchgeführt werden:
- Befüllung der Partitionen aktivieren
- Löschen der Foreign Key-Constraints
- Ausführen der Faktenprozeduren (Einbindung ins Logging über P_SYSLOG_Exec)
- Wiederherstellen der Foreign Key-Constraints, inkl. Prüfung der referentiellen Integrität
- Befüllung der Partitionen deaktivieren

CREATE PROC [dbo].[P_APP_Transform_MsrGrp6] AS
-- Del-Fill-Logic
UPDATE st
SET st.DoFillTable = 1
FROM
dbo.T_Model_Fact_SourceTable st
WHERE
st.FactID = 6;
-- Drop FKs
EXEC [dbo].[P_BC_Drop_T_FACT_FKConstraints] @FactID = 6, @PartitionID = 1, @IncludePK = 0;
-- Load Facts
EXEC P_SYSLOG_Exec 'P_FACT_06_Deckungsbeitragsrechnung_bigData_01_V_Import_Fact_Deckungsbeitragsrechnung_1000000';
-- Recreate FKs
EXEC dbo.P_BC_Create_T_FACT_FKConstraints @FactID = 6, @PartitionID = 1, @IncludePK = 0, @DoCheck
= 1;
-- Drop FKs
EXEC [dbo].[P_BC_Drop_T_FACT_FKConstraints] @FactID = 6, @PartitionID = 2, @IncludePK = 0;
-- Load Facts
EXEC P_SYSLOG_Exec 'P_FACT_06_Deckungsbeitragsrechnung_bigData_02_V_Import_Fact_Deckungsbeitragsrechnung_5000000';
-- Recreate FKs
EXEC dbo.P_BC_Create_T_FACT_FKConstraints @FactID = 6, @PartitionID = 2, @IncludePK = 0, @DoCheck
= 1;
-- Drop FKs
EXEC [dbo].[P_BC_Drop_T_FACT_FKConstraints] @FactID = 6, @PartitionID = 3, @IncludePK = 0;
-- Load Facts
EXEC P_SYSLOG_Exec 'P_FACT_06_Deckungsbeitragsrechnung_bigData_03_V_Import_Fact_Deckungsbeitragsrechnung_10000000';
-- Recreate FKs
EXEC dbo.P_BC_Create_T_FACT_FKConstraints @FactID = 6, @PartitionID = 3, @IncludePK = 0, @DoCheck
= 1;
-- Del-Fill-Logic
UPDATE st
SET st.DoFillTable = 0
FROM
dbo.T_Model_Fact_SourceTable st
WHERE
st.FactID = 6;Und wenn es Foreign Key-Fehler gibt?
Natürlich kann es bei der Neuerstellung der Foreign Keys auf der bereits befüllten Tabelle zu Foreign Key-Fehlern kommen. Ohne Fehlerbehandlung würde ein solcher Fehler dazu führen, dass der Ladeprozess komplett abbricht.
Eine Möglichkeit, das abzufangen und das Neuerstellen der Foreign Keys in das Logging von DeltaMaster ETL einzubinden liefert der folgende Code:

Declare @return_status int
Declare @rc int
Declare @err_msg varchar(1000)
Declare @err_id int
exec dbo.P_SYSLOG_StartLog 'Recreate FKs for FACT_06_Deckungsbeitragsrechnung_bigData_01'
BEGIN TRY
EXEC dbo.P_BC_Create_T_FACT_FKConstraints @FactID = 6, @PartitionID = 1, @IncludePK = 0, @DoCheck = 1;
END TRY
BEGIN CATCH
SELECT @err_id = error_number()
SELECT @err_msg = CONVERT(varchar,error_number()) + ' - ' + error_message()
--Fill return status
SELECT @return_status =
CASE error_number()
WHEN 547 THEN -6
WHEN 2627 THEN -4
ELSE -9
END
END CATCH
exec dbo.P_SYSLOG_StopLog 'Recreate FKs for FACT_06_Deckungsbeitragsrechnung_bigData_01',
@return_status, @rc, @err_msgDurch den Try-Catch-Block wird der Fehler ermittelt, im Logging hinterlegt und der Rest des Prozesses fortgesetzt.

Abbildung 4: Einbindung von Foreign Key-Fehlern in das DeltaMaster ETL-Logging
Zusätzlich kann im Catch-Block ein detailliertes Fehlerlogging durchgeführt werden, indem die Prozedur P_Check_Fact aus der DeltaMaster-ETL-Toolbox aufgerufen wird.
EXEC [dbo].[P_Check_Fact] @FactID = 6, @SourceTableID = 1
Die präzisen Ergebnisse dieses Loggings sind dann im Bericht „Data Errors“ der DeltaMaster-ETL-Anwendung nachvollziehbar. Ob dieses Logging notwendig ist, muss im Projekt abgewogen werden, da die Laufzeit für die Prüfung im Fehlerfall unter Umständen beträchtlich sein kann. Dafür wird jedoch die Zeit, die für die Fehlersuche benötigt wird, reduziert.

Abbildung 5: Beispiel Bericht “Data Errors”
Wichtig: Die Faktentabelle mit der Fremdschlüsselverletzung bleibt zunächst befüllt. Das bedeutet, dass es beim Ausführen des Schritts „Fill OLAP database“ zu einem Verarbeitungsfehler kommen würde. Es sollte somit unbedingt darauf geachtet werden, dass der Schritt „Fill OLAP database“ im Fehlerfall nicht ausgeführt wird.
Bei regulären DeltaMaster-ETL-Prozessen, bei denen die Foreign Keys während der Transformation auf der Faktentabelle erhalten bleiben, würde die Tabelle im Fehlerfall komplett leer bleiben und ein anschließendes Verarbeiten der OLAP-Datenbank würde nicht zum Fehler führen.
Fazit
In bestimmten Konstellationen können Foreign Keys einen negativen Einfluss beim Befüllen von Tabellen haben. In diesen Fällen kann es Sinn ergeben, die Foreign Keys vor der Befüllung der Tabelle zu löschen und erst anschließend wieder zu erzeugen.
Es konnte gezeigt werden, dass dieser Spezialfall, auch in DeltaMaster-ETL-Modellen, umsetzbar ist, ohne das Modell für künftige Erweiterungen unbrauchbar zu machen (z. B. Ausführung der Schritte „Create relational schema“, „Create OLAP database“).
