Die Zuweisung von Datentypen in Datenbanken wird oft stiefmütterlich behandelt. Die daraus resultierende, oft notwendige implizite Konvertierung der Daten kann erhebliche Performanceeinbußen nach sich ziehen und in bester Absicht erstellte Indizes zu Statisten degradieren. Bei großen Datenmengen hat die Wahl des Datentyps auch entscheidenden Einfluss auf die Speichergröße der Datenbank. Datentypen verdienen demnach häufig mehr Beachtung als wir ihnen zukommen lassen.
Datentypen im Überblick
Im SQL-Server steht eine Vielzahl verschiedener Datentypen zur Auswahl. Die Wahl des richtigen Datentyps passend zu den Inhalten ist vor allem bei großen Datenbanken bzw. großen Datenmengen von entscheidender Bedeutung für Effizienz, Performance und Speicheroptimierung. Generell sollte bei der Auswahl der Datentyp gewählt werden, der die Daten vollumfänglich abbildet und dabei die kleinste Speichergröße aufweist. So ist beispielsweise für Datumsfelder meist smalldatetime völlig ausreichend und benötigt nur die Hälfte des Speicherplatzes im Vergleich zu datetime. Anbei eine Auflistung der wichtigsten Datentypen mit Datenbereich und benötigtem Speicher:
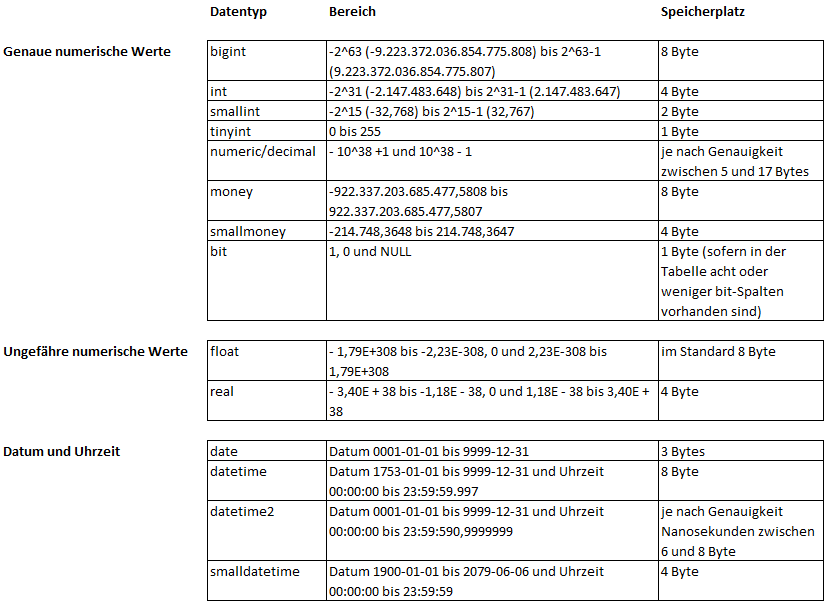
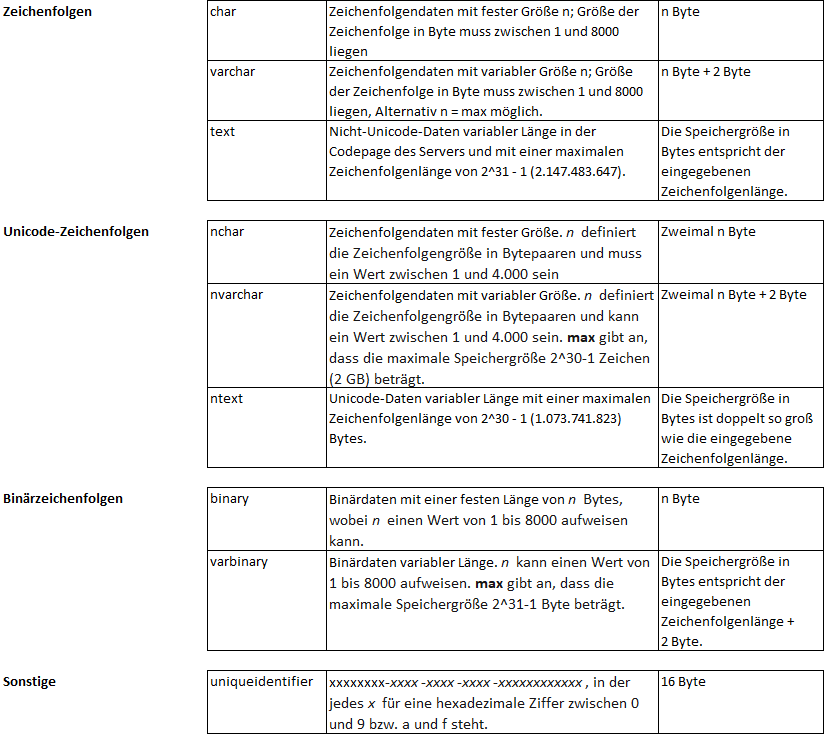 Abbildung 1: Auflistung der wichtigsten Datentypen
Abbildung 1: Auflistung der wichtigsten Datentypen
Rangfolge und implizite Konvertierung
Wenn in verschiedenen Tabellen Spalten mit dem gleichen Inhalt existieren, können diese trotzdem als unterschiedliche Datentypen definiert sein. Sobald diese Spalten aber über JOINs oder generelle Operatoren in Verbindung gebracht werden, müssen die unterschiedlichen Datentypen vereinheitlicht werden. Geschieht dies nicht User-gesteuert über eine explizite Konvertierung mittels CAST oder CONVERT, übernimmt der SQL-Server die Aufgabe selbständig und versucht den rangniedrigeren Datentypen zum ranghöheren Datentypen zu konvertieren. SQL-Server verwendet hierfür folgende Rangfolge:
- benutzerdefinierte Datentypen (höchster)
- sql_variant
- xml
- datetimeoffset
- datetime2
- datetime
- smalldatetime
- date
- time
- float
- real
- decimal
- money
- smallmoney
- bigint
- int
- smallint
- tinyint
- bit
- ntext
- text
- image
- timestamp
- uniqueidentifier
- nvarchar (einschließlich nvarchar(max))
- nchar
- varchar (einschließlich varchar(max))
- char
- varbinary (einschließlich varbinary(max))
- binary (niedrigster)
(Quelle: https://docs.microsoft.com/de-de/sql/t-sql/data-types/data-type-precedence-transact-sql)
Das heißt, ein JOIN über eine numerische Spalte mit einer Textspalte wird implizit immer zu einem numerischen Wert konvertiert. Ist dies nicht möglich, wird eine entsprechende Fehlermeldung ausgegeben.
Zur Veranschaulichung können wir eine einfache Tabelle erstellen mit einer Spalte von Typ integer und zwei Spalten von Typ varchar mit unterschiedlichen Datenwerten:
CREATE TABLE [dbo].[T_S_Datentypen]( [int] [int] NULL, [varchar] [varchar](50) NULL, [varchar2] [varchar](50) NULL ) ON [PRIMARY] GO INSERT [dbo].[T_S_Datentypen] ([int], [varchar], [varchar2]) VALUES (2, NULL, 'abc') INSERT [dbo].[T_S_Datentypen] ([int], [varchar], [varchar2]) VALUES (1, '1', '1') GO
Implizite Konvertierungen sind immer im Ausführungsplan ersichtlich. Ein Warnzeichen weist jeweils darauf hin. Ein JOIN der Testtabelle mit sich selbst über die Spalten [int] und [varchar] liefert einen Hinweis im Ausführungsplan, an dem zudem deutlich wird, dass die Konvertierung zum Datentyp integer erfolgen soll:
SELECT * FROM dbo.T_S_Datentypen d1 INNER JOIN dbo.T_S_Datentypen d2 ON d1.[int] = d2.[varchar]
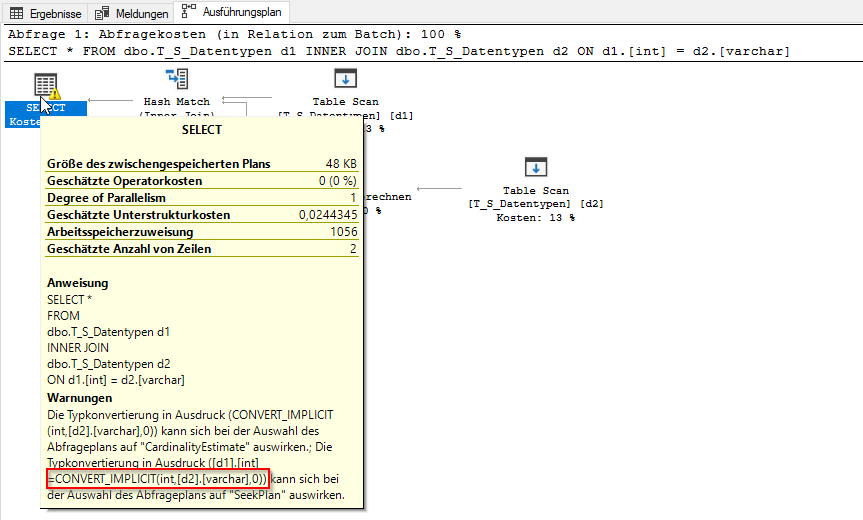 Abbildung 2: Ausführungsplan mit impliziter Konvertierung
Abbildung 2: Ausführungsplan mit impliziter Konvertierung
Beim JOIN-Versuch über die Spalte [varchar2], deren Datenwert „abc“ nicht in ein numerisches Format konvertiert werden kann, wird eine entsprechende Fehlermeldung ausgegeben:
SELECT * FROM dbo.T_S_Datentypen d1 INNER JOIN dbo.T_S_Datentypen d2 ON d1.[int] = d2.[varchar2]

Abbildung 3: Fehlermeldung bei fehlgeschlagener Konvertierung
Die implizite Konvertierung findet auch an anderen Stellen statt, z. B. wenn eine Filtereinschränkung auf einer Textspalte nicht als Text definiert ist (‚1‘ = 1). Ist die implizite Konvertierung nicht möglich (‚abc‘ = 1), gibt der SQL-Server auch hier einen entsprechenden Fehler zurück.
Bei Zuweisungsanweisungen ohne Vergleichsoperatoren, wie dem Einfügen von neuen Werten in eine Spalte oder dem Festlegen von Variablen, wird der Datentyp der Spalten- bzw. der Variablendefinition verwendet. Das Einfügen eines neuen Datensatzes in unsere Tabelle ohne explizites Kennzeichnen des Wertes der Spalte [varchar] als Text erfolgt automatisch im richtigen Format:
INSERT [dbo].[T_S_Datentypen] ([int], [varchar], [varchar2]) VALUES (2, 2, '1') GO
Performance und Indizes
Unter Umständen ist es mit erheblichen Performanceeinbußen verbunden, wenn verschiedene Datentypen implizit konvertiert werden müssen. Vor allem auch bei Verwendung von Indizes kann es bei großen Datenmengen zu signifikanten Zeiteinbußen kommen, da nicht der optimierte Index Seek, sondern ein vollständiger Index Scan ausgeführt wird. Somit werden nicht nur relevante Datensätze durchsucht, sondern konsequent alle Datensätze der entsprechenden Tabelle. Die Vorteile des Indizes sind damit komplett ausgehebelt.
Wenn wir einen Index auf unsere Beispieltabelle erstellen, zeigt sich die entsprechende Veränderung im Ausführungsplan, je nachdem ob konvertiert werden muss oder nicht.
CREATE CLUSTERED INDEX IX_T_S_Datentypen_varchar ON dbo.T_S_Datentypen ([varchar]) GO
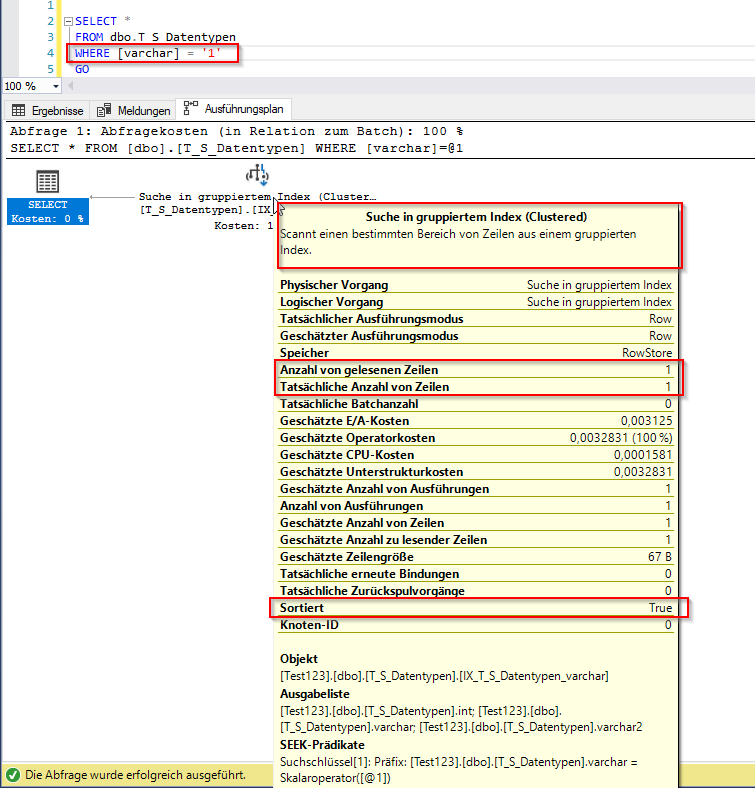 Abbildung 4: Ausführungsplan mit Index ohne Konvertierung
Abbildung 4: Ausführungsplan mit Index ohne Konvertierung
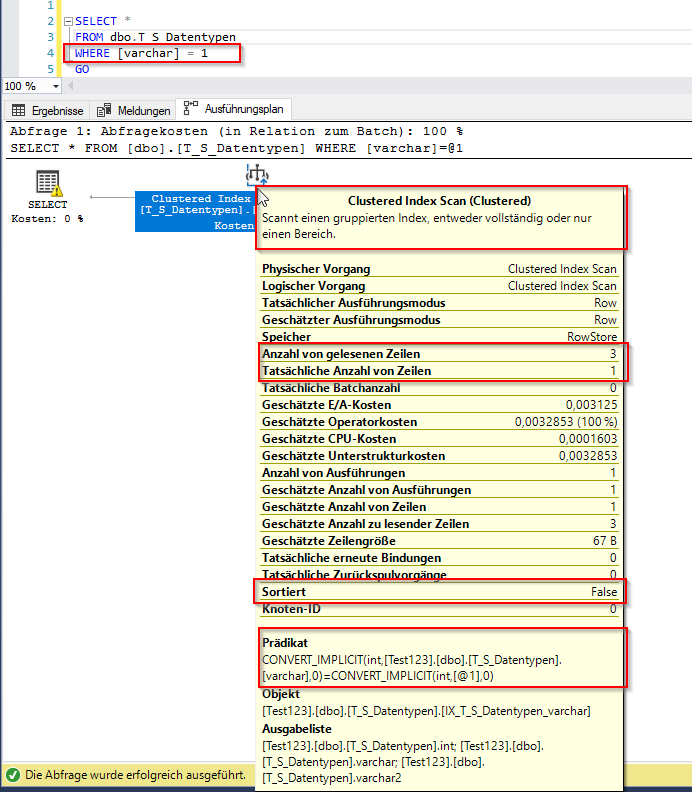 Abbildung 5: Ausführungsplan mit Index bei impliziter Konvertierung
Abbildung 5: Ausführungsplan mit Index bei impliziter Konvertierung
Schon in unserem kleinen Beispiel lassen sich die Unterschiede der gelesenen Zeilen sehr gut erkennen. Die Performance kann sich somit um ein Vielfaches verbessern, wenn auf die Verwendung konsistenter Datentypen geachtet wird. Der Index Scan kann auch zugunsten des Index Seeks vermieden werden, wenn die Datentypkonvertierung explizit über CAST oder CONVERT im Statement angegeben wird, sofern eine Angleichung der Datentypen sonst nicht möglich ist.
Unterschied der Datentypen bei COALESCE und ISNULL
Eine Besonderheit bei der Zuweisung von Datentypen ist zudem noch bei Verwendung von COALESCE und ISNULL zu berücksichtigen: bei COALESCE wird der ranghöchste Datentyp zugewiesen, bei ISNULL wird der Datentyp des ersten Ausdrucks verwendet.
Im Beispiel erstellen wir hierfür eine View aus unserer Testtabelle:
CREATE VIEW dbo.V_S_Datentypen AS SELECT COALESCE([varchar],[int]) as Test1 ,ISNULL([varchar],[int]) as Test2 FROM dbo.T_S_Datentypen GO
Im Ergebnis hat die durch COALESCE ermittelte Spalte den Datentyp integer, die durch ISNULL ermittelte Spalte den Datentyp varchar.
 Abbildung 6: Datentypen bei COALESCE und ISNULL
Abbildung 6: Datentypen bei COALESCE und ISNULL
Fazit
Beim Aufbau der Datenbank und beim Erstellen von Code in Datenbanken mit inkonsistenten Datentypen kann viel für Performance getan werden, wenn auf die korrekte Konvertierung geachtet wird. Es lohnt sich also immer, den Datentypen besondere Aufmerksamkeit zukommen zu lassen, vor allem wenn Abfragen optimiert werden sollen oder Indizes benötigt werden.
