Wenn sich Datentypen im Vorsystem, aus welchem Daten in Tabellen einer SQL-Server-Datenbank importiert werden, ändern, ist oft großer manueller Aufwand notwendig, um alle betroffenen Tabellen und Spalten zu identifizieren und anzupassen. In diesem Blogbeitrag wird eine Lösung mithilfe von Systemtabellen vorgeschlagen, die es ermöglicht, die Datentypänderung automatisch per Prozedur vorzunehmen.
In unseren Modellen greifen wir meistens auf Daten externer Vorsysteme eines Kunden zurück. Das kann eine oder auch eine Vielzahl von Quellen sein, aus welchen wir die erforderlichen Daten für die gewünschten Auswertungen und Analysen für den Kunden extrahieren und oftmals in einer neuen relationalen Datenbank auf SQL-Server-Basis speichern. In dieser neuen SQL-Server-Datenbank werden da-für die notwendigen Tabellen mit den entsprechenden Spalten und deren Datentypen von uns erstellt.
Nun gibt es zwei Ansätze, wie wir die Daten aus einem Vorsystem importieren können – entweder man importiert alle Werte als Text und formatiert sich die Daten im nachfolgenden Schritt in den jeweils er-forderlichen Datentyp oder man importiert entsprechend der Datentypen im Vorsystem gleich in die adäquaten Datentypen in der SQL-Server-Datenbank (im nachfolgenden als Zieldatenbank bezeichnet).
Bei beiden Ansätzen kann es vorkommen, dass sich die Datentypen im Vorsystem ändern und unsere Tabellen in der Zieldatenbank angepasst werden müssen. Betrifft dies nur eine Spalte in einer Tabelle, ist dies einfach zu lösen, indem man manuell den Datentyp der betroffenen Spalte in der Tabelle verändert. Was aber tun, wenn es mehrere Spalten in einer Vielzahl von Tabellen betrifft?
In diesem Blogbeitrag soll hierfür eine Lösung mittels einer SQL-Prozedur vorgestellt werden.
Szenario
Gehen wir von folgendem Szenario aus: Im Vorsystem ändern sich alle bisher als Nicht-Unicode-Zeichenfolgen bereitgestellten Daten in Unicode. Die aufnehmenden Importtabellen in der Zieldatenbank enthalten für alle oder zumindest für alle Zeichenfolgendatenspalten den Datentyp varchar. Damit die Änderung im Vorsystem nicht zu Fehlern während des Datenimports führt, müssen alle betroffenen Spalten in allen Importtabellen auf den Datentyp nvarchar umgestellt werden. Eine manuelle Umstellung kann hier sehr schnell sehr aufwändig werden.
Auch der Transact-SQL-Befehl:
![]()
ALTER TABLE ALTER COLUMN nvarchar() müsste für jede Tabelle und jede zu ändernde Spalte einzeln ausgeführt werden.
Der Grundgedanke für die hier vorgestellte Lösung besteht in der Nutzung der Systemtabellen des SQL-Servers für eine Prozedur, die genau diese Befehlszeile für jede Tabelle und jede darin enthaltene und betroffene Spalte der Importtabellen ausführt. Eine Übersicht über die Systemtabellen/-sichten erhält man in der MSDN von Microsoft unter dem Suchbegriff „Katalogsichten für Objekte (Transact-SQL)“.
Die nachfolgend aufgeführten SQL-Statements wurden beispielhaft auf unserer beliebten Demodatenbank Chair ausgeführt.
Vorgehensweise
Tabellenspalten ohne Index oder Primary Key
Aus den vorhandenen Systemtabellen müssen zunächst die relevanten Tabellen herausgefunden wer-den, welche die Tabellen- und Spaltendefinitionen enthalten.
Um alle Importtabellen in einer Datenbank zu ermitteln, brauchen wir die Tabelle sys.objects oder sys.tables, die Spaltendefinitionen finden sich in der Tabelle sys.columns. Der select-Befehl zum Ermitteln aller betroffenen Tabellen könnte wie folgt lauten, wenn beispielsweise alle Importtabellen mit dem Präfix „T_Import“ beginnen:
 +
+
SELECT
sys.objects.name
FROM
sys.objects
WHERE
sys.objects.type = 'U' -- U steht hier für User-Table
AND sys.objects.name LIKE 'T_IMPORT%'
Oder für die Verwendung der Tabelle sys.tables:
SELECT
sys.tables.name
FROM
sys.tables
WHERE
sys.tables.name LIKE 'T_IMPORT%'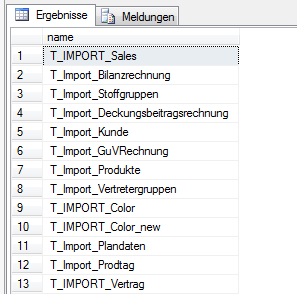
Abbildung 1: Ermitteln aller relevanten Importtabellen
Bei einem select über die Tabelle sys.columns für eine bestimmte Tabelle werden wir feststellen, dass der Datentyp in der Spalte „system_type_id“ als Code und nicht als Name gespeichert ist. Hier ist ein zusätzlicher Join über die Tabelle sys.types erforderlich. Im Folgenden wird als Beispieltabelle die Tabelle T_Import_Deckungsbeitragsrechnung verwendet. Das Statement für das Ermitteln der Datentypen dieser Tabelle würde dann wie folgt aussehen:
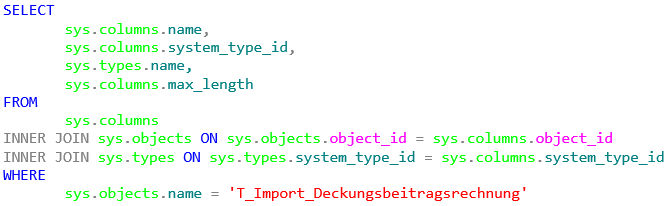
SELECT
sys.columns.name,
sys.columns.system_type_id,
sys.types.name,
sys.columns.max_length
FROM
sys.columns
INNER JOIN sys.objects ON sys.objects.object_id = sys.columns.object_id
INNER JOIN sys.types ON sys.types.system_type_id = sys.columns.system_type_id
WHERE
sys.objects.name = 'T_Import_Deckungsbeitragsrechnung'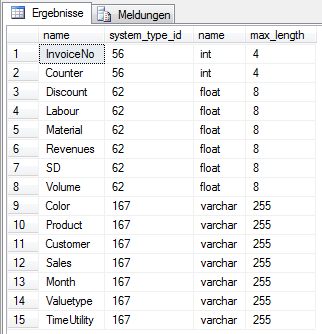
Abbildung 2: Ermitteln der Spalten einer Tabelle
Um aus allen Spalten nur die gewünschte Spalten vom Typ varchar zu filtern, ist die WHERE-Bedingung um die Bedingung ![]() zu ergänzen
zu ergänzen

SELECT
sys.columns.name,
sys.columns.max_length,
sys.columns.is_nullable
FROM
sys.columns
INNER JOIN sys.objects ON sys.objects.object_id = sys.columns.object_id
INNER JOIN sys.types ON sys.types.system_type_id = sys.columns.system_type_id
WHERE
sys.objects.name = 'T_Import_Deckungsbeitragsrechnung'
AND sys.types.name = 'varchar'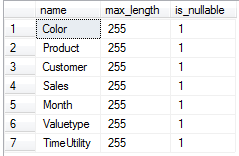
Abbildung 3: Ermitteln der Spalten vom Typ varchar der Tabelle T_Import_Deckungsbeitragsrechnung
Die Spaltenlänge und ob es sich bei der Spalte um eine NULL- oder NOT-NULL-Spalte handelt, soll wiederum nicht verändert werden, ist aber für die Ausführung der Änderung des Spaltentyps erforder-lich. Die Information für die Spaltenlänge ist im Feld „max_length“, für die NULL-Zulässigkeit in der Spalte „is_nullable“ der Tabelle sys.columns gespeichert.
Hätten wir damit alle Informationen, die wir zum Ändern des Spaltentyps varchar in nvarchar in unseren Importtabellen brauchen, beisammen? Wenn auf den zu ändernden Tabellenspalten kein Index und auch kein PrimaryKey liegen, wäre das tatsächlich alles, was wir an Informationen benötigen. Ein Cursor über alle relevanten Tabellen und ein weiterer Cursor über deren Spalten ermöglicht das Ändern des Spaltentyps z.B. von varchar in nvarchar.
Das Skript für die Prozedur “P_ALTER_TABLE_COLUMNS_wo_INDIZES“ befindet sich im Zusatzmaterial.
Tabellenspalten mit Index oder Primary Key
Tabellenspalten, welche in einen Index oder Primary Key eingebunden sind, können nicht ohne Aufhebung dieser Bindung geändert werden. Daher müssen vor einer Änderung alle Indizes oder Primary Keys, welche zu ändernde Spalten enthalten, gelöscht werden.
Sinnvollerweise sollte unsere neue Prozedur, welches eine Datentypänderung bei Spalten mit Index oder Primary Key beinhaltet, sich die Skripte zum Neuerstellen der betroffenen Indizes und Primary Keys vor dem Löschen merken, um sie nach der Änderung des Datentyps wieder neu erzeugen zu können.
Um dieses Szenario beispielhaft auf der Datenbank Chair und deren Tabelle T_Import_Deckungsbeitragsrechnung zu simulieren, müssen wir diese Tabelle um eine Spalte ergänzen, die wir mit einem Primary Key versehen können.
Dafür fügen wir dieser Tabelle eine neue Spalte „InvoiceNo_unique“ hinzu, füllen diese Spalte mit der InvoiceNo + ValueType, setzen die Spalte auf „NOT NULL“ und legen auf diese Spalte einen Primary Key:
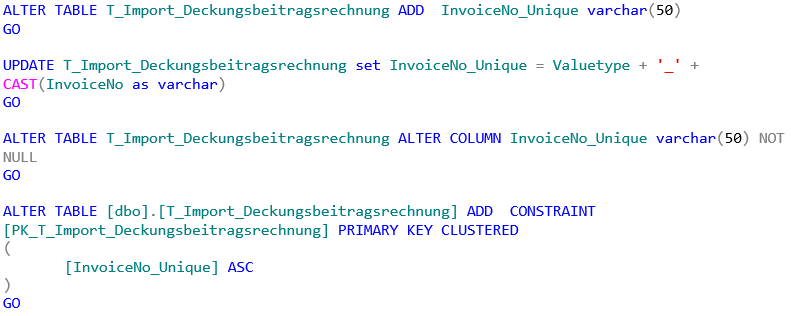
ALTER TABLE T_Import_Deckungsbeitragsrechnung ADD InvoiceNo_Unique varchar(50)
GO
UPDATE T_Import_Deckungsbeitragsrechnung set InvoiceNo_Unique = Valuetype + '_' + CAST(InvoiceNo as varchar)
GO
ALTER TABLE T_Import_Deckungsbeitragsrechnung ALTER COLUMN InvoiceNo_Unique varchar(50) NOT NULL
GO
ALTER TABLE [dbo].[T_Import_Deckungsbeitragsrechnung] ADD CONSTRAINT [PK_T_Import_Deckungsbeitragsrechnung] PRIMARY KEY CLUSTERED
(
[InvoiceNo_Unique] ASC
)
GODer Versuch, den Datentyp dieser Spalte zu ändern, führt jetzt zu einem Fehler:
![]()
ALTER TABLE T_Import_Deckungsbeitragsrechnung ALTER COLUMN InvoiceNo_Unique nvarchar(50)
Abbildung 4: Fehlermeldung bei Datentypänderung einer Spalte mit Primary Key
Darüber hinaus legen wir noch einen nicht-gruppierten Index auf die Spalten Month und Customer:

CREATE NONCLUSTERED INDEX [IX_T_Import_Deckungsbeitragsrechnung] ON [dbo].[T_Import_Deckungsbeitragsrechnung]
(
[Month] ASC,
[Customer] ASC
)Auch für diese Spalten funktioniert die Datentypänderung jetzt nicht:
![]()
ALTER TABLE T_Import_Deckungsbeitragsrechnung ALTER COLUMN Customer nvarchar(50)
Abbildung 5: Fehlermeldung bei Datentypänderung einer indizierten Spalte
Das ist eine Einschränkung für die gerade entwickelte Prozedur “P_ALTER_TABLE_COLUMNS_wo_INDIZES“. Importtabellen weisen in den meisten Fällen keine Indizes oder Primary Keys auf. Wenn aber doch, muss auch hierfür eine Lösung her und dafür können wieder die Systemtabellen herangezogen werden.
Die Informationen zu den vorhandenen Indizes einer Tabelle finden sich in der Systemtabelle sys.indexes, die in den jeweiligen Index eingeschlossenen Spalten in der Tabelle sys.index_columns.
Das SQL-Statement zum Ermitteln der Indexinformationen lautet dann:
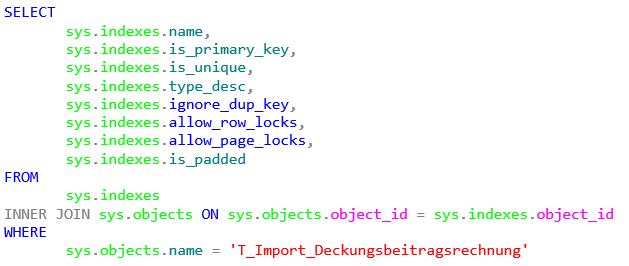
SELECT
sys.indexes.name,
sys.indexes.is_primary_key,
sys.indexes.is_unique,
sys.indexes.type_desc,
sys.indexes.ignore_dup_key,
sys.indexes.allow_row_locks,
sys.indexes.allow_page_locks,
sys.indexes.is_padded
FROM
sys.indexes
INNER JOIN sys.objects ON sys.objects.object_id = sys.indexes.object_id
WHERE
sys.objects.name = 'T_Import_Deckungsbeitragsrechnung'
Abbildung 6: Ermitteln der Indexinformationen einer Tabelle
Die von dem Index bzw. Primary Key eingeschlossenen Spalten einer Tabelle können mit folgendem Statement ermittelt werden:

SELECT
sys.columns.name,
sys.index_columns.is_descending_key
FROM sys.index_columns
inner join sys.indexes ON sys.indexes.index_id = sys.index_columns.index_id and sys.indexes.object_id = sys.index_columns.object_id
INNER JOIN sys.objects ON sys.objects.object_id = sys.indexes.object_id
INNER JOIN sys.columns ON sys.columns.object_id = sys.objects.object_id and sys.columns.column_id = sys.index_columns.column_id
WHERE
sys.objects.name = 'T_Import_Deckungsbeitragsrechnung'
AND sys.indexes.name = 'PK_T_Import_Deckungsbeitragsrechnung'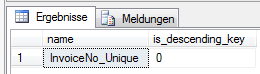
Abbildung 7: Ermitteln der Indexspalten (hier für den Primary Key ausgeführt)
Im SQL-Skript “P_ALTER_TABLE_COLUMNS_WITH_INDIZES”, welches im Zusatzmaterial zu finden ist, sind alle Schritte enthalten, die notwendig sind, um für jeden Index bzw. Primary Key jeder Tabelle die ent-sprechenden Informationen zu ermitteln und jeweils zu einem Statement für das Löschen und das Neu-erstellen zusammenzustellen und zwischenzuspeichern. Nachfolgend werden der jeweilige Index/Primary Key gelöscht, die Datentypen der jeweiligen Spalten wie bereits beschrieben aktualisiert und der Index wieder neu erstellt.
Noch ein Hinweis:
Sind auf einer Tabelle Fremdschlüssel (Foreign Key Constraints) vorhanden, ist keine automatische Datentypänderung der involvierten Spalten möglich, da die Datentypen der Spalten miteinander verknüpf-ter Tabellen identisch sein müssen und nicht einseitig geändert werden können.
„Ein Fremdschlüssel (FS) ist eine Spalte oder eine Kombination von Spalten, mit deren Hilfe eine Verknüpfung zwischen den Daten in zwei Tabellen eingerichtet und erzwungen wird.“ (https://technet.microsoft.com/de-de/library/ms175464%28v=sql.105%29.aspx)
