Wenn man von der Datenanalyse mit Microsoft Azure hört, stellt man sich unweigerlich einige Fragen: Wie funktioniert die Einrichtung einer Azure-Infrastruktur? Was ist gemeint mit Begriffen wie „Data Lake“ oder „Azure Data Factory“? Wozu braucht man das in einer modernen Azure-Architektur? Wie importiert man On-Premises-Daten nach Azure? Dieser Beitrag gibt dazu Antworten.
Immer mehr Unternehmen verlagern ihre IT-Infrastruktur in Teilen oder gänzlich in die Cloud. Dabei beschäftigen sie sich unter anderem mit der Aufgabe, Daten aus On-Premises-Systemen nach Azure zu verschieben, um weitere Transformation und Analysen mit Hilfe von Azure-Diensten zu ermöglichen.
Dieser Beitrag beschreibt, wie Daten aus einer On-Premises-SQL-Datenbank in eine Azure-SQL-Datenbank oder ein Azure Data Lake Storage Gen2 importiert werden. Hier stehen sie für weitere Schritte wie Datentransformationen und -analysen zur Verfügung stehen, die allerdings nicht in diesem Beitrag behandelt werden.
Architektur
Die Abbildung 1 zeigt die Architektur für den Import der On-Premises-SQL-Daten in eine Azure-SQL-Datenbank.
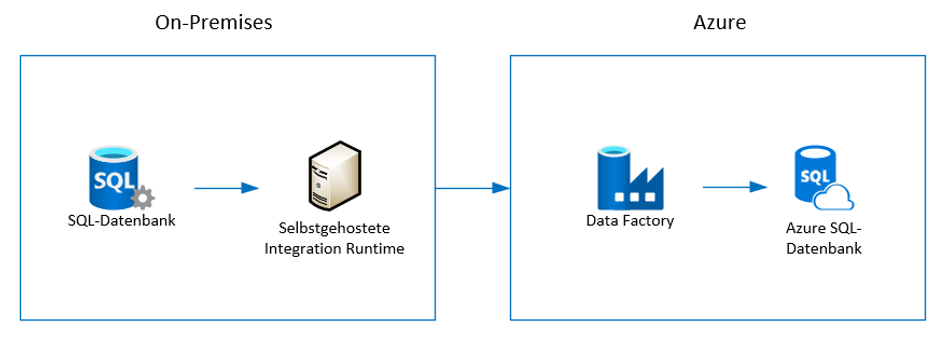
Abb.1: Architektur des Datenimports von einer On-Premises-SQL-Datenbank in Azure-SQL-Datenbank
Um die Architektur aus der Abbildung 1 zu implementieren, sind folgende Ressourcen nötig:
- On-Premises-SQL-Server-Datenbank
- selbstgehostete Integration Runtime
- Azure Data Factory V2
- Azure-SQL-Datenbank
Mit einer selbstgehosteten Integration Runtime (kurz IR) können Kopieraktivitäten zwischen einem Datenspeicher in einem privaten Netzwerk und einem Cloud-Datenspeicher ausgeführt werden. Weitere Informationen man in der Dokumentation von Microsoft zum Erstellen und Konfigurieren einer selbstgehosteten Integration Runtime. Eine selbstgehostete IR muss auf einem Rechner innerhalb des privaten Netzwerks installiert werden, in Azure Data Factory registriert werden, und kann für mehrere On-Premises-Quellen verwendet werden (auch aus unterschiedlichen Datenbanken/Servern). Eine selbstgehostete IR bietet eine sehr gute Performance, vergleichbar mit der Performance bei Extraktions- und Datenverschiebungsprozessen in lokalen Netzwerken. Die Geschwindigkeit der Internetverbindung mit dem lokalen Netzwerk ist der größte zu beachtende Performancefaktor.
Die Azure Data Factory V2 (kurz: ADF) ist ein ETL-Clouddienst für die Integration und Transformation von Daten mit einer Web-Benutzeroberfläche. Die ADF ist das Cloud-Pendant der SQL-Server Integration-Services-Runtime.
Die Azure-SQL-Datenbank ist eine cloudbasierte Platform-as-a-Service-Datenbank-Engine, die die meisten Datenbankmanagement-Funktionen erlaubt.
Die Abbildung 2 zeigt die Architektur für den Datenimport der On-Premises-SQL-Daten in einen Azure Data Lake Storage Gen2.
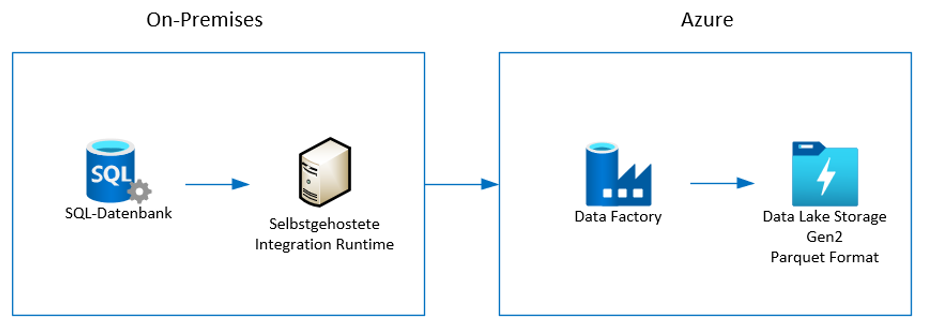
Abb. 2: Architektur des Datenimports von einer On-Premises-SQL-Datenbank in Azure Data Lake Storage Gen2
Azure Data Lake Storage Gen2 (kurz: ADLS) ist ein cloudbasiertes Blob-Storage mit hierarchischer Struktur. Das ADLS wurde konzipiert, um die Verarbeitung von mehreren Petabytes an Informationen bei Unterstützung eines Durchsatzes von Hunderten von Gigabit zu unterstützen und ermöglicht damit, riesige Datenmengen einfach und kostengünstig zu verwalten.
Als Ziel (in der Azure-Terminologie auch „Senke“ bzw. „sink“ genannt) für importierte On-Premises-Daten wird meist das ADLS mit Parquet-Format-Dateien gegenüber einer Azure-SQL-Datenbank bevorzugt. Apache Parquet ist ein kostenloses spaltenorientiertes Open-Source-Format, das eine effiziente Komprimierung erlaubt und eine sehr gute Performance beim Schreiben und Lesen/Abfragen hat. Zum Lesen der Parquet-Dateien gibt es kostenfreie Reader, die eine Kontrolle des Inhalts der Dateien erlauben. Die meisten Azure-Cloud-Dienste unterstützen den Zugriff auf Parquet-Dateien direkt.
Eine Azure-SQL-Datenbank ist für das Staging der Quelldaten in den meisten Anwendungsfällen nicht die optimale Option, da das ADLS in der Regel deutlich günstiger ist bei sehr guter Performance. Für Planungssysteme ist die Azure-SQL-Datenbank hingegen eine sinnvolle Alternative. Daher werden in diesem Artikel beide Varianten betrachtet.
Implementierung
Für die Implementierung der in diesem Artikel beschriebenen Lösung wird ein Azure-Abonnement benötigt. Ein kostenloses Azure-Abonnement kann hier erworben werden: azure.microsoft.com/de-de/free.
Nach Anmeldung und erfolgreichem Login wechseln wir zum Microsoft-Azure-Portal im Webbrowser und erstellen eine neue Data Factory. Dafür wählt man den Punkt „Ressource erstellen“ und sucht im Marketplace nach „Data Factory“. Die Abbildung 3 zeigt die Parameter für die Erstellung einer typischen ADF. Die angegebenen Namen müssen weltweit eindeutig sein. Für unser Beispiel erstellen wir eine neue Ressourcengruppe. „Git“ lassen wir zunächst außen vor, Einstellungen für den Netzwerkbetrieb werden „by default“ übernommen.
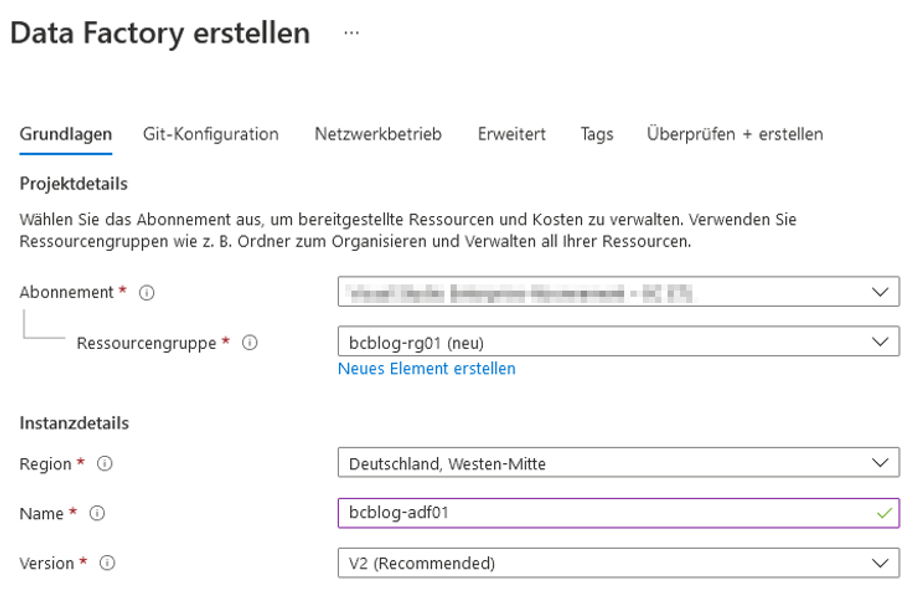
Abb. 3: Parameter für die Erstellung einer ADF
Für unser Beispiel brauchen wir weiterhin eine Azure-SQL-Datenbank als Senke (Ziel). Die Abbildung 4 zeigt die Parameter für die Erstellung einer typischen Azure-SQL-Datenbank. Als Ressourcengruppe geben wir die im vorherigen Schritt erstellte Bezeichnung an. Es soll ein neuer Server erstellt werden. Als Region verwenden wir am besten die gleiche Region für alle Ressourcen aus diesem Beispiel.
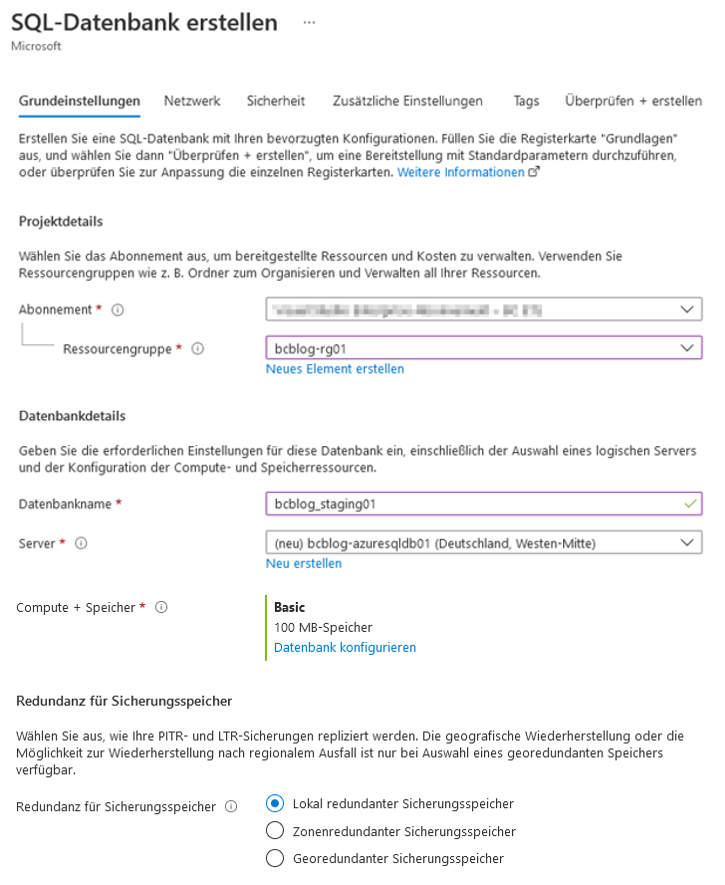
Abb. 4: Parameter für die Erstellung einer Azure-SQL-Datenbank
Bei „Compute + Speicher“ empfiehlt sich in unserem Beispiel, die Basic-Dienstebene mit den minimalen Kosten zu wählen (vgl. Abbildung 5). Die Azure-SQL-Datenbank bietet unterschiedliche Dienstebenen mit unterschiedlichen Möglichkeiten und Abrechnungsmodellen (mehr dazu kann man in den Microsoft Docs zum Thema Kaufmodelle nachlesen).
Als „Redundanz für Sicherungsspeicher“ empfehlen wir ein „Lokal redundanter Sicherungsspeicher“ als kostengünstigste Option für dieses Beispiel. Alle anderen Einstellungen können „by default“ übernommen werden, außer der Sortierung in den zusätzlichen Einstellungen – hier wird Latin1_General_CI_AS oder Latin1_General_CS_AS empfohlen.
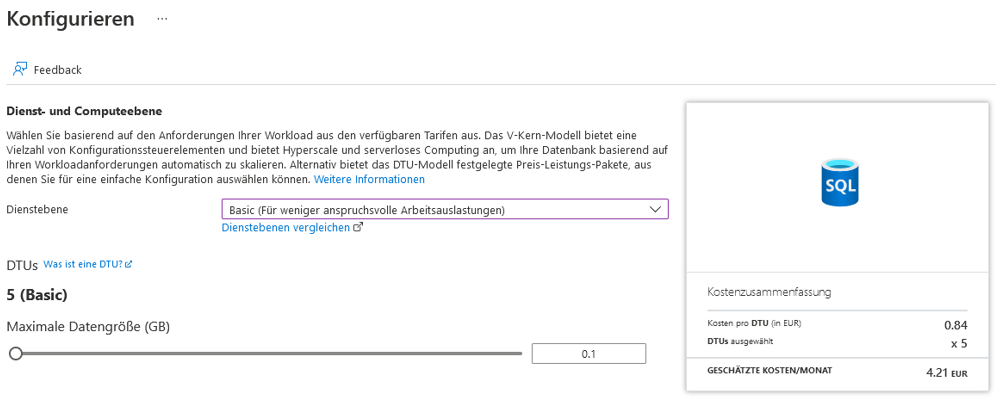
Abb. 5: Basic-Dienstebene
Nach der Erstellung der Azure-SQL-Datenbank, verbinden wir uns mit dem erstellten Server im SQL Server Management Studio (also bcblog-azuresqldb01.database.windows.net in diesem Beispiel). Bei der Anmeldung fügen wir unsere Netzwerkadresse oder das Subnetz zu den Firewall-Regeln der neuen Azure-SQL-Datenbank hinzu (vgl. Abbildung 6).
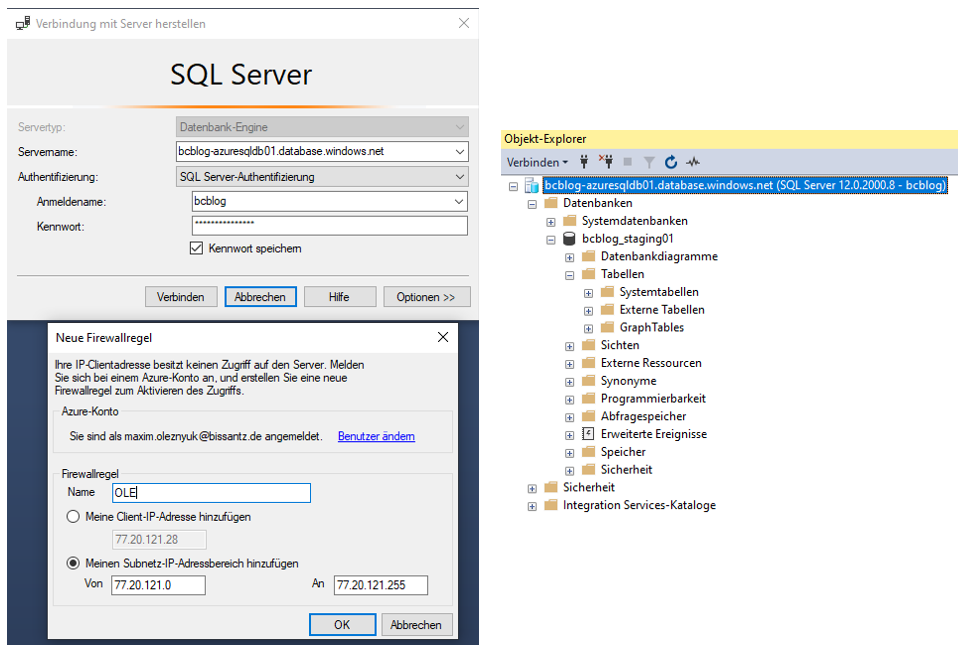
Abb. 6: Verbindung mit der Azure-SQL-Datenbank
Ohne diese Firewall-Freigabe kann kein Dienst auf die Datenbank zugreifen. Da jeder Dienst in der Regel eigene IP-Bereiche verwendet, müssen für jeden Dienst neue Bereiche ergänzt werden. Die IP-Adressen werden je nach Dienst dynamisch vergeben, weshalb die Ergänzung teilweise mehrfach erfolgen muss. Wenn ein Dienst den in Abbildung 6 gezeigten Dialog nicht anzeigt, kann der Eintrag auch über die mitgelieferte Stored Procedure sp_set_firewall_rule vorgenommen werden.
Als nächstes benötigen wir noch das Azure Data Lake Storage Gen2. Dafür suchen wir beim Hinzufügen einer neuen Ressource nach „Speicherkonto“ oder „storage account“, falls als Sprache in der Benutzeroberfläche Englisch verwendet wird. Die Abbildung 7 zeigt die Parameter für die Erstellung des Speicherkontos. Wir empfehlen für dieses Beispiel die „Locally-reduntant storage“ Redundanz als kostengünstigste Option zu selektieren.
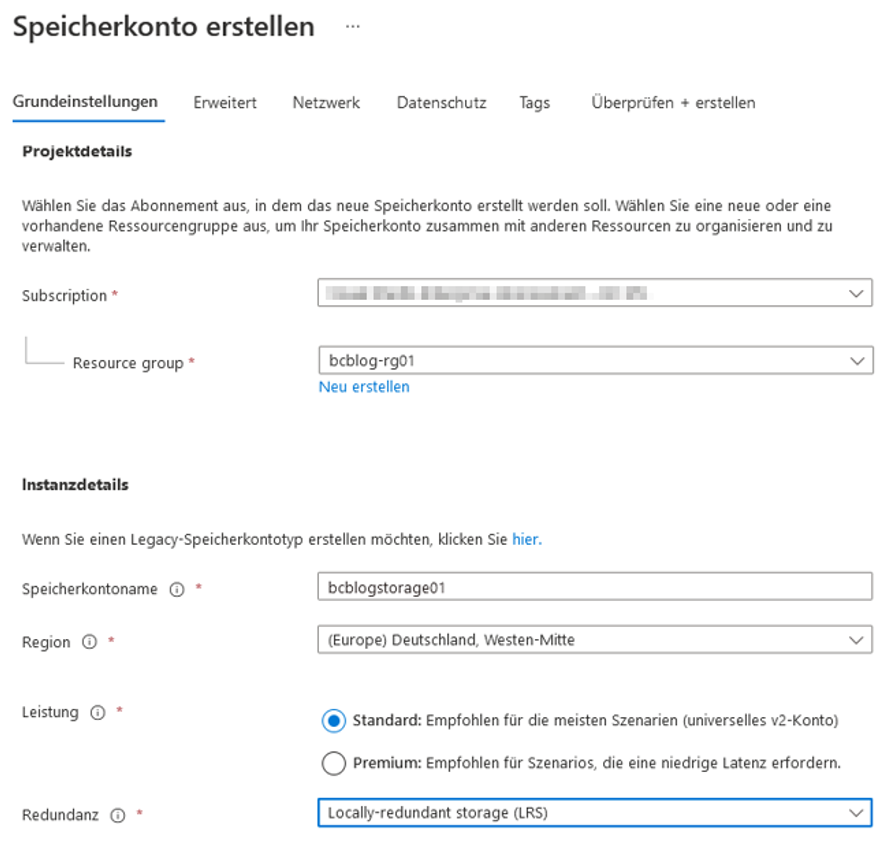
Abb. 7: Parameter für die Erstellung des Speicherkontos
Sehr wichtig ist es, den „Hierarchischen Namespace“ in den erweiterten Einstellungen zu aktivieren (vgl. Abbildung 8). Andernfalls wird ein Data Lake der ersten Generation (Gen 1) erstellt. Dieser unterstützt allerdings keine hierarchischen Strukturen. Alle anderen Einstellungen können „by default“ übernommen werden.
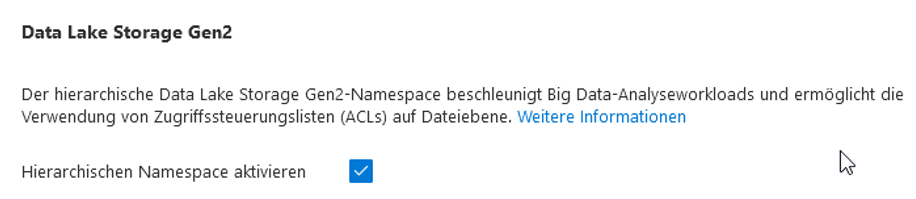
Abb. 8: Aktivierung des hierarchischen Namespaces
Im Anschluss daran muss ein sogenannter „Container“ im Data Lake angelegt werden. Dieser wird später alle Ordner und gespeicherten Dateien enthalten. Den Container kann man in etwa mit einer Datenbank gleichsetzen.
Für die Erstellung des Containers gehen wir in das erstellte ADLS, wechseln in den Speicherbrowser und erstellen einen neuen Blobcontainer „bcblog01“ sowie das Verzeichnis „staging“ in diesem Container. Dies wird in Abbildung 9 exemplarisch dargestellt.
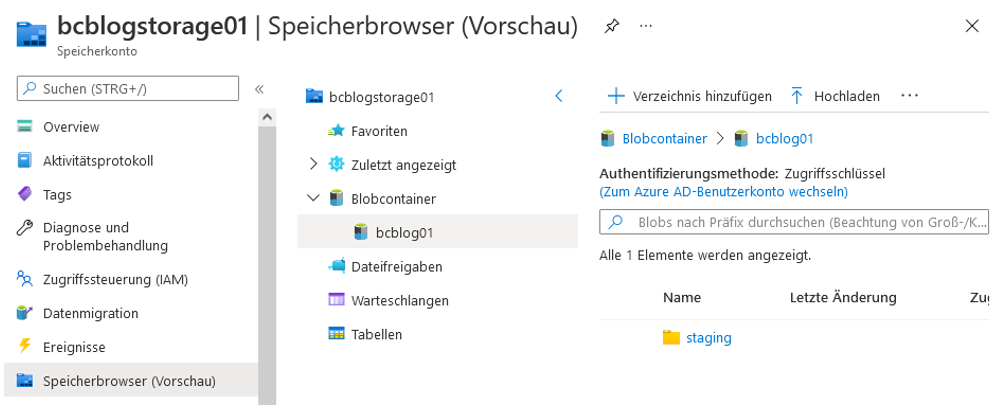
Abb. 9: Erstellung eines Blobcontainers
Jetzt haben wir alle Azure-Ressourcen, die nötig sind, um die Ladeprozesse aus der On-Premises-Welt nach Azure mit ADF aufzubauen. Wenn man zu Home → Abonnements → Ressourcen wechselt, kann man alle bereits erstellten Ressourcen sehen, wie in Abbildung 10 dargestellt (hier wurde eine Gruppierung nach Ressourcengruppe selektiert).

Abb. 10: Erstellte Azure-Ressourcen
Wir klicken auf die erstellte Data Factory und wählen dort „Azure Data Factory Studio öffnen“ aus, um mit der Entwicklung unseres Datenimports zu beginnen.
Als erstes wechseln wir im Data Factory Studio in die Verwaltung → Integration Runtimes und erstellen eine neue selbstgehostete IR (vgl. Abbildung 11).
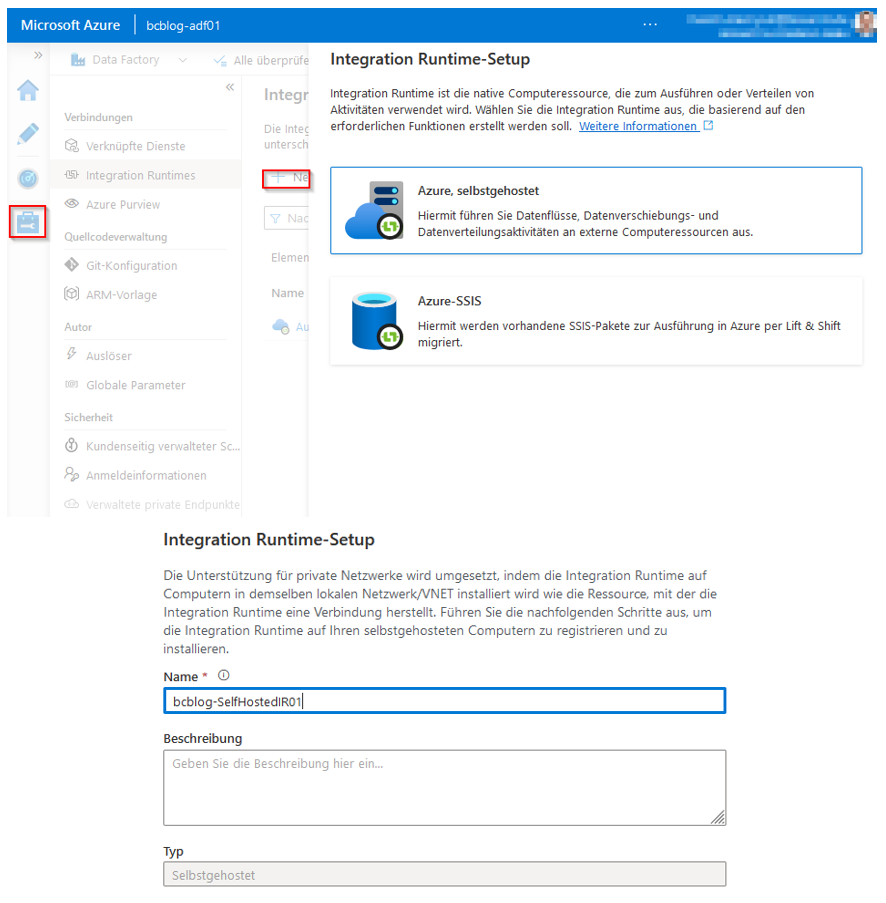
Abb. 11: Erstellung einer neuen IR
Nach der Erstellung der selbstgehosteten IR erscheint ein Fenster mit den Anweisungen für die Installation der IR im lokalen Netzwerk (vgl. Abbildung 12). Bei der Installation auf dem lokalen Rechner wählen wir „Option 1: Express-Setup“, bei der Installation auf einem anderen Rechner „Option 2: Manuelles Setup“.
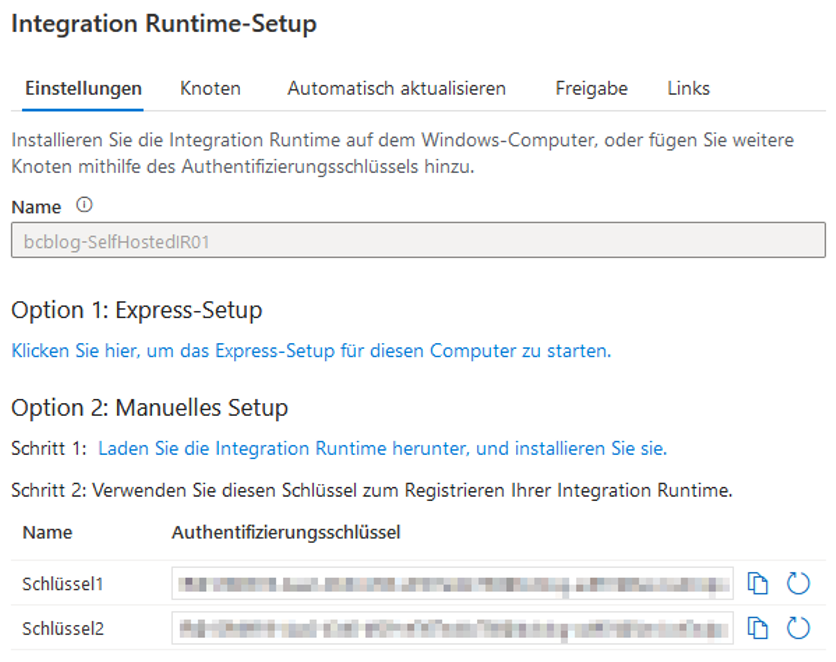
Abb. 12: Integration Runtime-Setup
In unserem Beispiel entscheiden wir uns für Option 1 und installieren die IR auf dem lokalen Rechner. Am Ende des Installationsprozesses wird die IR als „Wird ausgeführt“ in der Liste der Integration Runtimes angezeigt (vgl. Abbildung 13).
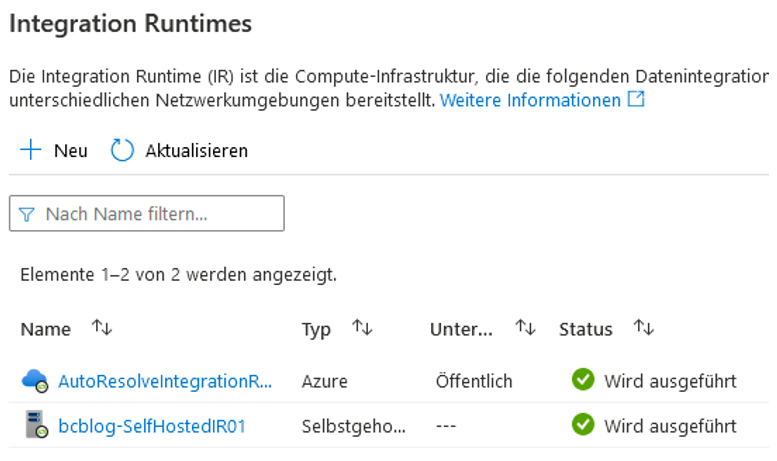
Abb. 13: Erstellte IR
Um Parquet-Dateien erstellen zu können, muss Java Runtime Environment auf der Maschine mit der selbstgehosteten IR installiert werden. Die Anwendung dazu lässt sich hier direkt herunterladen.
Als nächstes wird ein Linked Service für die On-Premises-SQL-Datenbank erstellt. Linked Services, also verknüpfte Dienste, können den alten Connection Managern in SSIS gleichgesetzt werden. Für die Erstellung wechseln wir zu „Verknüpfte Dienste“, wählen „Neu“, suchen nach „sql“ und wählen „SQL Server“ aus. Bei der Vergabe der Namen wird empfohlen das Präfix „LS_“ (für Linked Service) zu verwenden. Anschließend wird die selbstgehostete IR selektiert sowie der Server- und Datenbankname eingetragen. Als Authentifizierungstyp wird „Windows-Authentifizierung“ empfohlen. Vor der Erstellung sollte die Verbindung getestet werden (vgl. Abbildung 14).
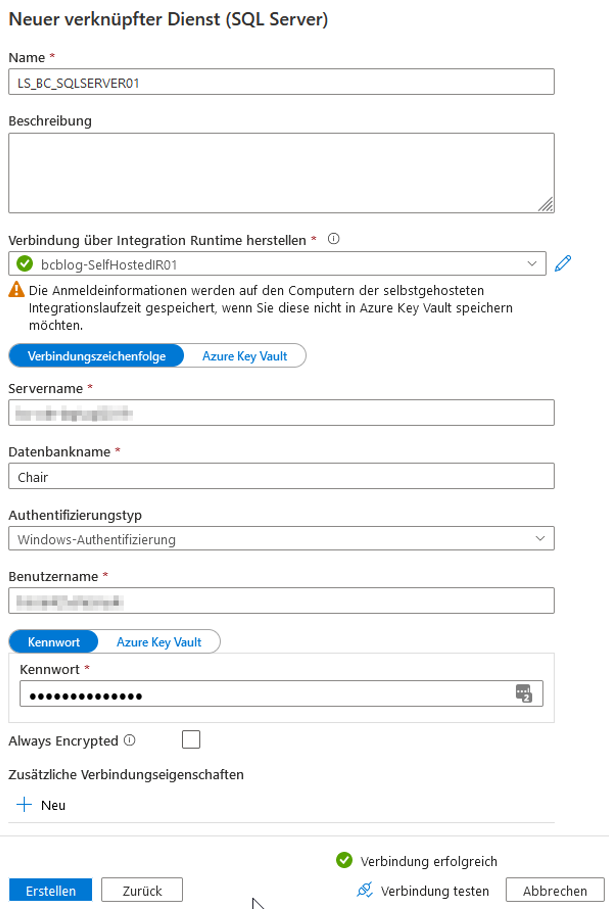
Abb. 14: Erstellung eines neuen Linked Services für SQL Server
Im Anschluss soll der Linked Service für unsere Senke, der Azure-SQL-Datenbank, erstellt werden (vgl. Abbildung 15). Dafür wählen wir „Neu“ in den Verknüpften Diensten, suchen nach „sql“ und wählen „Azure SQL-Datenbank“ aus.
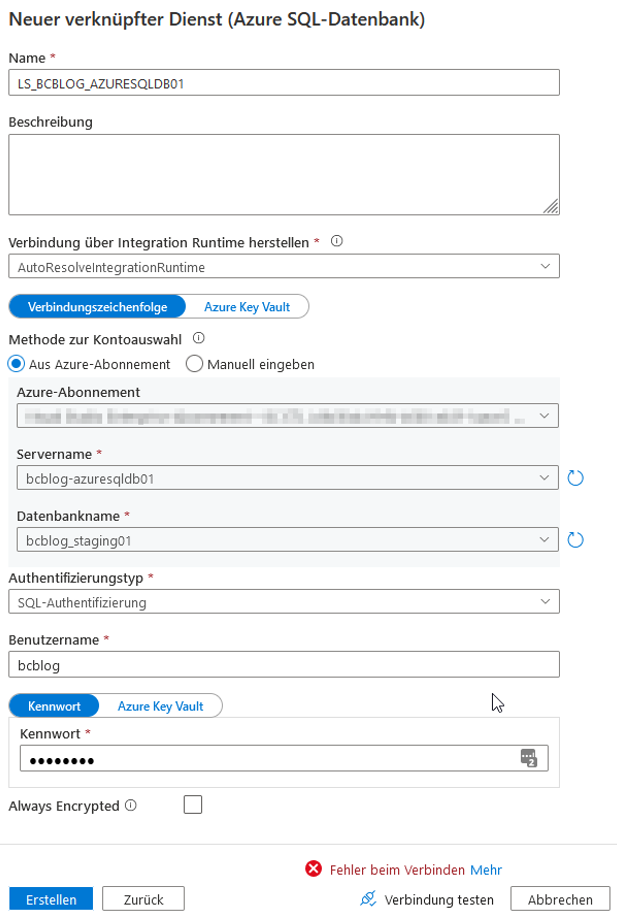
Abb. 15: Erstellung eines neuen Linked Service für die Azure-SQL-Datenbank
In der Abbildung 15 können wir einen Fehler bei „Verbindung testen“ sehen. Klickt man auf „Mehr“, wird deutlich, dass eine neue IP-Adresse in den Firewall-Regeln des Azure-SQL-Datenbank-Servers erlaubt werden muss. Die Abbildung 16 zeigt, wie das gemacht werden kann. Nachdem die Firewall-Regeln erweitert und gespeichert wurden, kann die Verbindung erfolgreich getestet und der Linked Service erstellt werden.
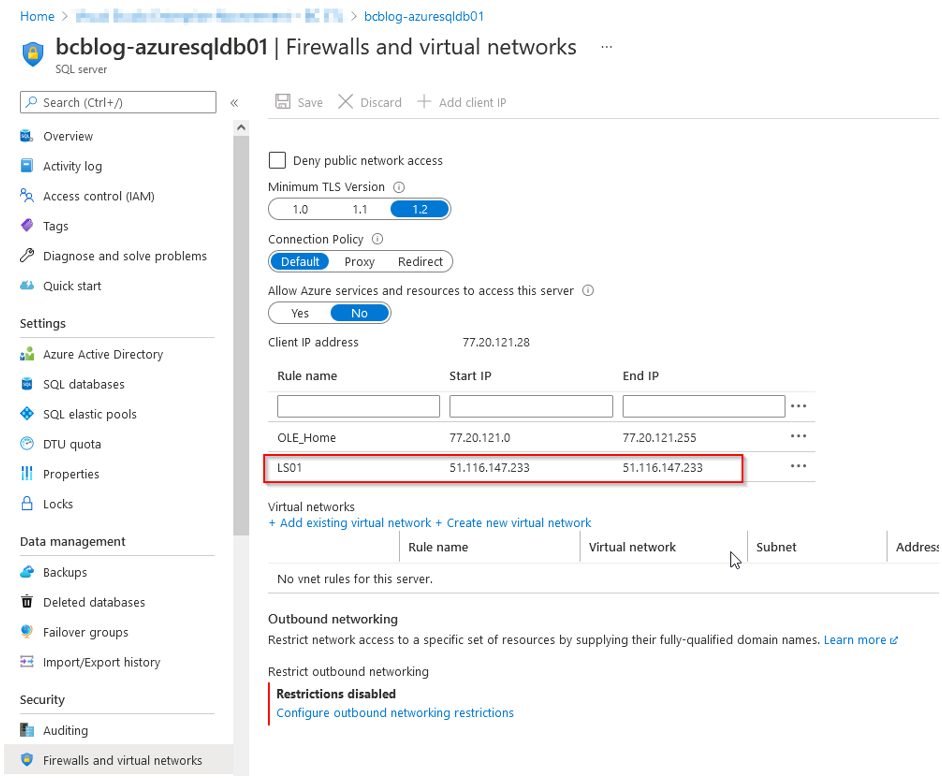
Abb. 16: Firewall-Regeln für Azure-SQL-Datenbank-Server
Als nächstes wird ein Linked Service für unsere Senke, die ADLS, erstellt (vgl. Abbildung 17). Dafür wird „Neu“ ausgewählt und nach „Azure-Blobspeicher“ gesucht.
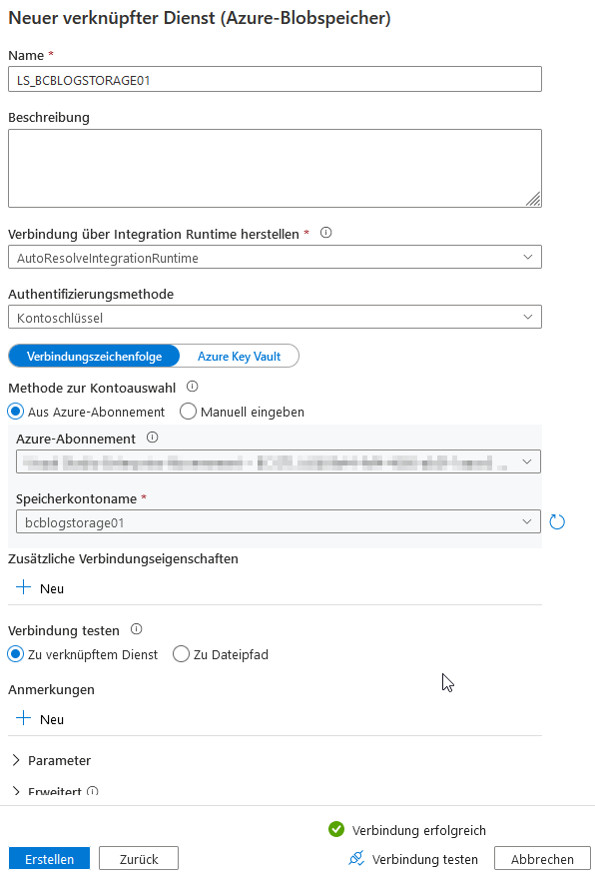
Abb. 17: Erstellung eines neuen Linked Services für ADLS
Jetzt haben wir alle nötigen Integration Runtimes und Linked Services, um unsere Pipelines für den Import der On-Premises-Daten nach Azure zu erstellen (siehe die Abbildung 18). Als Pipelines werden in ADF die früheren Pakete aus Integration-Services-Zeiten bezeichnet.
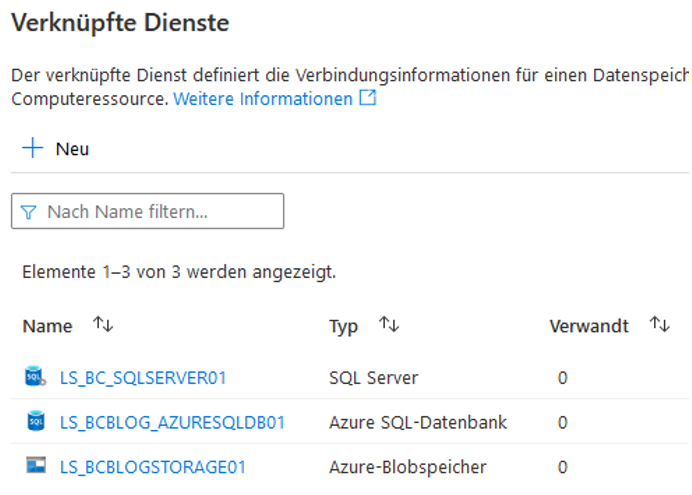
Abb. 18: Erstellte Linked Services
Um eine ADF-Pipeline zu erstellen, braucht man sogenannte Datasets. Ein Dataset kann man wie Quellen und Ziele in einem SSIS-Datenfluss betrachten – es gibt einige Unterschiede, aber die Idee ist ähnlich. Als erstes Dataset wird ein Dataset für die On-Premises-Quelltabellen erstellt (vgl. Abbildung 19). Man wählt ein „Neues Dataset“, sucht nach „sql“ und wählt „SQL Server“. Als Tabellenname wird „Keine“ selektiert, da die Tabelle später mit Hilfe einer SQL-Abfrage importiert wird. Als Präfix für den Dataset-Namen empfiehlt sich „DS_SOURCE_“ bzw. „DS_SINK_“.
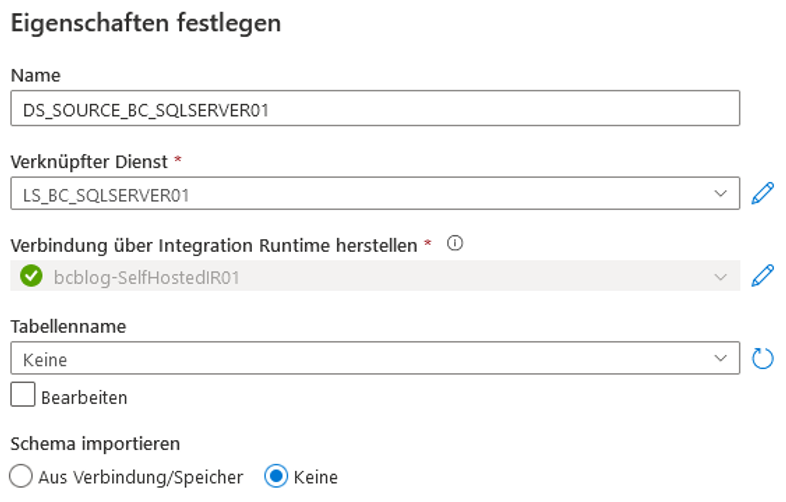
Abb. 19: Erstellung eines SQL Server-Datasets
Danach wird ein Senke-Dataset für die Azure-SQL-Datenbank erstellt (vgl. Abbildung 20). Es wird nach „sql“ gesucht und „Azure SQL-Datenbank“ selektiert. Als Tabellenname soll „Keine“ selektiert werden, da der Tabellenname später parametrisiert wird.
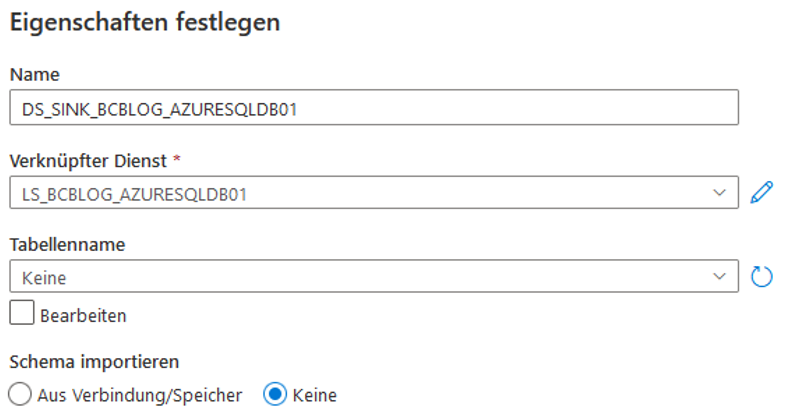
Abb. 20: Erstellung eines Azure-SQL-Datenbank-Datasets
Nach der Erstellung des Datasets fügen wir den Parameter „TableName“ hinzu, erlauben die Bearbeitung des Tabellennamens, tragen „dbo“ als Schema ein und fügen den dynamischen Inhalt @dataset().TableName für den Tabellennamen hinzu (vgl. Abbildung 21). Um den dynamischen Inhalt für ein Eingabefeld hinzuzufügen, muss man auf einen Link unter dem Eingabefeld zu klicken.
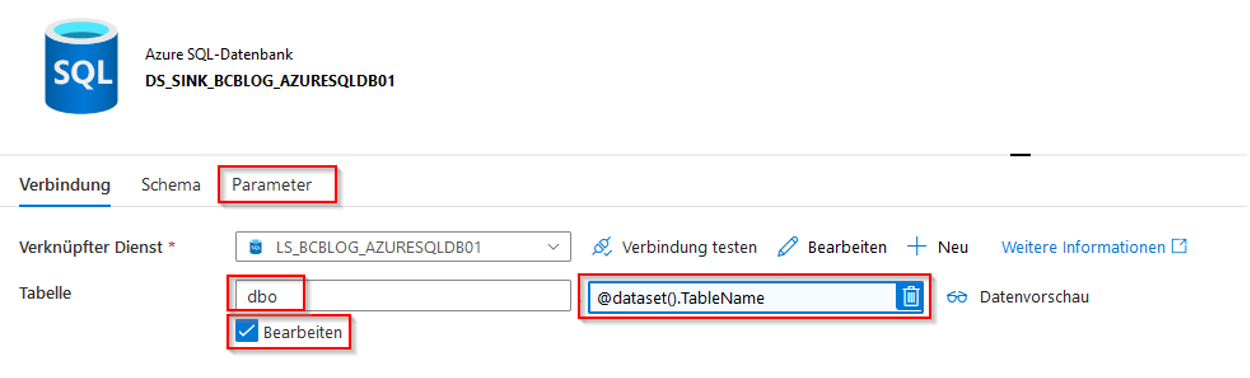
Abb. 21: Parametrisierung des Azure-SQL-Datenbank-Datasets
Danach wird ein Senke-Dataset für das ADLS erstellt (vgl. Abbildung 22). Hierfür wird nach „Azure-Blobspeicher“ gesucht und „Parquet“ als Format ausgewählt. Zu beachten ist, dass dabei der früher erstellte Pfad bcblog01/staging selektiert wird. Für „Schema importieren“ wird „Keine“ gewählt, da noch keine Dateien im staging-Verzeichnis existieren.
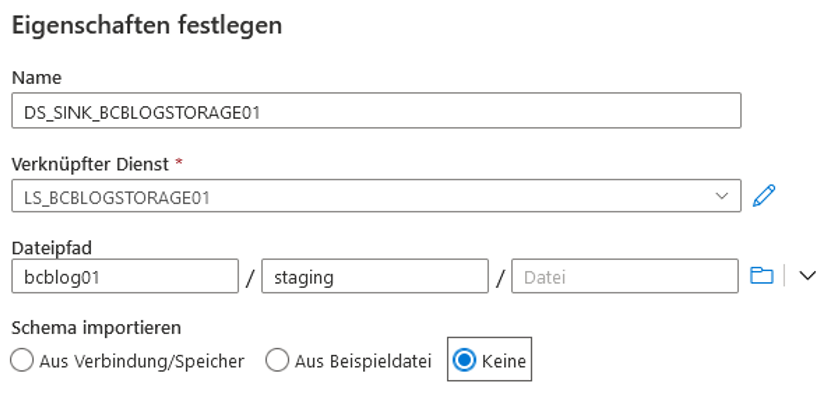
Abb. 22: Erstellung eines ADLS-Datasets
Nach der Erstellung des Datasets fügen wir den Parameter „TableName“ und den dynamischen Inhalt @{dataset().TableName}.parquet für den Dateinamen hinzu (vgl. Abbildung 23).
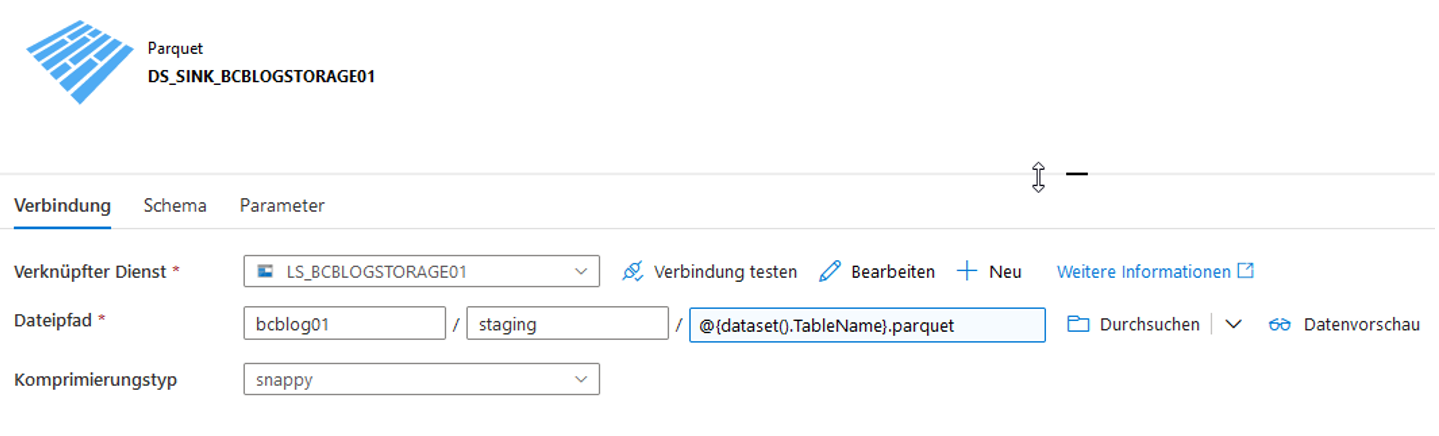
Abb. 23: Parametrisierung des ADLS-Datasets
Bevor wir mit der Erstellung unserer ersten Pipeline fortfahren, sollten alle Änderungen veröffentlicht werden. Zunächst sind alle Objekte nur im lokalen Workspace verfügbar. Für die Veröffentlichung wählen wir oben die Schaltfläche „Alle veröffentlichen“ (vgl. Abbildung 24).
Abb. 24: Änderungen veröffentlichen
Jetzt erstellen wir eine neue Pipeline namens “PL_ONPREMSQL_TO_ASQLDB” und fügen eine neue Copy Activity “C_ONPREMSQL_TO_ASQLDB” in die Pipeline hinzu (vgl. Abbildung 25). Es wird empfohlen, das Präfix „PL_“ für Pipelines und „C_“ für Copy Activities zu verwenden.
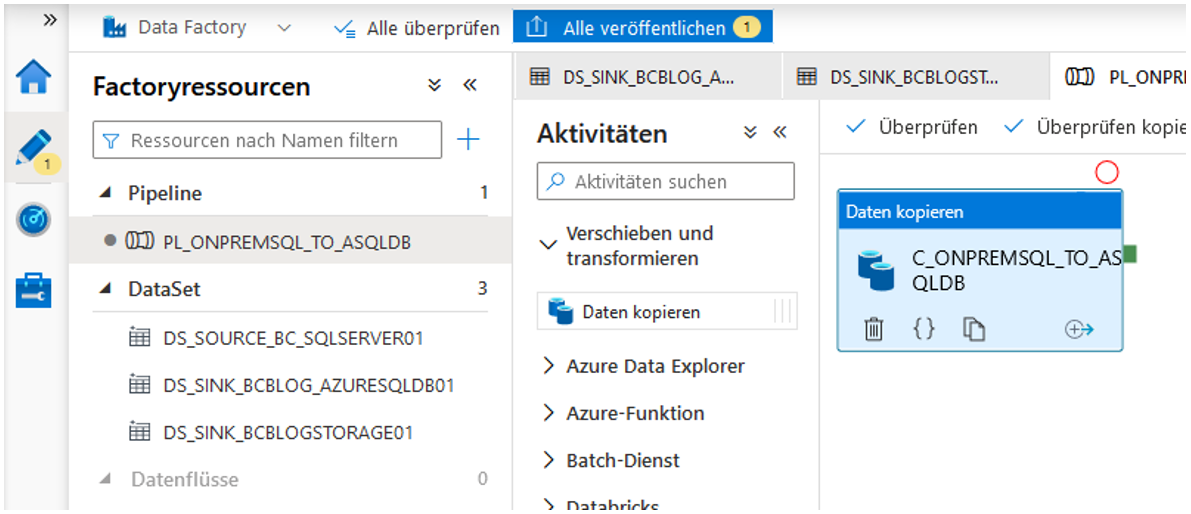
Abb. 25: Neue Pipeline und Copy Activity erstellen
Die Quell-Einstellungen der Copy Activity werden in Abbildung 26 gezeigt. Von hier aus kann man eine Datenvorschau aufrufen. Die Tabelle wird mit Hilfe von SQL abgefragt.
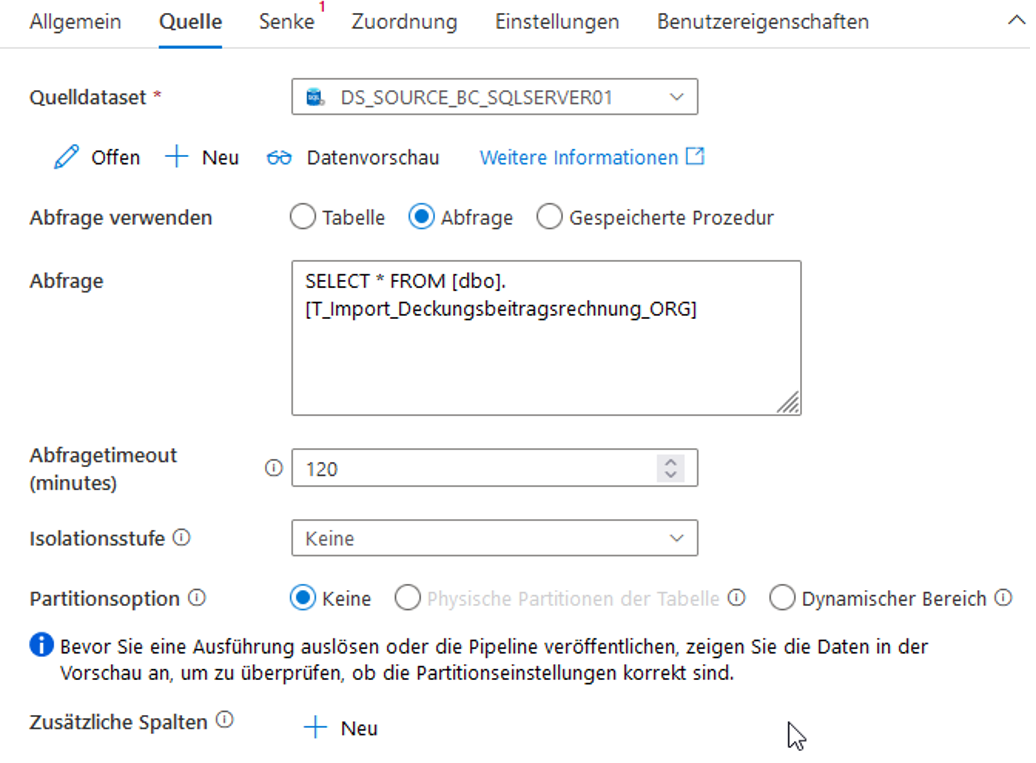
Abb.26: Quell-Einstellungen der Copy Activity
Bevor wir mit den Senke-Einstellungen beginnen, erstellen wir in der Ziel-Azure-SQL-Datenbank die Zieltabelle dbo.T_Import_Deckungsbeitragsrechnung_ORG. Diese kann in SSMS in der Quell-Datenbank geskriptet und in der Zieldatenbank ausgeführt werden.
Die Abbildung 27 zeigt die Senke-Einstellungen für die Azure-SQL-Datenbank. Hier ist zu beachten, dass der Dataset-Parameter „TableName” auf T_Import_Deckungsbeitragsrechnung_ORG gesetzt wird und das „Skript vor Kopiervorgang“ TRUNCATE für die Zieltabelle ausführt.
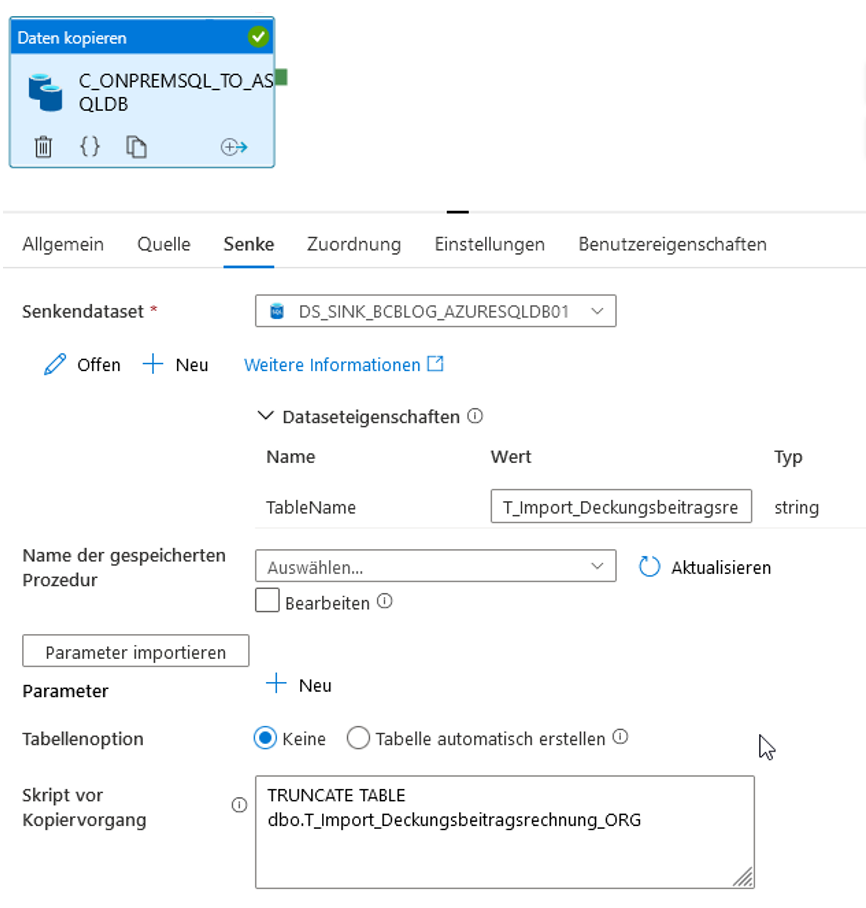
Abb. 27: Senke-Einstellungen für Azure-SQL-Datenbank
Jetzt können wir unsere Pipeline debuggen und veröffentlichen. Die Abbildung 28 zeigt die Ausgabe der Debug-Ausführung und die Daten in der Azure-SQL-Datenbank.
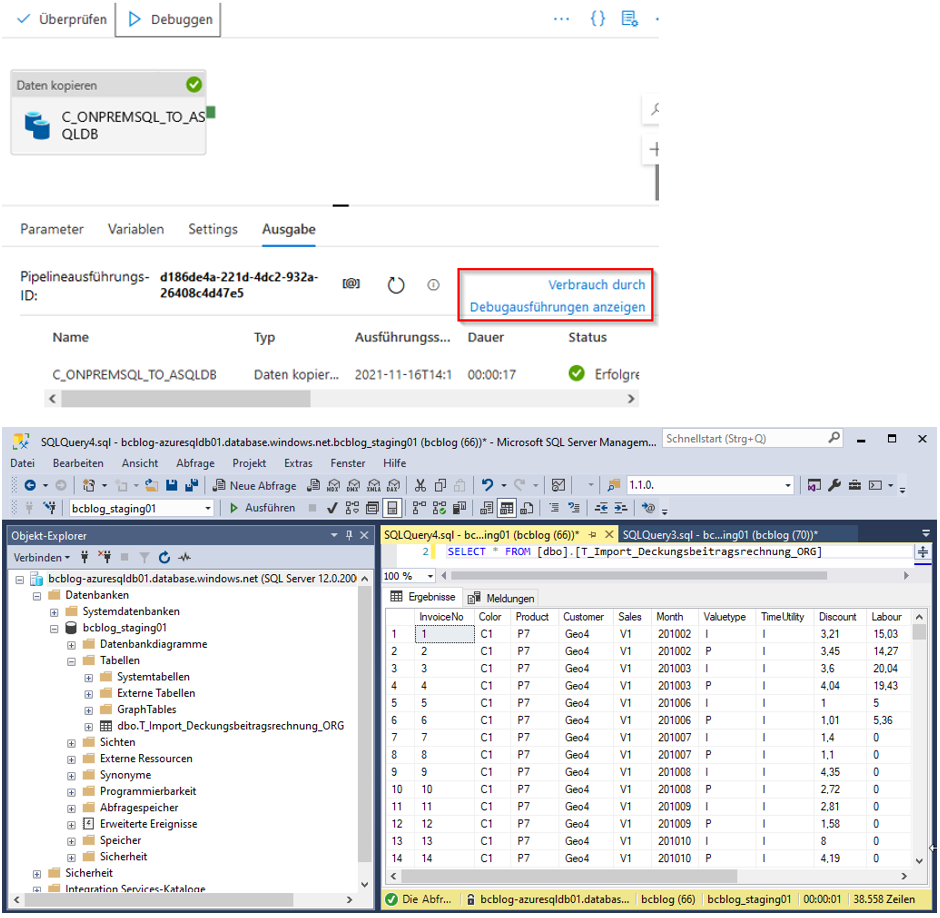
Abb. 28: Ausgabe der Debug-Ausführung und importierte Daten in Azure-SQL-Datenbank
In der Ausgabe der Debug-Ausführung kann man den Verbrauch durch die Debug-Ausführungen anzeigen lassen, um einen Eindruck für die entstehenden Kosten zu bekommen. Kostenmonitoring ist allerdings ein sehr umfassendes Thema in Azure und ist nicht Thema dieses Artikels.
Alle Ausführungen einer Pipeline kann man über den Punkt „Monitor“ anschauen, (vgl. Abbildung 29). Hier wird zwischen „Ausgelöst“ und „Debuggen“ getrennt. Wenn die aktuelle Debug-Ausführung nicht zu sehen ist, muss zunächst auf „Debuggen“ umgeschaltet werden. „Ausgelöst“ meint Ausführungen durch einen sogenannten Trigger (was den alten Jobs im On-Premises-SQL-Server entspricht).
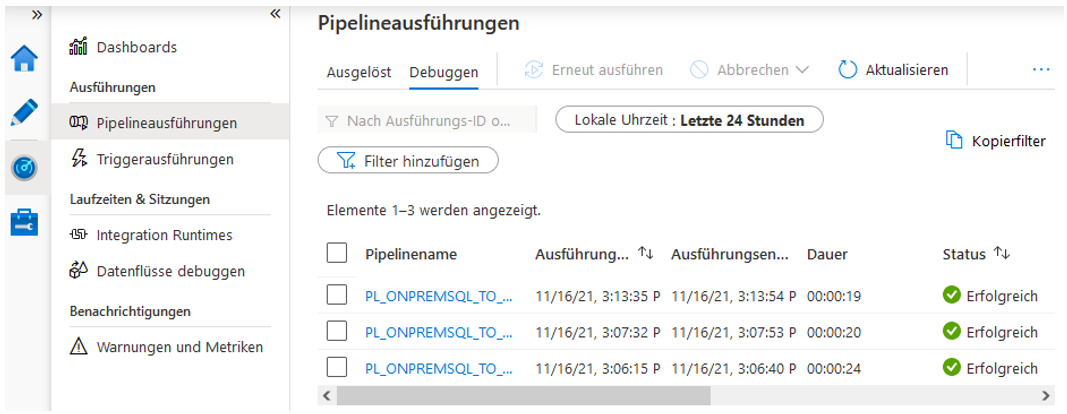
Abb: 29: Monitor der Pipeline-Ausführungen
Jetzt erstellen wir eine Pipeline, um die On-Premises-Daten nach das ADLS zu kopieren. Dafür klonen wir die existierende Pipeline „PL_ONPREMSQL_TO_ASQLDB“ und benennen sie in „PL_ONPREMSQL_TO_ADLS“ um. Auch die Copy Activity in der neuen Pipeline wird in „C_ONPREMSQL_TO_ADLS“ umbenannt. Die Quelleinstellungen werden nicht geändert.
Die geänderten Senke-Einstellungen werden in Abbildung 30 dargestellt. Mit dem ADLS muss die Senke nicht vorher bereinigt werden – die existierenden Dateien werden standardmäßig überschrieben. Man kann eine weitere Parametrisierung der Senke vornehmen, um die Daten z. B. nach Datum oder nach Partitionen zu speichern (dieses Thema wird in diesem Beitrag allerdings nicht näher betrachtet).
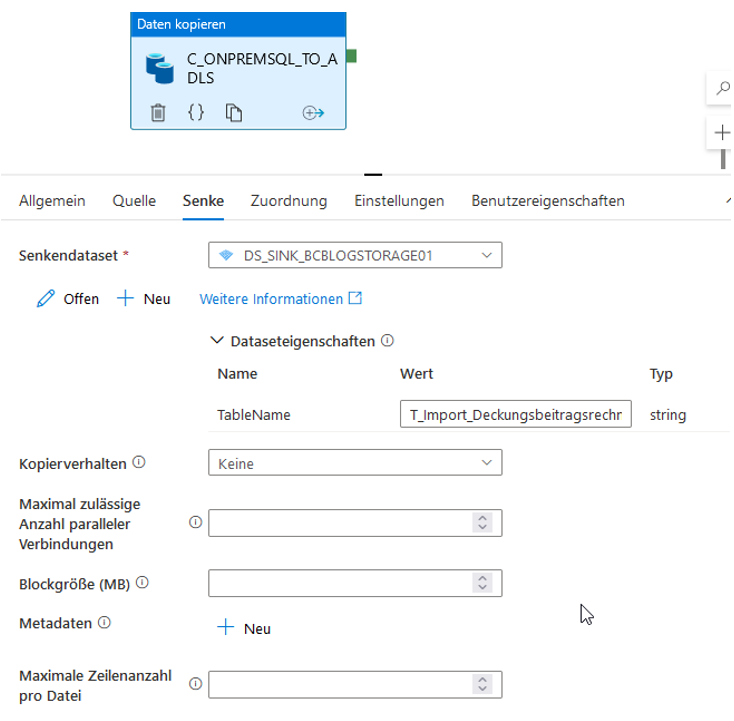
Abb. 30: Senke-Einstellungen für ADLS
Nach der Pipeline-Debug-Ausführung können wir im Speicherbrowser für bcblogstorage01 unsere Parquet-Datei sehen (vgl. Abbildung 31). Solche Parquet-Dateien können später mit ADF weiter transformiert, mit Azure Synapse Analytics (serverless) sehr performant per SQL abgefragt oder mit anderen Azure-Diensten transformiert bzw. analysiert werden. Um den Inhalt einer Parquet-Datei lokal anzuschauen, empfehlen wir den kostenlosen Apache Parquet Viewer aus dem Microsoft Store.
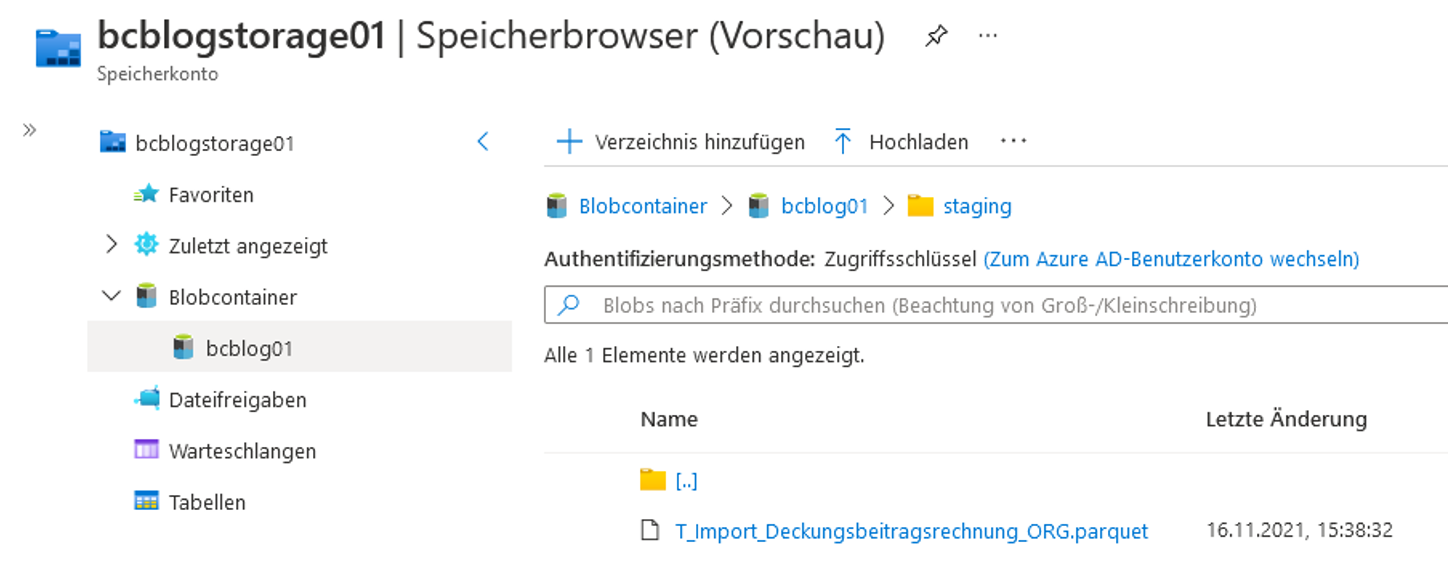
Abb. 31: Erstellte Parquet-Datei
Fazit
In diesem Artikel haben wir an einem alltäglichen Beispiel Schritt für Schritt gezeigt, wie On-Premises-SQL-Daten in eine Azure-SQL-Datenbank bzw. in das Azure Data Lake Storage Gen2 importiert werden können mit Hilfe von der Azure Data Factory V2. Dabei haben wir alle für diese Aufgabe nötigen Begriffe, Konzepte, Architekturen und ihre Bestandteile erklärt.
Mit einer kleinen Erweiterung der Pipeline mit Lookup- und Foreach-Aktivitäten können auch mehrere Tabellen aus einer Zieldatenbank mit Hilfe von nur einer Copy Activity dynamisch importiert werden – ein interessantes Thema für mögliche weitere Beiträge.
Weiterhin ist erwähnungswert, dass ADF auch Mapping Data Flows für die Pipelines bietet, mit denen inkrementelle Ladeszenarien besser unterstützt werden. Diese Data Flows können allerdings nur Azure-Dienste als Quellen haben, deswegen sind sie für unser Szenario mit dem Import von On-Premises-Daten ungeeignet.
Wir haben beobachtet, dass „On-Premises nach Azure“ ein kostengünstiges Importszenario ist. Anders sieht es aus, wenn eine Azure-SQL-Datenbank als Quelle verwendet wird. Unsere Tests für dieses Szenario haben gezeigt, dass hier relativ hohe Kosten entstehen können. Aktuell empfehlen wir daher, eine Azure-SQL-Datenbank als Quelle einer ADF zu vermeiden.
ADF und selbstgehostete Integration Runtimes unterstützen neben den gezeigten Formaten sehr viele weitere Quellformate, so dass auch Daten bspw. aus SAP HANA oder SAP ERP ohne die Installation zusätzlicher Komponenten abgezogen werden können. Das Spielfeld, auf dem man sich mit ADF tummeln kann, ist also sehr groß. Daher wird dies sicherlich nicht unser letzter Beitrag über die Azure Data Factory gewesen sein.
