Es ist keine Untertreibung – jeder Consultant kennt die Situation genau: in Workshops, Projekten, wie in Betriebsunterstützungszeiten müssen wir für unsere Kunden zügig herausfinden, wo welche Daten herkommen und welche Fehler wie erklärt werden können, sprich: wie der Datenfluss aussieht und wie die existierenden Probleme darin behoben werden können.
Im Idealfall sieht man die Abhängigkeiten auf einen Blick: welche P_DIMs erstellen die T_DIMs, welche V_Imports führen zu deren Befüllung, aus welchen Vorsystemen kommen die Daten in den SQL-Server. So strukturiert erkennt man in der Regel schnell, wo etwas im Argen liegt. Doch ist dieser Idealfall leider, aber aus nachvollziehbaren Gründen, nur selten gegeben.
Dieser Blogbeitrag zeigt die Möglichkeiten auf, die für die Darstellung des Datenflusses hilfreich sind. Das Ganze geschieht auf drei Weisen; angefangen von einer isolierten Betrachtung eines Datenbankobjekts bis hin zu einer unterstützenden Gesamtsicht, sowohl für ETL-Modelle als auch für Modelle, die ohne DeltaMaster ETL erstellt wurden. Letztlich wird ein Ausblick auf den wahren Idealzustand gegeben: die Dokumentation des Datenflusses auf Knopfdruck – inklusive ansehnlicher Visualisierung. Dieser ist – nur so viel vorab – in greifbarer Nähe.
Beginnen wir ohne langes Umherschweifen mit Stufe 1 – der Betrachtung von einzelnen Datenbankobjekten und deren Abhängigkeiten. Als Basis für unser Beispiel ziehen wir unsere Chair zurate.
Stufe 1: SQL Datenbankobjekte – Kontextmenü „Abhängigkeiten anzeigen“
Der erste grundlegende, aber zurecht schnell mühsam erscheinende Weg ist das Anzeigen von Abhängigkeiten zu einem ausgewählten Datenbankobjekt per Kontextmenü im SQL Server Management Studio.
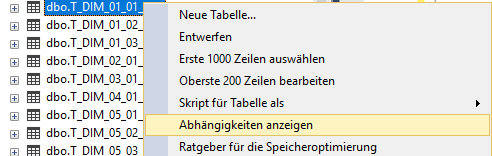
Rechtsklick auf das betreffende Objekt und Auswahl des Menüeintrags “Abhängigkeiten anzeigen” liefert im folgenden Dialog zwei Optionen der Darstellung:
a) Objekte, die vom gewählten Objekt abhängig sind, d. h. in unserem Beispiel dem gewählten Datenbankobjekt T_DIM_01_01_Jahr.
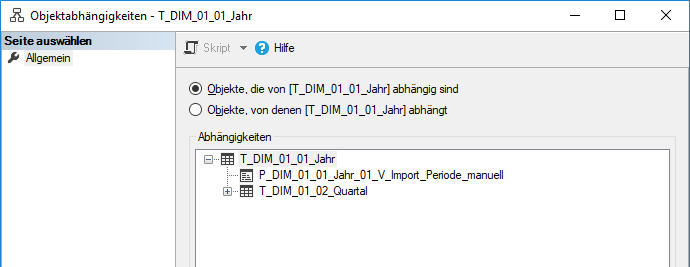
Unter diesem Wurzelknoten erscheint neben einer weiteren Tabelle (die den Fremdschlüssel der gewählten Tabelle aufweist und deshalb gelistet wird) auch die Prozedur P_DIM_01_01_Jahr_01_V_Import_Periode_manuell, die diese Tabelle befüllt. Dies ist logisch, da diese Prozedur in ihrem „Codebauch“ die Tabelle referenziert, um sie zu adressieren; nichtsdestotrotz ist die Abhängigkeit aus der Perspektive des Datenflusses eigentlich eine andere: die T_DIM-Tabelle ist eigentlich das Endergebnis und nicht die sie befüllende Prozedur.
b) Objekte, von denen das aktuell gewählte Datenbankobjekt abhängt. In diesem Fall betrachten wir wieder unsere bereits oben gewählte T_DIM-Tabelle; hiermit ist im Beispiel der Chair für diese Dimension das obere Ende des Datenflusses erreicht. Das bedeutet, dass es keine weiteren Abhängigkeiten zu verzeichnen gilt. Der „Blick nach oben“ im Datenfluss endet an dieser Stelle. So weit, so gut.
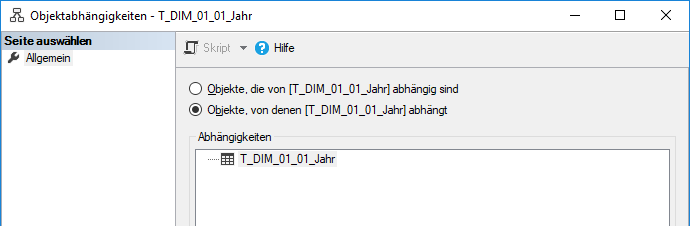
Bleibt man dieser Denkrichtung treu und hat man sich daran gewöhnt, wird es allerdings wieder ein Stückchen verwirrender, wenn man beispielsweise die Abhängigkeiten einer Sicht betrachtet, z. B. die V_Import_Dim_Produkte.
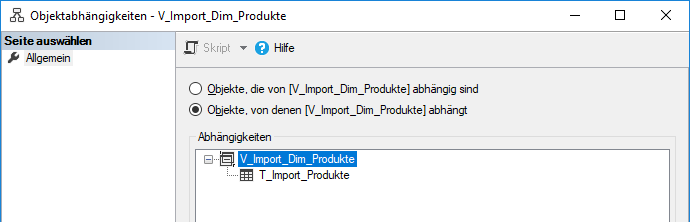
Wir wagen also hier den Blick wieder nach oben im Datenfluss – also eigentlich das, was wir uns wünschen: Von der T_Import-Tabelle kommend, landen wir bei der Sicht, die darauf aufbaut und die relevante Struktur für unsere Dimensionstabelle erzeugt. Die Betrachtung ist also aus datenbankseitiger Sicht natürlich wiederum logisch; aus Datenflusssicht (für Dokumentationen des Kunden) bedarf es allerdings ein Umdenken an der genannten Stelle. Wie ist denn nun die Denkweise? Nach vorne oder nach hinten? Nicht ganz befriedigend an dieser Stelle. Sei’s drum.
Diese Darstellungsoptionen der Abhängigkeiten bieten allein bereits einen ersten schnellen Blick auf das wohin und woher des betreffenden Objekts – trotz des notwendigen Umschaltens und Umdenkens zwischen logischen Abhängigkeiten in der Datenbank und Abhängigkeiten für die Datenfluss-Visualisierung. Nur: von einer Übersicht über alle Datenbankobjekte sind wir hier weit entfernt. Und wir wissen, dass unser Arbeitsgedächtnis begrenzt ist. Diesen Weg können wir also nur dann gehen, wenn wir konkret ein Problem bei einem Datenbankobjekt festgestellt haben und diesem auf den Grund gehen müssen. Gehen wir eine Stufe weiter.
Stufe 2a: ETL Bericht – Snowflake Dependencies
Um einem informativen Überblick über alle Abhängigkeiten gerecht zu werden, hat sich unser ETL-Team etwas Großartiges überlegt. Bei Modellen, die mit unserem mächtigen Werkzeug erstellt wur-den, gibt es diese Auswertungen bereits – in der Tabelle T_ModelInfo_Dependencies. Das Ergebnis ist nicht nur als Tabelle in der Datenbank zu finden, sondern gleich als Bericht in der DeltaMaster-Anwendung ETL eingeflossen und somit der Datenflussperspektive, die wir in diesem Blogbeitrag anstreben, dienlich. Hier ein Blick auf die aktuelle Version im Bericht Snowflake Dependencies im Ordner System Information anhand der Demo.
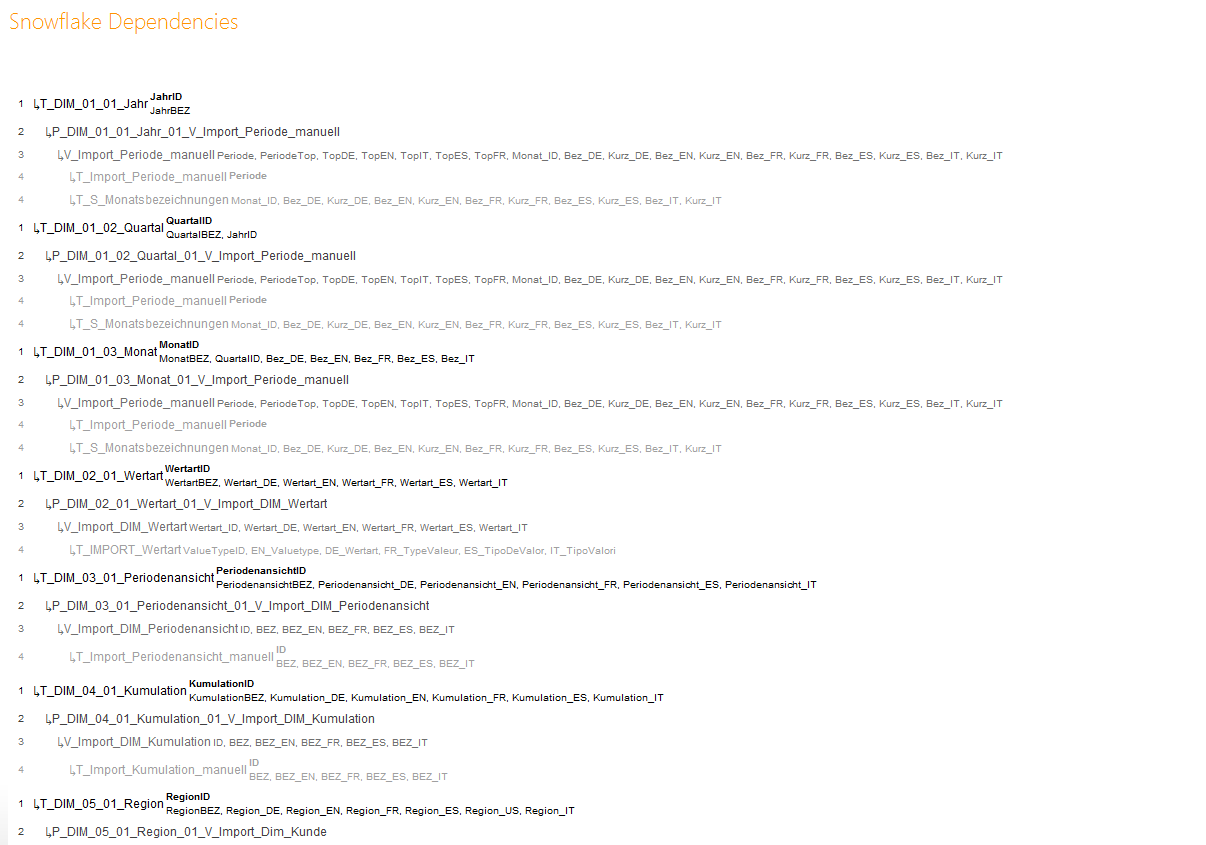
Der Bericht zeigt den Datenfluss ausgehend von den T_DIMs bzw. T_FACTs und verfolgt den Fluss nach unten gerichtet bis zu den T_Import-Tabellen – und das in der gewünschten Logik des Datenflusses. Dabei werden durch die im Hintergrund liegende Prozedur P_ModelInfo_Reload_Dependencies die folgenden Datenbankobjekte für die Erstellung der Zieltabelle berücksichtigt:
- T_DIM- und T_FACT-Tabellen
- P_DIM- und P_FACT-Prozeduren
- V_Import_DIM- und V_Import_FACT-Sichten sowie TMVs
- T_Import_DIM- und T_Import_FACT-Tabellen
Zudem findet man die Information zu den in den Datenbankobjekten enthaltenen Spaltennamen und Schlüsselattributen. Eine ganz schöne Hilfe; auch schön daran ist, dass die Logik rekursiv aufgebaut ist und damit bis zu 14 Ebenen, d. h. Abhängigkeiten nach unten visualisiert werden können. Nur wenige Kollegen sind mit solch „tiefgehenden“ Modellen häufiger unterwegs. Basis der Abfrage sind die SQL-eigenen Systemtabellen, vor allem aber die sys.sql_expression_dependencies. Diese zeigt die Abhän-gigkeiten ausgehend von den Datenbankobjekten, allerdings nur in die Richtung „flussabwärts“.
Ist unser Problem der übersichtlichen Darstellung des Datenflusses damit gelöst? Leider nur fast. Wa-rum? Weil dies nur für die Modelle gilt, die mit DeltaMaster ETL erstellt wurden. Was aber machen wir, wenn wir auf Modelle stoßen, die kein ETL-Modell beinhalten und wir dennoch den Datenfluss schnell analysieren müssen? Wir behelfen uns anderweitig.
Stufe 2b: Nicht-ETL-Modelle – SQL Systemtabellen
Wir nutzen die oben genannten SQL-eigenen Systemobjekte, was uns eine flexiblere Gestaltung zur Visualisierung der Abhängigkeiten ermöglicht. Im Folgenden findet sich ein Code-Snippet, das für solche Zwecke verwendet werden kann. Der Code listet im ersten Block die Objekte und ausgewählte Eigenschaften auf, auf die referenziert wird (z. B. T_Import-Tabellen). Im zweiten Block werden die Da-tenbankobjekte geführt, in deren Code die Referenz auf die anderen Datenbankobjekte enthalten ist (z. B. V_Import-Sichten, die auf T_Import-Tabellen verweisen). Die FROM-Klausel nutzt neben der In-formationen der Abhängigkeiten in der Systemtabelle sql_expression_dependencies zudem in zweifa-cher Ausführung die Systemtabelle objects, die sowohl die Zusatzinformationen zu den referenzierten als auch zu den referenzierenden Datenbankobjekten hinzuzieht. Zur Vereinfachung werden in der WHERE-Klausel die weniger relevanten Datenbanktypen bereits aussortiert. Übrig bleiben Tabellen, Sichten und Prozeduren.

SELECT
--Referenced objects ("From")
sed.referenced_server_name AS ObjServer_From,
sed.referenced_database_name AS ObjDatabase_From,
sed.referenced_schema_name AS ObjSchema_From,
sed.referenced_entity_name AS ObjName_From,
o1.type AS ObjType_From,
o1.type_desc AS ObjTypeDesc_From,
--Referencing objects ("To")
o.name AS ObjName_To,
o.type AS ObjType_To,
o.type_desc ASObjTypeDesc_To
FROM sys.sql_expression_dependencies sed
INNER JOIN sys.objects o
ON sed.referencing_id = o.object_id
LEFT OUTER JOIN sys.objects o1
ON sed.referenced_id = o1.object_id
--Filter irrelevant object types
WHERE
o1.type NOT IN ('C', 'FN', 'IF', 'TF', 'D', 'F', 'TR', 'UQ')
AND o.type NOT IN ('C', 'FN', 'IF', 'TF', 'D', 'F', 'TR','UQ')Der umgedrehten Datenflusslogik, wie in Schritt 1 beschrieben, werden wir allerdings dadurch auch nicht ganz Herr. Daher sind wir hier noch nicht am Ende. Gibt es ein noch besseres Ergebnis? Ja, und zwar die grafische Darstellung mithilfe von gewohnten Datenflussdiagrammen. Dies gelingt beispiels-weise mit Visio oder anderen Tools, die sich dieser Aufgabe widmen. Doch die in Stufe 2a (für ETL-Modelle) bzw. Stufe 2b (für Nicht-ETL-Modelle) gezeigten Abhängigkeiten müssten dazu manuell übertragen, korrekt miteinander verbunden, ansprechend ausgerichtet, final geprüft und dann noch regelmäßig angepasst werden. Eine Sisyphusarbeit, wenn Modelle – wie es in der Realität nun mal so ist – nicht in Stein gemeißelt sind, sondern regelmäßiger Anpassungen bedürfen.
Stufe 3 (Ausbaustufe): Automatische Dokumentation der Datenflüsse
Aufgrund einer umfangreichen Dokumentation für einen Kunden entstand auf Basis der oben gezeig-ten Ergebnisse zur Darstellung der Abhängigkeiten zwischen Datenbankobjekten die Idee einer auto-matisierten Dokumentation der Datenflüsse – alles auf Knopfdruck. Damit soll der Datenfluss erstellt und bei Änderungen direkt angepasst und erzeugt werden können – ohne manuelle Nacharbeit. So könnte dies beispielsweise aussehen.
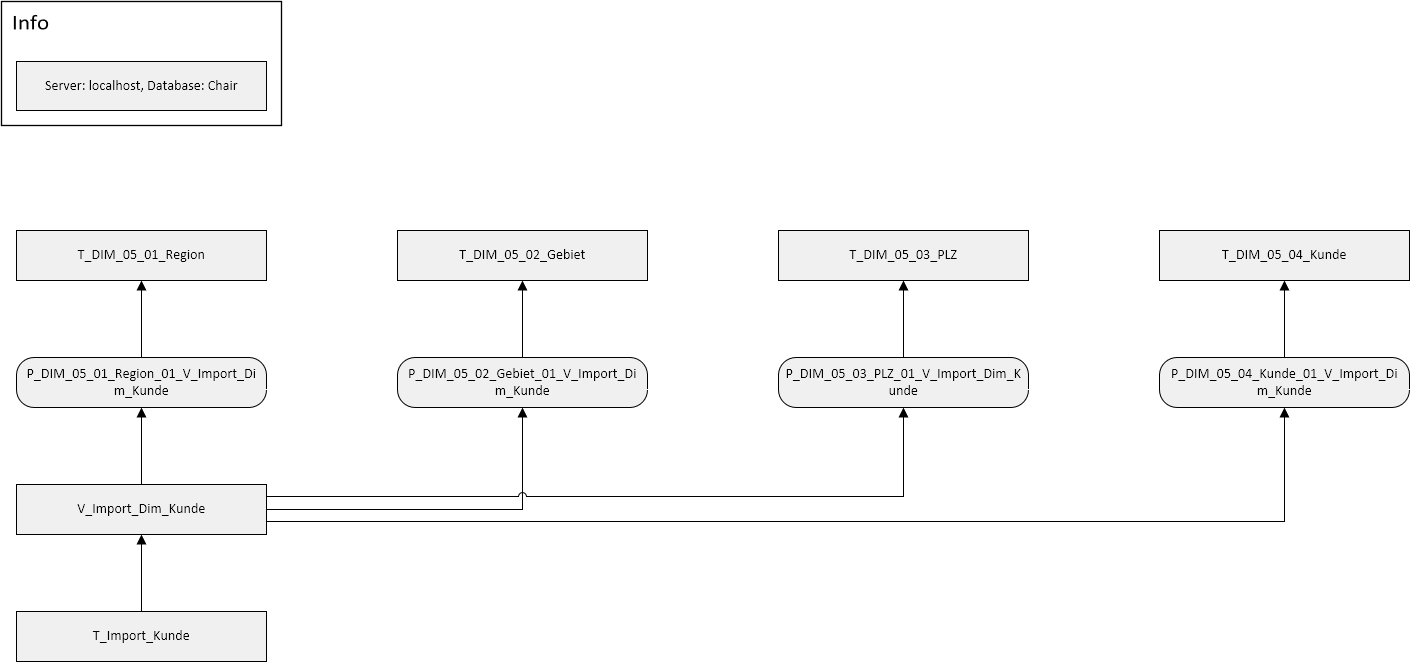
Mehr wird derzeit noch nicht verraten. Man darf aber gespannt sein. Nur so viel vorab: Bei den bloßen Abhängigkeiten von SQL-Datenbankobjekten bleibt die Idee nicht stehen, dafür gibt es zu viele weitere interessante Objekte (z. B. in SSIS-Paketen), die für einen durchgängigen Datenfluss sinnvoll sind und in der aktuellen Idee ihren Platz finden werden.

Kommentare
Sie müssten eingeloggt sein um Kommentare zu posten..