Eine Azure-SQL-Datenbank funktioniert weitgehend genauso wie eine On-Premises-SQL-Datenbank. In einigen Details unterscheiden sich die Lösungen jedoch. Datenbankübergreifende Abfragen sind so ein Fall. Grundsätzlich sollte man diese in seinem Code ohnehin vermeiden, wofür wir in der On-Premises-Welt auf Synonyme zurückgreifen. Bei Azure-SQL-Datenbanken stoßen beide Methoden auf Widerstände und funktionieren nicht wie gewohnt. Wir zeigen, wie man dieses Problem umgeht.
Grenzen bei Projekten mit Azure
Arbeitet man erstmals mit Azure, scheint zunächst alles wie gewohnt abzulaufen – nur eben in der Cloud. Schnell stößt man jedoch an Grenzen, die im Projektalltag mit großen Kundensystemen hinderlich sind. Solche Kundensysteme bauen wir häufig mit unserer Enterprise-Architektur mit verteilten Datenbankschichten auf, deren Trennung sich aus vielen Gründen als praktisch erwiesen hat, insbesondere bei Migrations- und Backup-Szenarien.
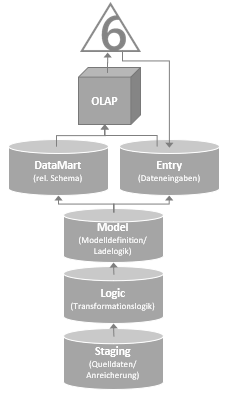
Abbildung 1: Bissantz & Company Enterprise Architecture
Abbildung 1 zeigt eine typische Enterprise-Architektur in voller Ausbaustufe mit fünf relationalen und einer OLAP-Datenbank. Damit die Verarbeitung der Daten sauber funktioniert, müssen die Datenbanken aufeinander zugreifen und miteinander kommunizieren. Eine Selbstverständlichkeit, über die man sich bisher wenig Gedanken gemacht hat – mit Ausnahme der Tatsache, dass datenbankübergreifende Objektzugriffe in programmatischen Objekten in der Regel verboten sind. Der Zugriff erfolgt immer zentral mit Synonymen. Diese können später im Falle eines geänderten Datenbanknamens einfach und komfortabel erneuert werden, ohne alle programmatischen Objekte manuell anzupassen. Damit ist beispielsweise eine Überprüfung des Quellcodes mit Hilfe eines Berichts in der DeltaMaster-ETL-Anwendung möglich, der Fehler im Code aufdeckt (vgl. Abbildung 2).

Abbildung 2: SQL Code Quality Check
Mit der bestehenden Erfahrung aus der On-Premises-Welt neigt man bei ersten Projekten mit Azure dazu, die gleichen Techniken zu nutzen. Zunächst haben wir also neben einer Polybase-Testdatenbank eine zweite Azure-SQL-Datenbank aufgebaut, um die eigentlich „verbotene” datenbankübergreifende Abfrage zu probieren. Das Ergebnis zeigt die Fehlermeldung in Abbildung 3. Zugriffe auf andere SQL-Datenbanken oder -Server werden demnach von der SQL-Server-Version nicht unterstützt.

Abbildung 3: Trial 1 – Cross DB Query
Auch die bewährte On-Premises-Lösung – der zentrale Zugriff per Synonym – führt zum gleichen Resultat (vgl. Abbildung 4).

Abbildung 4: Trial 2 – Create Synonym
Ebenso wenig wird der Befehl „USE <database>“ unterstützt.
Lösen lässt sich das Problem mit den so gennannten Elastic Queries, also elastischen Abfragen. Mit diesem Microsoft-Konzept werden Abfragen auf große Datenebenen skaliert, um die Abfrageergebnisse in Berichten für Business Intelligence (BI) darzustellen.
Elastische Abfragen in der Theorie
Elastic Query ist als Feature im Microsoft Azure Standard-Tarif verfügbar und ermöglicht es, Abfragen in zweierlei Hinsicht elastisch aufzubauen: Zum einen über eine vertikale Partitionierung, bei der Daten in verschiedenen Tabellen auf mehrere Datenbanken verteilt werden; zum anderen über eine horizontale Partitionierung, bei welcher Datensätze auf einer horizontal hochskalierten Datenschicht verteilt sind. Beide Ansätze werden in den Microsoft Docs ausführlich beschrieben und hier kurz erläutert.
Bei einer horizontalen Partitionierung werden unterschiedliche Datensätze auf Tabellen in mehrere Datenbanken verteilt. Die Tabellen in den Datenbanken müssen exakt identisch sein. Ein Beispiel: Alle Kunden mit einer geraden Kundennummer werden in Datenbank A, die mit einer ungeraden Kundennummer in Datenbank B abgelegt. Ohne horizontale Partitionierung wären alle Datensätze in der gleichen Tabelle abgelegt. Sind die Datenbanken in einem Pool für elastische Datenbanken verteilt, kann man die Daten in Azure effizient mit einer gleichzeitigen Abfrage über alle Datenbanken hinweg abfragen. Der Fachbegriff für dieses Verfahren ist „Sharding“.
Für eine vertikale Partitionierung werden Daten in verschiedenen Tabellen auf mehrere Datenbanken verteilt. Ein Beispiel: Alle historischen Daten in einer Tabelle werden in Datenbank A abgelegt und alle aktuellen Daten in einer anderen Tabelle in Datenbank B. Dadurch kann man in Azure beispielsweise unterschiedliche Storage- und Compute-Leistungslevel für die jeweiligen Datentöpfe nutzen, da die historischen Daten zwar viel Speicher brauchen, aber viel seltener abgefragt werden. Die Verteilung erfolgt hier eher über eine inhaltliche Trennung der Daten in verschiedenen Tabellen, die in verschiedenen Datenbanken liegen. Ein solches vertikales Szenario nutzen wir für unsere datenbankübergreifenden Abfragen.
Elastische Abfrage mit vertikaler Partitionierung
Zunächst müssen wir der Zieldatenbank, in der wir die Abfrage durchführen wollen, den Zugriff auf die Quelldatenbank ermöglichen. Das funktioniert per Benutzername und Kennwort, da die Authentifizierung per Azure Active Directory mit elastischen Abfragen derzeit nicht unterstützt wird. Hierfür erstellen wir in der Quell- und Zieldatenbank je eine Tabelle, die wir abschließend in einem „Join“ miteinander verknüpfen.
Quelldatenbank:
CREATE TABLE [dbo].[T_S_Test](
[Col1] [int] NULL,
[Col2] [varchar](50) NULL,
[Col3] [varchar](250) NULL
) ON [PRIMARY]
GO
INSERT INTO [dbo].[T_S_Test]
VALUES
(1, 'External data 1', NULL),
(2, 'External data 2', 'Spalte 3'),
(3, 'External data 3', NULL)
GO
Zieldatenbank:
CREATE TABLE [dbo].[T_S_Test02](
[Col1] [int] NULL,
[Col2] [varchar](50) NULL,
[Col3] [varchar](250) NULL
) ON [PRIMARY]
GO
INSERT INTO [dbo].[T_S_Test02]
VALUES
(1, 'Test 1', NULL)
,(2, 'Test 2', NULL)
GO
Damit wir den Zugriff erstellen können, benötigen wir außerdem noch einen Master-Key, um das Kennwort des Benutzers zu verschlüsseln. Folgende Befehle erledigen den ersten Schritt:
--Step 1a) Master Key anlegen
CREATE MASTER KEY ENCRYPTION BY PASSWORD = 'UnfassbarSicheresMasterKeyKennwort';
--Step 1b) Zugriff auf Quellatenbank erstellen
CREATE DATABASE SCOPED CREDENTIAL ElasticDBQueryCrededtial
WITH IDENTITY = 'MyUser',
SECRET = 'MyUserPassword';
Ab hier funktioniert das Ganze ähnlich wie die Zugriffe auf andere Server-Systeme per Polybase mit dem Anlegen einer Datenquelle und Erstellen einer externen Tabelle. Beim Aufbau der Datenquelle wird allerdings explizit eine Datenbank mit angegeben:
--Step 2) Datenquelle erstellen
CREATE EXTERNAL DATA SOURCE ElasticDBQueryDataSource WITH
(
TYPE = RDBMS,
LOCATION = 'servername.database.windows.net',
DATABASE_NAME = 'Quelldatenbank',
CREDENTIAL = ElasticDBQueryCrededtial,
) ;
Abschließend wird die externe Tabelle für den Zugriff angelegt. Sollen Zielschema und Zieltabellenname dem der Quelldatenbank entsprechen, können die Parameter „SCHEMA_NAME“ und „OBJECT_NAME“ weggelassen werden. Gibt man den Objektnamen explizit an, ist man bei der Namenswahl auf dem Zielsystem frei. Wir wählen hier bewusst einen anderen Namen, um die externen von den „normalen” Tabellen bei den Abfragen auf den ersten Blick unterscheiden zu können. Dabei hilft das neue Präfix „TE_“ (für „Table External“):
--Step 3) Externe Tabelle erstellen
CREATE EXTERNAL TABLE [dbo].[TE_S_Test]
(
[Col1] [int] NULL,
[Col2] [varchar](50) NULL
)
WITH
(
DATA_SOURCE = ElasticDBQueryDataSource
,SCHEMA_NAME = 'dbo'
,OBJECT_NAME = 'T_S_Test'
)
Bei der Erzeugung ist es wichtig, dass die Tabellendefinition im Zielsystem derjenigen der Quelltabelle eins zu eins entspricht. Lediglich Spalten können weggelassen werden und die Nullability darf abweichen. Unserem Beispiel habe wurde „Col3“ in der Definition weggelassen.
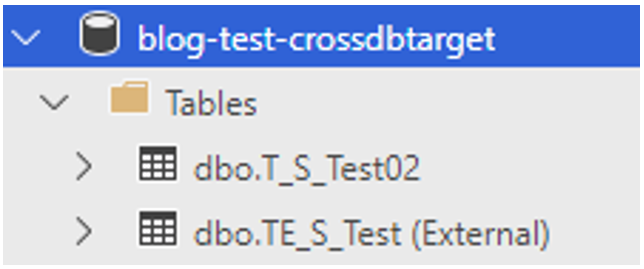
Abbildung 5: External Table created
Nach Abschluss dieses Arbeitsschrittes taucht die externe Tabelle wie üblich in den Datenbankobjekten auf (vgl. Abbildung 5). Sie kann in Abfragen wie eine lokale Tabelle verwendet werden. Abbildung 6 zeigt eine beispielhafte Abfrage mit der neuen externen Tabelle.
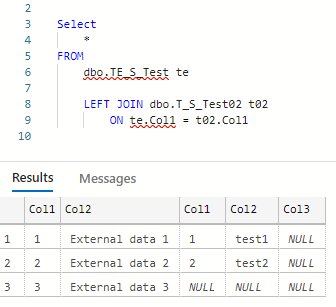
Abbildung 6: Finale Abfrage
Fazit
Mit der elastischen Abfrage ist damit die datenbankübergreifende Abfrage in der Cloud möglich, für die wir in der On-Premises-Variante auf Synonyme zurückgreifen. Sie hat allerdings ein paar Nachteile: Die komplette Tabellendefinition muss ein weiteres Mal vorgenommen werden und ist sehr empfindlich gegenüber Änderungen. Passt man beispielsweise die Länge eines „VARCHAR“-Datentyps in der Quelltabelle an, funktioniert die externe Tabelle bereits nicht mehr und reagiert auf Abfragen mit der in Abbildung 7 gezeigten Fehlermeldung.
Abbildung 7: Wrong data type
In dynamischen Umgebungen, die sich häufig ändern, ist man so dazu gezwungen, bei einer Definitionsänderung die externen Tabellen nachzupflegen. Hinzu kommt, dass die externe Tabelle nicht mehr sauber funktioniert, wenn die Länge des Quelldatentyps kleiner ist als in der Zieltabelle. Außerdem gibt es keine Übersicht, in welchen Datenbanken eine Quelltabelle als externe Tabelle angebunden ist. Damit schafft die Elastic Query in Azure-SQL-Datenbanken Fehlerquellen, gegen die Synonyme bei On-Premises-SQL-Datenbanken immun sind und daher stabiler funktionieren. Elastische Abfragen sind also eine praktikable Lösung zu datenbankübergreifenden Abfragen in der Cloud, haben aber noch Verbesserungsbedarf.
