In diesem Blogbeitrag wird aufgezeigt, wie Daten einfach, performant und nahezu in Echtzeit in einer OLAP-Datenbank aktualisiert werden können. Dafür wird eine periodische Aktualisierung mit einem Intervall im Sekundenbereich verwendet. Hervorzuheben sind die sehr gute Performance bei Datenabfragen bei gleichzeitiger unmittelbarer Verfügbarkeit von Daten und eine dazugehörige Fehlerbehandlung.
Eine Daten-Aktualisierung pro Tag ist für die meisten BI-Anwendungen ausreichend. Ausnahmen davon sind beispielsweise Lösungen im Produktionscontrolling. Auch an unsere Großbildschirmlösung DeltaMaster Gate wird häufig die Anforderung gestellt, dass die dargestellten Informationen auch untertägig aktualisiert werden sollen. Bisher wurden häufig ganze Würfel oder einzelne Kennzahlengruppen wiederholt untertägig verarbeitet.
In diesem Blogbeitrag wird eine Lösung aufgezeigt, in der Daten automatisch in einem konfigurierbaren periodischen Abstand aktualisiert werden. Dieses ist theoretisch sogar im Sekundenbereich möglich, also fast in Echtzeit. Eine tatsächliche Lösung in Echtzeit wäre auch denkbar, ist aber mit erhöhtem Aufwand und schlechterer Performance verbunden.
Als Beispiel-Datenbank wird die bekannte FoodMart Datenbank von Microsoft verwendet. Die Verkaufsdaten der Kennzahlengruppe „Sales Facts“ wird um eine dritte Partition „Real Time“ erweitert.
Proactive Caching
„Proactive Caching“ ist ein Feature von Microsoft Analysis Services (kurz SSAS). „Proactive Caching“ verbindet die Vorteile der beiden gegensätzlichen Speichermethoden multidimensional OLAP (kurz MOLAP) und relational OLAP (kurz ROLAP) von SSAS. Bei MOLAP werden Cube-Daten und Aggregationen in der OLAP-Datenbank gespeichert, müssen dafür aber aufwändig verarbeitet werden. Bei ROLAP entfällt die Verarbeitung, da alles auf der relationalen Datenbank verbleibt. Einzig die Meta-Informationen werden beim Deploy in der OLAP-Datenbank gespeichert. Ergänzend ist noch hybrid OLAP (HOLAP) zu nennen, dabei werden nur Aggregationen in der OLAP-Datenbank gespeichert.
Bereits mit dem SQL Server 2005 hat Microsoft „Proactive Caching“ vorgestellt, da die bereits genannten Möglichkeiten in der Praxis nicht immer ausreichen. Man möchte auch für periodisch aktualisierende Daten die bekannte und geschätzte Geschwindigkeit von Abfragen auf MOLAP und zusätzlich die unmittelbare Bereitstellung wie bei ROLAP. Und genau das bietet „Proactive Caching“.
Vorstellen kann man sich das Verfahren vereinfacht so, dass die entsprechend konfigurierte Partition einer Measuregroup nach einem festgelegten Intervall verarbeitet wird.
Quelldefinition
Die Daten müssen entweder in einer Tabelle auf der SQL BI-Datenbank bereitgestellt werden oder mittels eines Verbindungsservers abrufbar sein, beispielsweise von einem Vorsystem. Auf dieser Quelle wiederrum wird dann eine Sicht erstellt. Natürlich könnten die Quelldaten auch mittels einer Prozedur in eine Faktentabelle geladen werden, aber diese Prozedur müsste außerhalb des Features „Proactive Caching“ periodisch ausgeführt werden. Deswegen wird in diesem Beispiel eine Sicht erstellt.
Wenn eine Kennzahlengruppe aus mehreren Partitionen besteht, wie auch in diesem Beispiel, dann müssen folgende Punkte bei der Erstellung der Sicht oder Faktentabelle beachtet werden:
- Anzahl der Spalten muss in allen Partitionen gleich sein
- Bezeichnungen der Spalten müssen mit Bezeichnungen der vorhandenen Partitionen übereinstimmen
- Datentypen aller Spalten müssen exakt mit den Datentypen anderer vorhandener Partitionen übereinstimmen
Die Reihenfolge der Spalten spielt dagegen keine Rolle.
Beispiel Sicht für die FoodMart Datenbank:
CREATE VIEW [dbo].[V_sales_fact_real_time] AS -- 2017-07-06, TUN: created; view for sales fact real time data SELECT -- Dimensions fact.product_id ,fact.date_id ,fact.customer_id ,fact.promotion_id ,fact.store_id ,1 TimeUtilityID ,1 CumulationID ,1 ValueTypeID -- Measures ,fact.store_sales ,fact.store_cost ,fact.unit_sales -- Select * FROM dbo.sales_fact_real_time fact

Abbildung 1: SQL Server Management Studio – Vorhandene Fact-View und neue View
Konfiguration im Visual Studio
Im Visual Studio sind nur wenige aber entscheidende Schritte zur Konfiguration einer Partition und Aktivierung von „Proactive Caching“ notwendig.
- Zunächst wird eine neue Partition in der bereits vorhandenen „Sales Facts“ Kennzahlengruppe angelegt.

Abbildung 2: Visual Studio – Neue Partition anlegen
2. Als Partitionsquelle kann die Datenquelle oder die Datenquellensicht der OLAP Datenbank verwendet werden. Soll die Datenquellensicht verwendet werden, dann muss die View in der Datenquellensicht vorher angebunden werden.

Abbildung 3: Visual Studio – Partitionsquelle und Tabelle/Sicht auswählen
3. Zeilen brauchen nicht eingeschränkt werden.

Abbildung 4: Visual Studio – Zeilen einschränken
4. Verarbeitungs- und Speicherort brauchen ebenfalls nicht geändert werden.

Abbildung 5: Visual Studio – Verarbeitungs- und Speicherort
5. Aggregationen brauchen ebenfalls nicht entworfen werden. Dazu aus dem Auswahlmenü den Punkt „Aggregationen später entwerfen“ wählen.

Abbildung 6: Visual Studio – Aggregationen
6. Nachdem die Partition erstellt ist, müssen die Speichereinstellungen angepasst werden.

Abbildung 7: Visual Studio – Partitionen und Speichereinstellungen
7. In den Speichereinstellungen die Option „Benutzerdefinierte Einstellung“ auswählen und anschließend den Button „Optionen…“ für weitere Einstellungsmöglichkeiten klicken.

Abbildung 8: Visual Studio – Partition Speichereinstellungen festlegen
In den Speicheroptionen sollte zunächst sichergestellt werden, dass der Speichermodus „MOLAP“ gewählt ist (Standard). Für „Proactive Caching“ muss dann als erstes der Haken „Proaktives Zwischenspeichern aktivieren“ gesetzt werden. Anschließend wird in den Cacheeinstellungen der Haken bei „Cache regelmäßig aktualisieren“ gesetzt. Abschließend wird noch ein „Neuerstellungsintervall“ festgelegt.
Welches Intervall gewählt wird, hängt von mehreren Faktoren ab: Bestimmend sollten Einsatzzweck der Informationen und Aktualisierung der Daten im Vorsystem sein. Wenn die Daten im Vorsystem nur stündlich geändert werden, dann reicht als Intervall auch eine Stunde. Weiterhin ist die zu verarbeitende Datenmenge zu berücksichtigen. Zu kurz sollte das Intervall nicht gewählt werden, schließlich muss die Abfrage innerhalb dieser Zeit beantwortet werden.

Abbildung 9: Visual Studio – Benutzerdefinierte Speicheroptionen
8. Genau diese Konfiguration ist auf einem Kundensystem seit über einem Jahr aktiv und kann daher empfohlen werden. Dennoch sollen die weiteren Konfigurationsmöglichkeiten erläutert werden.
Alle nachfolgend genannten Optionen sind nur in Verbindung mit „Benachrichtigungen“ sinnvoll:
a. Cache bei Datenänderungen aktualisieren
i. Das „Ruheintervall“ gibt an, wie lange nach einer Benachrichtigung gewartet werden soll, bevor der Cache aktualisiert wird.
ii. Das „Ruheüberschreibungsintervall“ ist die maximale Wartezeit bevor der Cache aktualisiert wird. Theoretisch könnten immer wieder Benachrichtigungen kommen und der Cache würde nie aktualisiert werden.
b. Veralteten Cache löschen
i. Die „Latenzzeit“ gibt an, wie lange der veraltete Cache nach einer Benachrichtigung noch verwendet werden darf, während der neue Cache erstellt wird. Wenn die Zeit abgelaufen ist, dann werden die Abfragen an die relationale Datenbank gestellt.
c. Optionen
i. „Sofort online schalten“ bedeutet, dass Anfragen nie aus einem veralteten Cache beantwortet werden, sondern so lange von der relationalen Datenbank, bis der Cache aktualisiert wurde.
ii. „ROLAP-Aggregationen aktivieren“ bedeutet, dass materialisierte Views für Aggregationen auf der relationalen Datenbank erstellt werden.
d. Benachrichtigungen
i. „SQL Server“: Bei Datenänderungen in den angegebenen Tabellen teilt die relationale Datenbank SSAS mit, dass es eine Änderung gegeben hat. Die Option kann nur in Verbindung mit einem SQL Server als relationale Quelle genutzt werden. Außerdem muss der SSAS-Dienstuser oder der in der Datenquelle angegebene Nutzer SA- oder ALTER TRACE Rechte besitzen.
ii. „Vom Client initiiert“: An SSAS muss ein XMLA NotifyTableChange Befehl gesendet werden.
iii. „Geplantes Abrufen“: Periodisch wird eine relationale Quelle geprüft, ob neue Daten vorhanden sind. Ist das der Fall, kann der Cache ganz oder sogar inkrementell aktualisiert werden. Diese Option ist für große Partitionen äußerst sinnvoll und bietet die größtmögliche Flexibilität.
Die Abbildung 10 visualisiert die verschiedenen Optionen.

Abbildung 10: Analysis Services 2005 Performance Guide – Low Latency Proactive Caching Settings
Die vorgenommenen Änderungen müssen jetzt noch gespeichert und anschließend muss die OLAP Datenbank einmalig verarbeitet werden.
Test: Jetzt kann in der Basistabelle ein neuer Datensatz hinzugefügt werden und dieser sollte nach dem Neuerstellungsintervall im Bericht vorhanden sein. Weitere Einstellungen sind nicht erforderlich.
Fehlerbehandlung
Der aufmerksame Leser wird sich zurecht die Frage stellen, was passiert, wenn in der Faktentabelle unbekannte oder leere Dimensions-IDs stehen, beispielsweise eine neue KundenID. Hierfür gibt es u.a. folgende Lösungsvarianten, die auch kombiniert werden können:
- Die SQL View wird um eine Fehlerbehandlung erweitert: ISNULL-Prüfung in Verbindung mit LEFT JOIN auf die verarbeiteten Dimensionstabellen. Voraussetzung dafür ist, dass sich die Tabellen der Dimensionen nicht ändern. Achtung: Während einer Transformation ändern sich die Tabellen!
Wichtig ist auch, dass die View möglichst schnell ist, denn diese wird schließlich sehr häufig verarbeitet.
ALTER VIEW [dbo].[V_sales_fact_real_time] AS -- 2017-07-06, TUN: created; view for sales fact real time data -- 2017-07-06, TUN: changed; added error handling SELECT -- Dimensions ISNULL(p.product_id, -1) AS product_id -- -1: Unknown Member ,fact.date_id ,ISNULL(c.customer_id, -1) AS customer_id -- -1: Unknown Member ,ISNULL(promo.promotion_id, -1) AS promotion_id -- -1: Unknown Mbr ,ISNULL(s.store_id, -1) AS store_id -- -1: Unknown Member ,1 TimeUtilityID ,1 CumulationID ,1 ValueTypeID -- Measures ,fact.store_sales ,fact.store_cost ,fact.unit_sales -- Select * FROM dbo.sales_fact_real_time fact -- remove all datasets with an unknown date_id JOIN dbo.[time] t ON fact.date_id = t.date_id LEFT JOIN dbo.product p ON fact.product_id = p.product_id LEFT JOIN dbo.customer c ON fact.customer_id = c.customer_id LEFT JOIN dbo.promotion promo ON fact.promotion_id = promo.promotion_id LEFT JOIN dbo.store s ON fact.store_id = s.store_id
2. Konfiguration einer benutzerdefinierten Fehlerbehandlung in der Echtzeit-Partition. Wichtig sind die Parameter „KeyErrorLimit“ und „KeyErrorLimitAction“. „KeyErrorLimit“ definiert die maximal zulässige Anzahl an Fehlern. In „KeyErrorLimitAction“ wird eingestellt, was passieren soll, wenn das Limit erreicht wird. Hier sollte „StopLogging“ statt „StopProcessing“ eingestellt werden. Anschließend wird der Cache weiterhin regelmäßig aktualisiert, aber fehlerhafte Datensätze werden ignoriert, also nicht mit in den Würfel übernommen.
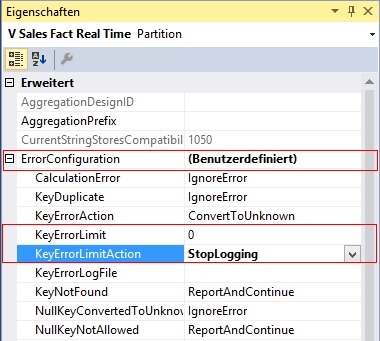
Abbildung 11: Visual Studio – Eigenschaften der Partition
Fazit
„Proactive Caching“ bietet eine einfache Möglichkeit, Daten in einem Würfel ohne aufwendige Verarbeitung bereitzustellen. Es muss auch nicht zwingend ein Echtzeit-Szenario sein, auch könnten untertägige Verarbeitungen ganz vermieden werden, wenn einzelne Partitionen auf „Proactive Caching“ umgestellt werden.
Wir empfehlen darüber hinaus, die Datenmenge in der „Proactive Caching“-Partition so klein wie möglich zu halten. Beispiel:
In einer BI-Anwendung, die täglich verarbeitet wird, reicht es aus, in der Echtzeit-Partition nur die Daten des aktuellen Tages vorzuhalten. Alle älteren Daten werden in den verarbeiteten Partitionen vorgehalten. Während einer Verarbeitung können dann alle Daten in die verarbeiteten Partitionen kopiert werden. Hat die Verarbeitung funktioniert und die Daten sind in den Cube geladen, können schließlich alle kopierten Daten aus der Echtzeit-Partition gelöscht werden.
Das hat auch noch einen weiteren Vorteil: Sollte eine Verarbeitung fehlschlagen, dann stehen trotzdem aktuelle Daten zur Verfügung.
Weiterhin ist zu erwähnen, dass „Proactive Caching“ auch für Dimensionen verwendet werden kann. Vorsicht ist nur bei der kombinierten Verwendung von „Proactive Caching“ in Dimensionen und Measuregroups geboten. In früheren SQL Server Versionen hat dieses nicht funktioniert. Tests mit aktuellen Versionen stehen noch aus.
Für Planungsanwendungen ist „Proactive Caching“ ausdrücklich nicht geeignet. Es kann nicht garantiert werden, dass ein Cache tatsächlich unmittelbar nach einer Dateneingabe aktualisiert wird. Dazu sollte RealTimeOLAP verwendet werden, so wie es auch in der Bissantz Hybrid-Planung gemacht wird.
Links
Speicheroptionen von Partitionen
https://msdn.microsoft.com/de-de/library/ms183583(v=sql.120).aspx
https://msdn.microsoft.com/de-de/library/ms189695(v=sql.120).aspx
Proaktives Zwischenspeichern
https://msdn.microsoft.com/de-de/library/ms174769(v=sql.120).aspx
http://bidn.com/Blogs/near-real-time-olap-using-ssas-proactive-caching
https://technet.microsoft.com/en-us/library/bb630295(v=sql.105).aspx
Analysis Services Proactive Caching Operations and Errors
SSAS Processing Error Configurations
