So leicht sich Benchmarking anhören mag, so komplex sind Konzepte zur effizienten Implementierung einer Benchmarkinganwendung. Dieser Blogbeitrag spiegelt die Erfahrungen eines unserer Projekte wider. Er beschreibt hierbei die grundlegenden Konzepte zum Aufbau einer Benchmarkinganwendung und deren spezielle Umsetzung in DeltaMaster. Interessiert? Dann erfahren Sie hier Schritt für Schritt, wie Sie Ihre eigene Benchmarkinganwendung mit DeltaMaster entwerfen können.
Begriffsdefinition
Benchmarking ist ein systematischer und kontinuierlicher Prozess des Vergleichens von Produkten, Dienstleistungen und Prozessen im eigenen Unternehmen sowie mit denen in fremden Unternehmen in qualitativer und/oder quantitativer Hinsicht. Als problematisch beim Benchmarking gilt die Informationsbeschaffung, wenn Vergleiche zu externen Marktteilnehmern angestrebt sind. Hingegen sind beim internen Benchmarking, also dem Messen der eigenen Performance mit Abteilungen oder Standorten des eigenen Unternehmens, die erforderlichen Daten leicht erhältlich.
Darüber hinaus sind die Benchmarkingobjekte des eigenen Unternehmens besser miteinander vergleichbar, als dies mit externen Vergleichsobjekten der Fall wäre. Der Grund hierfür liegt vor allem in unterschiedlichen Organisations- bzw. Führungsstrukturen, welche die operative Leistungserstellung eines Unternehmens stark prägen. Unter Berücksichtigung der genannten Punkte stellt das interne Benchmarking einen vergleichsweise leicht zu implementierenden Benchmarkingansatz dar. Damit kann die eigene Performance durch die Anlehnung an die internen „best practices“ gemessen und optimiert werden.
Anwendungsszenario und Herausforderung
In unserem Projekt ging es um ein internes Benchmarking zwischen den Standorten eines IT-Dienstleisters. Hierbei sollten den Standorten (Systemhäusern) insgesamt vier Arten des Vergleichs geboten werden. Neben drei organisatorisch verankerten Vergleichsgruppen sollte den Anwendern auch die Möglichkeit zur Definition einer individuell zu definierenden peergroup, die also mit beliebigen Wunschkandidaten befüllt werden kann, geboten werden. Neben der technischen Implementierung zur Selektion der Benchmarkingobjekte in den vier Vergleichsgruppen (in folgenden einfach als peergroups bezeichnet) galt es, DeltaMaster beizubringen, automatisch die passenden Vergleichsobjekte zur jeweiligen Einheit in den Berichten zu verwenden und die Berechnung von Rangpositionen stets innerhalb der entsprechenden peergroup durchzuführen.
Die Berichte wurden daher so konzipiert, dass bei Auswahl der eigenen Einheit in der Sicht (Dimension „Einheit“) die Vergleichsobjekte in den Achsen automatisch (d.h. datengetrieben) ermittelt und angezeigt werden. Ein datengetriebener Berichtsaufbau, der einzig durch die Auswahl eines Elements der Sicht gesteuert wird, ist auch hinsichtlich der Berichtsverteilung von sehr hohem praktischem Nutzen. So kann über den DeltaMaster Berichtsserver die Generierung und Verteilung der Berichtsmappen für jeden Standort schnell und einfach mittels einer Berichtsiteration entlang der Standortdimension erfolgen. Dieses Konzept ist keineswegs neu oder ausschließlich für das Design von Benchmarkinganwendungen geeignet. Auch in den Blogbeiträgen zur Implementierung von Planungsanwendungen wird genau dieser Ansatz beschrieben.
Wer oder was?
Gedanklicher Ausgangspunkt eines jeden Benchmarking ist neben der Auswahl der Benchmarkingkennzahlen die Auswahl der Objekte (Standorte, Filialen, Produkte, etc.), mit denen man sich vergleichen möchte. Aus technischer Sicht betrachtet liegen die Objekte, die miteinander verglichen werden sollen, stets innerhalb einer Dimension des Datenmodells. Diese Dimension wird in Folge als Benchmarkingdimension bezeichnet.
Die Objekte einer peergroup besitzen in der Regel ein gemeinsames Ordnungskriterium. Bei Standorten könnte dies beispielsweise eine übergeordnete Geo-Codierung (Region) oder eine organisatorische Zuordnung (Verantwortungsbereich) sein. Je nach Art der Benchmarkingkennzahlen ist es nicht zwingend erforderlich, dass sich die Vergleichsobjekte in Größe und Strukturen ähneln. Bei der Verwendung relativer Kennzahlen, wie beispielsweise einem Personalkostenanteil in %, sind Vergleiche stets aussagekräftig – also auch dann, wenn sich die gesamte Anzahl der Mitarbeiter der einzelnen Benchmarkingobjekte stark voneinander unterscheidet.
Datengetriebene peergroups
Widmen wir uns zunächst der Definition einer peergroup im Sinne einer Sammlung von Objekten mit identischen Ordnungskriterien. Eine solche peergroup kann in der Regel automatisch aus den Stammdaten des Datenmodells abgeleitet werden.
Der einfachste Fall liegt vor, wenn das identische Ordnungskriterium bereits als Ebene in der Benchmarkingdimensinon enthalten ist. In diesem Fall bilden die Kinder eines bestimmten Hierarchieknotens die peergroup. Im Hinblick auf unser Anwendungskonzept, bei dem stets die eigene Einheit in der Sicht der Benchmarkingdimension ausgewählt ist, lassen sich die Vergleichsobjekte mit folgendem MDX-Statement ermitteln:

Benutzergetriebene peergroups
Individuelle peergroups lassen sich am besten durch Picklisten, die der Anwender ggf. auch selbständig pflegen kann, zusammenstellen. Letzteres bedingt, dass die Definition der peergroup am besten in Form eines Berichts in DeltaMaster erfolgen sollte. Hierzu greifen wir auf bekanntes Know-how zurück: zur Parametrisierung einer Planungsanwendung hat sich bereits ein Ansatz etabliert, den wir “Aktivierung” nennen.
Hierbei versieht der Anwender durch Eingabe einer 1 in einer entsprechenden Aktivierungsmatrix die gewünschten Objekte mit einem Aktivierungsflag. Im Fall einer Planer-Land-Zuordnung bestünde die Aktivierungsmatix aus den zwei unterschiedlichen Dimensionen Planer und Land. Die Besonderheit, die es bei unserer Benchmarkinganwendung zu berücksichtigen gilt, liegt nun darin, dass sowohl das Sichtkriterium (der Standort, der die Vergleichobjekte auswählt) als auch die Vergleichobjekte (welche Standorte er gerne in der Vergleichsgruppe hätte) in derselben Dimension liegen. Dies erfordert, dass die originäre Standortdimension nochmals als Hilfsdimension im Datenmodell gespiegelt und in der measuregroup zur Aktivierung aufgenommen wird. Nur so können die Aktivierungsflags auf die gewünschten Standorte (Vergleichsobjekte) eines Standorts gesetzt werden.
Neben dieser modelltechnischen Notwendigkeit muss überlegt werden, auf welche der beiden Standortdimensionen die Flags nun gesetzt werden. Die Antwort liegt klar auf der Hand: es muss die originäre Standortdimension sein, denn auf dieser Dimension liegen die Daten. Die Hilfsdimension dient lediglich dazu, den auswählenden Standort zu vermerken. Damit dies in unserer Benchmarkinganwendung automatisch geschieht, bedienen wir uns dem MDX-Statement LinkMember, dass zu einem Member aus Dimension A den gleichnamigen Member aus Dimension B findet. Somit lässt sich durch Auswahl der originären Einheit in der Sicht der gleichnamige Member der Hilfsdimension finden.
linkMember(, [Hilfsdimension].[Hierarchie])
Diese MDX-Abfrage zur Auswahl der gespiegelten Einheit in der Hilfsdimension wandert also in den Filter der Pivottabelle unserer Aktivierungsmatrix. Auf der Zeilenachse der Aktivierungsmatrix werden dann alle Standorte aus der originären Standortdimension angezeigt. Auf diese Weise werden die Flags auf die originären Einheiten gesetzt. Ein Berichtslayout für eine solche Aktivierungsmatrix, das dem Anwender neben der Aktivierung auch noch Zusatzinformationen über die Vergleichbarkeit des eigenen Standorts zu allen anderen bietet, könnte wie folgt aussehen:
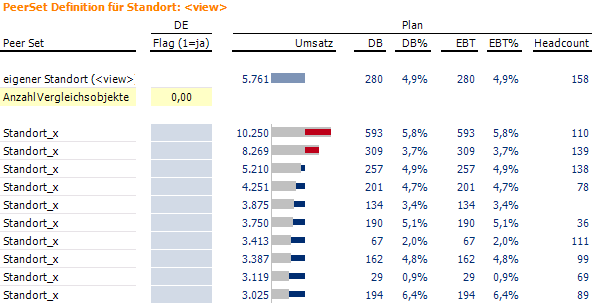
Die Abfrage einer individuellen peergroup erfolgt dann anhand der Aktivierung eines Standorts in Bezug auf den in der Hilfsdimension gespiegelten Standort:
Filter
([Dimension].[Hierarchie].[Ebene_Vergleichsobjekte].members,
(linkMember(, [Hilfsdimension].[Hierarchie]),
[Measures].[Aktivierungsflag]) = 1
)
Verwendung mehrerer Peergroups
Die Verwendung mehrerer Vergleichsgruppen erfordert besondere Berücksichtigung im Datenmodell und im Berichtsaufbau. Grundsätzlich lassen sich beliebig viele daten- und benutzerdefinierte peergroups nach den oben beschriebenen Ansätzen mit MDX definieren. Nun muss noch dafür gesorgt werden, dass der Anwender die gewünschte peergroup auswählen kann. Hierzu wäre es wenig produktiv, wenn jeder Bericht in x-facher Ausfertigung erstellt würde. Viel eleganter wäre eine Lösung, bei der stets ein und dasselbe Berichtstemplate für alle peergroups gleichermaßen verwendet wird
Zunächst muss eine Lösung geschaffen werden, dass der Anwender die peergroup auswählen kann. Am einfachsten könnte dies sicher über die Sicht erfolgen. Hierzu muss eine weitere Hilfsdimension ins Datenmodell aufgenommen werden, die ausschließlich einem einzigen Zweck dient: der Auswahl (und damit der Abfrage), welche peergroup verwendet werden soll.
Anhand einer Abfrage, welche peergroup der Anwender gerade in der neuen Hilfsdimension ausgewählt hat, ist es mittels eines MDX CASE-Statements recht einfach, die passende Auswahl der Vergleichsobjekte zu ermitteln. Hierbei lassen sich alle zuvor beschriebenen Szenarien zur Auswahl daten- und/oder benutzergetriebener peergroups integrieren:

Integriert man das oben skizzierte MDX-Statement in die Zeilenachse einer Pivottabelle, so liefert diese in Abhängigkeit der in der Hilfsdimension ausgewählten peergroup das entsprechende Set an Vergleichobjekten. Damit kann eine einzige Pivottabelle als template zur Anzeige beliebiger peergroups verwendet werden.
Ausblick
Der Blogbeitrag soll den grundsätzlichen Einstieg in eine Benchmarkinganwendung erleichtern. Welche Highlights DeltaMaster hinsichtlich der Benchmarkingberichte in der Hinterhand hat, erfahren Sie in einem folgenden Beitrag.
