Daten sind die Grundlage jedes BI-Projekts – ohne Daten ist keine Analyse möglich. Aber woher kommen diese Daten? Häufig wird eine SQL-Server-Datenbank als relationale Datenquelle gewählt. Aber meistens liegen nicht alle Daten in dieser Datenbank bereits vor. Dann müssen die fehlenden Daten in die SQL-Server-Datenbank importiert werden. Die Quellen für diese Datenimporte können sehr vielfältig sein – von anderen Datenbanken bis hin zu Textdateien. Um sich die Arbeit des Datenimports zu erleichtern, bietet sich die Verwendung der SQL Server Integration Services (SSIS) von Microsoft an. Daten aus verschiedensten Quellen lassen sich hier problemlos verarbeiten. Die Automatisierung über einen Scheduler ist ebenfalls leicht zu realisieren.
Was kann man aber tun, wenn man Daten in sporadischen Zeitabständen importieren soll und den Import nicht manuell ausführen möchte? Weiß man nicht, wann die Datei vorliegt, benötigt man ein SSIS-Paket, das prüft, ob eine Datei in einem vorgegebenen Verzeichnis vorhanden ist und die Verarbeitung auch nur dann startet. Nach dem Import muss die Datei gelöscht oder zumindest umbenannt werden, um einen erneuten Import der gleichen Daten am nächsten Ausführungstermin des SSIS-Paketes zu verhindern.
Genau dies soll hier am Beispiel eines Imports von Plandaten aus einer csv-Datei in die Chair-Datenbank gezeigt werden.
Wie gehen wir vor: Zunächst erzeugen wir uns ein neues SSIS-Paket und legen die Verbindungsmanager für die Verbindung zur Datenbank bzw. zur Importdatei fest. Der erste Task, den wir uns aus der Toolbox in die Ablaufsteuerung ziehen, sollte die Prüfung beinhalten, ob die zu importierende Datei vorhanden ist. Als Grundlage dafür bietet sich ein Skript-Task an.
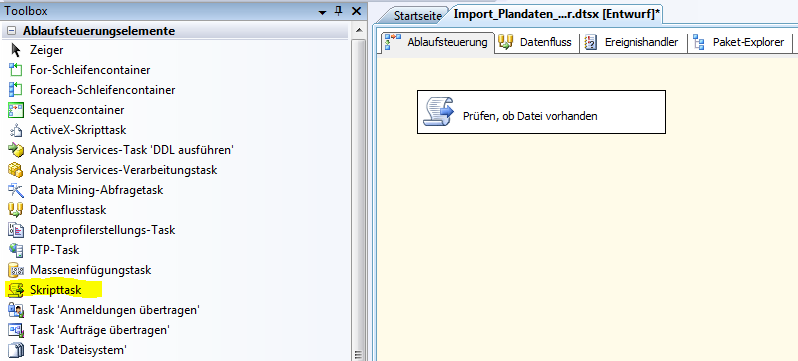
Abb. 1: Skripttask einfügen
Da man für Skript-Tasks meist Variablen benötigt, sollte man an dieser Stelle die erforderlichen Variablen anlegen. Dafür in der Menüleiste das Menü SSIS aufklappen und Variablen auswählen.
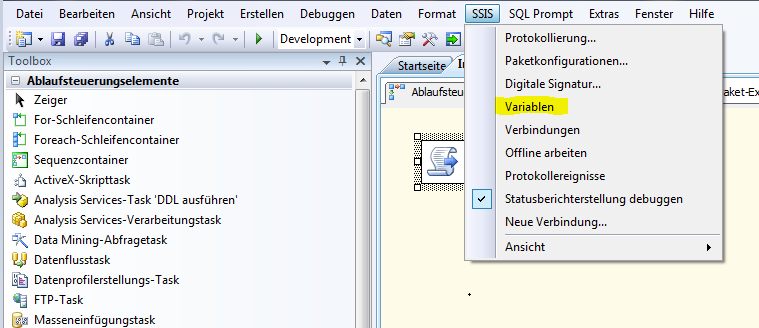
Abb. 2: Variablenanzeigen
Neben der Toolbox erscheint nun in einem separaten Reiter die Anzeige der Variablen. Wir legen folgende Variable an:
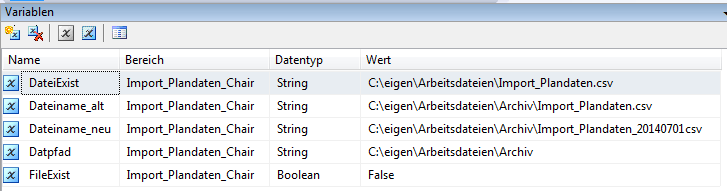
Abb. 3: Variable
Die Variable DateiExist enthält den vollständigen Pfad und den Namen der zu importierenden Datei. Die beiden Variablen Dateiname_alt und Dateiname_neu brauchen wir später zum Umbenennen der Importdatei. In DatPfad speichern wir das Verzeichnis, in welchem sich unsere Importdatei befindet und die Variable FileExist vom Typ Boolean wird das Ergebnis der Abfrage, ob die Importdatei vorhanden ist, aufnehmen.
Nun können wir uns unserem ersten Skripttask widmen, den wir bereits angelegt haben. Mit Skripttask bearbeiten erhalten wir folgenden Bildschirm:
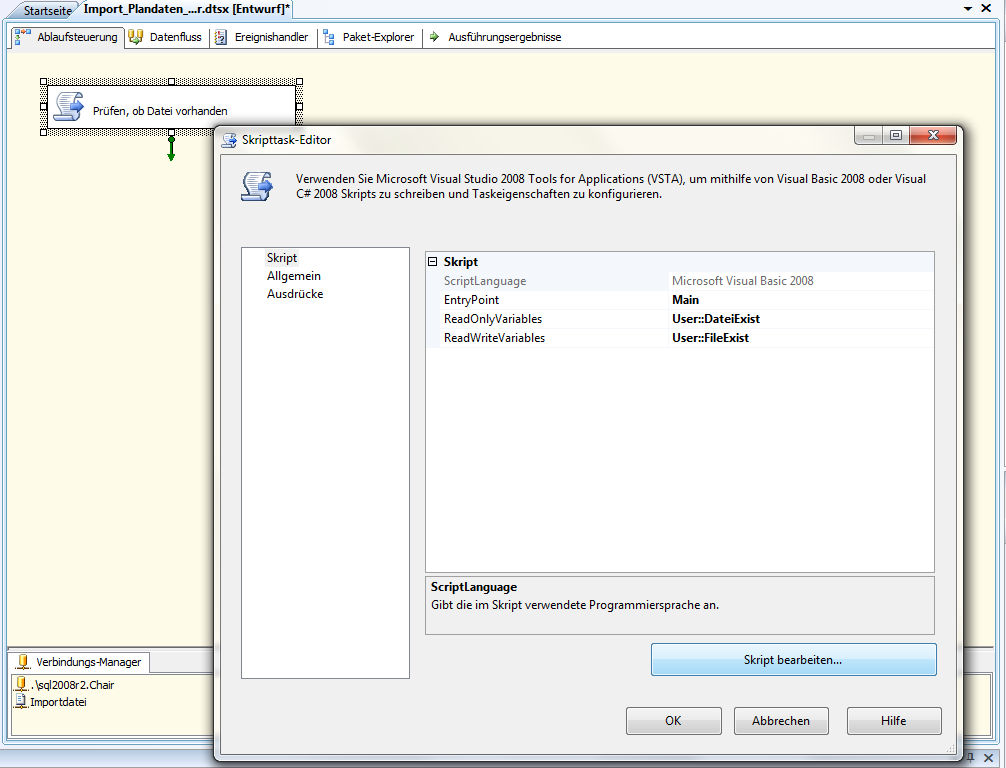
Abb. 4: Skripttask bearbeiten
In den ReadOnlyVariables tragen wir unsere Variable DateiExist ein. Da es sich um eine userspezifische Variable handelt, ist der vollständige Name der Variable User:DateiExist. In die ReadWriteVariables tragen wir die Variable User:FileExist ein. Danach gehen wir auf Skript bearbeiten und schreiben folgenden Programmcode:
Public Sub Main()
If System.IO.File.Exists(Dts.Variables("DateiExist").Value) Then
Dts.Variables("FileExist").Value = True
Else
Dts.Variables("FileExist").Value = False
End If
Dts.TaskResult = ScriptResults.Success
End Sub
Damit haben wir die Prüfung definiert, die feststellt, ob die Importdatei existiert. Bei erfolgreicher Prüfung soll der Datenimport gestartet werden. Dafür legen wir einen Datenflusstask an und verbinden den Skripttask mit dem neuen Datenflusstask. Da der Datenimport nur dann gestartet werden soll, wenn die Prüfung erfolgreich war, müssen wir die Verbindung konfigurieren. Das erfolgt durch einen Doppelklick auf den Verbindungspfeil und folgenden Eintrag im Rangfolgeneinschränkungs-Editor.
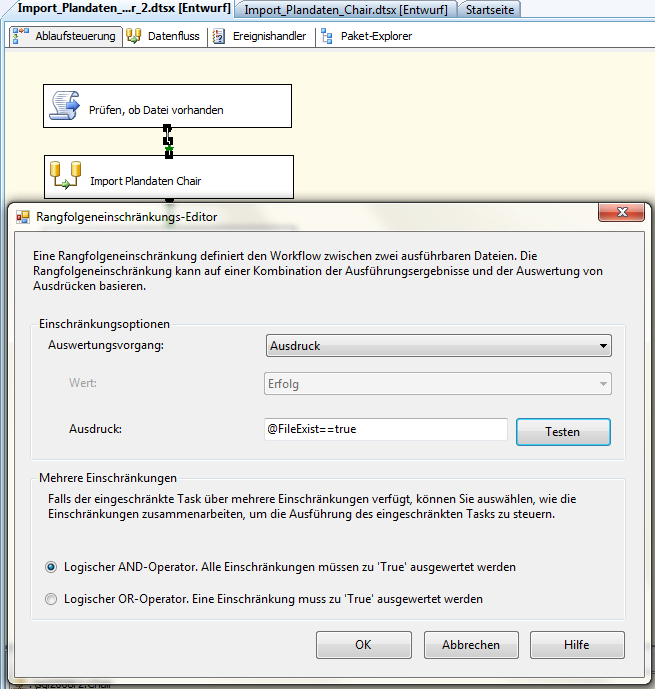
Abb. 5: Einschränkung festlegen
Dadurch erreichen wir, dass der nachfolgende Import nur dann ausgeführt wird, wenn die Variable FileExist dem Wert true entspricht. Ist keine Datei vorhanden, wird der Variable FileExist der Wert false zugewiesen und die Abarbeitung des Paketes ohne Datenimport beendet.
Wurde der Datenimport ausgeführt, sollten wir die Datei in ein Archivverzeichnis verschieben und sie sinnvollerweise auch umbenennen, damit nachfolgende Verschiebeaktionen die Datei, die ja für den Import immer den gleichen Namen hat, nicht überschreibt. Natürlich könnte man die Importdatei an dieser Stelle auch löschen, aber wenn der Datenimport aus verschiedensten Gründen wiederholt werden muss, wäre dies ohne die Importdatei nicht mehr möglich.
Das Verschieben und Umbenennen erreichen wir mit Dateisystem-Tasks. Bevor wir diese anlegen, sollten wir mit einem neuen Skripttask den neuen Dateinamen bilden. Die Variablen User:Datpfad, User:Dateiname_alt und User:Dateiname_neu haben wir bereits angelegt. User:Dateiname_alt wurde bereits bei der Anlage der Variable mit dem ursprünglichen Namen der Importdatei belegt.
Im Skripttask tragen wir die beiden anderen Variablen (User:Datpfad, User:Dateiname_neu) unter den ReadWriteVariables ein.
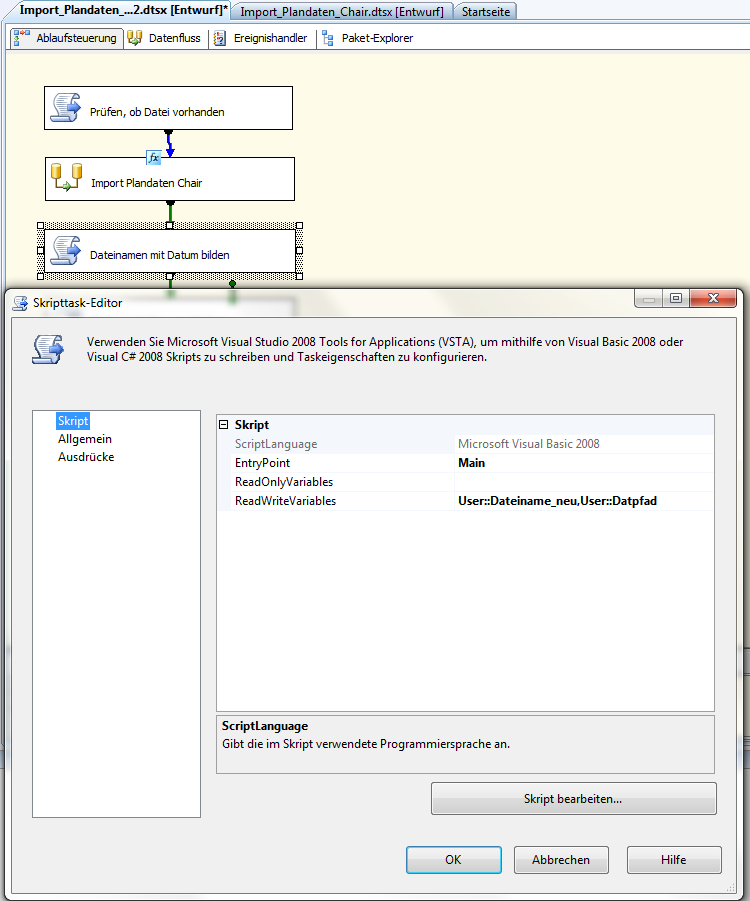
Abb. 6: Skripttask zur Bildung des neuen Dateinamens
Als Skript können wir zum Beispiel folgendes schreiben, wenn wir an den alten Dateinamen das aktuelle Jahr und Monat anhängen wollen, was bei monatlichem Import ausreichend ist. An dieser Stelle sind aber auch andere Skriptvarianten möglich, je nachdem welchen Namen die Importdatei zur Archivierung erhalten soll.
Public Sub Main()
'
Dim dattmp As String
Dim pathtmp As String
'
' Dateinamen neu bilden und in Variable Dateiname_neu ausgeben
' Dateipad in Variable DatPfad speichern
'
dattmp = "C:\eigen\Arbeitsdateien\Archiv\Import_Plandaten_" + CStr(Year(Today())) + CStr(Month(Today())) + ".csv"
Dts.Variables("Dateiname_neu").Value = dattmp
pathtmp = "C:\eigen\Arbeitsdateien\Archiv"
Dts.Variables("Datpfad").Value = pathtmp
Dts.TaskResult = ScriptResults.Success
End Sub
Nun fügen wir die beiden Dateisystem-Tasks ein und editieren sie wie folgt:
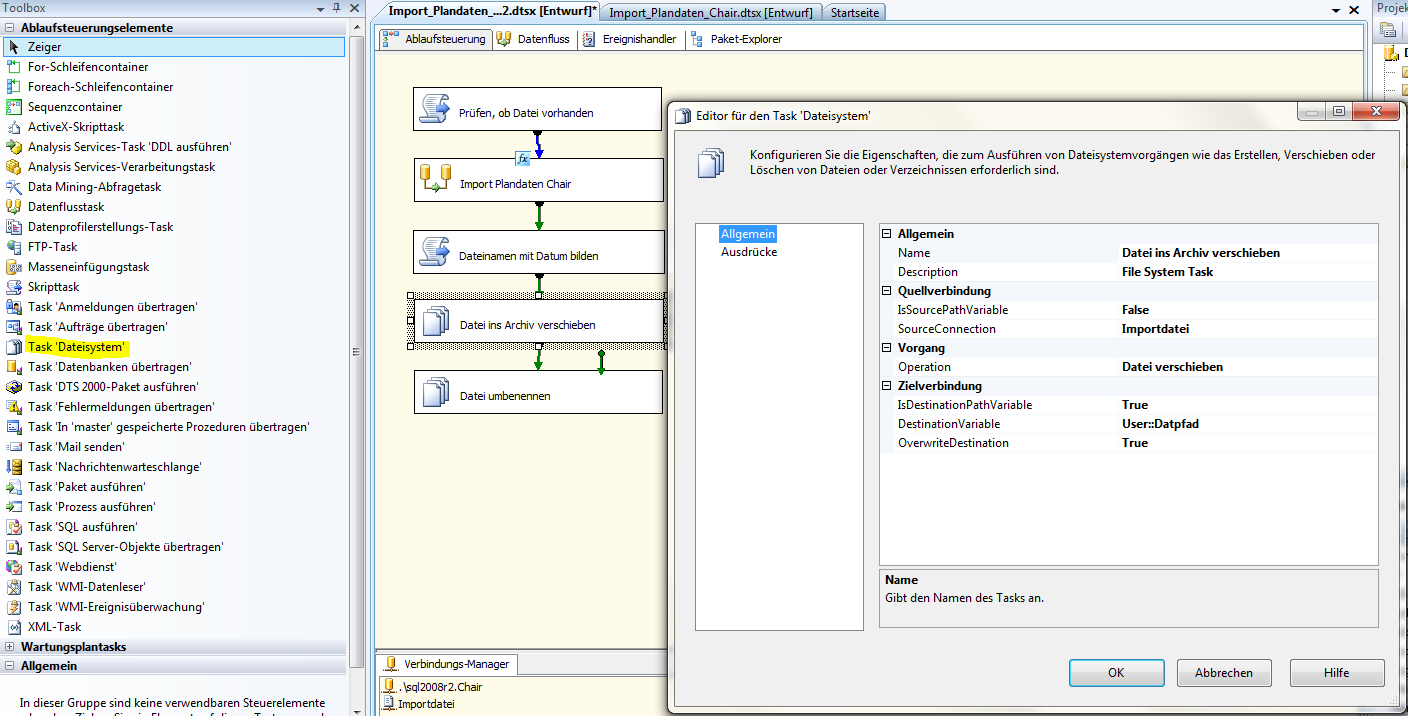
Abb. 7: Datei ins Archiv verschieben
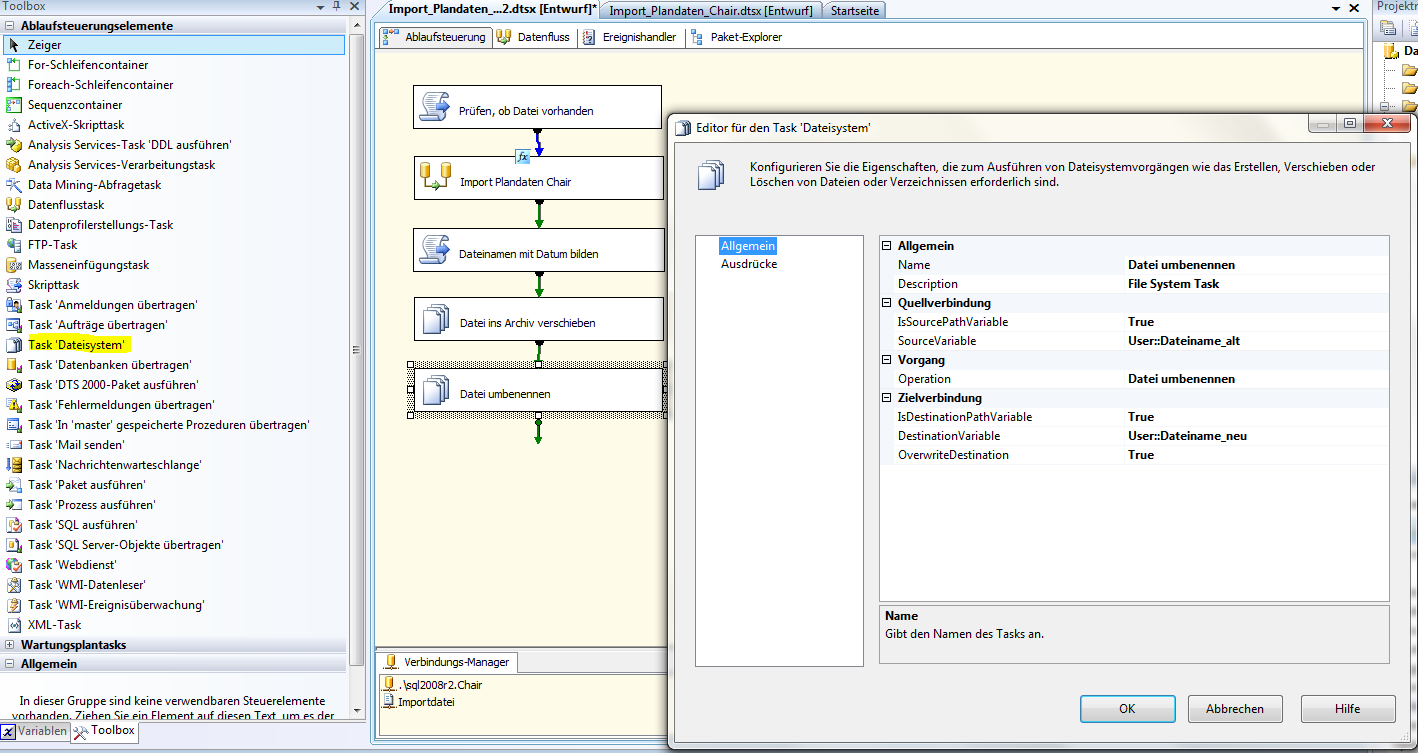
Abb. 8: Datei umbenennen
Damit haben wir ein SSIS-Paket erstellt, welches vor dem Import auf das Vorhandensein einer Im-portdatei prüft, nach dem Import die Datei in ein Archivverzeichnis verschiebt und ihr dort einen neuen Namen gibt.
Man kann das SSIS-Paket automatisiert ausführen ohne Kenntnis darüber, wann eine Importdatei zur Verfügung steht. Einzige Voraussetzung ist, dass die Importdatei immer den gleichen Namen hat und immer in dem gleichen festgelegten Verzeichnis abgelegt wird.
