Legt man Tabellen zur Dateneingabe an, ist es immer wieder eine Herausforderung, mit neuen Anforderungen umzugehen – inklusive der daraus resultierenden Veränderungen an den Zieltabellen und Routinen. Kleinere Änderungen können unter Umständen erheblichen Aufwand verursachen. Im Folgenden zeigen wir, wie man mit dem Application Designer von Bissantz einige Routinetätigkeiten vereinfacht und wie man das Tool auf verteilten Systemen im Kundenumfeld einsetzen kann.
Das Erstellen von Pflege- und Planungsanwendungen mit Eingabeszenarios erfordert aufwendige Arbeiten, um die Eingabe in die entsprechenden Tabellen zu steuern. Änderungen an den Zieltabellen ziehen meistens Änderungen an vielen Prozeduren und Views nach sich – besonders dann, wenn Tabellen umbenannt werden oder neue Spalten zu einer Tabelle hinzukommen.
Eine weitere Herausforderung ergibt sich, wenn es Anpassungen auf unterschiedlichen Systemen gibt, zum Beispiel bei einem Test- und einem Produktivsystem. Dann kann ein Skript nicht einfach zentral entwickelt werden, sondern muss für jedes Zielsystem individuell aufgebaut werden.
Mit dem Application Designer haben wir ein mächtiges Werkzeug zur Erstellung von Anwendungen zur Verfügung, mit dem sich die Erstellung des Modells von der Modellveröffentlichung trennen lässt. Wie in Abbildung 1 zu sehen ist, kann die Entwicklung lokal in einer Entwicklungsumgebung stattfinden, welche die komplette Modelldefinition enthält. Diese Datei wird dann in einem nächsten Schritt gegen die Zieldatenbank geprüft. Danach erstellt der Application Designer ein spezielles Änderungsskript, welches exakt auf die Gegebenheiten der Zieldatenbank angepasst ist.
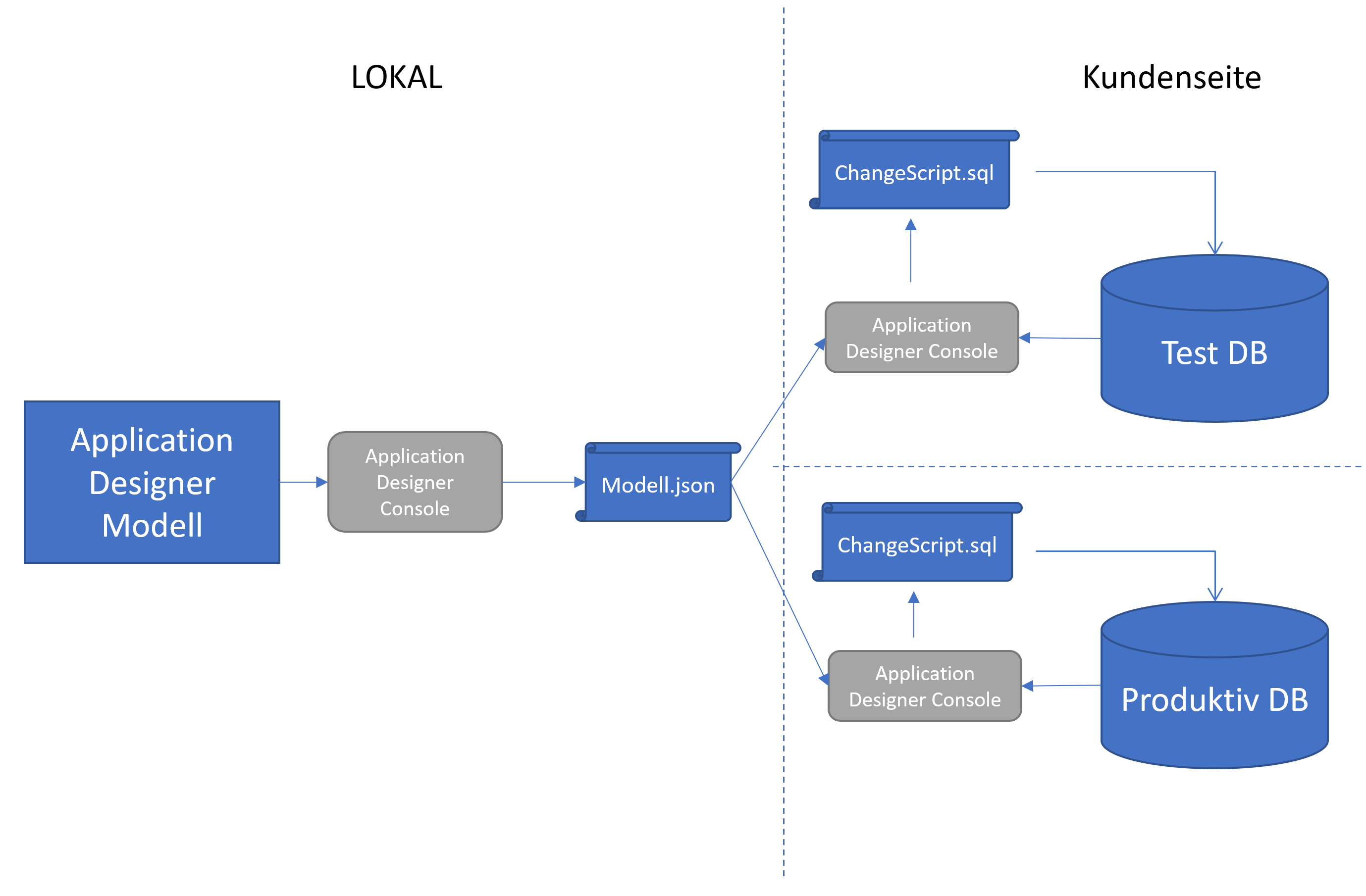
Abb. 1: Schema zum Einsatz des Application Designers bei mehreren Kundensystemen
Zu jeder im Modell definierten Tabelle werden dies, je nach Tabellenart, verschiedene Objekte sein. Bei einer Eingabetabelle werden beispielsweise immer folgende Objekte erstellt:
- eine View
- eine Update-Prozedur
- eine Insert-Prozedur
- eine Delete-Prozedur
Zu jeder Prozedur werden noch jeweils eine Pre- und Post-Prozess-Prozedur erstellt. Bei Pivoteingabetabellen wird neben Pre- und Post-Prozess-Prozedur zusätzlich noch die Eingabeprozedur erstellt.
In jeder dieser Pre- und Post-Prozess-Prozeduren kann der Anwender individuelle Logiken implementieren. Dafür gibt es zwei Wege: entweder gesteuert durch den Application Designer oder im Microsoft SQL Server Management Studio.
Im zweiten Fall wird während der SQL-Skript-Generierung der individuelle Code-Anteil in den Pre- und Post-Prozess-Prozeduren ausgelesen und dann nach den durchgeführten Änderungen wieder eingesetzt. Damit kann man zum Beispiel zu einer bestehenden Tabelle Spalten hinzufügen, ohne auch nur einen Code-Abschnitt manuell neu zu programmieren.
Beispiel: Erstellen eines einfachen JSON-Modells
Im Folgenden verdeutlichen wir diese Schritte an einem kleinen Beispiel. Dafür haben wir drei Datenbanken erstellt
- Blog_ModellDB: Dies ist die Modell-Datenbank, in der die Tabellen und die weiteren Objekte definiert werden.
- Blog_TestDB: Dies ist die Zieldatenbank eines möglichen Testsystems.
- Blog_ProdDB: Dies ist die Zieldatenbank eines möglichen Produktivsystems


Abb. 2: Tabelle „Masterdata“ im Test
Für den Test wurde eine „Masterdata“-Tabelle angelegt (siehe Abb. 2).

Abb. 3: Erzeugen der JSON-Datei über das Menü

Abb. 4: Kommandozeile für das Deployment
Nach dem Erzeugen der JSON-Datei über das Menü im „Target Environment“-Bericht (Abb. 3) und dem Deployment gegen die Zieldatenbank per Kommandozeile (Abb. 4) sind folgende Objekte automatisch erstellt worden:
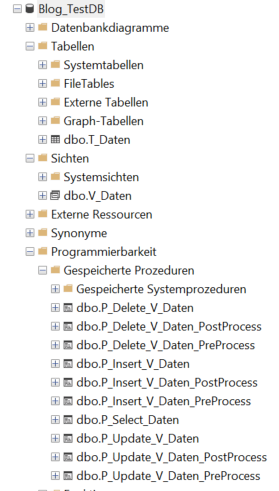
Abb. 5: Automatisch erstellte Objekte durch den Application Designer
Die „-connectionSetID“ gibt dabei die Zielumgebung beim Deployment an. Für die Datenbank „Blog_TestDB“ ist die ID gleich 1 und für die Datenbank „Blog_ProdDB“ ist sie gleich 2.

Abb. 6: Blog_TestDB und Blog_ProdDB

Abb. 7: Kommandozeile für Blog_ProdDB mit der ID 2
Wenn man sich nun beispielhaft die Prozedur „P_Insert_V_Daten_PreProcess“ ansieht, dann erkennt man verschiedene Code-Abschnitte, jeweils unterteilt mit den Kommentaren <Start…> und <End…>. Die Abschnitte, die mit „This section could be adjusted via code editor“ gekennzeichnet sind, könnten nun vom Kunden auf der Zielumgebung mit eigenem Code befüllt werden.
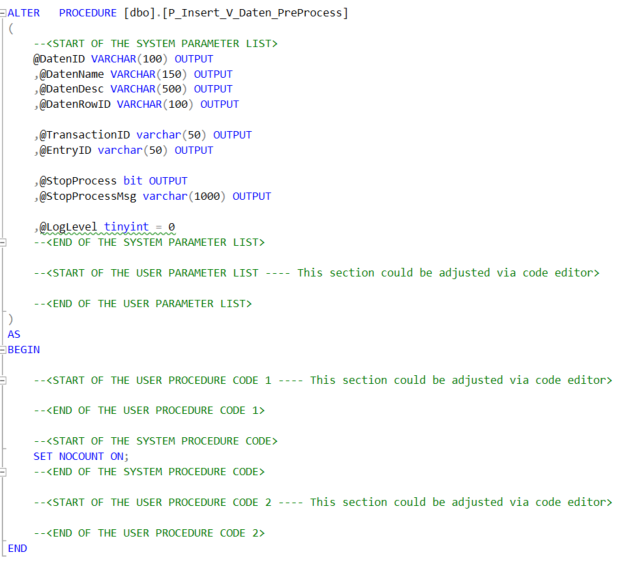
Abb. 8: Prozedur „P_Insert_V_Daten_PreProcess“
Einsatz beim Kunden
Als Beispiel simulieren wir nun eine individuelle Code-Anpassung durch den Kunden, bei der jedem Datensatz auf der Testdatenbank in dem Feld DatenName die Info „Test_“ als Prefix mitgegeben wird.

Auf dem Produktivsystem machen wir das gleiche mit dem Prefix „Prod_“.
In der Tabelle wird dafür eine Spalte „DatenInfo“ innerhalb des Datenmodells hinzugefügt. Ohne die Unterstützung des Application Designers würde in der Praxis dadurch sehr viel Aufwand entstehen: Jede der automatisch erstellten Prozeduren müsste angepasst werden.

Abb. 9: Hinzufügen der neuen Spalte „DatenInfo“
Stattdessen wird vom Application Designer der Code für die neuen Spalte um den User-Code herum gebaut, ohne dass der Anwender beim Deployment sich darum Gedanken machen muss.
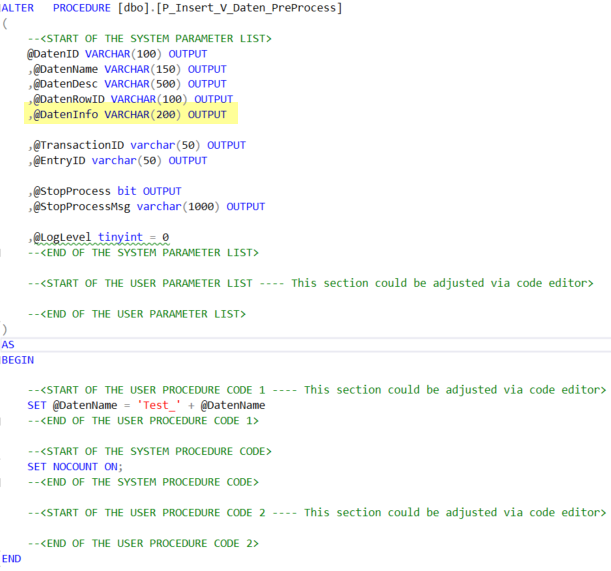
Abb. 10: Automatische Code-Generierung durch den Application Designer
Nach einem Update erkennt man, dass die neue Spalte zwar hinzugefügt, der individuelle Code aber nicht gelöscht oder verändert wurde.
Best Practices
Customizing Source Code
Innerhalb vom Application Designer gibt es die Möglichkeit, individuelle Code-Teile auch im Modell zu definieren. Dadurch lassen sich die individuellen Anpassungen an einer zentralen Stelle pflegen und auf beliebig vielen Systemen einsetzen, ohne in jedem System die Anpassungen manuell durch das Management Studio durchführen zu müssen.
Hierzu gibt es die Berichte „Pre-/PostProcess & View Customizing“ und „Pre-/PostProcess & View Customizing Source Code” (vgl. Abb. 11).


Abb. 11: Pre-/PostProcess & View Customizing und Pre-/PostProcess & View Customizing Source Code
In der resultierenden Prozedur entstehen dadurch neue Unterteilungen mit den definierten Codeabschnitten. Diese Abschnitte werden dann bei jedem Durchlauf des Application Designers neu generiert und mit den Einträgen aus dem Modell überschrieben.
Die resultierenden Prozeduren für die „Blog_TestDB“ und die „Blog_ProdDB“ zeigen, dass die individuellen Codeteile in die Prozeduren eingebaut wurden, ohne die Code-Abschnitte
„SET @DatenName = 'Test_' + @DatenName“und
„SET @DatenName = 'Prod_' + @DatenName“zu verändern.

Abb. 12: Prozedur für die „Blog_TestDB“

Abb. 13: Prozedur für die „Blog_ProdDB“
SQL-Skript-Generierung
Wie in den vorherigen Abschnitten erläutert, wird das resultierende SQL-Skript individuell auf die vorliegende Zieldatenbank und das Modell angepasst. Da sich nach einem Deployment die Zieldatenbank verändert, kann das bedeuten, dass eine zweimalige Ausführung von Application Designer auf der Zieldatenbank nicht in beiden Fällen das gleiche Skript liefern muss.
Um das resultierende SQL-Skript vor der Ausführung prüfen zu können, gibt es den Parameter
„-avoidScriptExecution“. Dieser Parameter erzeugt das resultierende SQL-Skript, verhindert aber dessen Ausführung. Das Skript wird in das Programmverzeichnis des Application Designer abgelegt. Da sich die Datenbank nicht verändert hat, wird eine zweite Ausführung ohne den Parameter zum gleichen Ergebnis kommen.
Wenn eine Skriptausführung gewünscht ist und der Parameter „-avoidScriptExecution“ nicht gesetzt wird, dann empfiehlt es sich immer, den Parameter „-savescript“ zu setzen. Das SQL-Skript wird dadurch gesichert und kann bei einer späteren Fehleranalyse verwendet werden.
Bei der Ausführung innerhalb des „Target Environment“-Berichts werden die Parameter automatisch gesetzt.

Abb. 14: Ausführung des „Target Environment“-Berichts
Allerdings muss dazu in den Settings die Vorauswahl der gewünschten Variante eingestellt werden (vgl. Abb. 15).

Abb. 15: Vorauswahl der gewünschten Variante in den Application Settings
Fazit
Mit dem Application Designer ist es möglich, eine Entwicklung außerhalb der Kundenumgebung durchzuführen und dann beim Kunden gegen die Zieldatenbank zu veröffentlichen. Dadurch eignet sich der Application Designer ideal zur Erstellung von fertigen Lösungsmodellen. Zusätzlich bietet er die Möglichkeit, zwischen zwei Versions-Updates Datenbankobjekte anzupassen, ohne dass dieser Code durch das Update wieder überschrieben wird. Außerdem lassen sich mit dem Application Designer notwendige Entwicklungsarbeiten bei Datenbanksystemen mit Test- und Produktivumgebungen weitgehend vereinheitlichen, ohne dass Tätigkeiten vom Anwender doppelt durchgeführt werden müssen.
