Als „Dilemma“ bezeichnete kürzlich ein Kunde ein häufig auftretendes Problem beim Aggregationstyp LastNonEmpty (LNE), der oft zur Abbildung von Bestandslogiken eingesetzt wird. Ausweglos, wie das Wort Dilemma nahe legt, ist die Problematik jedoch nicht, wie dieser Blogbeitrag zeigen wird.
Problemstellung
Das Problem tritt auf, wenn für eine bestimmte Dimensions-Kombination für eine bestimmte Periode (i. d. R. Tagesebene) ein Datensatz geliefert wird, für die darauffolgenden Perioden jedoch nicht. Das Verhalten tritt auf, wenn der Lagerbestand auf 0 fällt, also kein Bestand mehr vorhanden ist. Anstatt Datensätze mit „0“-Werten zu liefern, wird vollständig darauf verzichtet.
Betrachtet man nun die nächsthöhere Periode-Ebene, also z. B. Monat, dann wird wegen des LNE-Aggregationstyps der Wert des letzten gelieferten Datensatzes angezeigt.

Abbildung 1: Beispiel für das LNE-Problem
Im obigen Beispiel, aus dem Lager unserer Chair AG, werden für den Stuhl Arcade AE 44 ab dem 14.05. keine Datensätze mehr geliefert, weil der Restbestand von 409 Stühlen am 13.05. verkauft wurde. Im Monat Mai gibt es auch keine neuen Lagereingänge für dieses Produkt.
Betrachtet man nun den Monat Mai, so wird für Arcade AE 44 ein Bestand von 409 angezeigt und das, obwohl das Lager eigentlich leer ist. Soweit so richtig, denn der Aggregationstyp LastNonEmpty macht genau das was sein Name sagt: Er sucht nach dem letzten nicht-leeren Wert. Dies widerspricht jedoch unserer Denkweise, dass leere Kombinationen automatisch den Bestand 0 haben.
Richtig verwirrend wird es, wenn man die Summe auf Monatsebene betrachtet. Hier erscheint ein Bestand von 2.074 Stühlen in der Produktgruppe Arcade. Summiert man jedoch die Bestände für den Monat Mai für alle vier Stühle der Produktgruppe auf, so ergäbe sich ein Wert von 2.483 Stühlen. Auf Ebene der Produktgruppe wird also allgemein der Wert des letzten befüllten Datums, hier der 31.5. angezeigt. Für unseren „Problemfall“ Arcade AE 44 wird für diese Aggregation nicht auf den 409-Wert vom 13. Mai zurückgegangen, sondern der Wert 0 genommen.
Die Logik des Aggregationstypen LastNonEmpty ist also durchaus in sich schlüssig, widerspricht jedoch in vielen Fällen der Geschäftslogik.
Grundideen zur Lösung des Problems
Zur Lösung des Problems findet man grundsätzlich zwei verschiedene Ansätze.
Der erste Ansatz sieht eine Lösung im Cube-Skript vor. Dafür wird eine neue Kennzahl im Cube-Skript definiert, auf der dann ermittelt wird, ob eine Zelle leer ist. Ist die Zelle leer, wird eine 0 als Wert angegeben, ansonsten der bekannte Wert übernommen. Wie genau die Umsetzung erfolgt, hängt von der Anforderung ab. In manchen Fällen soll jeweils nur das letzte Datum, auf dem (für irgendeine Dimensionskombination) Werte vorliegen mit den „0“-Werten überschrieben werden, in anderen generell jede leere Zelle etc.
Problematisch an dieser Lösung ist die Auswirkung auf die Performance. Daher ist dieser Lösungsansatz allenfalls für geringe Datenmengen sinnvoll einsetzbar.
Beim zweiten Ansatz werden auf relationaler Ebene künstlich Datensätze erzeugt. Für möglichst alle betroffenen Dimensionskombinationen werden Datensätze angelegt, deren Kennzahlen stets den Wert 0 haben.
Hierbei gibt es verschiedene Strategien:
Die „Holzhammermethode“ ist, über die komplette Dimensionalität das Kreuzprodukt zu bilden und jeweils einen 0-Wert-Datensatz wegzuschreiben. Das führt, je nach Anzahl an Dimensionen und Dimensionselementen, zu einer riesigen Anzahl an Datensätzen.
Etwas elegantere Ansätze prüfen, ob eine Dimensionskombination vom LNE-Problem betroffen ist und fügen dann entsprechend für diese Fälle 0-Wert-Datensätze ein.
Problematisch bei diesen Varianten sind die große Menge von Datensätzen und die Laufzeit beim Er-mitteln und einfügen der 0-Wert-Datensätze.
Um diese beiden Probleme beim Erstellen von 0-Wert-Datensätzen möglichst gering zu halten, wurde der im Folgenden vorgestellte Ansatz entwickelt.
Die in den ersten beiden Abschnitten vorgestellte Grundproblematik und übliche Lösungsansätze wurden in noch ausführlicherer Form bereits in früheren Beiträgen behandelt, auf die an dieser Stelle verwiesen sei:
- Die LastNonEmpty-Aggregation
- Was nicht passt, wird passend gemacht (oder: Wie man mit wenig Aufwand LastNonEmpty doch verwenden kann)
Ein Lösungsansatz
Die Idee des hier vorgestellten Ansatzes ist es, die Behandlung des LNE-Problems im Anschluss des relationalen Transformationsprozesses durchzuführen. Der Vorteil ist, dass dann direkt auf Basis der Faktentabelle entschieden werden kann, welche 0-Wert-Datensätze nötig sind. Es sind also keine Joins nötig, sondern alle benötigten Daten stehen in einer einzigen Tabelle. Das verbessert die Laufzeit deutlich.
Außerdem wird versucht nur die minimal nötig Anzahl an 0-Wert-Datensätzen zu generieren.
Es wird davon ausgegangen, dass es sich um ein mit DeltaMaster Modeler gebautes Modell handelt. Der Ansatz ist jedoch auch auf andere Modelle übertragbar.
Zur Umsetzung dieser Lösung muss die Eigenschaft Partition per src.tab. im DeltaMaster Modeler-Bericht Measure groups auf Yes gestellt sein. Es wird also pro angebundener source table eine eigene T_FACT-Tabelle erzeugt.
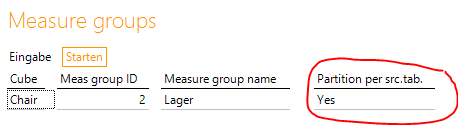
Abbildung 2: Partition per src.tab.-Eigenschaft im DeltaMaster Modeler-Bericht Measure groups
Im nächsten Schritt muss im Bericht Measure group source table eine weitere source table zur betroffenen Measure Group hinzugefügt werden. Als Source table name kann derselbe Eintrag der bereits be-stehenden source table hergenommen werden, wenn die Fill table-Eigenschaft deaktiviert wird. Alternativ kann auch eine eigene FACT-View verwendet werden, die die richtige Struktur bereitstellt, aber keine Datensätze liefert (z. B. über SELECT TOP 0). Ziel ist es, dass eine weitere T_FACT-Tabelle erstellt wird, in die die benötigten LNE-Datensätze geschrieben werden können. Diese wird jedoch nicht im eigentlichen Transform-All befüllt, sondern erst im Anschluss daran.

Abbildung 3: Anlegen der weiteren source table im Bericht Measure group source table
Im Anschluss an diese Anpassungen muss ein Create Snowflake durchgeführt werden, bei dem die neue T_FACT-Tabelle erstellt wird. In unserem Beispiel ist das die Tabelle T_FACT_02_Lager_02.
Nun wird eine Prozedur benötigt, mit deren Hilfe die neu erstellte Tabelle befüllt werden kann.


CREATE PROC [dbo].[P_Lager_LNE] AS
-- letztes Datum finden, für das Werte in der Faktentabelle vorliegen
DECLARE @maxDate AS SMALLDATETIME
SET @maxDate = (SELECT max(TagID) FROM dbo.T_FACT_02_Lager_01);
-- Alle vorhandenen Dimensionskombinationen sortiert auflisten
WITH followingDay AS (
SELECT
[TagID]
,[WertartID]
,[PeriodenansichtID]
,[KumulationID]
,[ProduktID]
, ROW_NUMBER () OVER (
partition by
[WertartID]
,[PeriodenansichtID]
,[KumulationID]
,[ProduktID]
order by [TagID]
) RowNum
FROM T_FACT_02_Lager_01
)
-- LNE-Tabelle befüllen
INSERT INTO
--select * from
dbo.T_FACT_02_Lager_02 With (tablock)
(
[TagID]
,[WertartID]
,[PeriodenansichtID]
,[KumulationID]
,[ProduktID]
,[Lagerbestand]
)
-- LNE-Kombinationen finden
SELECT
DATEADD(DD, 1, fd.TagID) DayID
,fd.[WertartID]
,fd.[PeriodenansichtID]
,fd.[KumulationID]
,fd.[ProduktID]
,0 [Lagerbestand]
-- select count(*)
from followingDay fd
LEFT JOIN followingDay fd2 ON
fd.[WertartID] = fd2.[WertartID]
AND fd.[PeriodenansichtID] = fd2.[PeriodenansichtID]
AND fd.[KumulationID] = fd2.[KumulationID]
AND fd.[ProduktID] = fd2.[ProduktID]
AND fd.RowNum + 1 = fd2.RowNum
WHERE
fd.TagID < @maxDate
AND (
DATEDIFF(DAY, fd.TagID, fd2.TagID) > 1
OR
(fd2.TagID IS NULL)
)
GODie Logik dieser Prozedur:
-
- Zunächst wird das letzte Datum ermittelt, für das Datensätze in der Faktentabelle vorhanden sind.
- Die vorhandenen Dimensionskombinationen der Faktentabelle werden mithilfe der partition by Funktion sortiert. Es wird nach den Dimensionskombinationen gruppiert und die einzelnen Datensätze einer Kombination mithilfe eines order by Statements über die TagID-Spalte sortiert, wobei eine Zeilennummer innerhalb der Partitionierung zugewiesen wird.
- Abbildung 4 zeigt das Ergebnis dieser Sortierung, anhand unseres LNE-Beispiels aus Abbildung 1. Man sieht, dass der „Nachfolger“ für den Datensatz vom 13.05.2016 für die Kombination Wertart = I, Periodenansicht = 1, Kumulation = 1 und Produkt = P1 ein Datensatz vom 1.7.2016 ist. Das heißt, der Bestand muss am 14.5.2016 auf 0 gefallen sein.
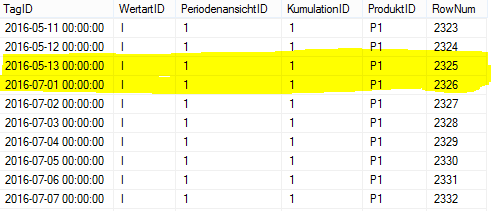
Abbildung 4: Ergebnis der Sortierung nach Dimensionskombination
Das Ergebnis dieser Sortierung wird in einem WITH-Statement festgehalten.
Diese sehr schnelle Möglichkeit zum Sortieren von Datensätzen wurde im Blogbeitrag T-SQL schnelle Nachfolgersuche (http://crew.bissantz.de/t-sql-schnelle-nachfolgersuche-2) vorgestellt. In unserem Beispiel benötigt dieser Sortiervorgang weniger als eine Sekunde.
Zum Vergleich: der zweite vorgestellte Ansatz zur Nachfolgersuche im Blogbeitrag T-SQL schnelle Nachfolgersuche benötigt auf demselben Rechner für die gleiche Aufgabe 2 Minuten! - Für den 14.05. soll von der Prozedur jetzt ein 0-Wert-Datensatz mit dieser Dimensionskombination erstellt werden. Dieser wird dann in die neue T_FACT-Tabelle eingefügt.
Um solche Daten zu ermitteln, wird das Ergebnis des WITH-Statements mit sich selbst über alle Dimensionen „gejoint“. Zusätzlich wird der Join über die RowNum-Spalte gebildet, so dass die RowNum + 1 des aktuell betrachteten Datensatzes identisch mit der RowNum des „gejointen“ Datensatzes ist.
Zusätzlich sind in der WHERE-Klausel Bedingungen auf der TagID-Spalte.
Zum einen muss der Tag kleiner als das aktuelle Datum sein. Diese Anforderung steht für sich, denn für Datensätze die bereits das größte Datum haben, kann kein Nachfolger gefunden wer-den und somit kann das LNE-Problem auch nicht auftreten.
Zum anderen muss der Abstand des betrachteten Datensatzes zu seinem Nachfolger größer als ein Tag sein oder der Datensatz darf keinen Nachfolger haben.
Führt man diese Prozedur aus, dann wird in unserem Beispiel genau ein Datensatz in die neue T_FACT-Tabelle eingefügt. Es ist der benötigte Datensatz für den 14.05.2016.
![]()
Abbildung 5: Ergebnis nach Ausführung der Prozedur
Prozessiert man jetzt die OLAP-Datenbank, sieht das Ergebnis in unserem Beispiel-Bericht vom Anfang wie folgt aus:

Abbildung 6: Ergebnis für das LNE-Beispiel nach Ausführung der Prozedur und Verarbeitung der OLAP-Datenbank
Abschließend sollte diese Prozedur noch am Ende der Prozedur P_Transform_All mit aufgenommen werden.
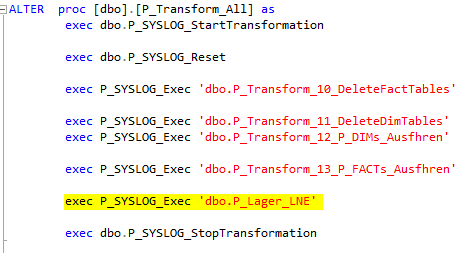
Abbildung 7: Aufnahme der Prozedur in P_Transform_All
Fazit
Die vorgestellte Technik zur Lösung des LNE-Problems schafft es die notwendigen 0-Werte-Datensätze stark zu minimieren. Gleichzeitig wird durch die Nutzung von partition by und den direkten Zugriff auf die zuvor befüllte T_FACT-Tabelle für eine gute Performance gesorgt.
Beides gilt auch bei großen Datenmengen.
Bedenken, dass hier noch im Anschluss der Transformation in die Faktentabellen eingegriffen wird, sind unbegründet, weil die Prozedur nur Datensätze hinzufügen kann, wenn auch in der eigentlichen Fakten-Tabelle Datensätze enthalten sind. Tritt beispielsweise während der Transformation eine Fremdschlüsselverletzung auf, die dazu führt, dass die Faktentabelle nicht befüllt ist, so wird die LNE-Prozedur eben auf dieser leeren Tabelle ausgeführt und liefert ebenfalls keine Datensätze zurück.
Ein weiterer schöner Nebeneffekt ist, dass durch Einfügen der LNE-Datensätze in eine eigene T_FACT-Tabelle, diese Datensätze nicht im SQL-Durchgriff stören. Voraussetzung ist, dass die Tabelle nicht mit in eine entsprechende V_SEC-View aufgenommen wird.
