Wer häufig mit SQL arbeitet, kennt sicher die seit Microsoft SQL Server Version 2012 verfügbaren Window Functions. Mit ihnen können schnell und unkompliziert Aggregationen über einen bestimmten Datenbereich ermittelt werden oder auch Vorgänger und Nachfolger. Die allgemeine Syntax dazu ist vielen bekannt. Dieser Beitrag zeigt, wie sie mit den dazugehörigen Ausdrücken ROWS oder RANGE weiter ergänzt werden kann, wie der Default lautet, wenn weder ROWS noch RANGE explizit angegeben werden und wozu man ROWS bzw. RANGE einsetzen kann.
Die Over-Klausel zur Definition einer Fensterfunktion in Microsoft SQL Server lautet OVER(PARTITION BY … ORDER BY…). PARTITION BY unterteilt ein Abfrageergebnis in Partitionen. ORDER BY definiert die logische Reihenfolge der Zeilen im Abfrageergebnis innerhalb jeder Partition.
Ein Beispiel aus unseren SQL-Schulungen, bei denen wir mit der Datenbank „Foodmart“ arbeiten: Mit dem folgendem SQL-Statement erhält man auf Datenbank Foodmart für jedes Produkt (product_name) das Nettogewicht (net_weight) und mit dem LAG-Ausdruck pro Product_Class den jeweiligen direkten Vorgänger des Nettogewichts.
SELECT
pr.product_name
, pr.net_weight
, LAG(pr.net_weight,1,0) OVER (PARTITION BY pr.product_class_id ORDER BY pr.net_weight) AS Vorgaenger
FROM dbo.product prROWS versus RANGE
Die Argumente ROWS bzw. RANGE grenzen die Zeilen innerhalb einer Partition weiter ein, indem sie Start- und Endpunkte innerhalb der Partition definieren. Ein ORDER BY ist dabei immer erforderlich. Das folgende kleine Beispiel verdeutlicht die Unterschiede zwischen ROWS und RANGE.
Wir erstellen eine Tabelle mit einer Zeilennummer und einer beliebigen Zahl als Wert dazu.
CREATE TABLE T_Daten (Zeile int, Wert decimal(10,2))
GO
INSERT INTO T_Daten
Values (1,1.0), (2,3.0), (3,4.0), (4,2.0), (5,6.0)
Nun lassen wir folgendes SQL-Statement zur Abfrage im Default (RANGE) laufen:
SELECT
Zeile
, Wert
, AVG(Wert) OVER(ORDER BY Zeile) AS Mittelwert
FROM T_DatenWir erhalten die in Abbildung 1 dargestellte Tabelle.
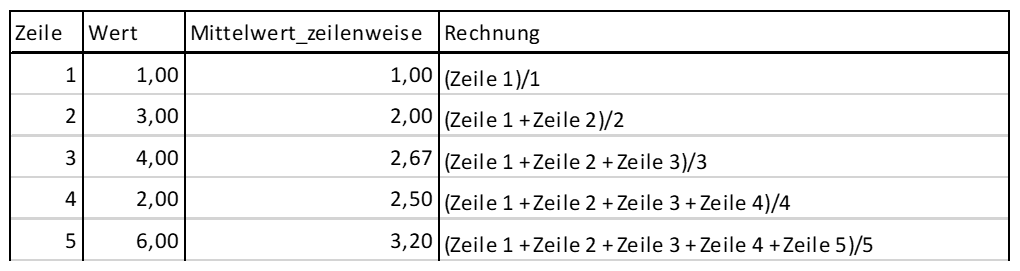
Abb. 1: Ergebnis und Rechnung Abfrage Default (RANGE)
Wie der Mittelwert in diesem Beispiel berechnet wird, ist in der Spalte ‚Rechnung‘ zusätzlich aufgeführt.
Nun ändern wir die SQL-Abfrage ab und fügen eine Einschränkung mit ROWS hinzu, die die Berechnung des Mittelwertes auf bestimmte Zeilen einschränkt:
SELECT
Zeile
, Wert
, AVG(Wert) OVER(ORDER BY Zeile ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING) AS Mittelwert_3_Werte
FROM T_DatenDas Ergebnis sehen wir hier:

Abb. 2: Ergebnis und Berechnung der Abfrage mit ROWS
Auch hier wurde eine Spalte ‚Rechnung‘ hinzugefügt, um zu verdeutlichen, wie der Mittelwert in dieser Abfrage berechnet wird.
Betrachten wir die jeweiligen SQL-Abfragen und deren Ergebnisse einmal genauer: Die erste Abfrage ermittelt den Mittelwert aus den Werten aller vorhergehenden Zeilen inklusive der aktuellen Zeile. Die zweite Abfrage ermittelt den Mittelwert aus jeweils 3 Werten – Vorgänger, aktuelle Zahl und Nachfolger – und teilt das jeweilige Ergebnis durch die Anzahl der verwendeten Zeilen.
Warum ist das so?
Der Default, also ohne Definition von ROWS– oder RANGE-Einschränkungen, ist immer RANGE UNBOUNDED PRECEDING AND CURRENT ROW. Damit werden alle vorhergehenden Zeilen einschließlich der aktuellen Zeile in der Partition zur Berechnung herangezogen. ROWS hingegen schränkt die Berechnung auf bestimmte Zeilen ein, die in der BETWEEN folgenden Anweisung angegeben sind, wobei sich die Einschränkung immer auf das im ORDER BY angegebenen Datenfeld bezieht.
Nun könnte man meinen, dass der Default RANGE UNBOUNDED PRECEDING AND CURRENT ROW (gleichbedeutend mit RANGE UNBOUNDED PRECEDING) und ROWS UNBOUNDED PRECEDING das gleiche Ergebnis liefern. Solange wir keine doppelten Zeilennummern in unserer Tabelle haben, stimmt das auch. Das können wir überprüfen, indem wir folgende SQL-Abfragen parallel ausführen:
SELECT
Zeile
, Wert
, AVG(Wert) OVER(ORDER BY Zeile) AS Mittelwert_zeilenweise
FROM T_DatenSELECT
Zeile
, Wert
, AVG(Wert) OVER(ORDER BY Zeile RANGE UNBOUNDED PRECEDING) AS Mittelwert
FROM T_DatenSELECT
Zeile
, Wert
, AVG(Wert) OVER(ORDER BY Zeile ROWS UNBOUNDED PRECEDING) AS Mittelwert
FROM T_DatenAlle drei Abfragen erzeugen das Ergebnis, welches in Abbildung 1 gezeigt wird. Das ändert sich, sobald wir z. B. folgende Zeilen in die Tabelle T_Daten einfügen:
INSERT INTO T_Daten
Values (2,4.0), (4,10.0)Die Abfrage lautet:
SELECT * FROM T_Daten
ORDER BY ZeileSie erzeugt die in Abbildung 3 dargestellte Tabelle.
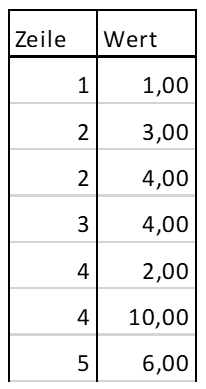
Abb. 3: Select-Ergebnis Tabelle T_Daten
Die Zeilen sind nicht mehr eindeutig. Wir starten unsere Abfragen erneut.
SELECT
Zeile
, Wert
, AVG(Wert) OVER(ORDER BY Zeile ROWS UNBOUNDED PRECEDING) AS Mittelwert_zeilenweise
FROM T_DatenSELECT
Zeile
, Wert
, AVG(Wert) OVER(ORDER BY Zeile) AS Mittelwert_zeilenweise
FROM T_DatenDas Ergebnis für ROWS UNBOUNDED PRECEDING sieht folgendermaßen aus:
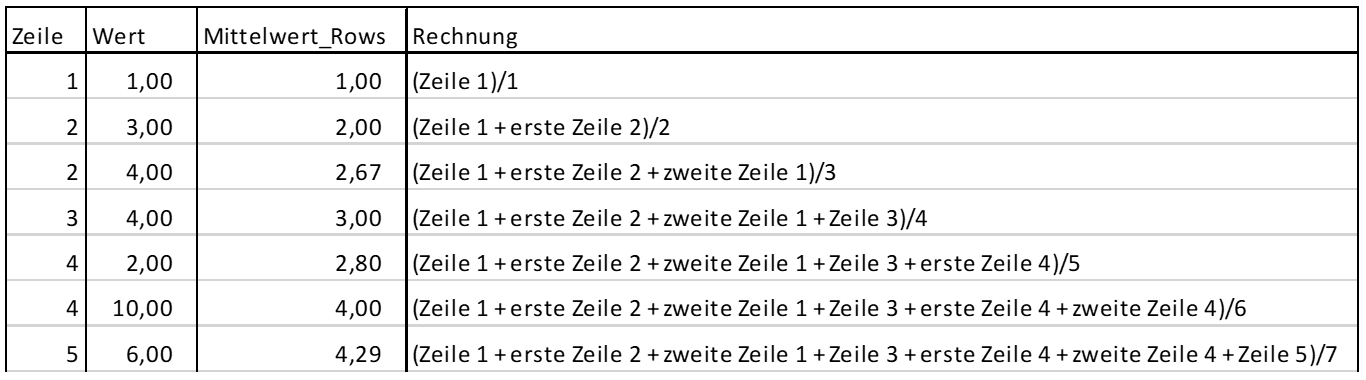
Abb. 4: Ergebnis und Rechnung zur Abfrage ‚Rows Unbounded‘
Für die Abfrage ohne Angabe einer Einschränkung mit ROWS oder RANGE, was gleichbedeutend mit RANGE UNBOUNDED PRECEDING AND CURRENT ROW ist, ergibt sich folgende Tabelle:
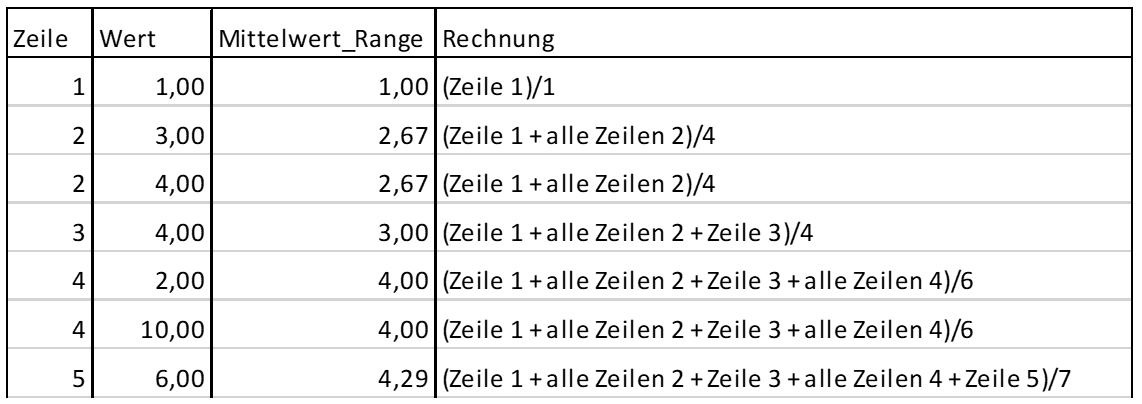
Abb. 5: Ergebnis und Rechnung Abfrage Default (‚Range‘)
Die in der Spalte ‚Rechnung‘ dargestellte Berechnung der jeweiligen Ergebnisse zeigt, dass ROWS auch dann zeilenweise arbeitet, wenn der Inhalt in der Zeile gleich ist, RANGE hingegen fasst diese Zeilen zusammen. Verwendet man die Default-Einstellung, muss man sich also darüber im Klaren sein, dass damit RANGE UNBOUNDED PRECEDING AND CURRENT ROW eingesetzt wird und Zeilen gleichen Inhalts immer gemeinsam betrachtet werden. Wofür kann man das Argument ROWS nun sinnvoll einsetzen?
Anwendungsbeispiel
In einer Abfrage soll der Gesamtumsatz über alle Jahre und der Umsatz der Vorjahre ermittelt werden. Um dies zu demonstrieren, erweitern wir unsere kleine Beispieltabelle um die Spalte ‚Jahr‘ und vervielfachen die Einträge für jedes Jahr.
ALTER TABLE T_Daten ADD Jahr int
GO
UPDATE T_Daten
SET Jahr = 2019
GO
INSERT INTO T_Daten (Zeile, Wert, Jahr)
SELECT
Zeile
, Wert
, Jahr+1
FROM T_Daten
WHERE Jahr = 2019
INSERT INTO T_Daten (Zeile, Wert, Jahr)
SELECT
Zeile
, Wert
, Jahr+2
FROM T_Daten
WHERE Jahr = 2019Die SQL-Abfrage, um sowohl die Summe der Werte über alle Jahre als auch die Summe der Werte der Vorjahre zu berechnen, könnte wie folgt aussehen:
SELECT
b.Jahr
, b.Zeile
, b.Wert
, SUM(Wert) OVER (PARTITION BY b.Zeile ORDER BY b.Jahr ROWS BETWEEN UNBOUNDED PRECEDING AND 1 PRECED-ING ) AS Umsatz_Vorjahre
, SUM(Wert) OVER (PARTITION BY b.Zeile ORDER BY b.Jahr) AS Umsatz_alleJahre
FROM T_Daten b
ORDER BY b.Zeile, b.JahrDie Einschränkung ROWS BETWEEN UNBOUNDED PRECEDING AND 1 PRECEDING begrenzt die Berechnung der Summe auf alle vorhergehenden Werte bis zum vorletzten Wert. Dabei bezieht sich das PRECEDING auf das im ORDER BY verwendete Jahr. Die Summe der Werte wird im Beispiel als Umsatz bezeichnet.
Wir erhalten folgendes Ergebnis:
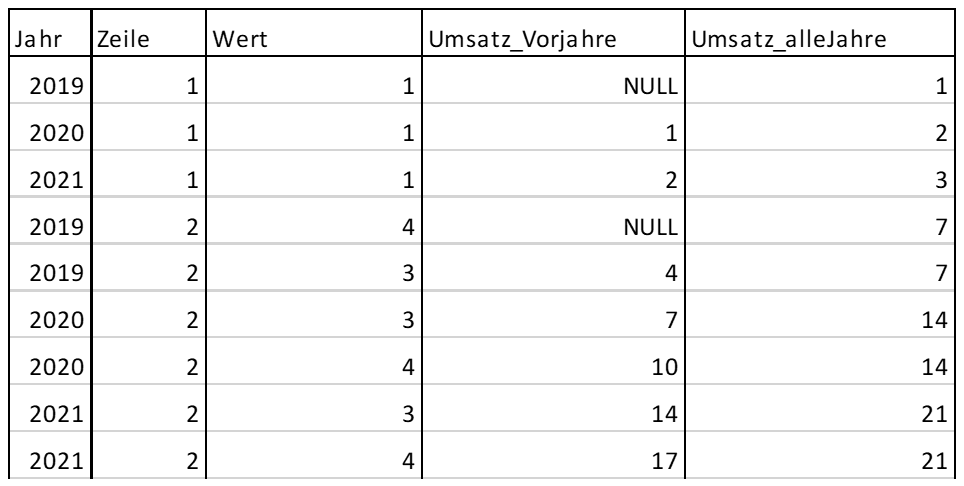
Abb. 6: Ausschnitt aus dem Ergebnis der Umsatzermittlung
Betrachten wir die Zeile 1 in Abbildung 6, sieht alles passend aus. In der Tabelle T_Daten gibt es für die Zeilen 2 und 4 aber mehr als einen Eintrag (diese Einträge haben wir, wie oben beschrieben, selbst eingefügt, um die Funktionsweise von ROWS zu demonstrieren).
Da ROWS, wie bereits gezeigt, zeilenweise arbeitet und die Daten der Zeilen 2 nicht zusammenfasst, erhalten wir mit unserer Abfrage für diese Zeilen nicht das gewünschte Ergebnis. Eine RANGE-Einschränkung, die nur bis zur vorletzten Zeile arbeitet, gibt es nicht. Daher müssen wir, wenn die Zeilen nicht eindeutig sind, hier selbst eingreifen. Das können wir beispielsweise, indem wir über eine vorhergehende Summierung die Zeilen wieder eindeutig machen:
WITH cte_Jahressumme
AS
(
SELECT
Jahr
, Zeile
, SUM(Wert) AS Wert
FROM T_Daten
GROUP BY Jahr, Zeile
)
SELECT
b.Jahr
, b.Zeile
, b.Wert
, SUM(Wert) OVER (PARTITION BY b.Zeile ORDER BY b.Jahr ROWS BETWEEN UNBOUNDED PRECEDING AND 1 PRECEDING ) AS Umsatz_Vorjahre
, SUM(Wert) OVER (PARTITION BY b.Zeile ORDER BY b.Jahr) AS Umsatz_alleJahre
FROM cte_Jahressumme b
ORDER BY b.Zeile, b.JahrNun erhalten wir das gewünschte Ergebnis:
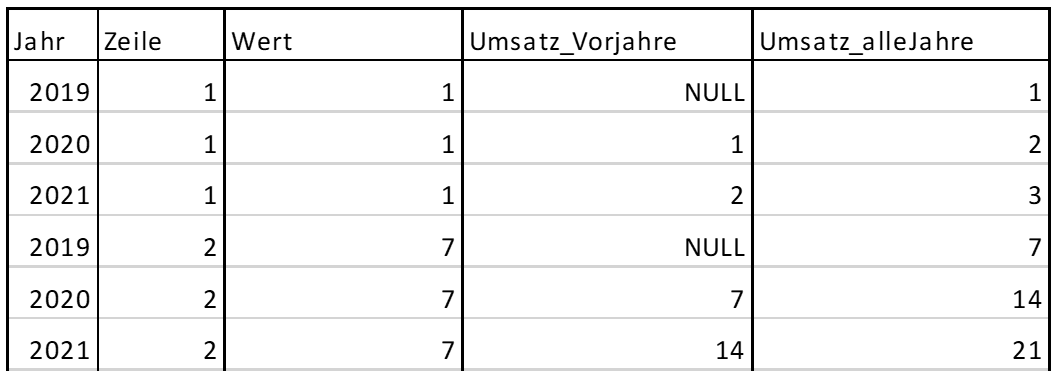
Abbildung 7: Ergebnis aus Umsatzermittlung mit vorhergehender Summierung pro Jahr und Zeile
Fazit
Wer Aggregationen mit der OVER-Klausel verwendet, sollte sich über die Wirkung der verwendeten Einschränkungen mit ROWS bzw. RANGE bewusst sein. Wird explizit keine Einschränkung gesetzt, wird als Default immer RANGE UNBOUNDED PRECEDING AND CURRENT ROW verwendet. Das bedeutet, dass alle vorhergehenden Werte bis zum aktuellen Wert des im ORDER BY verwendeten Datenfelds in die Aggregation einbezogen werden.
Mit ROWS kann die Berechnung gezielt auf bestimmte Zeilen eingeschränkt werden, womit z. B. die Ermittlung einer Summe über die Vorjahre möglich wird. Dabei muss man lediglich beachten, dass mit ROWS die tatsächlichen Datenzeilen gemeint sind auch wenn die betroffenen Felder den gleichen Inhalt aufweisen.
