Das sagenumwobene Flag „Fast = TRUE“ hat sich wohl jeder IT-ler in seinem Leben schon einmal gewünscht. Microsoft verspricht spätestens ab SQL-Server-Version 2005 eine Option, die diesem Flag schon ziemlich nahekommt. Die Rede ist hier von der Möglichkeit, Tabellen zu partitionieren. Dies soll deutliche Performancegewinne insbesondere beim Laden und Verwalten von umfangreichen Faktendaten ermöglichen. Der Clou daran ist, dass einzelne Tabellenpartitionen einer Faktentabelle einfach gegen eine strukturidentische Deltatabelle ausgetauscht werden können. Bei dieser Operation werden lediglich Metadaten verändert, was nur einen Bruchteil der Zeit eines echten Datenimports benötigen soll.
Die Restriktionen, das allgemeine Vorgehen sowie die tatsächlichen Performancegewinne beim Partitionieren werden in Teil 1 und 2 des nachfolgenden Artikels betrachtet.
Was bringt die Partitionierung?
Partitionierte Tabellen lohnen immer dann, wenn es um die „Bewirtschaftung“ von großen Datentabellen geht. Groß ist dabei ein wachsweicher Begriff. Wir können vereinfachend annehmen, dass eine Tabelle als „groß“ zu betrachten ist, sobald die Leistung beim Laden und Abfragen nicht mehr zufriedenstellend ist.
Performancezugewinne sind durch mehrere Faktoren zu erwarten. Durch das Aufteilen der Tabelle in kleinere „Häppchen“ kann zum einen der Lade- und Löschprozess erheblich beschleunigt werden. Aber auch die lesenden Zugriffe auf die Tabelle können optimiert werden.
Beim Laden und Löschen kommt die Optimierung insbesondere aus der Tatsache, dass die zu löschenden oder ladenden Daten in einer separaten (kleinen) Tabelle verwaltet werden können und nach fertiger Aufbereitung einfach und schnell in die Faktentabelle überführt werden können.
Bei den lesenden Zugriffen rührt eine Optimierung aus der besseren Nutzung der Hardware-Ressourcen, da der Server bei einer Abfrage zielgerichtet in die richtigen Partitionen „greifen“ kann. Weiterhin können Abfragen durch die Nutzung mehrerer Prozessoren parallelisiert werden, sofern die Partitionen auch in jeweils eine eigene SQL-Server-Dateigruppe (mit jeweils einer Datendatei) abgelegt werden. Auf diesen Schritt wird im weiteren Artikel aus Gründen der Einfachheit verzichtet. Die Details können im Microsoft Devloper Network (MSDN) nachgelesen werden.
Vertikal oder horizontal?
Wie das Wort Partitionierung bereits zum Ausdruck bringt, geht es darum, die große Tabelle in kleinere Blöcke aufzuteilen. Die Theorie unterscheidet hierbei eine vertikale und eine horizontale Partitionierung. Diese Begriffe kann man einigermaßen wörtlich nehmen, wenn man sich eine Tabelle vorstellt:
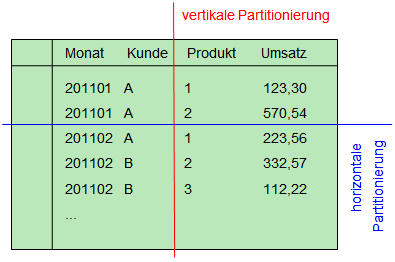
Bei einer vertikalen Partitionierung ist die Idee, die Tabellenspalten nach „häufig genutzt“ und „weniger häufig genutzt“ zu trennen und in getrennte Tabellen auszugliedern. Die häufig genutzten Daten können dann direkt in kleineren Abfragen verarbeitet werden. Die Gesamttabelle erhält man durch Vereinigung der beiden Basistabellen in einer View. Dieser Fall ist für OLAP-Systeme eher irrelevant und wird daher auch nicht weiter betrachtet.
Die horizontale Partitionierung kann in Business-Intelligence-Systemen schon wesentlich häufiger zum Einsatz gebracht werden. Hierbei werden die Daten nach Inhalten aufgeteilt, beispielsweise nach Monaten (wie in der obigen Darstellung angedeutet). Ein typisches Szenario könnte sein, dass in einem Ladeprozess die Umsatzdaten des letzten Monats in eine Faktentabelle geladen werden. Um die Datenmenge klein zu halten, soll bei Erreichen eines neuen Monats der älteste Monat aus der Faktentabelle entfernt werden. Dieser Anwendungsfall dürfte jedem BI-Architekten bekannt vorkommen. Die Tabelle würde in dem Fall über Monate partitioniert werden. Eine Partition würde je nach Design dann beispielsweise immer nur genau einen Monat enthalten. Während des Ladeprozesses würden dann einzelne Monatspartitionen ausgetauscht werden. Die schematische Darstellung verdeutlicht eine mögliche Tabellenpartitionierung:
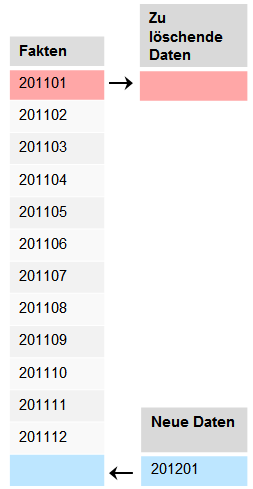
Wichtig beim Anwenden der SQL-Server-seitigen, horizontalen Partitionierung ist, dass nur eine Spalte das Partitionierungskriterium enthalten darf. Eine Partitionierung über eine ganze Spaltengruppe ist nicht möglich!
Horizontal! Linksrum oder rechtsrum?
Hat man sich dazu durchgerungen, den mühsamen Weg der Partitionierung einzuschlagen, stellt sich als nächste die Frage wie partitioniert werden soll? Entscheidend für das „Schneiden“ der Partitionen ist entweder die Nutzung der einzelnen Blöcke (sehr alte historische Daten werden beispielsweise weniger genutzt als aktuelle Daten) oder die Ladegranularität (jede Nacht einen vollen Monat laden). Da wir im OLAP-System selten direkt auf die relationalen Daten zugreifen, soll in unserem Beispiel die Ladegranularität entscheidend sein.
Wenn das Kriterium für die Partitionierung festgelegt ist, muss entschieden werden, auf welche Art und Weise partitioniert werden soll. Wenn wir wie hier mit dem Monat als Partitionierungsschlüssel arbeiten, kommt eine Bereichspartition zum Einsatz, welche links- oder rechts-basiert definiert werden kann. Das bedeutet, dass man nicht die exakten Von-Bis-Grenzen für eine Partition angibt, sondern jeweils die obere oder untere Grenze einer Partition. Die Grenzen spannen einen Datenbereich auf, daher der Name „Bereichspartition“. Im Gegensatz dazu gibt es noch eine Listendefinition in der explizit genannte Elemente für die Partitionierung herangezogen werden. Diese wird allerdings primär bei textuellen Datentypen verwendet und bildet eher die Ausnahme. Daher beschränken wir uns im vorliegenden Artikel auf die Bereichspartition. Ob man den Bereich links- oder rechtsherum definiert, hängt vom jeweiligen Anwendungsfall und den persönlichen Vorlieben ab.
Da die Grenzdefinition mit das Verwirrendste bei der Arbeit mit Partitionen ist, schauen wir uns hier ein ausführliches Beispiel an. Nehmen wir an, wir haben eine Tabelle mit Daten von Januar 2011 bis Dezember 2011 (ja, wir können für den Moment in die Zukunft schauen…) und wollen diese in zwei Partitionen unterteilen. Die Grenze soll die Jahresmitte darstellen.
Wählt man die links-basierte Variante so muss man die oberste Grenze für die erste Partition definieren. Das bedeutet also bei der Variante LEFT:
- die erste Partition enthält alle Daten <= 201106,
- die zweite Partition enthält alle Daten > 201106
Codeausschnitt:
RANGE LEFT FOR VALUES (201106)
Mit der Variante RIGHT sähe es folgendermaßen aus:
- die erste Partition enthält alle Daten < 201107
- die zweite Partition enthält alle Daten >= 201107
Codeausschnitt:
RANGE RIGHT FOR VALUES (201107)
Bei dem rechts-basierten Weg würde man also die Grenze einen Monat weiter rechts definieren. Entscheidend ist an welcher Stelle das Kleiner-Gleich-Zeichen verwendet wird.
Das Ergebnis der Definition sehen wir hier noch einmal schematisch:
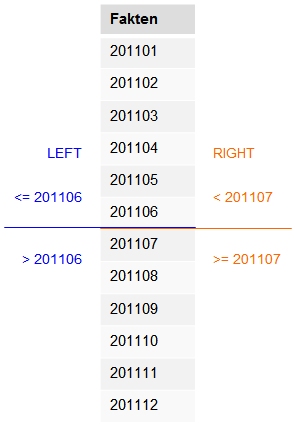
Was aus dem kleinen Codeausschnitt und dem Beispiel bereits hervorgeht, ist ein wichtiges Grundprinzip der Tabellenpartitionierung. Obwohl wir nur eine Grenze angeben, werden zwei Partitionen erstellt. Das heißt, wenn man beispielsweise eine Partition pro Monat bei einer Tabelle mit zwölf Monaten erzeugen möchte, muss man lediglich elf Partitionsgrenzen definieren.
Weiterhin muss man sich bewusst sein, dass immer eine Restklasse existiert. Das bedeutet, dass selbst wenn die Grenze mit dem maximal vorhandenen Monat definiert wird, auch eine Partition für alle Folgemonate generiert wird. Dadurch wird gewährleistet, dass keine Daten im „Partitionsnirvana“ hängen bleiben und wirklich jeder Datensatz einer Partition zugeordnet wird.
Horizontal, linksrum! Und weiter?
Die Arbeit mit partitionierten Tabellen kann in zwei Hauptteile unterschieden werden. Die Einrichtung der Tabellenpartitionierung sowie die Änderung von Tabellenpartitionen. Um keine abendfüllende Lektüre zu erzeugen beschränken wir uns im ersten Teil auf die Einrichtung der Partitionierung. Im zweiten Teil schauen wir uns dann die Partitionen in Action an.
Um eine Partitionierung einzurichten, muss man drei Schritte in der korrekten Reihenfolge durchführen:
- Erstellung der Partitionierungsfunktion (mit Definition der Blockgrenzen)
- Erstellung eines Partitionsschemas (mit Zuordnung der Partitionen zu(r) Dateigruppe(n))
- Anwenden des Partitionsschemas auf die Tabelle(n)
Erstellung der Partitionierungsfunktion
Die Partitionierungsfunktion enthält die eigentliche Logik der Partitionsblöcke. Hier werden mittels LEFT oder RIGHT Argument die Blockgrenzen gesetzt und diese später auf die Tabellen angewendet.
Bleiben wir in unserem Beispiel bei der Faktentabelle mit Daten von Januar 2011 bis Dezember 2011. Unsere Tabelle soll T_FACT_01_Umsatz heißen. Diese Tabelle wollen wir nach Monaten partitionieren, d.h. pro Monat eine Partition. Wir verwenden die links-basierte Schreibweise. Weiterhin muss der Partitionierungsfunktion ein Funktionsname sowie der Datentyp der Partitionierungsspalte (in unserem Fall also INT) mitgegeben werden.
Die Syntax für die Erstellung der Funktion sieht wie folgt aus:
--Create Partiton Function -- user-defined-name CREATE PARTITION FUNCTION PF_APP_UmsatzMonthRange(int) -- int=datatype of month column AS -- LEFT = left-based RANGE LEFT FOR VALUES ( -- Block borders 201101, -- <= 201101 (<= due to LEFT) 201102, -- > 201101 AND <= 201102 201103, -- > 201102 AND <= 201103 201104, -- ... 201105, 201106, 201107, 201108, 201109, 201110, 201111 -- > 201110 AND <= 201111 -- 12th partition > 201111 (11 ranges create 12 partitions!!) ) GO
Wichtig für den Aufbau eines wiederholbaren Scripts ist, dass die Partitionierungsfunktionen nicht (!) in den sys.objects enthalten sind und auch keine ObjectID haben. Um zu prüfen ob die Partitionierungsfunktion bereits existiert, muss die Systemtabelle „sys.partition_functions“ verwendet werden. Der zugehörige Löschbefehl sieht also wie folgt aus:
--Delete partition function IF EXISTS(SELECT * FROM sys.partition_functions WHERE [name] = 'PF_APP_UmsatzMonthRange') BEGIN DROP PARTITION FUNCTION PF_APP_UmsatzMonthRange END GO
Wenn später Partitionen in den Tabellen verändert werden, wird die erzeugte Partitionierungsfunktion entsprechend mit geändert, um beispielsweise neue Klassengrenzen abzubilden (erster Monat wird gelöscht, ein neuer hinzugefügt).
Erstellung des Partitionierungsschemas
Ist die Partitionierungsfunktion erfolgreich erstellt, kommt das zugehörige Partitionierungsschema an die Reihe. Das Partitionsschema ordnet die erstellten Partitionen aus der zugehörigen Funktion den entsprechenden Dateigruppen zu. Für eine optimale Performance sollte jede Partition in einer eigenen Dateigruppe liegen. Die Operationen auf einer so partitionierten Tabelle können optimal parallelisiert werden. Eine weitere Überlegung ist, die Dateigruppen auch jeweils auf eigene Speichermedien auszulagern. Wie bereits angekündigt vereinfachen wir in diesem Blogbeitrag die Vorgehensweise und verzichten auf eine Aufteilung der Partitionen nach Dateigruppen.
Damit vereinfacht sich auch die Syntax der Schemaerstellung deutlich, wie nachfolgendes Beispiel zeigt:
--Create Partition Scheme CREATE PARTITION SCHEME PS_APP_UmsatzMonthRange AS PARTITION PF_APP_UmsatzMonthRange –-Name of partition function --ALL = Applies for all partitions ALL TO ([PRIMARY]) –-= PRIMARY-Filegroup GO
Details zur Erstellung von Partitionsschemata auf mehreren Dateigruppen können der MSDN-Dokumentation entnommen werden.
Auch das erzeugte Schema taucht nicht in den Systemobjekten auf. Hierfür gibt es ebenfalls eine eigene Systemtabelle namens „sys.partition_schemes“. Damit muss der Löschbefehl folgendermaßen erzeugt werden:
--Delete partition schema IF EXISTS(SELECT * FROM sys.partition_schemes WHERE [name] = 'PS_APP_UmsatzMonthRange') BEGIN DROP PARTITION SCHEME PS_APP_UmsatzMonthRange END GO
Wichtig: Die Partitionsfunktion kann nicht gelöscht werden, solange ein Partitionsschema auf sie verweist. Das Löschen muss daher in umgekehrter Reihenfolge erfolgen.
Anwenden des Partitionsschemas auf die Tabelle(n)
Jetzt fehlt lediglich noch das Wissen, wie die Partitionierung konkret auf die Faktentabelle angewendet werden kann. Dies ist mit die einfachste Übung, da das CREATE TABLE Statement lediglich um eine Zeile erweitert werden muss, in der das zu verwendende Partitionsschema sowie die Spalte, über welche partitioniert werden soll, angegeben werden. In unserem Fall die Spalte „MonthID“:
--Create Fact table CREATE TABLE T_FACT_01_Umsatz ( MonthID int NOT NULL ,CustomerID varchar(100) NOT NULL ,ProductID varchar(100) NOT NULL ,Umsatz money NULL ,Menge int NULL ) -- Name of partition scheme ON PS_APP_UmsatzMonthRange(MonthID) GO
Wichtig: der Datentyp der Spalte muss zu der Typdefinition in der Partitionierungsfunktion passen.
Um die Partitionierung auch prüfen zu können brauchen wir nun ein paar Testdaten. Nachfolgendes Skript nimmt uns hier die Arbeit ab:
------------------------------------------------- --FILL TABLES ------------------------------------------------- --Init base variables DECLARE @InitMonthID int DECLARE @MonthID int DECLARE @NewMonthID int DECLARE @CustomerID varchar(100) DECLARE @ProductID varchar(100) DECLARE @RecPerMonth int SET @InitMonthID = 201101 SET @MonthID = @InitMonthID SET @NewMonthID = 201201 SET @CustomerID = 'Customer A' SET @ProductID = 'Product ' SET @RecPerMonth = 10000 -- run times for generation: -- ca. 0:05 min for 10.000 rec. per month -- ca. 1:00 min for 100.000 rec. per month -- ca. 8:30 min for 1.000.000 rec. per month --Generat initial recordset for first month --Init Record counter DECLARE @RecCounter int SET @RecCounter = 1 --Insert Values WHILE @RecCounter <= @RecPerMonth BEGIN --Fact INSERT INTO T_FACT_01_Umsatz VALUES (@InitMonthID, @CustomerID, @ProductID + convert(varchar, @RecCounter), (1 + rand()*10000) , (1 + rand()*10000)/10) SET @RecCounter = @RecCounter + 1 END --Set next month and init loop SET @MonthID = 201102 --Loop Months WHILE @MonthID <= 201112 BEGIN --Copy fact data INSERT INTO T_FACT_01_Umsatz SELECT @MonthID MonthID , CustomerID , ProductID , Umsatz , Menge FROM T_FACT_01_Umsatz WHERE MonthID = @InitMonthID SET @MonthID = @MonthID + 1 END GO
Über den Parameter „@RecPerMonth“ kann die Anzahl Datensätze verändert werden, die pro Monat in die Faktentabelle eingefügt werden. Die Laufzeiten sind exemplarisch ergänzt, so dass frei gesteuert werden kann, auf welche Wartezeiten man sich einlassen möchte.
Richtig oder nicht?
Natürlich kann man auch das mühsam erarbeitete Ergebnis prüfen und schauen, in welche Partitionen eine Tabelle aktuell aufgeteilt ist. Der folgende Befehl:
--Show Partition split Fact SELECT 'T_FACT_01_Umsatz' Tab ,$partition.PF_APP_UmsatzMonthRange(u.MonthID) AS [Partition Number] ,min(u.MonthID) AS [Min Monht] ,max(u.MonthID) AS [Max Month] ,count(*) AS [Rows In Partition] FROM dbo.T_FACT_01_Umsatz AS u GROUP BY $partition.PF_APP_UmsatzMonthRange(u.MonthID) ORDER BY [Partition Number] GO
liefert das ersehnte Ergebnis:
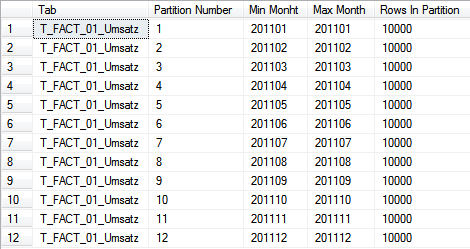
Wie man in der Tabelle sehr schön erkennen kann, wurden wie angekündigt zwölf Partitionen erstellt. Alle erstmal mit der gleichen Anzahl Datensätze (die aus dem RecPerMonth-Parameter). Würde nun ein neuer Monat Januar 2012 in der Tabelle ergänzt werden, so würde dieser in die zwölfte Partition mit eingefügt werden und dort die Anzahl Datensätze erhöhen.
Aber Achtung bei der Interpretation der gezeigten Abfrage. Ist eine Partition ganz leer, wird diese von dem gezeigten Statement nicht zurückgegeben. Das ändert aber nichts an der Tatsache, dass diese Partition trotzdem existiert!
Wie eine leere Partition aussieht, wie man mit den erstellten Partitionen weiterarbeiten kann und ob die Partitionierung wirklich so viel bringt, schauen wir uns im zweiten Teil an. Daher bleibt zum Schluss, frei nach Löwenzahn, nur noch eines zu sagen: Abschalten!
