Die Möglichkeit, ein „Create Relational Schema“ lediglich inkrementell auszuführen und somit nur von Änderungen betroffene Tabellen neu aufzubauen, spart insbesondere in großen Projektumgebungen bereits einiges an Zeit. Bislang gibt es in DeltaMaster ETL jedoch noch nicht die Möglichkeit, einerseits die Auswirkungen eines solchen inkrementellen Create Relational Schema im Vorfeld abzuschätzen (sprich: Welche Tabellen im konkreten Fall betroffen wären) und andererseits ein inkrementelles Laden (sprich: nur die neu erstellten Tabellen zu befüllen) durchzuführen. Für beide Anwendungsfälle soll in diesem Blogbeitrag ein Weg vorgestellt werden, dies über selbst erstellte Views bzw. Prozeduren zu ermöglichen.
Ausgangssituation
Die Möglichkeit, ein „Create Relational Schema“ lediglich inkrementell auszuführen und somit nur von Änderungen betroffene Tabellen neu aufzubauen, spart insbesondere in großen Projektumgebungen bereits einiges an Zeit. Mögliche Anwendungsfälle hierfür sind, dass bspw. lediglich in einigen Faktentabellen neue Kennzahlen hinzugekommen bzw. entfernt worden sind, oder bestimmte Dimensionen nur um ein Attribut ergänzt wurden. In diesen Fällen erscheint es wenig sinnvoll, das komplette Sternschema neu aufzubauen und vor allem, alle Tabellen neu zu befüllen. Um lediglich die von Änderungen betroffenen Dimensions- sowie Faktentabellen neu zu erstellen, genügt ein Klick auf „Execute“ bei ausgewähltem „Incremental mode: changed & dependant tables, all views & all procs“:
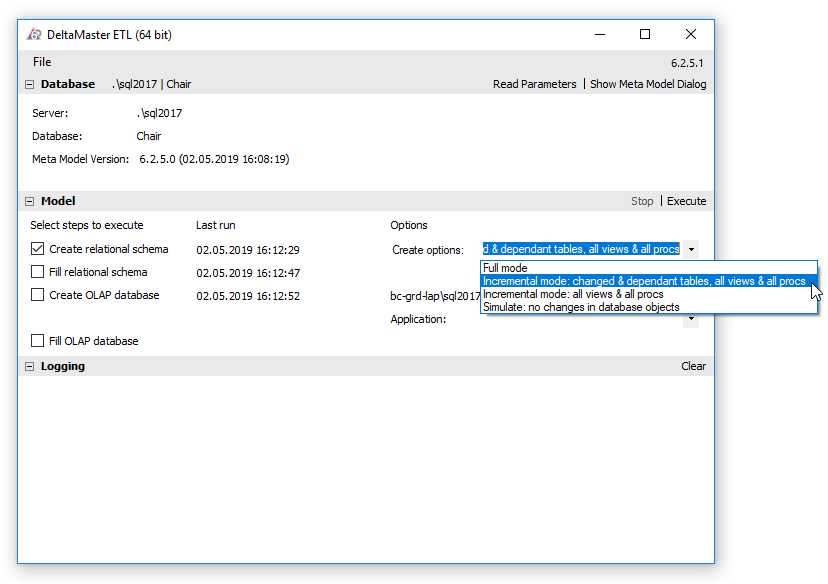
Abbildung 1: Ausführen eines inkrementellen „Create Relational Schema“
Was genau dieser Klick bewirkt, ist für den Anwender an dieser Stelle aber zunächst nicht ersichtlich. Genauer gesagt ist nicht klar, welche Tabellen denn nun in der Vergangenheit geändert wurden. Das kann insbesondere in Mehrbenutzersystemen, in denen ggf. andere Nutzer testweise Veränderungen vorgenommen haben, durchaus mehr sein, als man gerade selbst im System angepasst hat. Auch sind vielleicht nicht alle Abhängigkeiten und Wechselwirkungen der eigenen Anpassungen auf Anhieb klar (klassischerweise, wenn eine Dimension in vielen Measuregroups verwendet wird, die dann alle neu erstellt würden). Hier lohnt sich ein Blick in die Logik, die DeltaMaster ETL für das inkrementelle Create Relational Schema verwendet, um Auswirkungen dieses Schritts bereits im Vorfeld abschätzen zu können. Eine Abfrage, die eine Auswirkungsanalyse des inkrementellen Create Relational Schema vornimmt, ist in diesem Blogbeitrag beschrieben. Ist das inkrementelle Create Relational Schema durchgeführt worden, liegen einige Fakten- und Dimensionstabellen nur noch leer vor, während vermutlich die meisten noch befüllt sind. Welche Tabellen genau das sind, erfahren wir allerdings auch (noch) nicht direkt vom Tool selbst. Vielmehr gilt es, manuell nachzusehen, welche Tabellen betroffen waren und diese von Hand neu zu befüllen, indem alle passenden P_Dim- und P_Fact-Prozeduren in der korrekten Reihenfolge ausgeführt werden. Auch für diesen Anwendungsfall soll in diesem Blogbeitrag ein Verfahren vorgestellt werden, das automatisiert lediglich die veränderten Tabellen befüllt.
Auswirkungsanalyse für ein inkrementelles Create Relational Schema
Änderungen am Metamodell werden durch die angestoßenen Eingabeprozeduren in der Analysesitzung „DeltaMaster ETL.das“ erfasst. Jede Änderung an einer Dimension(sebene), Measuregroup, Partition etc. resultiert in einer Markierung der entsprechenden Tabelle samt aller abhängigen Objekte in der Datenbank. Wichtig ist, dass hierbei lediglich festgehalten wird, dass eine Änderung vorgenommen wurde und das Objekt somit beim nächsten inkrementellen Create Relational Schema neu aufgebaut werden soll. Es wird dabei jedoch nicht darauf geachtet, ob Änderungen bspw. wieder rückgängig gemacht wurden. Somit führen auch testweise, kurzzeitig übernommene und wieder gelöschte Eingaben dazu, dass Dimensions- und Faktentabellen u.U. unnötigerweise neu erstellt und damit befüllt werden müssen. Auch deshalb kann es vorteilhaft sein, bereits vor einem inkrementellen Create Relational Schema zu wissen, welche Tabellen genau betroffen wären. In der Datenbank wird die Markierung, ob ein Objekt beim nächsten inkrementellen Create Relational Schema erstellt werden soll, wie folgt gesetzt. In der View V_MODELSYS_CreateSnowflakeModelObject gibt es eine Spalte IncludeInNextCS, die mit einem Wert größer 0 befüllt wird, wenn das Objekt betroffen ist. Um also alle Objekte zu ermitteln, die von einem inkrementellen Create Relational Schema betroffen wären, genügt folgende Abfrage:
SELECT DISTINCT CSBaseObjName AS IncrementalSnowFlakeAffectedTable FROM V_MODELSYS_CreateSnowflakeModelObject WHERE IncludeInNextCS > 0 ORDER BY CSBaseObjName
Mit dieser Abfrage kann überprüft werden, ob nur die gewünschten Anpassungen vorgenommen werden, oder ob es weiterreichende Auswirkungen gibt, die man nicht berücksichtigt hat. Da man in manchen Umgebungen allerdings auch nicht weiß, wie umfangreich eine Neuerstellung wäre, sprich, wie viele Datensätze nachgeladen werden müssten, empfiehlt es sich, auch deren Anzahl anzuzeigen. Hierfür kann man eine weitere mit DeltaMaster ETL ausgelieferte View verwenden (V_ModelInfo_SysTabRowCount), die den Füllstand von Objekten im Datenmodell ausgibt. Im Ergebnis erhalten wir folgende, neue View:
CREATE VIEW V_APP_ModelInfo_CreateIncrementalSnowflake_AffectedTables AS SELECT DISTINCT TOP 100 PERCENT newobjects.CSBaseObjName AS IncrementalSnowFlakeAffectedTable, COALESCE(tabinfos.[RowCount],0) AS AffectedDataSets FROM V_MODELSYS_CreateSnowflakeModelObject newobjects LEFT JOIN V_ModelInfo_SysTabRowCount tabinfos ON newobjects.CSBaseObjName = tabinfos.ObjectName WHERE IncludeInNextCS > 0 ORDER BY CSBaseObjName
Da es auch vollkommen neue Tabellen (bspw. Dimensionen) bei einem inkrementellen Create Relational Schema geben kann, werden diese in der View mit 0 Datensätzen ausgewiesen (hier gibt es ja noch keine vorherige Befüllung, es würden also keine bereits vorhandenen Datensätze gelöscht).
Das Ergebnis dieser View bei ein paar beispielhaften Anpassungen in der Dimension „Kunde“ sowie Anlage einer neuen Dimension „NewDimension“ sieht wie folgt aus:
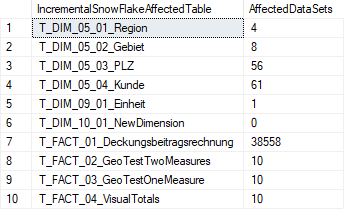
Abbildung 2: Beispielhaftes Ergebnis der vorgestellten View
Wir wissen nun somit bereits vor einem inkrementellen Create Relational Schema, welche Tabellen genau neu aufgebaut und somit geleert werden und wie viele Datensätze sich dort aktuell befinden. Dies wiederum ermöglicht eine ungefähre zeitliche Abschätzung des Eingriffs.
Inkrementelles Befüllen der betroffenen Tabellen
Zu wissen, welche Tabellen genau von einem inkrementellen Create Relational Schema betroffen und somit leer sein werden, ist bereits ein erster Schritt hin zu einer automatisierten Befüllung genau dieser Tabellen. Nach der Durchführung eines inkrementellen Create Relational Schema können wir uns aber nicht mehr derselben Logik bedienen, um herauszufinden, was verändert wurde. Die Begründung liegt darin, dass die oben beschriebene Tabelle wieder „zurückgesetzt“ wird, also die Markierungen für neu zu erstellende Objekte wieder entfernt werden. Das ergibt auch Sinn, da diese Anpassungen ja bereits vorgenommen wurden. Daher verwenden wir für die nachträgliche Betrachtung die View V_MODELSYS_CreateSnowflakeCode, die den ausgeführten Code für das Create Relational Schema anzeigt. Hier gilt es noch, unsere Auswahl auf das letzte Create Relational Schema einzuschränken (das mit der höchsten ID) und nur solche Objekte anzuzeigen, für die ein CREATE tatsächlich ausgeführt wurde. Um zusätzlich die Prozedurnamen für die Befüllung zu erhalten, verbinden wir den SnowflakeCode über die ModelRowID mit den Views für Fakten- und Dimensionsprozeduren:
SELECT CSObjName AS TableName,
COALESCE(FactProcName,DimensionLevelProcName) AS TransformProcedure
FROM V_MODELSYS_CreateSnowflakeCode cscode
LEFT JOIN V_Model_CreateFactProcs facts
ON cscode.ModelRowID = facts.FactRowID
LEFT JOIN V_Model_CreateDimProcs dims
ON cscode.ModelRowID = dims.DimLevelRowID
WHERE CSID = (SELECT MAX(CSID) FROM T_MODELSYS_CreateSnowflakeCode)
AND CSCmdExecutionState > 0
AND CSCmdOrigin IN ('Create_DIM_Tables','Create_Fact_Tables')
AND (CSObjType LIKE 'FACT%TAB' OR CSObjType LIKE 'DIM%TAB')
ORDER BY CSCmdID ASC
Mit dieser Abfrage erhalten wir alle Fakten- und Dimensionstabellen, die beim letzten Create Relational Schema neu erstellt wurden und somit jetzt leer sind (wenn sie nicht in der Zwischenzeit befüllt wurden). Im Fall eines Full Create Relational Schema werden das einfach alle Tabellen sein. Zusätzlich erhalten wir alle Befüllungsprozeduren, die ausgeführt werden müssen, um diese Tabellen wieder mit Daten zu versorgen. Auf dieser Grundlage können wir nun eine Prozedur erstellen, die lediglich die Objekte befüllt, die beim letzten Create Relational Schema neu erstellt wurden. Als möglicher Lösungsansatz wurde der Quellcode der Standard-ETL-Prozeduren P_Transform_12_P_DIMs_Ausfhren und P_Transform_13_P_Facts_Ausfhren zusammengefügt. Diese Prozeduren erstellen jeweils einen Cursor mit allen Objekten, die befüllt werden sollen.
Bei der Erstellung des jeweiligen Cursors wird die Menge mithilfe der obigen Abfrage auf die gewünschten Objekte eingeschränkt. Das sieht für die Dimensionsbefüllung wie folgt aus:
SELECT obj.[name] AS sp_name ,sch.[name] + '.' AS sch_name --select * FROM sys.objects obj LEFT JOIN sys.schemas sch ON obj.[schema_id] = sch.[schema_id] LEFT JOIN V_Model_CreateDimProcs cdp ON obj.[name] = parsename(cdp.DimensionLevelProcName,1) LEFT JOIN V_Model_CreateDimAttrTables cdat ON obj.[name] = parsename(cdat.DimAttrProcName, 1) WHERE ( (obj.[name] LIKE N'P[_]DIM%' AND isnull(cdp.DimensionID, cdat.DimensionID) IS NOT NULL) -- Nur Objekte die in aktueller Modelldefinition enthalten sind
OR obj.[name] LIKE N'P[_]UDIM%' ) AND obj.[type] = 'P' --ab hier erfolgt eine zusätzliche Einschränkung: AND cdp.DimensionLevelTableName IN ( SELECT CSOBjSchema + CSObjName AS TabName FROM T_MODELSYS_CreateSnowflakeCode WHERE CSID = (SELECT MAX(CSID) FROM T_MODELSYS_CreateSnowflakeCode) AND CSCmdExecutionState > 0 AND CSCmdOrigin = 'Create_DIM_Tables' AND CSObjType LIKE 'DIM%TAB') ORDER BY --obj.[name] isnull(isnull(cdp.DimensionID, cdat.DimensionID), 9999) ,isnull(isnull(cdp.DimensionLevelID, cdat.DefinitionLevelID), 9999) ,isnull(cdp.SourceTableID, 9999)
Bei der Erstellung des Cursors für die Befüllung der Faktentabellen ergibt sich ein ähnliches Bild:
SELECT
obj.[name] AS sp_name
,sch.[name] + '.' AS sch_name
--select *
FROM
sys.objects obj
LEFT JOIN sys.schemas sch
ON obj.[schema_id] = sch.[schema_id]
LEFT JOIN V_Model_CreateFactProcs cfp
ON obj.[name] = parsename(cfp.FactProcName,1)
LEFT JOIN V_Model_CreateFactProcs cfp_fk
ON obj.[name] = parsename(cfp_fk.FactProcFKCreateName,1)
AND cfp_fk.SourceTableID = 1
WHERE
(
(obj.[name] LIKE N'P[_]FACT%' AND isnull(cfp.FactID, cfp_fk.FactID) IS NOT NULL) -- Nur Objekte die in aktueller Modelldefinition enthalten sind
OR obj.[name] LIKE N'P[_]UFACT%'
)
AND obj.[type] = 'P'
AND isnull(cfp.FactIsActive, cfp_fk.FactIsActive) = 1
--ab hier erfolgt eine zusätzliche Einschränkung:
AND sch.name+'.'+obj.[name] IN ( SELECT facts.FactProcName
FROM V_MODELSYS_CreateSnowflakeCode cscode
LEFT JOIN V_Model_CreateFactProcs facts
ON cscode.ModelRowID = facts.FactRowID
WHERE CSID = (SELECT MAX(CSID)
FROM T_MODELSYS_CreateSnowflakeCode)
AND CSCmdExecutionState > 0
AND CSCmdOrigin = 'Create_Fact_Tables'
AND CSObjType LIKE 'FACT_Tab')
ORDER BY
obj.[name]
Mithilfe dieser beiden Abfragen kann man sich natürlich jederzeit ausschließlich die Dimensions- und Faktenprozeduren anzeigen lassen, die nach einem inkrementellen Create Relational Schema ausgeführt werden müssen. Die Verwendung als Prozedur inkl. des restlichen Codes aus den Standard-Prozeduren von DeltaMaster ETL hat darüber hinaus allerdings den Vorteil, dass auch ein Fehler-Logging entsprechend der eingestellten Log-Stufe erfolgt.
Am Ende kann noch die Standard-ETL-Prozedur P_Transform_14_P_ELEMDEL_Ausfuehren eingefügt werden, um unnötig eingefügte Dimensionselemente wieder zu entfernen. Um bei versehentlichen Ausführungen Mehrfachbefüllungen zu vermeiden, können auch die Prozeduren für das Leeren von Fakten- und Dimensionstabellen an den Anfang gesetzt werden (mit entsprechender Anpassung der WHERE-Bedingungen). Auch ggf. notwendige Preprocess- oder Postprocess-Schritte können in die Prozedur aufgenommen werden. Die resultierende Prozedur wird aus Platzgründen separat zur Verfügung gestellt.
Fazit
Die vorgestellte Auswirkungsanalyse kann hilfreich sein, um die Dauer eines inkrementellen Create Relational Schema inkl. Neubefüllung der betroffenen Tabellen abzuschätzen. Sollten aufgrund von anderen Nutzern bspw. zu viele Änderungen notwendig sein, die im konkreten Anwendungsfall nicht notwendig sind und zu viel Zeit in Anspruch nehmen würden, kann der tatsächlich auszuführende Create Relational Schema Code manuell aus der Tabelle T_MODELSYS_CreateSnowflakeCode entnommen und ausgeführt werden. Hierfür gilt es, zunächst die Option „Simulate: no changes in database objects“ in DeltaMaster ETL auszuwählen und damit ein Create Relational Schema anzustoßen. Dieser Ansatz empfiehlt sich allerdings nur für fortgeschrittene Nutzer. Die vorgestellte Prozedur zum inkrementellen Befüllen spart insofern Zeit, als man nun nicht mehr bspw. über die Tabelle sys.objects manuell nachsehen muss, welche Tabellen zuletzt erstellt wurden und somit vermutlich vom inkrementellen Create Relational Schema betroffen waren. Vielmehr kann man sich entspannt auf die ausgeklügelte Logik der von DeltaMaster ETL geführten Create-Relational-Schema-Code-Tabelle verlassen und lediglich veränderte Tabellen befüllen. Da der verwendete Quellcode aus den Prozeduren P_Transform_12_P_DIMs_Ausfhren und P_Transform_13_P_Facts_Ausfhren stammt und innerhalb der erstellten Prozedur auch von einem „Create Metamodel“ nicht betroffen wäre, ist stets auf die Version von DeltaMaster ETL zu achten. Die beispielhaft erstellte Prozedur wurde auf Basis von DeltaMaster ETL 6.2.5 erstellt. In zukünftigen Versionen könnte sich allerdings die Logik der Befüllung ändern. Dies kann ein Nachteil des vorgestellten Verfahrens sein, da die Prozedur ggf. bei Metamodelländerungen manuell angepasst werden muss. Langfristig ist geplant, das Feature eines inkrementellen Befüllens auch in den Funktionsumfang von DeltaMaster ETL aufzunehmen. Bis dahin kann die vorgestellte Prozedur jedoch hilfreich sein, wenn man für Änderungen an großen Kundensystemen häufig das inkrementelle Create Relational Schema verwendet.


Kommentare
Sie müssten eingeloggt sein um Kommentare zu posten..